ANTLR3完全参考指南读书笔记[03]
前言
文中第4章内容有点多,有点枯燥,但不坚持一下,之前所做的工作就白做了。
再次确认一下总体目标:
protege4编辑器中Class Definition中语法解析和错误提示;
Java虚拟机规范7版中描述符和签名语法的解析器。
内容
按照文中章节组织,记录重要知识点。
这部分内容需要在后面的学习过程中回来再做理解。
4 ANTLR Grammars
4.1 Describing Languages with Formal Grammars
4.2 Overall ANTLR Grammar File Structure
4.3 Rules
4.4 Tokens Specification
4.5 Global Dynamic Attribute Scopes
4.6 Grammar Actions
4 ANTLR Grammars
4.1 Describing Languages with Formal Grammars
翻译器(translator)是将每个输入语句s映射为输出语句t的程序;这里的翻译器包含了编译器(compiler)和解释器(interpreter)的含义。
文法(grammar)是用于描述其他语言的DSL,又称元语言(metalanguage)。
最常用的文法标记是BNF(Backus-Naur-Form),EBNF作为BNF的扩展(iso 14977 EBNF翻译(http://blog.sina.com.cn/s/blog_9c88479d010197cw.html)),添加了可选(optional)和重复(repeated)元素。
EBNF标记的文法成为上下文无关文法(context-free grammmar, CFG)。
ANTLR通过语义谓词和句法谓词,支持上下文相关文法的识别器和翻译器生成。
4.2 Overall ANTLR Grammar File Structure
ANTLR支持的文法类型有:lexer, parser, tree和combined lexer and parser
文法结构
grammarType grammar name; <<optionSpec>> <<tokenSpec>> <<attributeScopes>> <<actions>> rule1 : ...|...|...; rule2 : ...|...|...;
文法词汇
comments: /**/, //,/***/
identifier: 词法规则名称全部大写,非词法规则名称以小写字符开始;只支持ASCII字符
literals:字符串以''表示,不支持非ASCII字符;ANTLR生成的识别器接收所有Unicode字符
actions:{}中以language选项一致的目标语言编写的代码块
templates:从翻译器中emit结构化文本时可以使用StringTemplate模板。需设置选项output=template。
两种方式:行内模板、另外定义的StringTemplate group
行内模板格式:单行("")、多行(<<>>),表示模板引用
4.3 Rules
规则的一般形式:
access-modifier rule-name[<<arguments>>] returns [<<return-values>>] <<throws-spec>> <<options-spec>> <<rule-attribute-scopes>> <<rule-actions>> : <<alternative-1>> -> <<rewrite-rule-1>> | <<alternative-2>> -> <<rewrite-rule-2>> ... | <<alternative-n>> -> <<rewrite-rule-n>> ; <<exception-spec>>
选择项中的元素
元素集合
'x'..'y':用于lexer规则,表征范围,x到y的任一字符
(A|B|...|C):用于parser或tree parser规则,任一token
('x'..'y'|'a'|...|'b'):用于lexer规则,任一字符
~x:用于任一类型规则,匹配不再x中的任一字符或token,这里x可以是单个元素、范围或子规则集合
元素标签(label)
动作通过标签引用文法中的规则、token或字符
标签的类型:Toke, <<rule>>_return
树操作符,均用于parser规则
T(Token), r(rule)
!: excluse, ^: 选择树的root
扩展的BNF子规则
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/4b98148f67114aa1953d8faeb626310c.png)
(<<x>>|<<y>>|<<z>>)
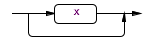
x?
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/5ff867d88a6c45afa2a50c60d4845106.png)
(<<x>>|<<y>>|<<z>>)?
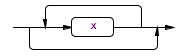
x*
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/5d8b8311fc7b4f3382d24de395ab2730.png)
(<<x>>|<<y>>|<<z>>)*
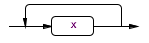
x+
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/99e9771888a94632a89a62f7f526d66d.png)
(<<x>>|<<y>>|<<z>>)+
<<...>>表示文法片段
子规则可以设置规则级选项
(options {<<>option-assignments>}): <<subrule-alternatives>>)
规则级选项
backtrack:设置为true时,LL(*)分析无法生成确定结果时,使用回溯。常与memoize选项一起使用,默认为true
memoize:回溯时,解析器记录部分解析结果,保证给定输入位置不会解析一条规则最多一次
k:启动LL(k)解析器,默认为*
greedy:最长匹配
在规则中嵌入规则
sample:
rule returns [int n] @init { $n =0; // init return value } @after { System.out.println("n=" + $n); } : ID {$n=23;} | WS {$n=24;} ;
规则参数和返回值
sample:
rule2[int a, String b] returns [int c, String d] : ID {$c=$a; $d=$b;} ;
ANTLR的parser和tree parser规则可以带参数和返回值,就像规则是方法一样;
但只有片段lexer规则(fragment lexer rule)可以携带参数。
规则引用Sample:
rule3 : v=rule2[3, "test"] {System.out.println($v.d);}
;
动态的规则属性作用域
规则可以定义在其引用规则中可见的属性
sample:
method @scope { String name; } : 'void' ID {$method::name = $ID.text;} '(' args ')' body ;
重写规则(rewrite rule)
为什么需要重写规则?在识别特定文法规则后,实施特定的操作,以生成内部表示(IR)。
通过设置output选项,ANTLR的解析器可以生成AST或StringTemplate模板。
所有文法规则都可以在动作中设置隐含的返回值。
重写规则以符号->开始。
sample:
unaryID : '-' ID -> ^('-' ID);
classDefinition
: 'class' ID ('extends' sup=typename)?
