前言
本文为《Flask Web开发:基于Python的Web应用开发实战》第2版 的内容摘要
摘要
第 1 章:安装
Flask 自开发伊始就被设计为可扩展的框架,它具有一个包含基本服务的强健核心,其他功能则可通过扩展实现。
Flask 有 3 个主要依赖:路由、调试和 Web 服务器网关接口(WSGI,Web server gateway interface)子系统由 Werkzeug 提供;模板系统由 Jinja2 提供;命令行集成由 Click 提供。这些依赖全都是 Flask 的开发者 Armin Ronacher 开发的。
虚拟环境创建:
1.安装虚拟环境 virtualenv:
● Python3 标准库中的 venv 包原生支持虚拟环境:python3 -m venv venv
● Python2 需先安装第三方虚拟环境库:pip install virtualenv,然后创建虚拟环境:virtualenv venv
2.启动虚拟环境:
| System | Command |
|---|---|
| Linux | source venv/bin/activae |
| Windows | venv\Scripts\activate |
3. 退出虚拟环境:deactivate
第 2 章:应用的基本结构
Web 服务器(eg:Nginx)使用一种名为 Web 服务器网关接口(WSGI,Web server gateway interface,读作“wiz-ghee”)的协议,把接收自客户端的所有请求都转交给这个对象处理。
Flask 类的构造函数只有一个必须指定的参数,即应用主模块或包的名称。在大多数应用中,Python 的 name 变量就是所需的值(
app = Flask(__name__))。
传给 Flask 应用构造函数的 name 参数可能会让 Flask 开发新手心生困惑。其实 Flask 是用这个参数确定应用的位置,进而找到应用中其他文件的位置,例如图像和模板。客户端(例如 Web 浏览器)把请求发送给 Web 服务器,Web 服务器再把请求发送给 Flask 应用实例。应用实例需要知道对每个 URL 的请求要运行哪些代码,所以保存了一个 URL 到 Python 函数的映射关系。处理 URL 和函数之间关系的程序称为 路由。
- 将路由映射到的函数称为 视图函数。
比如,如下代码中的函数index即为视图函数:
# 使用装饰器模式定义路由
@app.router('/')
def index():
return 'Hello World
'
# 或者使用传统的方式 app.add_url_rule() 方法定义路由映射
def index():
return 'Hello World!
'
app.add_url_rule('/', 'index', index)
- Flask 支持在路由中使用 string、int、float 和 path 类型。
# 默认 string 类型
@app.route('/user/')
def user(name):
return 'Hello, {}!
'.format(name)
# int 类型
@app.route('/user/')
def user(id):
return 'num = {}
'.format(id)
注:path 类型是一种特殊的字符串,与 string 类型不同的是,它可以包含正斜线。
Flask 应用自带 Web 开发服务器,通过 flask run 命令启动。这个命令在 FLASK_APP 环境变量指定的 Python 脚本中寻找应用实例。Flask 提供的 Web 服务器只适用于开发和测试。
Flask 使用上下文临时把某些对象应用的基本结构变为全局可访问。有了上下文,便可以像下面这样编写视图函数:
from flask import request
@app.route('/')
def index():
user_agent = request.headers.get('User-Agent')
return 'Your browser is {}
'.format(user_agent)
注:在这个视图函数中我们把request当作全局变量使用。事实上,request不可能是全局变量。试想,在多线程服务器中,多个线程同时处理不同客户端发送的不同请求时,每个线程看到的request对象必然不同。Flask 使用上下文让特定的变量在一个线程中全局可访问,与此同时却不会干扰其他线程
- 在 Flask 中有两种上下文:应用上下文 和 请求上下文。
| 变量名 | 上下文 | 说明 |
|---|---|---|
| current_app | 应用上下文 | 当前应用的应用实例 |
| g | 应用上下文 | 处理请求时用作临时存储的对象,每次请求都会重设这个变量(单次请求时数据保存使用) |
| request | 请求上下文 | 请求对象,封装了客户端发出的 HTTP 请求中的内容 |
| session | 请求上下文 | 用户会话,值为一个字典,存储请求之间需要“记住”的值(跨请求时数据保存作用) |
- Flask请求对象(
request)具体内容:
| 属性或方法 | 说明 |
|---|---|
| form | 一个字典,存储请求提交的所有表单字段 |
| args | 一个字典,存储通过 URL 查询字符串传递的所有参数 |
| values | 一个字典,form 和 args 的合集 |
| cookies | 一个字典,存储请求的所有 cookie |
| headers | 一个字典,存储请求的所有 HTTP 首部 |
| files | 一个字典,存储请求上传的所有文件 |
| blueprint | 处理请求的 Flask 蓝图的名称; |
| endpoint | 处理请求的 Flask 端点的名称;Flask 把视图函数的名称用作路由端点的名称 |
| method | HTTP 请求方法,例如 GET 或 POST |
