架构解密从分布式到微服务:从微服务到Service Mesh
从微服务到Service Mesh
Service Mesh之再见架构
Kubernetes平台很好地解决了大规模分布式系统架构中的一些通用问题,从基本的自动化部署,服务注册、服务发现、服务路由,到全自动化的运维体系,几乎面面俱到。但由于Kubernetes致力于从更基础的TCP/IP层面提供更广泛的分布式系统的统一架构方案,因此必定以牺牲上层应用层协议的适配为代价。我们看到Kubernetes在解决一些问题时多少有些“鞭长莫及”:
- 在自动部署方面无法实现灰度发布;
- 在服务路由方面无法按照版本或者请求参数实现精细化路由;
- 在服务保护方面无法实现类似于Spring Cloud中的熔断机制或服务限流;
- 在安全机制方面服务之间的调用安全问题缺失;
- 在全链路监控方面几乎空白。
第Ⅰ章提到了HTTP服务很容易通过代理模式完美解决上述问题,也简单介绍了ServiceMesh的相关基础,至此,我们可以清晰地比较Kubernetes 与 Service Mesh 的关系了。
Kubernetes致力于打造一个基于TCP/IP层的大统一的分布式系统支撑平台,Service Mesh则围绕着HTTP的分布式系统提供了更细粒度、更丰富的架构方案。Kubernetes提供了基础平台,Service Mesh则进行了有针对性的优化,因此,Kubernetes 与Service Mesh在未来会更加密切地融合。不排除Service Mesh重要实现之一的Istio逐步发展成为Kubernetes内在的一部分,即Kubernetes中的资源对象继续扩展,原生支持采用了Service Mesh 架构的应用。
Spring框架在诞生之初带来的最大冲击,就是彻底颠覆了当时主流开发(J2EE开发)中的“处处框架”编程模式,从那以后,大家开始习惯无侵入式的框架,代码中框架的痕迹越来越少。下面通过一个简单的Hello Word例子,给出J2EE代码与对应的Spring 代码的对比。
首先是J2EE代码:
//定义远程接口
public interface HelloworldRemote extends EJBObject {
String sayHello()throws RemoteException;
}
//定义本地接口
public interface HelloWorldHome extends EJBHome{
HelloWorldRemote create() throws RemoteException, CreateException; ?}
//Session Bean
public class HelloworldBean implements SessionBean {
public void setSessionContext (SessionContext arg0) throws EJBException,RemoteException {
}
public string sayHello() throws RemoteException[
return "Welecome to ejb ";
}
}
大家看到,在一个 Hello Word程序中整整写了3个类!还涉及 EJBObject、EJBHome、SessionContext、EJBException、RemoteException这5个框架的接口或类。如果用Spring框架,则全程无须引入 Spring的任何接口或类,只需编写如下简单代码:
public class HelloworldBean{
public String sayHello()
{
return "Welecome Spring ";}}
Spring框架之所以能实现这样神奇的简化,是因为其后有一个强大的设计模式在起作用,那就是代理模式(Proxy Pattern),而 Service Mesh的理念之所以能够完美实现,除了HTTP本身所具备的高度灵活性,在很大程度上归功于代理模式。代理模式的最大亮点是在保持现有(业务)代码完全不变的前提下,做到无入侵式的功能增强效果。如下所示是Service Mesh 中 SideCar代理的示意图。

由于采用了代理模式的设计实现思路,因此Service Mesh 与Spring框架一样,让我们实现了“无入侵”的编程开发,不同的是Spring框架面向Java,以单体架构或微服务的开发为主。
Service Mesh 则提供了与语言无关的分布式系统的架构方案,由于在我们的代码中不再包括Service Mesh 的任何API,所以在用了Service Mesh之后,所有的架构细节就都被隐藏在配置文件中,在源码中基本见不到任何与Service Mesh 架构相关的代码。
Service Mesh最早的开源版本是Linkerd,它最初采用了Scala,一经公布,就引发业界的广泛关注。随后谷歌、IBM 与Lyft(美国第二大打车公司,其愿景是让人们乘坐无人驾驶汽车出行)联手发布了Istio这个开源版本。Linkerd 在2.0版本中改为采用Rust和 Go后,性能和稳定性大幅提升,并且基于Kubernetes平台部署,但仍难抵Istio的优势。
Envoy 核心实践入门
Istio的核心毫无疑问是Envoy,本节针对Envoy做一些实践,以加深读者对Service Mesh原理的理解。
Envoy在本质上是一个(反向)HTTP代理服务器,抓住这个核心,我们就能很好地理解Envoy的配置、功能和使用方法了。
