机器学习之朴素贝叶斯算法的详解(包含高斯朴素贝特斯、多项式朴素贝叶斯、伯努利朴素贝叶斯,以及相应算法的简单实现)
机器学习18_贝叶斯算法详解(2021.06.02 - 2021.06.05)
一. 朴素贝叶斯算法
- 为什么需要朴素贝叶斯算法?
比如说,我们想预测一个人究竟是否能够侥幸在空难中生还,那么我们就需要建立一个分类模型来学习我们的训练集。在训练集中,其中一个人的特征是30岁,男,普通舱,他最终在空难中去世了。训练完成后,当我们使用训练好的模型进行测试的时候,测试的目标的特征也是30岁,男,普通舱,那么我们的模型必然会给这个人打上去世的标签。然而事实却不一定为此,也许这个人正好坐在了离逃生口最近的位置,他得到了第一时间的救治而生存下来了。因此对于分类算法来说,基于训练的经验,这个人“很有可能”去世,但算法永远无法确定这个人“一定没有活下来”。即便是这个人最后真的去世了,算法也无法根据训练数据给出绝对的判断和结论。
从这个故事就可以看出,根据算法训练得到的结果其实常常只是一种非100%确定的推测,而我们在使用模型时却非要强行让算法给我们一个分类的结果,这样的结果其实也并不是我们想要的,换句话说大多数时候,我们也希望算法能给我们一个多可能的带有概率分布的结果,因此就有了真正基于概率的算法 ----- 朴素贝叶斯。 - 什么是朴素贝叶斯算法?
朴素贝叶斯算法是一种直接衡量标签与特征之间的概率关系的有监督的学习算法,是一种专注分类的算法。其根源就是基于概率论与数理统计的贝叶斯理论,因此它是根正苗红的概率模型。 - 朴素贝叶斯算法所需的概率知识扫盲
1.什么是概率?
概率,旧称几率,又称机率、机会率或或然率,是对随机事件发生之可能性的度量,为数学概率论的基本概念;概率的值是一个在0到1之间的实数,也常以百分数来表示。
2.通俗地理解联合概率和条件概率
一篇比较轻松易懂的博文推荐:https://zhuanlan.zhihu.com/p/150438364
3.概率计算公式总结

- 朴素贝叶斯算法的适用范围
1.朴素贝叶斯值适用于特征之间是条件独立的情况下,否则分类效果不好,这里的朴素指的就是条件独立。
2.朴素贝叶斯主要被广泛地使用在文档分类中。 - 朴素贝叶斯算法的分类
在sklearn中提供了三种不同类型的贝叶斯模型算法,分别是:高斯模型、多项式模型、伯努利模型
二. 高斯朴素贝叶斯算法
- 高斯分布(正态分布)的扫盲
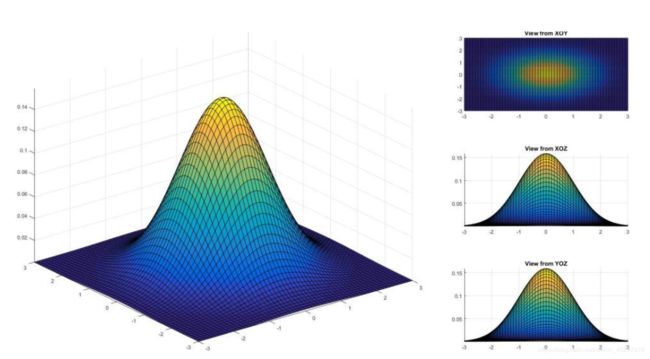 高斯分布(正态分布)是一种连续型变量的概率分布,简单地来说,高斯分布(正态分布)就是当频率直方图的区间变得特别小的拟合曲线,像一座小山峰,其中两端特别小,越往中间越高。所谓的高斯分布(正态分布)其实就是正常形态的分布,它是自然界的一种规律。现实生活中有很多现象服从高斯分布,比如人的身高、收入、体重等等,大部分的人都处在中等水平,只有极少数的人会特别高或者特别低。高斯朴素贝叶斯公式如图所示,本质上就是通过假设P(xi|Y)是服从高斯分布(正态分布),从而来估计每个特征分到每个类别Y上的条件概率。
高斯分布(正态分布)是一种连续型变量的概率分布,简单地来说,高斯分布(正态分布)就是当频率直方图的区间变得特别小的拟合曲线,像一座小山峰,其中两端特别小,越往中间越高。所谓的高斯分布(正态分布)其实就是正常形态的分布,它是自然界的一种规律。现实生活中有很多现象服从高斯分布,比如人的身高、收入、体重等等,大部分的人都处在中等水平,只有极少数的人会特别高或者特别低。高斯朴素贝叶斯公式如图所示,本质上就是通过假设P(xi|Y)是服从高斯分布(正态分布),从而来估计每个特征分到每个类别Y上的条件概率。

- 高斯朴素贝叶斯模型的作用
在贝叶斯分类中,高斯模型就是用来处理特征变量的,当使用此模型时,第一步:我们会假定特征属于高斯分布,第二步:去计算训练样本集中每一个样本数据的每一个特征分到帅的条件概率和丑的条件概率,再基于最大化P的准则,定义每个特征所属的标签及其概率,第三步:基于训练样本集计算特征所属标签的均值和标准差,这样就可以估计某个特征属于某个类别的概率。