| scheme | URL 方案(http 或 https) |
| host | 请求定义的主机名,如果客户端定义了端口号,还包括端口号 |
| path | URL 的路径部分 |
| query_string | URL 的查询字符串部分,返回原始二进制值 |
| full_path | URL 的路径和查询字符串部分 |
| url | 客户端请求的完整 URL |
| base_url | 同 url,但没有查询字符串部分 |
| remote_addr | 客户端的 IP 地址 |
| environ | 请求的原始 WSGI 环境字典 |
| get_data() | 返回请求体缓冲的数据 |
| get_json() | 返回一个 Python 字典,包含解析请求体后得到的 JSON |
| is_secure() | 通过安全的连接(HTTPS)发送请求时返回 True |
- ▲ 请求钩子:处理请求之前或之后执行的代码。
请求钩子通过装饰器实现。Flask 支持以下 4 种钩子。
| name | description |
|---|---|
| before_request | 注册一个函数,在每次请求之前运行。 |
| before_first_request | 注册一个函数,只在处理第一个请求之前运行。可以通过这个钩子添加服务器初始化任务。 |
| after_request | 注册一个函数,如果没有未处理的异常抛出,在每次请求之后运行。 |
| teardown_request | 注册一个函数,即使有未处理的异常抛出,也在每次请求之后运行。 |
注:在请求 钩子函数 和 视图函数 之间 共享数据 一般使用 上下文全局变量g。例如,before_request 处理程序可以从数据库中加载已登录用户,并将其保存到g.user中。随后调用视图函数时,便可以通过g.user获取用户。
- Flask 视图函数还可以返回一个响应对象(
make_response)。
from flask import make_response
@app.route('/')
def index():
response = make_response('This document carries a cookie!
')
response.set_cookie('answer', '42')
return response
其中,响应对象最常使用的属性和方法如下表所示:
| 属性或方法 | 说明 |
|---|---|
| status_code | HTTP 数字状态码 |
| headers | 一个类似字典的对象,包含随响应发送的所有首部 |
| content_length | 响应主体的长度 |
| content_type | 响应主体的媒体类型 |
| set_cookie() | 为响应添加一个 cookie |
| delete_cookie() | 删除一个 cookie |
| set_data() | 使用字符串或字节值设定响应 |
| get_data() | 获取响应主体 |
注:响应有个特殊的类型,称为重定向。重定向的状态码通常是 302,在 Location 首部中提供目标 URL。Flask 提供了redirect()辅助函数,用于生成这种重定向响应:
//手动构建重定向响应
from flask import make_response
@app.route('/')
def index():
response = make_response()
response.status_code = 302
response.headers['Location'] = r'http://www.example.com'
return response
//使用 Flask 提供的重定向辅助功能,更加简单直接
from flask import redirect
@app.route('/')
def index():
return redirect('http://www.example.com')
还有一种特殊的响应由abort()函数生成,用于处理错误。在下面这个例子中,如果 URL中动态参数 id 对应的用户不存在,就返回状态码 404:
from flask import abort
@app.route('/user/')
def get_user(id):
user = load_user(id)
if not user:
abort(404)
return 'Hello, {}
'.format(user.name)
注意,abort() 不会把控制权交还给调用它的函数,而是抛出异常。
第 3 章:模板
模板 是包含响应文本的文件,其中包含用占位变量表示的动态部分,其具体值只在请求的上下文中才能知道。使用真实值替换变量,再返回最终得到的响应字符串,这一过程称为渲染。为了渲染模板,Flask 使用一个名为 Jinja2 的强大模板引擎。
注:可认为 模板 就是 html 文件,只是内部使用占位符标识动态部分内容,在请求时进行真实内容替换。形式最简单的 Jinja2 模板就是一个包含响应文本的文件。
Hello World!
当然,模板通常是会带有占位符表示动态内容:
Hello, {{ name }}!
默认情况下,Flask 在应用目录中的 templates 子目录里寻找模板。
Jinja2 能识别所有类型的变量,甚至是一些复杂的类型,例如列表、字典和对象。
A value from a list: {{ mylist[3] }}.
A value from a dictionary: {{ mydict['key'] }}.
A value from a list, with a variable index: {{ mylist[myintvar] }}.
A value from an object's method: {{ myobj.somemethod() }}.
