机器学习之逻辑回归算法详解(Sigmoid函数、逻辑回归的损失函数、梯度下降 、逻辑回归的正则化、逻辑回归API中的超参数介绍)
机器学习19_逻辑回归算法详解(2021.06.07 ~ 2021.06.12)
一. 究极总结
逻辑回归:一个打着回归旗号,却在做分类任务的分类器。
二. 必备知识复习
逻辑回归在本质上其实是由线性回归衍变而来的,因此想要更好地理解逻辑回归,先让我们复习一下线性回归。线性回归的原理其实就是用一个线性回归方程来描述一个线性回归的问题。而线性回归的方程可以写作一个几乎大家都熟悉的方程:

在这个方程中,w0被称作截距,w1 ~ wn 被称作系数,这个线性回归方程也可以用矩阵来表示:

通过求出函数z,线性回归便完成了使用输入的特征矩阵X得到了一组连续型的标签值y_pred的操作,从而就可以完成对各种连续型变量的预测任务了。(比如预测一个人的收入、一只股票的价格等等) 深度了解线性回归可参考博主之前有关线性回归的博文:链接在此
但是线性回归模型更多地被用于对连续型数据进行预测,很少甚至是不被用于对离散型数据进行分类。因此为了实现回归模型可以对离散型数据进行分类操作,就有了逻辑回归这个回归模型。在逻辑回归算法中,为了实现分类的效果,我们通常使用的就是sigmoid函数。
三. Sigmoid函数
- Sigmoid函数的用途
sigmoid函数就是为了让线性回归方程得到的取值范围在(-∞,+∞)的y变换成为取值范围在(0,1)之间的g(z),且当g(z)接近0时,样本的标签为类别0;当g(z)接近1时,样本的标签为类别1。这样就得到了一个分类模型。g(z)如下,其中e是自然对数的底数,是一个无限不循环小数,值为2.71828…

sigmoid函数是一个S型的函数,当自变量z趋近于正无穷时,因变量g(z)就会趋近于1,反之当z趋近于负无穷时,g(z)就会趋近于0,它能够将任何实数(非0和1的标签数据)映射到(0,1)之间,使其可用于将任意值函转换为更适合二分类的函数,因为这个性质,sigmoid函数也就被当做是归一化的一种方法,与之前用于归一化的MinMaxScaler功能包的本质道理相同,是属于将数据进行缩放处理的。区别在于,使用MinMaxScaler进行归一化后,是可以将任一实数压缩到0或者1的,而sigmoid只是无限地趋近于0和1。
四. 逻辑回归于线性回归之间的关联
在线性回归中我们可以得出有关z的线性回归方程,再将其带入到sigmoid函数中,就可以把线性回归方程得到的结果压缩到0~1之间了。从而有了以下的组合方程。这个结果也就是我们逻辑回归所返回的标签值。将这个标签中重命名为y(x)。

那么又如何将这个标签值退化为之前的线性回归方程呢?这里就要用到形似几率了,并在形似几率的基础上取对数,就可以将逻辑回归得到的标签结果重新退化为之前的线性回归方程了。过程如下:

不难发现,其实逻辑回归的结果的形似几率再取对数的本质其实就是线性回归方程,那么反过来其实就是我们对线性回归模型预测的结果取对数几率来让其结果无限地逼近0或者1,因此我们也常常将逻辑回归叫做对数几率回归。
总结来说: 逻辑回归的形似几率取对数就是线性回归,线性回归解的对数几率就是逻辑回归。从而我们就知道了,其实逻辑回归就是由线性回归衍变而来的。
五. 逻辑回归想要完成的任务
由于逻辑回归其实就是线性回归的一个衍生,而线性回归的核心任务就是通过求解线性回归方程中的系数w(也叫权重)从而构建线性回归函数z,并希望通过线性回归函数z解得的值能够尽量地拟合真实数据。因此,逻辑回归的核心任务也是类似的,即通过求解逻辑回归函数中的w来构建一个能够尽量拟合的数据的预测函数y(x),并通过向预测函数中输入特征矩阵X来获取相应的标签值y。
六. 为什么说使用Sigmoid函数就能实现分类功能呢?
通过sigmoid函数求得的y(x)的取值范围为(0,1),因此可以有这么一个公式: (1 - y(x)) + y(x) = 1。而这个公式恰巧类似于概率中的正反事件的求和公式。因此可以抽象地理解为:y(x)为事件A会发生的概率,1 - y(x) 就为事件A不会发生的概率,从而也可以衍生为:事件A和事件B联合起来构成了一个总的事件S,即P(A) + P(B) = P(S) = 1,从而求得y(x)就是会发生事件A的概率,而1 - y(x)就为事件B发生的概率,通过比较y(x)和1 - y(x)的大小就可以知道到底是会发生事件A还是事件B,从而就完成了类似于分类的功能。
七. 逻辑回归的优点
-
因为逻辑回归是线性回归的衍生物,因此,当特征数据与标签数据存在着极强的线性关系的时候,逻辑回归后所得到的拟合效果非常的好!那么如何判断数据集是一个线性关系数据集呢?这里以二分类为例,给你做一个简单的解释。简单的来说当所对应的分类的决策边界可以由一条直线来表示时,就可以称这个数据集是一个线性关系的数据集。如下图中的图一,圆圈和三角的决策边界正好可以由一条直线来表示,那么这组数据集就符合线性关系,反之如图二,这组数据就不符合线性关系。