举个例子:当你想判断一个人是帅还是丑,则帅和丑就是分类的标签。在样本数据集中,一个人的特征假设有身高、体重、三围这三种。对于样本数据中的其中一条数据(某一个人),高斯分布就会计算身高的特征分到帅的条件概率和丑的条件概率,再计算体重的特征分到帅和丑的概率,以此类推。在这之后,将数据集中的每一条数据按照上述描述进行相同的操作。然后对训练样本集中的每一条数据的特征(身高、体重、三围)分到每一个类别的最大概率进行均值、方差计算。从而最终返回每一个特征的系数w。 - 高斯朴素贝叶斯算法的API
from sklearn.naive_bayes import GaussianNB
实例化模型对象的时候,我们不需要对高斯朴素贝叶斯输入任何参数,可以说是一个非常轻量级的类,操作非常容易,但过于简单也意味着贝叶斯没有太多的参数可以调整,因此贝叶斯算法的成长空间并不是太大,如果贝叶斯算法的效果不是太理想,我们一般会考虑换模型。 - 基于高斯朴素贝叶斯算法和sklearn中的digits数据集的数字分类的代码实现
from sklearn.naive_bayes import GaussianNB # 导入高斯朴素贝叶斯
from sklearn.datasets import load_digits # 导入数字数据集
from sklearn.model_selection import train_test_split # 用于对数据集的拆分
# 读取样本数据集
data = load_digits()
# print(data)
# 提取特征数据和标签数据
feature = data.data
target = data.target
# 拆分数据
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2021)
# 训练模型
nb = GaussianNB() # 实例化模型对象
nb.fit(x_train, y_train) # 训练模型
# 给模型评分
score = nb.score(x_test, y_test)
print(score)
# 预测
pred_result1 = nb.predict(x_test[6].reshape(1, -1))
true_result1 = y_test[6]
print('预测结果为:', pred_result1, '真实结果为:', true_result1)
# 打印perd_result1属于0~9每个类别的概率,最大值就是分类的结果
DP_pred_result1 = nb.predict_log_proba(x_test[6].reshape(1, -1))
print(DP_pred_result1)
# 结果如下,可以看出在9处的概率最高,也是因此将该测试数据的结果定义为了9
# [[-3.32723175e+02 -4.31949249e+01 -2.13646036e+02 -1.09524299e+02
# -4.67899190e+07 -7.60473436e+01 -8.76400506e+02 -9.94269149e+08
# -2.10601963e+02 0.00000000e+00]]
三. 多项式朴素贝叶斯算法
- 多项式朴素贝叶斯算法的特性
1.与高斯朴素贝叶斯相反,多项式朴素贝叶斯主要适用于离散特征的概率计算(虽然在sklearn中的多项式模型也可以被用作在连续性特征概率计算中,但是如果我们想要处理连续性变量时最好选择高斯模型)。
2.sklearn的多项式模型不接受输入负值(所以如果样本数据为数值型数据的话,务必要进行归一化处理保证特征数据中没有负值出现)。 - 什么是多项式朴素贝叶斯算法?
通过举一个简单的例子来理解什么是多项式朴素贝叶斯(对一篇文章类型的分类)。
对于一篇文章它到底财经类文章还是体育类文章该如何进行分类呢?多项式朴素贝叶斯的方法就是分别计算出这篇文章为不同类型文章的概率,换句话说就是计算出这篇文章是财经文章的概率是多少,是体育文章的概率是多少,之后再将这些概率进行大小比较,从而得出该文章的分类。在这个例子中,最大的概率类型其实就是该文章的类别,而文章又是由一个个词语组成的,所以有以下的公式:

如果假设文章为体育类型文章的概率为1/3,为财经类型文章的概率为1/6,则就可以推测这篇文章是一篇体育类型的文章。
⇒ 那么红色框子内的概率是如何计算的呢?