- Jinja2变量过滤器:可以修改变量的值。
如过滤器Hello, {{ name|capitalize }}把 name 变量的值变成首字母大写的形式。
注:下表是 Jinja2 提供的部分常用过滤器:
| name | description |
|---|---|
| safe | 渲染值时不转义 |
| capitalize | 把值的首字母转换成大写,其他字母转换成小写 |
| lower | 把值转换成小写形式 |
| upper | 把值转换成大写形式 |
| title | 把值中每个单词的首字母都转换成大写 |
| trim | 把值的首尾空格删掉 |
| striptags | 渲染之前把值中所有的 HTML 标签都删掉 |
注:safe 过滤器值得特别说明一下。默认情况下,出于安全考虑,Jinja2 会转义所有变量。例如,如果一个变量的值为 '
Hello
',Jinja2 会将其渲染成 '<h1>Hello</h1>',浏览器能显示这个 h1 元素,但不会解释它。很多情况下需要显示变量中存储的 HTML 代码,这时就可使用 safe 过滤器。完整的过滤器列表可查看:builtin-filters
- Jinja2 提供了多种控制结构,可用来改变模板的渲染流程。以下是较常用的一些控制结构:
{% if user %}
Hello, {{ user }}!
{% else %}
Hello, Stranger!
{% endif %}
{% for comment in comments %}
- {{ comment }}
{% endfor %}
{% block head %}
{% block title %}{% endblock %} - My Application
{% endblock %}
{% block body %}
{% endblock %}
{% extends "base.html" %}
{% block title %}Index{% endblock %}
{% block head %}
{{ super() }}
{% endblock %}
{% block body %}
Hello, World!
{% endblock %}
- 自定义错误页面:像常规路由一样,Flask 允许应用使用模板自定义错误页面。最常见的错误代码有两个:
404:客户端请求未知页面或路由时显示;
500:应用有未处理的异常时显示。
Flask 中可以使用app.errorhandler装饰器为这两个错误提供自定义的处理函数。
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
- 使用 Flask-Moment 本地化日期和时间:通常 Web 应用的用户来自世界各地,为了能正确处理日期和时间,服务器需要统一时间单位,以保证结果和用户所在的地理位置无关,所以一般使用协调世界时(UTC,coordinated universal time)。但 UTC 时间不易于观看,用户更希望能看到当地时间,而且采用当地惯用的格式。因此一个优雅的解决方案为:在服务器上只使用 UTC 时间,然后请求时,把时间单位发送给 Web 浏览器,让其自己转换成当地时间,然后用 JavaScript 渲染。Web 浏览器可以更好地完成这一任务,因为它能获取用户计算机中的时区和区域设置。
有一个使用 JavaScript 开发的优秀客户端开源库,名为 Moment.js,它可以在浏览器中渲染日期和时间。Flask-Moment 是一个 Flask 扩展,能简化把 Moment.js 集成到 Jinja2 模板中的过程。
Flask-Moment 快速使用方法如下:
1. 初始化扩展
from flask_moment import Moment
moment = Moment(app)
2. 增加 moment.js 和 jQuery 依赖
{{ moment.include_jquery() }}
{{ moment.include_moment() }}
注:如果项目本身已存在 jQuery 依赖,则可以移除引入moment.include_jquery()
3. 在模板中渲染时间戳
The current date and time is: {{ moment().format('MMMM Do YYYY, h:mm:ss a') }}.
Something happened {{ moment(then).fromTime(now) }}.
{{ moment(then).calendar() }}.
The local date and time is {{ moment(now).format('LLL') }}.
That was {{ moment(now).fromNow(refresh=True) }}
注:模板参数中的变量then和now必须是 Python datetime的实例(now = datetime.utcnow())
第 4 章:Web表单
- Flask 请求对象包含客户端在请求中发送的全部信息,对包含表单数据的 POST 请求来说,用户填写的信息通过
request.form访问。也可以使用插件 flask-wtf 使表单操作更加简单。
flask-wtf 这个扩展对独立的 WTForms 包进行了包装,方便集成到 Flask 应用中。
与其他多数扩展不同,flask-wtf 无须在应用层初始化,但是它要求应用配置一个 密钥。密钥是一个由随机字符构成的唯一字符串,通过加密或签名以不同的方式提升应用的安全性。Flask 使用这个密钥保护用户会话,以防被篡改。每个应用的密钥应该不同,而且不能让任何人知道。
app = Flask(__name__)
app.config['SECRET_KEY'] = 'hard to guess string'
flask-wtf 之所以要求应用配置一个密钥,是为了防止表单遭到跨站请求伪造(CSRF,cross-site request forgery)攻击。恶意网站把请求发送到被攻击者已登录的其他网站时,就会引发 CSRF 攻击。flask-wtf 为所有表单生成安全令牌,存储在用户会话中。令牌是一种加密签名,根据密钥生成。
