紧接着上回的文章,来书写一个Callback并演示一下爬虫吧。
实例分析
以一个实际的例子为主,即展示爬取一本小说为例子。
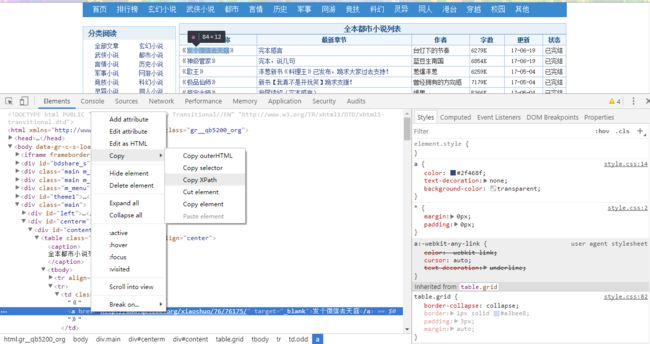
右键获取xpath
通过xpath的获取,就可以写下索引页面的callback函数,从而产生详情页的自定义Request,具体的事项请见上一回文章。
def qb5200_index_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是index函数
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
all_tr_tags = html.xpath('//div[@id="content"]//tr')
for tr_tag in all_tr_tags[:2]: # 请求一本小说,取前两个element,第一个是表格头,第二是小说
td_temp = tr_tag.xpath('./td[@class="odd"]')
if len(td_temp):
name = td_temp[0].xpath('./a/text()')[0]
url = td_temp[0].xpath('./a/@href')[0]
yield Request(
url, name=name, folder=name, pipeline=FolderPipeline,
title=name, callback=qb5200_detail_task, headers={'Referer': spider.url},
category=DETAIL
)
except Exception as e:
raise e
当抛出新的自定义Request后,管理器会将新的请求扔进Redis中,从而在下次的循环中弹出。
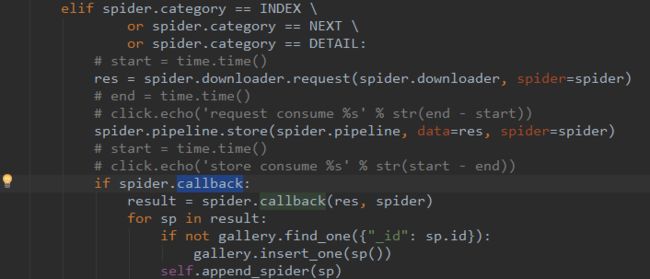
callback的结果处理

下轮循环弹出新的自定义Request
索引页的Callback创建完了,新生成的请求需要详情页的Callback来决定之后的请求走向。
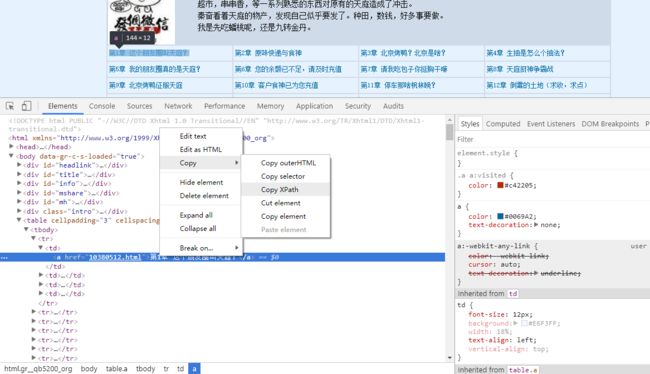
详情页的xpath
同样以第一本小说为例子,写下如下的详情页的Callback:
def qb5200_detail_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是detail函数
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
base_url = spider.url
