这个面试题会不定期进行整理,内容会采用无序的方式进行添加,但会根据时间来进行更新。
2018.06.13 更新
1.linux
题1:先来个难点的linux题,感觉这个题有点像考察运维的难度——计算IP Count。如题
某个目录下有两个文件a.txt和b.txt,文件格式为(ip username),例如:
a.txt
127.0.0.1 zhangsan
127.0.0.1 wangxiaoer
127.0.0.2 lisi
127.0.0.3 wangwu
b.txt
127.0.0.4 lixiaolu
127.0.0.1 lisi
每个文件至少有100万行,请使用linux命令行完成如下工作:
1)两个文件各自的ip数,以及总ip数
2)出现在b.txt而没有出现在a.txt的ip
3)每个username出现的次数,以及每个username对应的ip数
解1):首先我们看文件内容每一行的格式为(ip username),其中两个参数用空格号“ ”分开,这里我用awk来获取第一个参数的内容,然后用sort和uniq命令进行排序和去重,为了后面的第二次去重着想,我们把内容输出到ip_a.txt和ip_b.txt中,代码如下
awk -F ' ' '{print $1}' a.txt | sort | uniq > ip_a.txt
awk -F ' ' '{print $1}' b.txt | sort | uniq > ip_b.txt
结果如下:


由上可以看到已经成功筛选。
那么下一步,我们就是统计a.txt和b.txt文件中ip的数量,以及总ip的数量
我们定义a.txt和b.txt中ip的数量分别为变量ip_count_a和ip_count_b,而总ip数量为变量ip_count,然后用wc命令来统计文件中ip的数量,则最终统计的shell脚本如下:
#!/bin/bash
#两个文件各自的ip数,以及总ip数
ip_count_a=0
ip_count_b=0
ip_count=0
awk -F ' ' '{print $1}' a.txt | sort | uniq > ip_a.txt
awk -F ' ' '{print $1}' b.txt | sort | uniq > ip_b.txt
ip_count_a=$(wc -l < ip_a.txt)
ip_count_b=$(wc -l < ip_b.txt)
echo "a.txt文件的IP数为$ip_count_a"
echo "b.txt文件的IP数为$ip_count_b"
ip_count=$(cat ip_a.txt ip_b.txt | sort |uniq | wc -l)
echo "总IP数为$ip_count"
结果如下:

问题2)、3)待后续解
2.数据库MySQL
题目如下图:
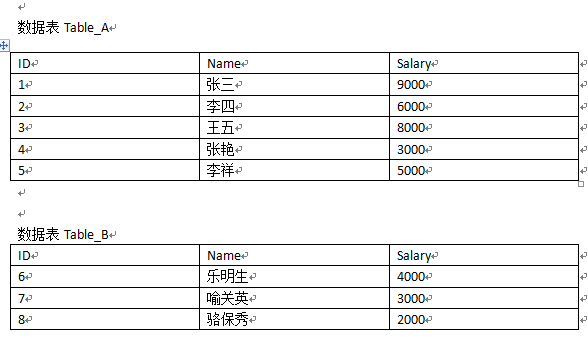
1).算出Table_A表中姓“张”的人员的平均薪资。
2).查询出两张表中Salary大于等于4000的所有人员Name和Salary。
3).如果用一句sql将Table_B表的数据插入Table_A表中。
4).写出一条sql语句:取出表Table_A中第31到第40的记录(SQLServer,以自动增长的ID,作为主键,注意:ID可能不是连续的,尽可能用多种思路)
在解题之前,因为我的数据库没有这些原始数据,需要先添加数据
添加Table_A数据
insert into table_a values(1,'张三',9000),(2,'李四',6000),(3,'王五',8000),(4,'张艳',3000),(5,'李祥',5000);
添加Table_B数据
mysql> insert into table_b (ID,Name,Salary) values (6,'乐明生',4000),(7,'喻关英'
,3000),(8,'骆保秀',2000);
然后我们查询一下Table_A
select * from table_a;
结果如下
+----+--------+--------+
| ID | Name | Salary |
+----+--------+--------+
| 1 | 张三 | 9000 |
| 2 | 李四 | 6000 |
| 3 | 王五 | 8000 |
| 4 | 张艳 | 3000 |
| 5 | 李祥 | 5000 |
+----+--------+--------+
5 rows in set (0.00 sec)
再查询一下Table_B
select * from table_b;
结果如下
+----+--------+--------+
| ID | Name | Salary |
+----+--------+--------+
| 1 | 张三 | 9000 |