注:为了增强安全性,密钥不应该直接写入源码,而要保存在环境变量中。
- 使用 flask-wtf 时,在服务器端,每个 Web 表单都由一个继承自 FlaskForm 的类表示。这个类定义表单中的一组字段,每个字段都用对象表示。字段对象可附属一个或多个验证函数。验证函数用于验证用户提交的数据是否有效。
from flask_wtf import FlaskForm
from wtforms import StringField, SubmitField
from wtforms.validators import DataRequired
# 代表一个 form 表单
class NameForm(FlaskForm):
# 代表一个 对象,其lable为 'What is your name',数据必须存在
name = StringField('What is your name?', validators=[DataRequired()])
# 代表一个 对象
submit = SubmitField('Submit')
NameForm 表单中有一个名为 name 的文本字段和一个名为 submit 的提交按钮。
其中:
- WTForms 支持的 HTML 标准字段 如下表所示:
| 字段类型 | 说明 |
|---|---|
| BooleanField | 复选框,值为 True 和 False |
| DateField | 文本字段,值为 datetime.date 格式 |
| DateTimeField | 文本字段,值为 datetime.datetime 格式 |
| DecimalField | 文本字段,值为 decimal.Decimal |
| FileField | 文件上传字段 |
| HiddenField | 隐藏的文本字段 |
| MultipleFileField | 多文件上传字段 |
| FieldList | 一组指定类型的字段 |
| FloatField | 文本字段,值为浮点数 |
| FormField | 把一个表单作为字段嵌入另一个表单 |
| IntegerField | 文本字段,值为整数 |
| PasswordField | 密码文本字段 |
| RadioField | 一组单选按钮 |
| SelectField | 下拉列表 |
| SelectMultipleField | 下拉列表,可选择多个值 |
| SubmitField | 表单提交按钮 |
| StringField | 文本字段 |
| TextAreaField | 多行文本字段 |
- WTForms 内建的 验证函数 如下表所示:
| 验证函数 | 说明 |
|---|---|
| DataRequired | 确保转换类型后字段中有数据 |
| 验证电子邮件地址 | |
| EqualTo | 比较两个字段的值;常用于要求输入两次密码进行确认的情况 |
| InputRequired | 确保转换类型前字段中有数据 |
| IPAddress | 验证 IPv4 网络地址 |
| Length | 验证输入字符串的长度 |
| MacAddress | 验证 MAC 地址 |
| NumberRange | 验证输入的值在数字范围之内 |
| Optional | 允许字段中没有输入,将跳过其他验证函数 |
| Regexp | 使用正则表达式验证输入值 |
| URL | 验证 URL |
| UUID | 验证 UUID |
| AnyOf | 确保输入值在一组可能的值中 |
| NoneOf | 确保输入值不在一组可能的值中 |
- 创建了表单对象后,可在在模板中调用该对象渲染成 HTML。
app = Flask(__name__)
app.config['SECRET_KEY'] = '1234567'
class NameForm(FlaskForm):
name = StringField('What is your name?', validators=[DataRequired()])
submit = SubmitField('Submit')
@app.route('/form/', methods=['GET', 'POST'])
def register():
form = NameForm()
if form.validate_on_submit():
name = form.name.data
print('name=%s' % name) # 输出接收的名称内容
return redirect('/') # 注册完成,重定向到首页
return render_template('form.html', form=form)
@app.route('/')
def index():
return 'Hello Flask
'
Form
视图函数register中,第一次访问路由/form/时,使用GET方法,则此时会创建一个自定义的 Form 表单NameForm实例,并交给到模板form.html中进行渲染,客户端就能得到一个表单页面。然后客户端提交表单(POST)后,视图函数register内部依据提交的内容构建出一个NameForm实例,然后提交的数据如果能被所有验证函数验证通过,那么validate_on_submit()返回True,进入注册流程。
- 应用提交 POST 请求时,通常完成后都会重定向到另一个页面。如果另一个页面也需要改 POST 提交的数据,则由于 POST 请求与重定向请求是两次HTTP请求,POST 请求提交的数据在重定向后就消失了,因此需要借助 用户会话(session),以便在请求之间“记住”数据。用户会话是一种私有存储,每个连接到服务器的客户端都可访问。
@app.route('/', methods=['GET', 'POST'])
def index():
form = NameForm()
if form.validate_on_submit():
session['name'] = form.name.data
return redirect(url_for('index'))