-
逻辑回归对于线性数据的拟合和计算都非常快,在计算效率上甚至优于SVM和随机森林。
-
逻辑回归的结果并不是单纯的0和1,而返回的是一个概率,因此我们就可以将这些返回的概率值当作连续型数据来使用。举个例子来说,当一个用户想要办理信用卡的时候,你可以通过逻辑回归求得一个他会不会定时还款的概率结果,从而决定要不要给他办理信用卡。同时,这个概率结果也可以被用作是这个用户的信用额度,概率越高,信用额度就可以适当的升高。
八. 逻辑回归的损失函数
不论是预测还是分类,我们都会想要通过量化的方式来表示出来结果的准确性,或者说我们需要找到这个结果所伴随的误差是多少。在做逻辑回归分类的时候,不管原本样本数据的类别使用怎样的值或文字表示,逻辑回归统一将其视为0类别或1类别。因为逻辑回归的本质其实也是通过寻找每个特征的权重w来寻找特征数据与目标数据之间的关系,在这过程中难免会出现真实值与预测值的误差,这个误差就可以通过损失函数计算出来。但是逻辑回归是用来做分类操作的,因此该损失函数和线性回归的损失函数是不一样的(注:没有求解参数需求的模型是没有损失函数的,比如KNN算法,决策树算法)逻辑回归采用的损失函数是:对数似然损失函数。逻辑回归的损失函数方程如下:

- 问题又来了,我们为什么要选择-log函数来作为逻辑回归的损失函数呢?
因为损失函数的本质就是,如果我们预测对了,就没有损失,反之如果我们预测的结果不对,则损失就会越大,而-log函数[0, 1]之间正好符合这一点。因此逻辑回归损失函数的图像可以总结为以下两个:
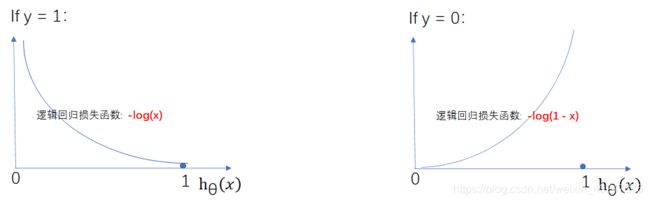
将两种条件下的损失函数求和就可以得到综合完整的损失函数:

本质上损失函数表示的其实就是预测值与真实值之间的差异程度,如果预测值与真实值越接近则损失函数就越小。
九. 用于减小逻辑回归损失函数的方法:梯度下降
逻辑回归的数学目的是求解能够让模型最优化,拟合程度最好的参数w的值,也就是求解能够让损失函数最小的值。因此如何减小损失函数的值就成为了最重要的问题。在线性回归中我们经常使用最小二乘法降低减少我们的损失,在逻辑回归中我们最常用的方法就是梯度下降法。