根据之前学习的条件概率公式(单一条件下的多事件发生)的变形就可以计算出来了。具体的计算过程如下所示:

为了更好的理解介绍的这段计算过程,通过实例化来解释。假设现在有一篇将要被预测的文章,文章中出现了影院、支付宝、云计算这三个词汇,请计算一下该文章属于科技、娱乐的类别概率。
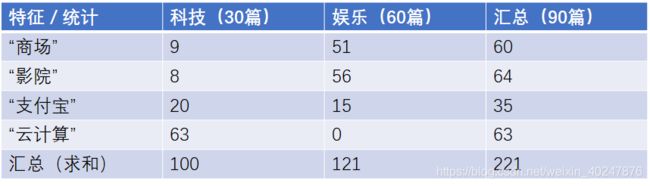
计算过程如下所示:

在计算后发现公式2的结果竟然变成了0,可是这篇文章中也出现了其他有关娱乐的词,所以如果直接将0作为该文章被分类为娱乐文章的概率明显是不合适的,那么要如何解决呢?这就要用到拉普拉斯平滑系数了!(简单地来说,就是在为0的分子上进行加1处理,并将分母也做一定的增大调整,从而使得为0的概率被消除。)

- 多项式朴素贝叶斯的API
from sklearn.naive_bayes import MultinomialNB
参数介绍: MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None),其中alpha为拉普拉斯平滑系数,fit_prior和class_prior都可以不用调整。 - 多项式朴素贝叶斯实现对文章的分类
import sklearn.datasets as datasets # 用于导入数据集
from sklearn.feature_extraction.text import TfidfVectorizer # 用于文本的特征提取
from sklearn.model_selection import train_test_split # 用于数据集的拆分
from sklearn.naive_bayes import MultinomialNB # 导入多项式朴素贝叶斯算法
# 获取数据集
news = datasets.fetch_20newsgroups_vectorized(subset='all')
# print(news)
# 提取特征数据和标签数据
feature = news.data # 返回的是列表,列表中位一篇篇的文章
# print(feature)
# print(len(feature))
target = news.target # 返回的是ndarray,存储的是每一篇文章的分类
# print(target)
# print(len(target))
# 数据集的拆分
x_train, y_train, x_test, y_test = train_test_split(feature, target, test_size=0.2, random_state=2021)
# print(x_train) # 发现拿到的不论是训练集还是测试集的数据都不是数值型数据,因此必须要做特征工程
# 对数据集进行特征抽取
tf = TfidfVectorizer() # 实例化一个工具类
x_train = tf.fit_transform(x_train.toarray()) # 返回训练集所有文章中每个词的重要性
# print(x_train)
x_test = tf.fit_transform(x_test.toarray())
# 模型的训练
mlt = MultinomialNB(alpha=1)
mlt.fit(x_train, y_train)
# 对模型进行评价
y_pred = mlt.predict(x_test)
y_true = y_test
score = mlt.score(x_test, y_test)
print('预测分类为', y_pred)
print('真实分类为', y_true)
print('模型分类准确率为', score)
- 知识补充 ----- 代码中input的TidifVectorizer是什么?
TF:词频,TF(w)= 词w在文档中出现的次数 / 文档的总词数
IDF:逆向文章评率,有些测可能在文本中频繁的出现,但并不重要,即信息量很小。比如:is、are、of 等等,因此我们就可以利用这一点,降低它们的权重。IDF(w) = log_e 语料库的总文档数 / 语料库中w(is、 are、of…)出现的文档数
TF-IDF:就是将上面的TF和IDF做相乘就得到了该综合参数
想要深入了解,请移步到这位大神的博文中:链接在此
四. 伯努利朴素贝叶斯
- 什么是伯努利朴素贝叶斯?
对于多项式朴素贝叶斯来说,它既可以处理二项分布(抛硬币)又可以处理多项式分布(掷骰子)。其中的二项分布又被称为伯努利分布,它是一种现实中常见,并且拥有很多优越数学性质的分布。 - 什么是伯努利模型?
