淘宝技术这十年——互联网技术大全!
淘宝技术——探究寻秘 前言
这其实是《淘宝技术这十年》的读书笔记,该书以时间为脉络讲述了淘宝这十年来的技术迭代,是一本了解互联网名词、技术的好书。
本文从书的第0章开始将遇到的计算机、互联网名词进行一一介绍,并附上进一步了解的链接,也算是增加自己对整个系统架构的熟悉程度和知识储备。
目录
- 第0章 引言
- Hadoop分布式计算集群
- CDN网络
- PV、UV
- LVS:Linux Virtual Server
- 轮询/加权轮询算法
- 浏览器资源并发下载数量限制
- TFS:Taobao File System
- 搜索系统介绍
- TimeTunnel
- 淘宝云梯分布式计算平台
- ODPS数据存储、挖掘
- 数据挖掘
第0章 引言
Hadoop分布式计算集群
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
参考链接:
https://blog.csdn.net/qq_32649581/article/details/82892861
CDN网络
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。CDN的关键技术主要有内容存储和分发技术。
参考链接:
CDN是什么?使用CDN有什么优势? https://www.zhihu.com/question/36514327/answer/1604554133
PV、UV
PV,page view,页面访问量;
UV,unique view,用户访问量;
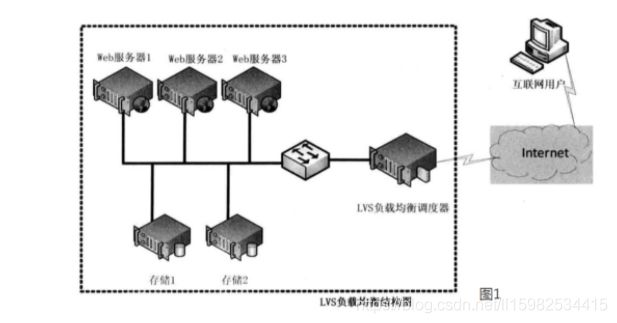
LVS:Linux Virtual Server
即Linux虚拟服务器,是由章文嵩博士主导的开源负载均衡项目,目前LVS已经被集成到Linux内核模块中。该项目在Linux内核中实现了基于IP的数据请求负载均衡调度方案,其体系结构如图所示:
参考链接:
https://blog.csdn.net/weixin_40470303/article/details/80541639
轮询/加权轮询算法
参考链接:
https://blog.csdn.net/JMW1407/article/details/107787546
浏览器资源并发下载数量限制
浏览器的网络请求资源数是针对单一域名的。不同浏览器,不同http协议版本允许的网络请求资源数是不一样的(具体自行百度),不过总的来说在2-8个之间。
参考链接:
实验证明:
https://www.cnblogs.com/skyweaver/p/6091063.html
简单解释:
https://blog.csdn.net/u010080235/article/details/99978360
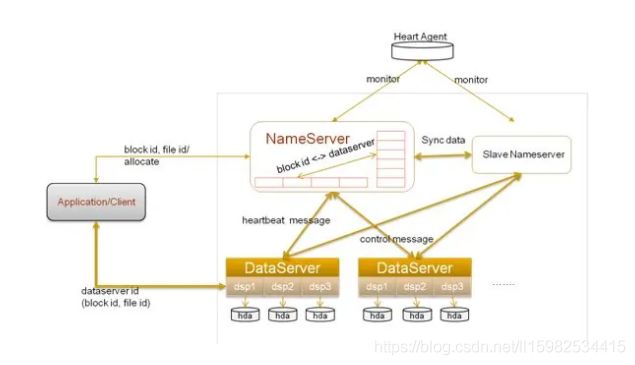
TFS:Taobao File System
TFS(Taobao File System)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据。
参考链接:
https://baike.baidu.com/item/TFS/5561187?fr=aladdin
搜索系统介绍
搜索系统主要包括:分词、数据查询、数据排序。其架构图如图所示:
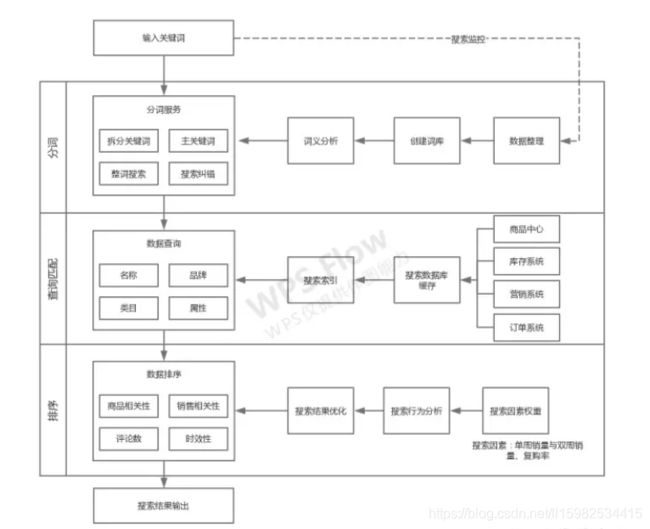
其中,分词主要包括建立词库、词义分析,以及搜索纠错。
产品经理:
http://www.woshipm.com/pd/3422975.html
或者:
https://zhuanlan.zhihu.com/p/24083308
TimeTunnel
TimeTunnel(简称TT)是一个基于thrift通讯框架搭建的实时数据传输平台,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点(基于Hbase)。
目前TimeTunnel在阿里巴巴广泛的应用于日志收集、数据监控、广告反馈、量子统计、数据库同步等领域。
参考链接:
https://blog.csdn.net/pelick/article/details/26265663
淘宝云梯分布式计算平台
参考链接:
https://blog.csdn.net/uxiAD7442KMy1X86DtM3/article/details/90819717
ODPS数据存储、挖掘
开发数据处理服务(Open Data Processing Service,简称ODPS),2016年后更名MaxComputer。ODPS是一种由阿里云自主研发,针对TB/PB级数据、实时性要求不高的分布式处理服务。主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务。
CSDN
https://blog.csdn.net/helloxiaozhe/article/details/79590647
简书
https://www.jianshu.com/p/963e23880d01
数据挖掘
数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘过程模型步骤主要包括定义问题、建立数据挖掘库、分析数据、准备数据、建立模型、评价模型和实施。下面让我们来具体看一下每个步骤的具体内容:
python实战
https://www.cnblogs.com/zhuPython/p/9466770.html
你用 Python 做过什么有趣的数据挖掘/分析项目? - 何明科的回答 - 知乎 https://www.zhihu.com/question/28975391/answer/82797746
你用 Python 做过什么有趣的数据挖掘/分析项目? - 挖数的回答 - 知乎 https://www.zhihu.com/question/28975391/answer/100796070
(未完待续)