return render_template('index.html', form=form, name=session.get('name'))
注:默认情况下,用户会话保存在客户端 cookie 中,使用前面设置的密钥加密签名。如果篡改了 cookie 的内容,签名就会失效,会话也将随之失效。
- 浏览器刷新机制:浏览器刷新页面时,会重新发送之前最后一次请求。因此,最好别让 Web 应用把 POST 请求作为浏览器发送的最后一个请求(因为会重发 POST 请求,此时浏览器会弹出确认框)。因此,通常对于 POST 请求的结果都是使用 重定向 作为响应(重定向后,最后一次请求变成 GET 请求),而不是使用常规响应。这个技巧称为 Post / 重定向 /Get 模式
第 5 章:数据库
Flask-SQLAlchemy 是一个 Flask 扩展,简化了在 Flask 应用中使用SQLAlchemy 的操作。SQLAlchemy 是一个强大的关系型数据库框架,支持多种数据库后台。SQLAlchemy 提供了高层 ORM,也提供了使用数据库原生 SQL 的低层功能。
在 Flask-SQLAlchemy 中,数据库使用 URL 指定。几种最流行的数据库引擎使用的 URL 格式如下表所示:
| 数据库引擎 | URL |
|---|---|
| MySQL | mysql://username:password@hostname/database |
| Postgres | postgresql://username:password@hostname/database |
| SQLite | (Linux,macOS) sqlite:////absolute/path/to/database |
| SQLite | (Windows) sqlite:///c:/absolute/path/to/database |
注:应用使用的数据库 URL 必须保存到 Flask 配置对象的 SQLALCHEMY_DATABASE_URI 键中。Flask-SQLAlchemy 文档还建议把 SQLALCHEMY_TRACK_MODIFICATIONS 键设为 False,以便在不需要跟踪对象变化时降低内存消耗。
import os
from flask_sqlalchemy import SQLAlchemy
basedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] =\
'sqlite:///' + os.path.join(basedir, 'data.sqlite')
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
- 模型 这个术语表示应用使用的持久化实体。在 ORM 中,模型一般是一个 Python 类,类中的属性对应于数据库表中的列。
# flask-sqlalchemy 创建的表需默认继承 db.Model
class User(db.Model):
# 表名
__tablename__ = 'users'
# 列 id
id = db.Column(db.Integer, primary_key=True)
# 列 username
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return '' % self.username
注:db.Column类构造函数的第一个参数是数据库列和模型属性的类型。下表列出了一些可用的列类型以及在模型中使用的 Python 类型:
| 类型名 | Python类型 | 说明 | |
|---|---|---|---|
| Integer | int | 普通整数,通常是 32 位 | |
| SmallInteger | int | 取值范围小的整数,通常是 16 位 | |
| BigInteger | int 或 long | 不限制精度的整数 | |
| Float | float | 浮点数 | |
| Numeric | decimal.Decimal | 定点数 | |
| String | str | 变长字符串 | |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 | |
| Unicode | unicode | 变长 Unicode 字符串 | |
| UnicodeText | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 | |
| Boolean | bool | 布尔值 | |
| Date | datetime.date | 日期 | |
| Time | datetime.time | 时间 | |
| DateTime | datetime.datetime | 日期和时间 | |
| Interval | datetime.timedelta | 时间间隔 | |
| Enum | str | 一组字符串 | |
| PickleType | 任何 | Python 对象 自动使用 Pickle 序列化 | |
| LargeBinary | str | 二进制 blob |
下表是最常用的 SQLAlchemy 列选项:
| 选项名 | 说明 |
|---|---|
| primary_key | 如果设为 True,列为表的主键 |
| unique | 如果设为 True,列不允许出现重复的值 |
| index | 如果设为 True,为列创建索引,提升查询效率 |
| nullable | 如果设为 True,列允许使用空值;如果设为 False,列不允许使用空值 |
| default | 为列定义默认值 |
- 关系型数据库使用关系把不同表中的行联系起来。关系在 Sqlalchemy 中在模型类中的表示方法如下面代码所示:假设现有两张表,user(用户) 和 role(角色)。其中,user 表内有一个指向 role 表的外键 role_id。role 表代表用户角色。两者呈现一个多对一关系:一个用户对应一个角色,一个角色可以对应多个用户。
class Role(db.Model):