代理服务器的常规做法是在某个端口监听,并处理收到的请求。从编程角度来看,一般是通过可装配的filter链来实现各种代理功能的。此外,大部分反向HTTP代理服务器都实现了虚拟主机 (Virtual Host)的功能,因为虚拟主机的功能实现起来比较简单,只要具备基于 HTTP域名的路由转发功能即可。Envoy中的虚拟主机更接近Kubernetes Service的概念,其域名可以被视为Service的 DNS名称,转发路由(route)则对应Service的 Endpoints,即 Service后端的真实Pod地址列表(upstream),这个目标地址列表是一个“集合”地址,可能存在多个不同的Service对应同一个目标地址的情况。另外,在按照HTTP Path路由的情况下,多个不同的 Path也可能被路由到同一个目标地址,所以在Envoy中作者把这个集合地址单独抽出来,并命名为cluster对象,因此形成了如下 Envoy配置对象的拓扑结构。
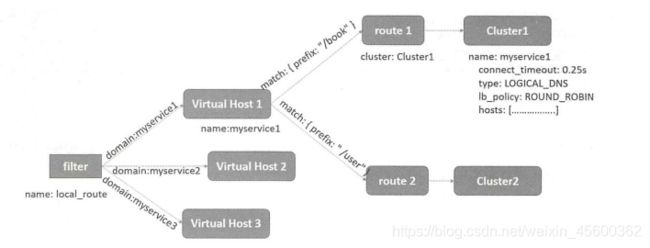
接下来,我们以一个最简单的例子来解释说明Envoy的配置文件和用法,在这个例子中,我们用Envoy创建一个到百度的反向代理服务器,在本地端口8080上监听,将收到的任何请求都转发到百度。完整的配置信息如下,其中的关键内容都用粗体字标明:
admin:
access_log_path: /tmp/admin_access. logaddress:
socket_address:{
address: 0.0.0.0, port_value:9901 }static resources:
listeners:
-name: listener0address:
socket address: {
address:0.0.0.0,port_value: 8080}filter chains:
-filters:
- name: envoy.http_connection_manager
config:
stat_prefix: ingress_httproute_config:
name: baidu_routevirtual hosts:
- name: baidu_ service
domains: [""*""]
routes:
-match: {
prefix:"/”"}
route: {
host_rewrite: www.baidu.com,cluster:
service baidu_cluster }
http filters:
-name: envoy .router
clusters:
name: service baidu_cluster
connect_timeout: 0.25stype: LOGICALDNS
lb poliey: ROUND_ ROBIN
hosts: [{
socket_address:{
address: baidu. com,port_value: 443 })]
tls_context: {
sni: www .baidu.com }
从上述配置来看,我们定义了一个名为 baidu_service的虚拟主机,它对应发往本机的任意HTTP请求(domains: ["*""]),然后只有一个路由(Prefix:"“ /”)。这个路由指向service_baidu_cluster这个Cluster,再找到它的定义,发现地址是百度的443端口,并采用了DNS地址轮询的简单负载均衡机制(type: LOGICAL_DNS,lb_policy: ROUND_ROBIN)来转发请求。我们将上述配置文件保存为/root/baidu-envoy.yaml,然后运行如下Docker命令,启动Envoy容器:
docker run -it -p 9901:9901 -p8080:8080 -v
/root/baidu-envoy.yaml :/etc/envoy/envoy.yml envoyproxy/envoy
上述9901端口为Envoy实例的管理端口,在打开浏览器访问此端口后,会出现下图所示的管理界面。
当我们访问8080端口时,会出现如下所示的百度界面,这就表明我们的第一个入门例子成功了。Envoy作为 https:/baidu.com这个服务的SideCar,成功实现了基本的服务代理和服务路由功能。
下面再介绍一个稍微复杂的例子,在这个例子中,我们来演示如何实现灰度发布中的“流量切分”功能。版本升级对应的发布过程通常非黑即白,即直接用新版本代替旧版本,如果验证成功就发布完成,如果失败就可能考虑补救或回滚到旧版本。对于传统的企业应用来说,按照发布计划,系统中断服务几个小时甚至十几个小时是可以接受的,但对于互联网应用来说,这是代价和影响很大的故障类事件,需要极力避免。因此就有了灰度发布。灰度发布也被称为金丝雀发布,不是非黑即白的部署方式,即在系统中同时存在一定比例的旧版本(黑色标记)及新版本(白色标记)的组件,“调色”的结果就是系统变成了“灰色”版本。
灰度发布是一个持续的过程,在一开始时,我们发布少量的新版本组件实例到系统中,并通过“流量切分”手段将一部分流量引向新版本来观察新版本的功能是否正常,如果新版本一切正常,则继续“切分”更多的流量到新版本中,再观察、切分,直到系统从“灰”变“白”。这与Kubernetes中的Pod副本滚动升级机制有相似之处,但在本质上不同:后者的目标是保证系统全自动“平滑”升级,并且在很短的时间内升级到最新版本;灰度发布则是一个人为控制的版本升级过程,通常需要花费更多时间来测试和观察新版本的可靠性。
如果你觉得自己学习效率低,缺乏正确的指导,可以加入资源丰富,学习氛围浓厚的技术圈一起学习交流吧!