与多项式模型一样,伯努利模型适用于离散特征的情况,所不同的是,数据集中可以存在多个特征,但每个特征都必须是二分类的,且伯努利模型中每个特征的取值都只能是1和0。举个例子:当你想检查一个单词是否在一篇文章中出现过,那你就需要对出现或者没出现的这个事件做一个定义,换句话说就是,当文章中出现过这个词的时候,这个词的特征值就为1,反之,如果这个词没在文件中出现过,那么个词的特征值就为0。 - 伯努利朴素贝叶斯的作用
伯努利朴素贝叶斯与多项式朴素贝叶斯非常相似,都常用于处理文本分类数据,但由于伯努利朴素贝叶斯是处理二项分布的,所以他更加在意的是“是与否”。举个例子来说: 在对一篇文章进行种类区分的时候,伯努利模型做的是判断一篇文章是不是科技类文章,而不是像多项式朴素贝叶斯做的是判断这篇文章是科技类文章还是艺术类文章。
(注意:由于伯努利模型需要使用的特征值不是0就是,那么是否需要我们将用于训练的数据集进行二值化呢?实际上是不用的,因为伯努利模型类中已经集成了二值化操作,但为了了解一下二值化的含义,还是先动手做一个二值化操作吧。)
from sklearn import preprocessing
import numpy as np
X = np.array([
[1, -2, 2, 3, 1, 10],
[1, 2, 3, 33, 4, -90],
[11, 22, 33, 5, -80, 4]
])
binaryzation = preprocessing.Binarizer(threshold=5) # 将大于5的数字视为1,小于等于5的视为0
X_binaryzation = binaryzation.transform(X)
print('二值化结果为(阈值为5):\n', X_binaryzation)
# 结果
# 二值化结果为(阈值为5):
# [[0 0 0 0 0 1]
# [0 0 0 1 0 0]
# [1 1 1 0 0 0]]
- 伯努利朴素贝叶斯的API: from sklearn.naive_bayes import BernoulliNB
参数介绍:alpha:拉普拉斯平滑系数;binarize:可以是数值或者不输入。如果不输入,则认为每个数据特征已经是二值化的了,否则的话,小于binarizer的会归为一类,大于binarizer的会归为一类。 - 基于伯努利贝叶斯的鸢尾花分类的代码实现
import sklearn.datasets as datasets # 用于导入数据集
from sklearn.model_selection import train_test_split # 用于数据集的拆分
from sklearn.naive_bayes import BernoulliNB # 导入伯努利朴素贝叶斯算法
# 读取数据集
iris = datasets.load_iris()
# 提取特征数据和标签数据
feature = iris.data
target = iris.target
# 数据集的拆分
x_train, x_test, y_train, y_test = train_test_split(feature, target, test_size=0.2, random_state=2021)
# print(x_train) # 可以看出训练集数据均为数值型类型,且相差不是很大,因此不需要做特征抽取和特征预处理
# 对数据集进行训练
mlt = BernoulliNB(binarize=6) # 通过调节binarizer参数值的大小可以改善模型预测的准确率
mlt.fit(x_train, y_train)
score = mlt.score(x_test, y_test)
y_pred = mlt.predict(x_test)
y_true = y_test
print("预测鸢尾花类型为", y_pred)
print("实际鸢尾花类型为", y_true)
print("预测模型准确率为", score)
# 结果
# 预测鸢尾花类型为 [0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 0 0 0 0 0 2 2 0 2 2 2 2 0 0]
# 实际鸢尾花类型为 [0 0 1 0 0 0 0 0 0 0 0 1 2 2 1 2 1 1 0 1 1 2 2 0 2 1 1 1 0 0]
# 预测模型准确率为 0.6333333333333333
由此可见,当待处理的样本数据是一个多分类的数据时,(鸢尾花的种类有三种(山鸢尾、杂色鸢尾、维吉尼亚鸢尾),需要判断它是哪一种),因此预测的结果偏差就较大。反之,如果样本数据中全部都是山鸢尾,那么训练后的模型就能很好地对一个未知的种类的鸢尾花它是不是山鸢尾而做出预测。
五. 感悟
- 朴素贝叶斯模型来源于古典数学理论,有着稳定的分类效率,而且对确实的数据不太敏感,算法也相对比较简单。通常被使用在文本分类的项目中。
- 由于朴素贝叶斯算法是基于样本属性独立的假设,所以如果样本属性有关联的时候,朴素贝叶斯算法的分类效果就不尽如人意了。
如有问题,敬请指正。欢迎转载,但请注明出处。