# ...
users = db.relationship('User', backref='role')
class User(db.Model):
# ...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
关系使用 users 表中的外键 role_id 连接两行。其中:
1.传给db.ForeignKey()的参数roles.id表明,这列的值是 roles 表中相应行的 id 值。
2.db.relationship()第一个参数表明这个关系的另一端是哪个模型(这里即为 roles 表与 user 表建立关系,User表实例内含有 roles 相关信息)。
3.db.relationship()中的backref参数向 User 模型中添加一个 role 属性,从而定义反向关系。通过 User 实例的这个属性可以获取对应的 Role 模型对象,而不用再通过 role_id 外键获取(User().role)。
注:多数情况下,db.relationship()都能自行找到关系中的外键,但有时却无法确定哪一列是外键。例如,如果 User 模型中有两个或以上的列定义为 Role 模型的外键,SQLAlchemy 就不知道该使用哪一列。如果无法确定外键,就要为db.relationship()提供额外的参数。下表列出了定义关系时常用的配置选项:
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一个模型中添加反向引用 |
| primaryjoin | 明确指定两个模型之间使用的联结条件;只在模棱两可的关系中需要指定 |
| lazy | 指定如何加载相关记录,可选值有 select(首次访问时按需加载)、immediate(源对象加载后就加载)、joined(加载记录,但使用联结)、subquery(立即加载,但使用子查询),noload(永不加载)和 dynamic(不加载记录,但提供加载记录的查询) |
| uselist | 如果设为 False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关联表的名称 |
| secondaryjoin | SQLAlchemy 无法自行决定时,指定多对多关系中的二级联结条件 |
注:一对一关系可以用前面介绍的一对多关系表示,但调用db.relationship()时要把uselist设为False,把“多”变成“一”。
更多其他内容,请参考:Flask-SQLAlchemy 基本使用
- 更新表 推荐的方法是使用数据库迁移框架。源码版本控制工具可以跟踪源码文件的变化;类似地,数据库迁移框架能跟踪数据库模式的变化,然后以增量的方式把变化应用到数据库中。Flask 中推荐使用 Flask-Migrate 扩展。该扩展是对 Alembic 的轻量级包装,并与 flask 命令做了集成。
Flask-Migrate 的大致使用方法如下:
- 代码添加 Migrate:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///app.db'
db = SQLAlchemy(app)
migrate = Migrate(app, db)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(128))
首先使用
flask db init添加数据库迁移支持。命令运行成功后会创建 migrations 目录,所有迁移脚本都存放在这里(注意FLASK_APP需先进行设置)。对模型类做必要的修改。
执行
flask db migrate命令,自动创建一个迁移脚本。检查自动生成的脚本,根据对模型的实际改动进行调整。
执行
flask db upgrade命令,把迁移应用到数据库中。后续模型类更改时,重新执行
migrate和upgrade命令即可。如果想回滚迁移,则执行
flask db downgrade。
第 7 章:大型应用的结构
- Flask 应用的基本组织结构如下图所示:

这种结构有 4 个顶级文件夹:
• Flask 应用一般保存在名为 app 的包中;
• 和之前一样,数据库迁移脚本在 migrations 文件夹中;
• 单元测试在 tests 包中编写;
• 和之前一样,Python 虚拟环境在 venv 文件夹中。
此外,这种结构还多了一些新文件:
• requirements.txt 列出了所有依赖包,便于在其他计算机中重新生成相同的虚拟环境;
• config.py 存储配置;
• flasky.py 定义 Flask 应用实例,同时还有一些辅助管理应用的任务。
- 在单脚本应用中,应用实例存在于全作用域中,路由可以直接使用
app.route装饰器定义。但如果现在应用在运行时创建,那么就只有在运行创建后才能使用app.route装饰器,这时定义路由就太晚了。自定义的错误页面处理程序也面临相同的问题,因为错误页面处理程序使用app.errorhandler装饰器。针对这个问题,Flask 为我们提供了一个更好地解决方案:蓝图(blueprint)。蓝图和应用类似,也可以定义路由和错误处理程序。不同的是,在蓝图中定义的路由和错误处理程序处于休眠状态,直到蓝图注册到应用上之后,它们才真正成为应用的一部分。使用位于全局作用域中的蓝图时,定义路由和错误处理程序的方法几乎与单脚本应用一样。
from flask import Blueprint
main = Blueprint('main', __name__) # 创建一个蓝图对象
def createApp(): # 运行时创建应用实例
app = Flask(__name__)
return app
@main.route('/index/'): # 蓝图路由
def index():
return 'Using Blueprint to reigster route
'
if __name__ == '__main__':
app = createApp()
app.register_blueprint(main) # 注册到应用上,使能蓝图路由
- 在蓝图中编写错误处理程序稍有不同,如果使用
errorhandler装饰器,那么只有蓝图中的错误才能触发处理程序。要想注册应用全局的错误处理程序,必须使用app_errorhandler装饰器:
from . import main
from flask import render_template
@main.app_errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
@main.app_errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
在单脚本应用中,
index()视图函数的 URL 可使用url_for('index')获取。在蓝图中就不一样了,Flask 会为蓝图中的全部端点加上一个命名空间,这样就可以在不同的蓝图中使用相同的端点名定义视图函数,而不产生冲突。命名空间是蓝图的名称(Blueprint 构造函数的第一个参数),而且它与端点名之间以一个点号分隔。因此,视图函数index()注册的端点名是main.index,其 URL 使用url_for('main.index')获取。url_for()函数还支持一种简写的端点形式,在蓝图中可以省略蓝图名,例如url_for('.index')。在这种写法中,使用当前请求的蓝图名补足端点名。这意味着,同一蓝图中的重定向可以使用简写形式,但跨蓝图的重定向必须使用带有蓝图名的完全限定端点名。应用中最好有个 requirements.txt 文件,用于记录所有依赖包及其精确的版本号:
pip freeze > requirements.txt
第 8 章:用户身份验证
服务器端存储密码时,若想保证数据库中用户密码的安全,关键在于不存储密码本身,而是存储密码的散列值。计算密码散列值的函数接收密码作为输入,添加随机内容(盐值)之后,使用多种单向加密算法转换密码,最终得到一个和原始密码没有关系的字符序列,而且无法还原成原始密码。核对密码时,密码散列值可代替原始密码,因为计算散列值的函数是可复现的:只要输入(密码和盐值)一样,结果就一样。
使用 Werkzeug 计算密码散列值:Werkzeug 中的 security 模块实现了密码散列值的计算。这一功能的实现只需要两个函数,分别用在注册和核对两个阶段:
☛generate_password_hash(password, method='pbkdf2:sha256',salt_length=8)
这个函数的输入为原始密码,返回密码散列值的字符串形式,供存入用户数据库。method和salt_length的默认值就能满足大多数需求。
☛check_password_hash(hash, password)
这个函数的参数是从数据库中取回的密码散列值和用户输入的密码。返回值为True时,表明用户输入的密码正确。
通常将密码散列值计算集成到数据库 ORM 框架模型中,方便使用:
from werkzeug.security import generate_password_hash, check_password_hash
class User(db.Model):