all_td_tags = html.xpath('//table//td')
for td_tag in all_td_tags:
a_tag = td_tag.xpath('./a')
if len(a_tag):
title = a_tag[0].xpath('./text()')[0]
folder = title.replace('?', '?')\
.replace('!', '!')\
.replace('.', '。')\
.replace('*', 'x') # 去除创建文件时冲突的特殊字符
url = a_tag[0].xpath('./@href')
yield Request(
base_url + url[0], name=spider.name, folder=folder, pipeline=FilePipeline,
title=title, callback=qb5200_text_task, headers={'Referer': spider.url},
category=TEXT
)
except Exception as e:
raise e
注意category设置,这个将影响管理器处理这个请求的方式。TEXT代表了以文本的方式处理,在管理器中它会这样处理。
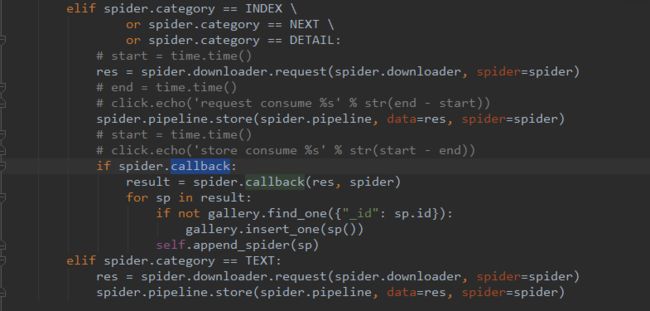
TEXT类别的处理
当然很好奇上述抛出的Request中明明定义了qb5200_text_task这个Callback函数,但是没有调用。这里是因为保持pipeline存储的第一个参数是Response对象,所以将内容的处理放到了pipeline里。
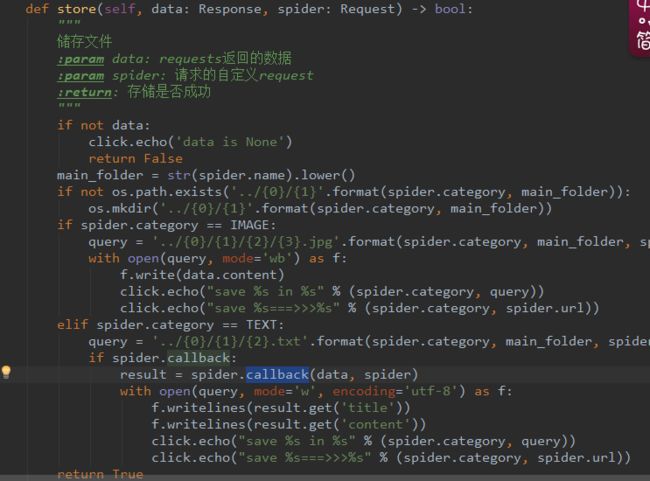
callback的调用处
同时放上最后的qb5200_text_task的代码:
def qb5200_text_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是真实数据请求函数,目前为针对于全本小说网的text文本
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
title_temp = html.xpath('//div[@id="title"]')
if len(title_temp):
title = title_temp[0].xpath('./text()')[0]
content_temp = html.xpath('//div[@id="content"]')
if len(content_temp):
content = content_temp[0].xpath('string(.)')