- 梯度下降的原理
如上方的gif动图所示,右边的三维曲面图就是我们的损失函数,其中Error轴代表着逻辑回归损失函数求得的误差的大小,Weight轴和Bias轴分别代表着两种会影响误差值大小的权重w1和w2,现在我们要做的事情其实就是寻找损失函数的最小值也就是整个三维曲面的最低点。从数学的角度来分析如何获取这个最低点实在有些困难,何况具体的梯度下降操作已经被封装在逻辑回归的功能包中了,因此在这里就从原理的角度简单来分析一下就好。
其实寻找损失函数的最小值的过程就是在这个三维曲面上放置一个小球,松手之后这个小球就会这个小球就会顺着这个三维曲面滑落,直到滑落到三维曲面中的深蓝色的区域,也就是损失函数的最低点了。为了约束或者说是严格监控这个小球的行为,从而不让它一次性就滑落到最低点,我们就可以提前规定好小球每次可以滑动的距离以及小球可以滑动的次数,从而根据这两个值也就可以实时的返回当前损失函数值的大小。通过不断地调试小球每次滑动的距离以及滑动的次数,最终就可以找到你想要的那个损失函数的最低值,也就是三维曲面的最低点。
十. 逻辑回归的正则化
- 什么是逻辑回归的正则化?为什么我们需要对逻辑回归的结果进行正则化?
由于我们为了追求损失函数的最小值,从而让模型在训练集上表现最优而使用了梯度下降。但在这同时可能会引发另一个问题:如果模型在训练集上表现优秀,却在测试集上表现糟糕,那么模型就出现了过拟合的情况。所以我们还是需要使用控制过拟合的技术来帮助我们调整模型,这个控制技术就是通过正则化来实现的。常用的正则化方式有两种选择,一种是L1正则化还有一种是L2正则化,也就是在损失函数后加上参数向量w的L1范式和L2范式的倍数来实现。这个增加的范式被称为“正则项”,也被称为“惩罚项”。
L1范式与L2范式如下,L1范式表现为参数向量w中的每个参数的绝对值之和,L2范式表现为参数向量w中的每个参数的平方和的开方值。

总结:我们知道损失函数的损失值越小(在训练集中预测值和真实值越接近)则逻辑回归模型就越有可能发生过拟合(模型只在训练集表现好,在测试集表现不好)的现象,通过正则化的L1和L2范式可以加入正则项(惩罚项)C来矫正模型的拟合度,因为C越小则损失函数会越大表示正则化的效力越强,参数w会被逐渐压缩的越来越小。
注意:L1正则化将会参数w压缩为0,L2正则加只会让参数尽量地小不会取到0. - L1范式和L2范式的区别
- 在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征参数w会比携带大量信息、对模型有巨大贡献的特征的参数更快地变为0,所以L1正则化的本质是一个特征选择的过程,L1正则化越强,参数向量中就越多的参数为0,选出来的特征就越少,以此来防止过拟合。因此,如果特征量很大,数据维度很高,我们会倾向与使用L1正则化。
- L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数w会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了,但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。因此一般情况下,我们的主要的目的就是防止过拟合,那么选择L2其实就足够了,但是如果使用了L2之后在未知数据上的表现仍然比较差,那么就再使用L1。
- 代码展示L1范式与L2范式的区别
"""L1范式和L2范式的比较"""
from sklearn.linear_model import LogisticRegression as LR # 逻辑回归
from sklearn.datasets import load_breast_cancer # 导入数据集
# import numpy as np
# from sklearn.model_selection import train_test_split # 数据集拆分
# 加载数据集
data = load_breast_cancer()
X = data.data # 特征数据
Y = data.target # 标签数据
# 建立两种用于正则化的模型
LR1 = LR(penalty="l1", C=0.5, solver="liblinear")
LR2 = LR(penalty="l2", C=0.5, solver="liblinear")
# 逻辑回归的重要属性coef_, 查看每个特征所对应的参数
LR1.fit(X, Y)
print("L1范式:", LR1.coef_)
LR2.fit(X, Y)
print("L2范式:", LR2.coef_)
# 结果
# L1范式: [[ 3.21172271 0.02596161 -0.06371837 -0.01242846 0. 0.
# 0. 0. 0. 0. 0. 0.49961334
# 0. -0.07298843 0. 0. 0. 0.
# 0. 0. 0.37556908 -0.23964358 -0.14220463 -0.01748585
# 0. 0. -2.351896 0. 0. 0. ]]
# L2范式: [[ 1.61358623e+00 1.00284781e-01 4.61036191e-02 -4.21333984e-03
# -9.27388895e-02 -3.00561176e-01 -4.53477303e-01 -2.19973055e-01
# -1.33257382e-01 -1.92654788e-02 1.87887747e-02 8.75532438e-01
# 1.31708341e-01 -9.53440922e-02 -9.64408195e-03 -2.52457845e-02
# -5.83085040e-02 -2.67948347e-02 -2.74103894e-02 -6.09326731e-05
# 1.28405755e+00 -3.00219699e-01 -1.74217870e-01 -2.23449384e-02
# -1.70489339e-01 -8.77400140e-01 -1.15869741e+00 -4.22909464e-01
# -4.12968162e-01 -8.66604813e-02]]
# 可以看出来L1明显明显压缩的更狠,很多系数w都被压缩成了0,而且随着对超参数C的缩小,对系数的压缩就会更厉害,也就是会出现更多的0
十一. 逻辑回归的API介绍
from sklearn.linear_model import LogisticRegression
超参数介绍:
- penalty: 可以输入l1或者l2来指定使用哪一种正则化方式,不填的话默认为l2。注:若选择l1正则化,参数solver仅能使用求解方式liblinear和saga,若使用l2正则化,参数solver中所有的求解方式都可以使用。
- C: 惩罚项,必须是一个大于0的浮点数,不填的话默认为1.0,即默认正则项与损失函数的比是1:1,C越小,损失函数会越大,模型对损失函数的惩罚越重,正则化的效力越强,参数会逐渐被压缩的越来越小。
- max_iter: 梯度下降能走的最大步数,默认为100,步数不同的取值可以帮助我们获取不同的损失函数的损失值,目前没有好的办法可以计算出最优的max_iter的值,一般是通过绘制学习曲线对其进行取值。
- solver: 我们之前提到的梯度下降法,只是求解逻辑回归参数w的一种方法,sklearn为我们提供了多种选择,让我们可以使用不同的求解器来计算逻辑回归,求解器的选择由参数slover控制,共有以下五种选择:(liblinear是二分类专用的梯度下降,也是现在的默认求解器,lbfgs、newton-cg、sag、saga是多分类专用,基本上不用)