# ...
password_hash = db.Column(db.String(128))
@property
def password(self):
raise AttributeError('password is not a readable attribute')
@password.setter
def password(self, password):
self.password_hash = generate_password_hash(password)
def verify_password(self, password):
return check_password_hash(self.password_hash, password)
其单元测试代码如下:
import unittest
from app.models import User
class UserModelTestCase(unittest.TestCase):
def test_password_setter(self):
u = User(password = 'cat')
self.assertTrue(u.password_hash is not None)
def test_no_password_getter(self):
u = User(password = 'cat')
with self.assertRaises(AttributeError):
u.password
def test_password_verification(self):
u = User(password = 'cat')
self.assertTrue(u.verify_password('cat'))
self.assertFalse(u.verify_password('dog'))
def test_password_salts_are_random(self):
u = User(password='cat')
u2 = User(password='cat')
self.assertTrue(u.password_hash != u2.password_hash)
- 在 Flask 中,把应用的不同子系统放在不同的蓝图中,有利于保持代码整洁有序。比如,主模块路由放置于
main蓝图中,身份验证子系统路由放置于auth蓝图中:
from flask import Blueprint
main = Blueprint('main', __name__)
# http://127.0.0.1:5000/index/
@main.route('/index/')
def index():
return return_template('index.html')
auth = Blueprint('auth', __name__)
# http://127.0.0.1:5000/auth/login/
@auth.route('/login/')
def login():
return render_template('auth/login.html')
if __name__ == '__main__':
app = Flask(__name__)
app.register_blueprint(main)
app.register_blueprint(auth, url_prefix='/auth')
- 用户登录应用后,他们的验证状态要记录在用户会话中,这样浏览不同的页面时才能记住这个状态。Flask-Login 是个非常有用的小型扩展,专门用于管理用户身份验证系统中的验证状态,且不依赖特定的身份验证机制。
☛ Flask-Login 初始化:
from flask_login import LoginManager
login_manager = LoginManager()
login_manager.init_app(app)
☛ Flask-Login 用于管理用户登录状态,因此,其运转需求一个用户模型User。该 User模型需实现如下几个方法:
| 属性/方法 | 说明 |
|---|---|
is_authenticated |
如果用户提供的登录凭据有效,必须返回 True,否则返回 False |
is_active |
如果允许用户登录,必须返回 True,否则返回 False。如果想禁用账户,可以返回 False |
is_anonymous |
对普通用户必须始终返回 False,如果是表示匿名用户的特殊用户对象,应该返回 True |
get_id() |
必须返回用户的唯一标识符,使用 Unicode 编码字符串 |
这些属性和方法可以直接在模型类中实现,不过还有一种更简单的替代方案。Flask-Login 提供了一个UserMixin类,其中包含默认实现,能满足多数需求。如下所示:
from flask_login import UserMixin
class User(UserMixin, db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key = True)
email = db.Column(db.String(64), unique=True, index=True)
username = db.Column(db.String(64), unique=True, index=True)
password_hash = db.Column(db.String(128))
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
☛ 最后,Flask-Login 要求应用指定一个函数 user_loader,用于从 session 中存储的 user ID 加载得到一个用户对象模型:
from . import login_manager
@login_manager.user_loader
def load_user(user_id):
return User.query.get(int(user_id))
正常情况下,user_loader这个函数的返回值必须是用户对象;如果用户标识符无效,或者出现了其他错误,则返回 None。
☛ 可以通过LoginManager对象的login_view属性为 Flask-Login 设置登录页面的端点,匿名用户尝试访问受保护的页面时,Flask-Login 将重定向到登录页面。
login_manager.login_view = 'auth.login' #蓝图登录路由
注:因为登录路由在蓝图中定义,所以要在前面加上蓝图的名称。
☛ 保护路由:为了保护路由,只让通过身份验证的用户访问,Flask-Login 提供了一个login_required装饰器:
from flask_login import login_required
@app.route('/secret/')
@login_required
def secret():
return 'Only authenticated users are allowed!'