('implements' i+=typename (',' i+=typename)*)?
'{'
(varibaleDefinition|methodDefinition|ctorDefinition)*
'}'
-> ^('class' ID ^('extends' $sup)? ^('implements' $i+)?
varibaleDefinition* methodDefinition* ctorDefinition*);
构造AST时,重写规则是解析文法到树文法的映射。
生成模板时,重写规则描述创建的模板、以及模板中的placeholder属性。
规则异常处理
错误报告和恢复处理的方法。
sample:
rule_with_exception : expr_temp ; catch[FailedPredicateException e] {;} catch[RecognitionException e] {;} finally {;}
句法谓词
sample:
stat : (decl)=> decl ';'
| expr ';'
| 'return' expr ';'
| 'break' ';'
;
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/57cca9930d0b4004849c98a5996fe2de.png) //文法名称为T_template
//文法名称为T_template
替代方法:
stat options{backtrack=true;} : decl ';' | 'return' expr ';' | 'break' ';' | expr ';' ;
![ANTLR3完全参考指南读书笔记[03]](http://img.e-com-net.com/image/product/0944a30cd6f74c5d8037ae1b63b79e1f.jpg)
词法规则
片段词法规则
ANTLR要求所有的lexer规则必须描述一个有效的token,添加了fragment关键字的lexer规则不会提交一个token给解析器。
sample
UNICODE_CHAR : '\\' 'u' HEX_DIGIT HEX_DIGIT HEX_DIGIT; fragment HEX_DIGIT : '0'..'9'|'a'..'f'|'A'..'F';
前面提到ANTLR词法规则中只有片段词法规则可以携带参数
sample:
fragment CODE[boolean stripCurlies] : '{' CODE[stripCurlies] | ~('{'|'}')* '}' { if(stripCurlies) { setText(getText().subString(1, getText().length())); } } ;
channel和skip()
ANTLR运行token对象存在于不同的channel中,解析器会忽略不在其channel中的token
sample:
WS : (' '|'\t'|'\n'|'\r')+ {$channel=HIDDEN;};
skip动作会自动跳过匹配token,定位到下一token
sample:
WS : (' '|'\t'|'\n'|'\r')+ {skip();};
每条词法规则匹配时emit多个token
ANTLR词法规则允许手动调用emit()动作,一次提交多个token。
树匹配规则
在需要对输入流多次遍历时,可以采用解析器生成AST,再用某种tree walker或tree visitor遍历,或者用树文法(tree grammar)描述树的结构。
树文法规则同样可以携带参数和返回值,与其他规则不同的,其规则引用$T表示对节点T的指针引用。
4.4 Tokens Specification
用<<tokenSpec>>创建新的token类型或者创建token字面量的别名。
sample:
tokens{ VARDEF; MOD='%'; } var : type ID ';' -> ^(VARDEF type ID); expr : INT (MOD INT)*;
4.5 Global Dynamic Attribute Scopes
规则间引用通过参数传递和返回值完成,但在嵌套层次比较深时,极易生成复杂的代码。
全局作用域中定义的变量在所有规则中可见,唯一不同的是每个声明了引用该作用的规则使用的变量是识别器维护的stack中的变量,即每个规则用到变量是不同的。
sample:
scope SymbolScope { List symbols; } classDefinition scope SymbolScope; : 'class' ID ('extends' sup=typename)? ('implements' i+=typename (',' i+=typename)*)? '{' (varibaleDefinition|methodDefinition|ctorDefinition)* '}' -> ^('class' ID ^('extends' $sup)? ^('implements' $i+)? varibaleDefinition* methodDefinition* ctorDefinition*) ; methodDefinition scope SymbolScope; : WS ;
4.6 Grammar Actions
ANTLR提供了规则级动作(即由{}标识的动作)和命名动作,命名动作的语法为:
@action-name {...} //header, members
@action-scope-name::action-name {...} //action-scope-name可以是lexer, parser, treeparser