- multi_class: 表示样本不平衡处理的参数。样本不平衡是指在一组数据中,某种标签天生就占有很大的比例,或者说误分类的代价很高。那么怎么理解误分类代价很高这件事呢?简单举个例子来说,我们现在要对犯罪嫌疑人和良民进行分类,如果我们没有能够识别出犯罪嫌疑人,那么这些人就可能继续去危害社会,也就是说带来了较大的误分类代价。但如果说我们将良民识别成了犯罪嫌疑人,其实相对的代价就没有很大。所以我们宁愿将良民划分为犯罪嫌疑人之后再做甄别,也不愿放跑任意一个犯罪嫌疑人,有一种宁可错杀也不能放过的感觉。
- None: 因为我们要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模,该参数默认为None,此模式表示自动给数据集中的所有标签相同的权重,即自动1:1。
- balanced: 当误分类的代价很高的时候,我们使用balanced模式,可以解决样本不均衡的问题。
十二. 绘制学习曲线感受逻辑回归在乳腺癌分类上的表现从而找到超参数max_iter的最优值
import sklearn.datasets as datasets
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression as LR
import numpy as np
l2 = []
l2_test = []
cancer_data = datasets.load_breast_cancer()
data = cancer_data.data
target = cancer_data.target
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.3, random_state=420)
for i in np.arange(1, 201, 10):
lrl2 = LR(penalty="l2", solver="liblinear", C=0.9, max_iter=i)
lrl2.fit(x_train, y_train)
l2.append(accuracy_score(lrl2.predict(x_train), y_train))
l2_test.append(accuracy_score(lrl2.predict(x_test), y_test))
graph = [l2, l2_test]
color = ["black", "red"]
label = ["L2train", "L2test"]
plt.figure(figsize=(20, 5))
for i in range(len(graph)):
plt.plot(np.arange(1, 201, 10), graph[i], color[i], label=label[i])
plt.legend(loc=4)
plt.xticks(np.arange(1, 201, 10))
plt.show()
结果展示

其中黑色的线是模型在训练集的表现,红色的线是模型在测试集的表现。
十三. 感悟
- 逻辑回归虽然被称为回归,但本质上其实是分类模型,并且常常用于二分类。
- 逻辑回归的细节仍有很多,想要彻底理解逻辑回归算法只了解本文所讲到的东西是远远不够的,推荐一篇博主认为写的很好的博文:链接在此
如有问题,敬请指正。欢迎转载,但请注明出处。