return {
"title": str(title),
"content": str(content)
}
except Exception as e:
raise e
最后启动运行初始代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : run.py
@Time : 2017/11/7 0007 20:40
@Author : Empty Chan
@Contact : [email protected]
@Description: 运行spider
"""
from downloader import HttpDownloader
from manager import Manager
from pipeline import ConsolePipeline
from request import Request
from tasks import qb5200_index_task
from utils import INDEX
if __name__ == '__main__':
'''定义初始的链接请求,初始化到manager中,然后run'''
req = Request("http://www.qb5200.org/list/3.html", name='qb5200', category=INDEX,
pipeline=ConsolePipeline, callback=qb5200_index_task,
downloader=HttpDownloader)
instance = Manager(req)
instance.run()
结果展示:
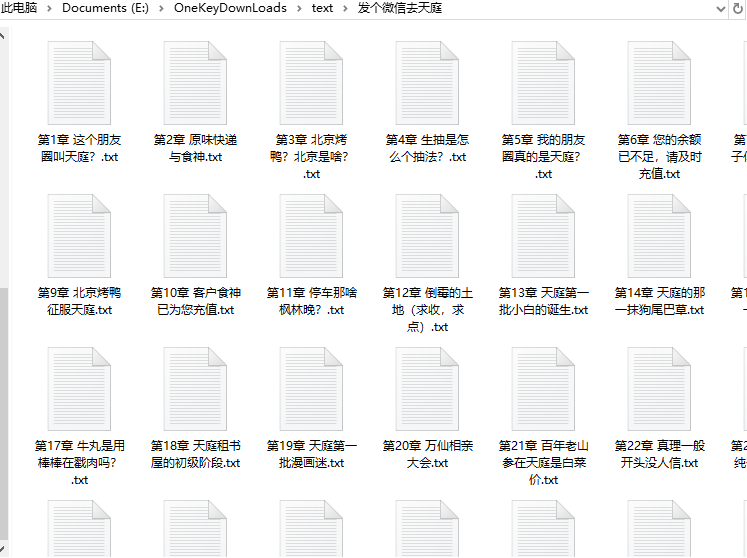
爬取完成一本
Callback全部代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@File : tasks.py
@Time : 2017/10/21 0021 19:27
@Author : Empty Chan
@Contact : [email protected]
@Description: 申明任务来执行callback, 且必须满足两个参数,一个为requests请求的返回值,一个是自定义的spider请求
"""
import json
import click
from requests import Response
from lxml import etree
import re
import abc
from log_util import Log
from request import Request
from pipeline import FolderPipeline, ConsolePipeline, FilePipeline
from pipeline import FilePipeline
from utils import TEXT, IMAGE, VIDEO, INDEX, NEXT, DETAIL
qb5200_index_pat = re.compile(r'.*(\d+).*', re.MULTILINE)
qb5200_logger = Log("qb5200")
def qb5200_index_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是index函数
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
all_tr_tags = html.xpath('//div[@id="content"]//tr')
for tr_tag in all_tr_tags[:2]: # 请求一本小说,取前两个element,第一个是表格头,第二是小说
td_temp = tr_tag.xpath('./td[@class="odd"]')
if len(td_temp):
name = td_temp[0].xpath('./a/text()')[0]
url = td_temp[0].xpath('./a/@href')[0]
yield Request(
url, name=name, folder=name, pipeline=FolderPipeline,
title=name, callback=qb5200_detail_task, headers={'Referer': spider.url},
category=DETAIL
)
except Exception as e:
raise e
def qb5200_detail_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是detail函数
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
base_url = spider.url
all_td_tags = html.xpath('//table//td')
for td_tag in all_td_tags:
a_tag = td_tag.xpath('./a')
if len(a_tag):
title = a_tag[0].xpath('./text()')[0]
folder = title.replace('?', '?')\
.replace('!', '!')\
.replace('.', '。')\
.replace('*', 'x')
url = a_tag[0].xpath('./@href')
yield Request(
base_url + url[0], name=spider.name, folder=folder, pipeline=FilePipeline,
title=title, callback=qb5200_text_task, headers={'Referer': spider.url},
category=TEXT
)
except Exception as e:
raise e
def qb5200_text_task(response: Response, spider: Request):
"""
自定义的任务callback函数,这里是真实数据请求函数,目前为针对于全本小说网的text文本
:param response: requests返回的数据
:param spider: 自定义的请求
:return: yeild出新的自定义Request
"""
html = etree.HTML(response.content.decode('gbk'))
try:
title_temp = html.xpath('//div[@id="title"]')
if len(title_temp):
title = title_temp[0].xpath('./text()')[0]
content_temp = html.xpath('//div[@id="content"]')
if len(content_temp):
content = content_temp[0].xpath('string(.)')
return {
"title": str(title),
"content": str(content)
}
except Exception as e:
raise e
有些东西写得不好,算是很基础的东西吧,希望后期能够完善一下。感谢大家阅读!!!
放上Github地址。
大家下回见~~