[Java架构群]
群内有许多来自一线的技术大牛,也有在小厂或外包公司奋斗的码农,我们致力打造一个平等,高质量的JAVA交流圈子,不一定能短期就让每个人的技术突飞猛进,但从长远来说,眼光,格局,长远发展的方向才是最重要的。
在Kubernetes 的滚动升级中,我们无法手工控制新旧版本的流量切分,比如指定新版本获得10%的流量,但Envoy有这个功能,且使用起来很简单。我们将上述例子中 baidu_server这个虚拟主机服务的路由改为如下定义,即新旧版本的服务(对应 service_baidu_cluster_vl 与service_baidu_cluster_v2)各自获取50%的流量即可:
-match:{
prefix: "/"}
route:
host_rewrite: www . baidu .comweighted_clusters:
runtime key prefix: routing.traffic_split.baidu_serviceclusters:
name:service baidu cluster_v1
weight: 50
name:service baidu_cluster_v2
weight: 50
下面是新旧版本的两个服务对应的Cluster地址定义,可以注意到,我们故意将新版本(v2)的地址设置为不可访问,以方便观察流量切分的效果:
clusters:
- name: service_baidu_cluster_v1connect_timeout: 0.25s
type: LOGICAL_DNS
lb_policy: ROUND_ROBIN
hosts:[ socket_address:{
address: baidu.com, port_value:443HH]tls_context: {
sni: www.baidu.com }
-name: service baidu_cluster_v2
connect_timeout: 0.25stype: LOGICALDNS
lb_policy: ROUND ROBIN
hosts: [{
socket_address:{
address: baidu2.com,port_value: 443 }H]tls context: {
sni: baidu2.com }
我们在修改好配置文件后将其命名为
/root/baidu-envoy-split.yaml,重新启动新的测试容器:
docker run -it -p 9901:9901 -p 8080:8080 -v
/root/baidu-envoy-split.yaml:/etc/envoy/envoy.yaml envoyproxy/envoy
然后会有50%的概率在浏览器中看到如下信息:
no healthy upstream
这说明,流量切分功能生效。
以上实践的这些高级功能对于现有应用来说是无侵入的,没有修改和编写一行代码,只需写一些配置文件即可生效,这就是Service Mesh最吸引人的一个特点。当然,如果所有的Envoy实例都需要我们手工编写配置文件,则这又成了一个梦魇,Istio和其他Service Mesh产品的核心架构和主要功能之一就是解决这种“控制层面”的配置问题,并且尽量自动化,从架构设计的角度建模相关的配置对象,方便我们理解和正确定义这些配置信息。
lstio 背后的技术
我们都知道,Service Mesh架构的核心在于执行代理功能的SideCar,因为所有流量的转发都需要通过SideCar进行,并且在系统中会部署大量的SideCar实例,因此我们需要将SideCar设计成占用资源(内存、CPU)最少、转发性能最高,并且稳定性很高的守护进程。开发这样的网络服务器程序最考验编程经验和功底,开发难度和不确定性也最大。恰好Lyft公司已经有一个可以充当SideCar 的产品——Envoy,一个用C++开发的、高性能的分布式代理。
Istio的核心首推 Envoy,这点毫无疑问。除了Envoy,Istio还涉及哪些重要技术呢?