| 2 | 李四 | 6000 |
| 3 | 王五 | 8000 |
| 4 | 张艳 | 3000 |
| 5 | 李祥 | 5000 |
+----+--------+--------+
5 rows in set (0.00 sec)
可见数据输入正确,接下来是解题:
问题1).算出Table_A表中姓“张”的人员的平均薪资。
解:
思路:这一题就是考察基本的mysql语句,select、from、where、like几个语句的结合使用,还有一个就是平均数函数avg的使用
select avg(Salary) from table_a where Name like '张%';
+-------------+
| avg(Salary) |
+-------------+
| 6000.0000 |
+-------------+
1 row in set (0.00 sec)
问题2).查询出两张表中Salary大于等于4000的所有人员Name和Salary。
解:
思路:这道可以分别查询Table_A和Table_B,然后把查询结果放到一起,其实就是考察union的使用
select Name,Salary from table_a where Salary >= 4000 union select Name,Salary from table_b where Salary >= 4000;
+-----------+--------+
| Name | Salary |
+-----------+--------+
| 张三 | 9000 |
| 李四 | 6000 |
| 王五 | 8000 |
| 李祥 | 5000 |
| 乐明生 | 4000 |
+-----------+--------+
5 rows in set (0.00 sec)
问题3).如果用一句sql将Table_B表的数据插入Table_A表中。
解:
思路:其实就是考察插入语句insert into的使用
insert into table_A select * from Table_B;
+----+-----------+--------+
| ID | Name | Salary |
+----+-----------+--------+
| 1 | 张三 | 9000 |
| 2 | 李四 | 6000 |
| 3 | 王五 | 8000 |
| 4 | 张艳 | 3000 |
| 5 | 李祥 | 5000 |
| 6 | 乐明生 | 4000 |
| 7 | 喻关英 | 3000 |
| 8 | 骆保秀 | 2000 |
+----+-----------+--------+
8 rows in set (0.00 sec)
也可以用以下语句实现,原理跟上面语句是一个意思
insert into table_a (id,name,salary) select id,name,salary from table_b;
+----+-----------+--------+
| ID | Name | Salary |
+----+-----------+--------+
| 1 | 张三 | 9000 |
| 2 | 李四 | 6000 |
| 3 | 王五 | 8000 |
| 4 | 张艳 | 3000 |
| 5 | 李祥 | 5000 |
| 6 | 乐明生 | 4000 |
| 7 | 喻关英 | 3000 |
| 8 | 骆保秀 | 2000 |
+----+-----------+--------+
8 rows in set (0.00 sec)
问题4).写出一条sql语句:取出表Table_A中第31到第40的记录(SQLServer,以自动增长的ID,作为主键,注意:ID可能不是连续的,尽可能用多种思路)
解:
思路:这题考察order by、记录条数限制limit和下标offset的使用,我的想法是这样的
select * from table_a order by id limit 10 offset 31;
+----+----------+--------+
| ID | Name | Salary |
+----+----------+--------+
| 53 | 张艳
| 3911 |
| 54 | 张艳
| 3912 |
| 55 | 张艳
| 3913 |
| 56 | 张艳
| 3914 |
| 57 | 张艳
| 3915 |
| 58 | 张艳
| 3916 |
| 59 | 张艳
| 3917 |
| 64 | 张艳
| 3918 |
| 65 | 张艳
| 3919 |
| 66 | 张艳
| 3920 |
+----+----------+--------+
10 rows in set (0.00 sec)