第一:基于数字证书的加密技术。
Istio的一个高级特性就是支持双向TLS认证,这使得我们开发的普通HTTP服务可以在互联网上被授权的合法用户((其他服务或客户端)安全访问,并且整个传输链路被加密,不存在数据被窃听的风险。以两个Service之间的访问为例,Istio里的双向安全加密机制的具体实现思路如下图所示。
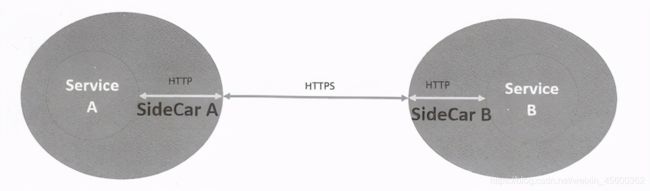
Service A在访问Service B的时候,出口流量仍然是普通的HTTP,这个流量被“劫持”到Service A对应的SideCar A进程上,注意到它们是被部署在同一台服务器中的,并没有跨越网络,因此是安全的。SideCar A在收到流量后,会与Service B对应的SideCar B建立起HTTPS安全连接,两者之间的传输通信就被加密传输。SideCar B在通过HTTPS 收到SideCar A发出来的加密数据报文后,再解密出明文数据,将其以普通的HTTP方式转发到Service B,此后ServiceB的应答数据也通过同样的处理流程返回到Service A。在整个过程中无须编写或修改业务代码,只需要一些简单的配置即可实现任意服务之间双向安全的TLS认证。看到这里,有人可能会问了,如果是一个普通的客户端而非某个Service’发起对另外一个Service的服务访问,而客户端进程并没有SideCar,应该如何解决? Istio的双向TLS提供了一个宽容模式(Permissive Mode),在该模式下允许Service同时接收普通非加密流量和双向 TLS 流量。
第二:分布式链路追踪技术。
对于大规模的分布式系统,特别是微服务化的互联网应用系统来说,分布式链路追踪技术变得越来越重要,因为在一个请求从用户浏览器发出到最后返回响应数据之前,这个调用链可能跨越了十几个服务进程(微服务实例及各类中间件、数据库),由于这些进程分别在不同的节点上,可能还是由不同的开发语言实现的,所以一旦某个调用链出现严重的性能问题或 Bug,想要排查问题的根源,就变得极为困难。
分布式链路追踪的核心,是标识、关联、记录每个链路的调用全过程。我们可以用‘Trace来表示一个调用链,在每个请求开始时都生成一个全局唯一的TraceID,并想办法将其传递到整个调用链,我们可以将调用链中的每一节都称为一个Span。为了排查性能和 Bug问题,还需要记录每个Span对应的调用方法名、花费的时长、是否抛出异常等关键信息。
我们以Java为例,先来分析一下解决分布式链路追踪问题的传统方法。首先在每个请求开始的时候都生成一个唯一的TraceID,这并不难,考虑到性能问题,使用业务流程名+时间戳(毫秒)+3位的随机数字即可,这是因为我们通常会采用采样的方法来追踪并生成相关的Trace 及记录,而不会对每一个请求都追踪记录,后者的代价很大,因此一般是通过采样来抽取部分请求进行分析的,采样频率一般是30秒/次。
在生成了TracelID 以后,接下来的问题就是如何将其传递下去了。Java里的传统方法是将TraceID放入ThreadLocal中保存,这样一来,在当前线程上运行的调用栈中的任何一个方法都可以从ThreadLocal 中获取TraceID,这意味着我们不用改变调用方法的签名来增加TraceID参数了,但在这样实现的时候仍有以下问题无法解决。
- 如果在调用过程中存在跨线程的情况,ThreadLocal方式就失效了。
- TraceID和上级SpanID等信息无法通过ThreadLocal传递到远程服务中,导致后继调用链条断裂,无法形成完整的调用链。
上述问题都是进程内的问题,但第二个问题很棘手:这是真正进入分布式领域的追踪链路调用,对此只有另想办法了。一般来说,我们在应用开发过程中所用到的远程访问,不外乎以下几种。
- HTTP调用(含REST、gRPC):HTTP 调用是主流,也是最常见和应用最广泛的微服务接口协议,还是各类分布式链路追踪系统主要解决的问题。对此,一般的做法是增加自定义Tracing 相关的自定义HTTP Header,比如x-trace-id.x-span-id,然后添加在HTTP请求报文中发出,服务端在收到请求报文后,再从Header中获取这些Tracing 信息,最后生成所需的Tracing数据。上述HTTP客户端和服务器端的逻辑都可以以某种通用化的方式实现。
- RPC调用(如Java RMI、ICE等):RPC调用则很难追踪,因为传统的RPC协议是特定化的TCP,并没有考虑到分布式追踪的需求,其报文是无法增加相关参数的,因此我们无法深入跟踪,在调用链中遇到一个RPC调用时,整个调用链被迫终止,除非我们在RPC 调用的业务接口中增加Tracing相关的参数,才能继续跟踪。
- 特定的TCP传输数据,比如各类中间件和数据库:该问题类似于RPC调用的问题,我们也只能跟踪到这里了。
如果你坚持探索下去,则还可能会发现更复杂的问题。
- Trace数据的保存问题。
- 如何直观展示完整的调用链和相关性能的统计结果。
事实证明,分布式链路追踪是一个相对专业、复杂的系统性的技术问题,每个分布式系统都会遇到这个问题,传统方法只能临时救急,不能一劳永逸地提供解决方案,因此这里应该有一个更加专业的、通用的解决方案。实际上,早在2010年,谷歌就发布了这个领域的经典论文Dapper - a Large-Scale Distributed Systems Tracing Infrastructure。2012年,Twitter紧跟着开源了知名的分布式链路追踪项目——Zipkin。为了更好地指导各个厂商开发相互兼容的分布式链路追踪产品,CNCF 基金会发布了开源分布式服务追踪标准——OpenTracing API规范。后来 Uber继续在Zipkin和谷歌论文的指导下,进一步完善了自己的分布式链路追踪系统并于2018年开源了Jaeger,这也是符合OpenTracing API规范的第一个开源系统。在Istio中默认支持的分布式链路追踪系统主要是Jaeger。
Jaeger 或Zipkin及其他类似软件的设计思路大体差不多,整个架构由以下几个核心组件组成。
- Client API &SDK:一般以某种方式嵌入用户的代码中,用来生成Tracing Data并发送给Agent。
- Agent:通常是一个独立于用户代码进程的TCP/UDP Server,通常被设计为两个端口,其中,UDP用来传输Tracing Data,TCP则用来传输指令。Agent 会把 Client 发来的数据做初步的汇聚后再发给Collector,Agent通常会部署多个实例,实例的数量通常取决于系统中的微服务实例数量。
- Collector:是一个独立的TCP/UDP进程,除了在内存中缓存一部分Tracing Data数据,也负责将历史数据持久化地写入后端数据库中保存。在部分系统的设计中,UI界面也会与Collector打交道,以获取实时数据。
- UI:是一个独立的Web进程,负责展示Tracing Data,主要以拓扑方式展示完整的调用链,并且提供基本的调用性能统计分析界面。
- Data Store:可以是任何具备持久存储数据的系统,Zipkin 默认采用Cassandra且内在支持ElasticSearch 及 MySQL存储,也可以扩展第三方存储。Jaeger在这方面并没有更多的改进。
下图是 Jaeger 的架构示意图。
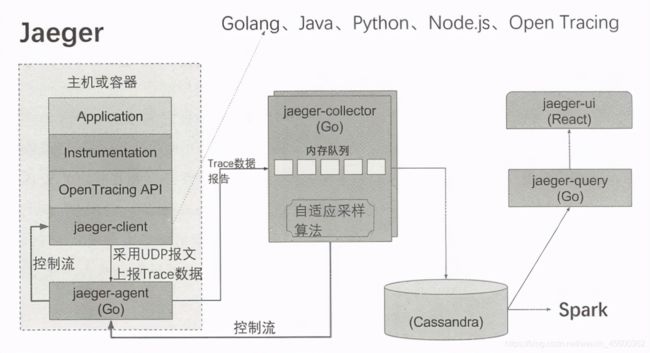
得益于SideCar这种 HTTP代理的设计思路,Service Mesh架构下的微服务很容易实现“全自动”的分布式链路追踪功能,具体做法就是请求开始时的Envoy实例自动生成TracingID 并将其填充到HTTP的Header字段x-request-id中,随后整个调用链中的每个Service实例对应的Envoy实例都自动从Header中获取 x-request-id的值,拦截调用过程,记录响应时间并生成所需的Tracing Data数据,最后调用Jaeger/Zipkin的API,完成调用链上所有Span的Tracing Data的记录,在整个过程中无须手工编写一行代码!
本节说说Istio中的另外一个复杂技术xDS。
在Service Mesh架构中的确实现了“业务系统中零架构代码”的“完美”,但代价是我们不得不写很多相关配置!以Istio为例,Envoy实现的所有代理功能,包括路由、流控、安全、遥测、分布式链路追踪都需要我们在配置文件中定义好规则和相关配置才能正常运行。而且这些配置写得是否正确,还没有智能的IDE来纠错和验证,我们还不能把这些陌生的配置文件甩给运维人员,因为这些配置基本都是与系统架构和研发相关的。考虑到系统中Envoy的实例数量非常多,在标准情况下与Service实例的数量一样多,因此我们需要一个“配置中心”来负责下发相关配置到每个 Envoy实例。Envoy中的配置项目都比较复杂,不是简单的 key/value 条目,而是一个个完整的配置对象,不同配置对象之间还经常存在引用关系,此外,绝大多数配置项都需要在系统运行期间做到“按需改变,立即生效”,因此如何设计 Envoy 与 Istio配置中心Pilot 之间的数据接口,成为一个复杂的问题,也成为Istio项目中原创的、最复杂的一部分设计与实现。
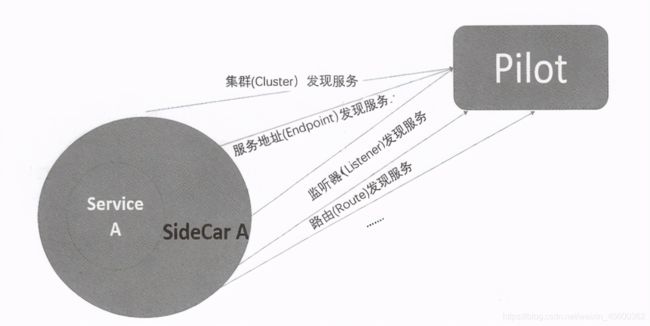
考虑到Envoy是用来代理Service的,首先要从配置中心获取在系统中定义的各种Service的信息,然后是Service相关的各种配置对象如 Cluster、Endpoint、Listener、router等,所以我们把 Envoy获取这些配置对象的过程称为“服务发现”也是理所应当的,于是这个接口就被命名为xDS接口。
xDS接口包括下面这些接口。
- CDS (Cluster Discovery Service):集群发现服务。
- EDS (Endpoint Discovery Service):端点发现服务。
- HDS (Health Discovery Service):健康发现服务。
- LDS (Listener Discovery Service):监听器发现服务。
- MS (Metric Service):将 metric推送到远端服务器。
- RLS (Rate Limit Service):速率限制服务。
- RDS (Route Discovery Service):路由发现服务。
- SDS (Secret Discovery Service):秘钥发现服务。
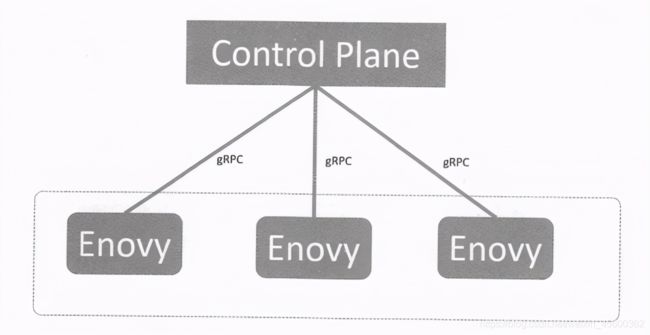
xDS的复杂性不在于接口数量是否多,而在于其设计和实现机制的复杂,最后引发了性能、全量下发与增量同步及最终一致性等诸多复杂问题。与我们的一般认识不同,xDS虽然是用来解决配置问题的,但没有沿用常规的设计思路,而是采用了类似于消息中间件中的消息订阅/推送模型,由于 Envoy中的每种配置对象都被视为一种独立的消息类型,所以Envoy实例会为每个不同的xDS资源类型都启动一个独立的双向 gRPC连接来实现对应的订阅通信,于是就形成如下所示的连接情况。
考虑到不同的配置对象因为有逻辑上的依赖关系而需要保证一定的处理顺序,所以有了如下重要规则:
- 如果有CDS更新消息,则必须始终先推送CDS更新;
- 如果有EDS 更新消息,则必须在相应集群的CDS更新消息后才能通知下发;
- LDS更新消息必须在相应的CDS/EDS更新消息后到达;
- 与新添加的LDS相关的RDS更新消息必须在最后到达;
- 最后,删除过期的 CDS集群和相关的 EDS 端点。
而对多个独立的 gRPC连接分别传输这些配置对象,则带来编程上的极大挑战,也对集群中的数据最终一致性带来难题。后来为此增加了新的ADS(聚合服务发现),可以将其理解为在一个gRPC通道上传输所有的xD对象,这样一来Pilot 与Envoy的代码实现就都简单多了。
此外,为了保证最终数据的一致性,在xDS接口中传输的配置对象数据中都增加了版本信息,以及一个辅助的随机加密的Nonce数据,防止通信过程中的“重放攻击”,增强了接口的安全性,这些都导致了xDS的复杂性。
其实,Envoy中的这些配置对象与 Kubernetes中的资源对象“高度相似”,而 Kubernetes集群所面临的资源对象的一致性问题要比Envoy集群中的问题更复杂,规模也更庞大。在笔者看来,如果直接使用Kubernetes成熟的设计来实现对Envoy配置对象的管理,则会大大降低Poliot与 Envoy在这方面的复杂性并提升运行效率,这里的最大阻力可能来自: Envoy采用C++开发,Kubernetes则采用Go开发,要想把Go中协程这种独特的机制在C++中模仿实现,可能比较难。
lstio的架构演变
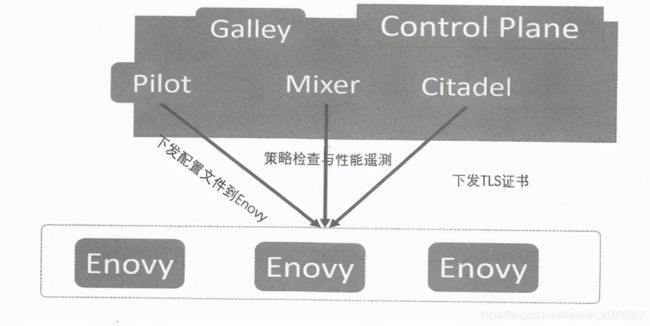
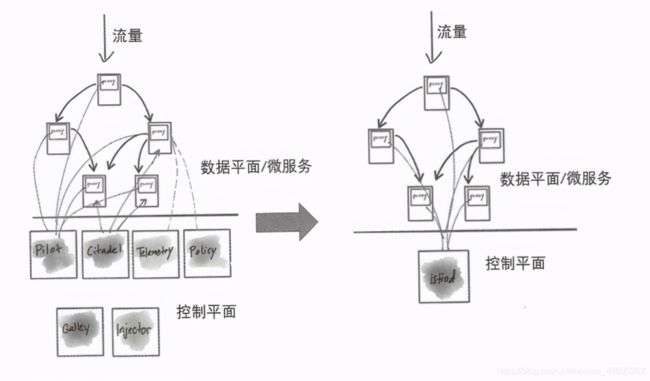
Istio的架构从总体上来说分为两个平面:数据平面(Data Plane)与控制平面(Control Plane),按照常规设计,应该是如下所示的架构。
实际上,Istio 1.0正式版的架构是下面这样的,控制平面被拆分为4个独立的微服务进程。
没错, Istio galley 组件的确是在Istio 1.0版本中出现的,因为Istio新增了50多种 KubernetesCRD (Custom Resource Definition)资源对象,比Kubernetes自身所有资源对象的种类加起来还要多很多。手工编写的这些CRD没有任何错误,一旦出现低级的配置错误,纠错的代价就太大了。为了保险起见,Istio 1.0一开始就提供了一个独立部署的Galley组件,Galley 组件实现了Kubernetes APl Server资源准入机制中的回调插件ValidatingWebhook接口,用来自动检查提交到Kubernetes集群中的Istio相关的CRD对象是否被正确定义。
在Istio 1.1中,Galley组件的功能被继续强化,新增了MCP(Mesh Configuration Protocol),用来将存储在Kubernetes中的Istio CRD资源对象(及其变化消息)传递到Istio的其他组件中,使得Istio 与Kubernetes的边界更加清晰(划清界限),这样看来,未来 Istio与Kubernetes深度融合的可能性并不大。如下所示是Istio 1.1的架构示意图。
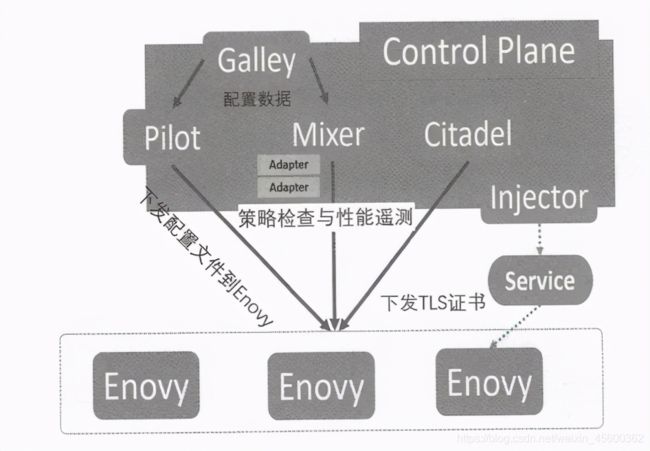
Istio 1.1还有一个重要的变化,就是Mixer进程分裂为核心本体与外围分身这两部分,变成多个相互独立的进程,这种设计完美遵循了开放封闭原则(Open Closed Principle)的设计准则,大大增加了架构的扩展性和隔离性,但进一步加剧了Mixer组件的性能问题,而性能问题一直是Service Mesh各类产品无法回避的“达摩克利斯之剑”,也是彼此相互竞争的重要指标之一。在上图中首次画出了Istio Injector组件,这个组件的作用是在普通的Kubernetes Service对应的Pod中自动注入Envoy容器的定义,使得这个Service成为Istio中一个标准的被SideCar包裹的网格Service,因为谁也不想自己手工编写如此复杂的YAML文件。在本质上,Istio Injector组件所做的事情就是修改符合条件的目标 Pod的资源定义,自动添加相应的Sidecar相关的容器定义,主要包括如下两个容器。
- 名为istio-init的 initContainer:通过配置iptables来劫持Pod 中的流量。
- 名为 istio-proxy 的 sidecar’容器:有两个进程pilot-agent和 envoy,pilot-agent进行初始化并启动envoy进程。
Istio自1.1版本之后,其架构就没有太大的变化了。我们看到,Istio这样一个不是很庞大的系统,其控制平面的功能竟然被分隔成了5个独立的微服务进程,而且怎么看都特别有道理!Istio的架构和功能演变看起来已经很完美了,但相对于Kubernetes平台越来越流行的事实来看,Istio无疑是失败的。Lyft公司的技术大咖、Envoy的发起者Matt Keiln曾在自己的Twitter 上表达自己对Service Mesh落地情况的失望:相对于轰轰烈烈的业界宣传及推广,来自最终用户的案例和提议是如此稀少。
是什么导致Istio这样的由经验丰富的IT巨头们共同发起的重量级的、功能全面的、架构优雅的Service Mesh产品最终落得个“曲高和寡”的尴尬境地?正应了那句古话——“成也萧何,败也萧何”,Istio最初成功吸睛的关键因素就是其“漂亮架构”,而过度追求“漂亮架构”也导致其系统过于复杂且大幅提高了应用落地的门槛,同时,过于追求松耦合的架构也导致Istio在性能方面存在不可忽视的缺陷。
Istio这样的产品与我们通常所开发的业务系统有很大的不同,作为基础性框架,它的功能相对集中,控制平台的很多功能都有很强的内在耦合关联性,为了架构的优雅而硬生生地将它们分离在不同的微服务进程中,现在看来的确是不合适的。此外,对于控制层面的很多功能来说,基本不存在水平扩容的需求,甚至一段时间的单点故障都是可以接受的,这样看来,将Istio控制层面复杂的“微服务架构”重新回归为简单的“单体架构”,可能是最好的解决方案。在2019年年底举办的 KubeCon大会上,Google API基础设施的首席工程师&架构师Louis Ryan透露:Istio社区正在考虑将Istio控制平面回归单体架构,计划从2020年初发布的Istio 1.5版本开始,将Istio原本的多个独立的组件整合成一个新的单体的 istiod进程。其内在原因是: Istio本身采用的微服务架构方式并没有为Service Mesh要实现的目标增加任何价值,相反,背离了它的初衷。
如下所示是Istio架构的微服务架构版与单体版的对比和区别,正对应了本节开头的讲解:在控制层面其实只需一个服务进程即可。
写在最后
最近我整理了整套《JAVA核心知识点总结》,说实话,作为一 名 Java 程序员,不论你需不需要面试都应该好好看下这份资料。拿到手总是不亏的~我的不少粉丝也因此拿到腾讯字节快手offer,点击下面图片↓直达领取
好了,以上就是本文的全部内容了,如果觉得有收获,记得三连,我们下期再见。