得益于login_required装饰器,如果未通过身份验证的用户访问这个路由,Flask-Login 将拦截请求,把用户发往登录页面。
☛ 记录登录状态:当用户提交登录请求时,服务器进行验证,如果验证通过,则进行登录,此时需要调用 Flask-Login的login_user记住登录状态(记住客户端 session):
@auth.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm()
if form.validate_on_submit():
user = User.query.filter_by(email=form.email.data).first()
if user is not None and user.verify_password(form.password.data):
# store login status
login_user(user, form.remember_me.data)
# check auth url,and redirct
next = request.args.get('next')
if next is None or not next.startswith('/'):
next = url_for('main.index')
return redirect(next)
flash('Invalid username or password.')
return render_template('auth/login.html', form=form)
login_user()函数的参数是要登录的用户,以及可选的“记住我”布尔值,“记住我”也在表单中勾选。如果这个字段的值为False,关闭浏览器后用户会话就过期了,所以下次用户访问时要重新登录。如果值为True,那么会在用户浏览器中写入一个长期有效的 cookie,使用这个 cookie 可以复现用户会话。cookie 默认记住一年,可以使用可选的REMEMBER_COOKIE_DURATION配置选项更改这个值。
☛ 登出用户:使用方法logout_user:
from flask_login import logout_user, login_required
@auth.route('/logout')
@login_required
def logout():
logout_user()
flash('You have been logged out.')
return redirect(url_for('main.index'))
☛ Flask-Login的运作方式 总结:
- 用户点击登录链接(eg:访问 http://localhost:5000/auth/login)。显示表单进行登录;
- 用户输入用户名和密码,然后点击提交按钮。再次调用相同的处理函数,不过这一次处理的是 POST 请求,而非 GET 请求:
a. 处理函数验证通过表单提交的凭据,通过验证则调用 Flask-Login 的login_user()函数记录用户登录状态;
b.login_user()函数把用户的 ID 以字符串的形式写入用户会话(保存登录用户的 cookie);
c. 视图函数重定向到首页/其他请求页; - 此后浏览器访问被
login_required装饰的路由时,Flask-Login 会自动判断用户是否已处于登录状态,如果是,则允许访问,否则重定向到登录页面。如果要获取当前登录用户资料,可以使用current_user引用,Flask-Login 会内部会通过如下几个过程返回当前用户:
a. 在还没有给上下文变量current_user赋值时,会调用 Flask-Login 内部的_get_user()函数,找出用户是谁;
b._get_user()函数检查用户会话中有没有用户 ID。如果没有,返回一个 Flask-Login 的 AnonymousUser 实例。如果有 ID,调用应用中使用user_loader装饰器注册的函数,传入用户 ID;
c. 应用中的user_loader处理函数从数据库中读取用户,将其返回。Flask-Login 把返回的用户对象赋值给当前请求的 current_user 上下文变量。
对于某些特定类型的应用,有必要确认注册时用户提供的信息是否正确。常见要求是能通过提供的电子邮件地址与用户取得联系。为了确认电子邮件地址,用户注册后,应用会立即发送一封确认邮件。新账户先被标记成待确认状态,用户按照邮件中的说明操作后,才能证明自己可以收到电子邮件。账户确认过程中,往往会要求用户点击一个包含确认令牌的特殊 URL 链接。
使用 itsdangerous 生成确认令牌:确认邮件中最简单的确认链接是
http://www.example.com/auth/confirm/这种形式的 URL,其中
但这种实现方式显然不是很安全,只要用户能判断确认链接的格式,就可以随便指定 URL 中的数字,从而确认任意账户。解决方法是 把 URL 中的
可以把这种生成和检验令牌的功能添加到User模型中:
from itsdangerous import TimedJSONWebSignatureSerializer as Serializer
from flask import current_app
from . import db
class User(UserMixin, db.Model):
# ...
confirmed = db.Column(db.Boolean, default=False)
def generate_confirmation_token(self, expiration=3600):
s = Serializer(current_app.config['SECRET_KEY'], expiration)
return s.dumps({'confirm': self.id}).decode('utf-8')
def confirm(self, token):
s = Serializer(current_app.config['SECRET_KEY'])
try:
data = s.loads(token.encode('utf-8'))
except:
return False
if data.get('confirm') != self.id:
return False
self.confirmed = True
db.session.add(self)
return True
dumps()方法为指定的数据生成一个加密签名,然后再对数据和签名进行序列化,生成令牌字符串。
expires_in参数设置令牌的过期时间,单位为秒。
loads()方法可以解码令牌,其唯一的参数是令牌字符串。这个方法会检验签名和过期时间,如果都有效,则返回原始数据。如果提供给loads()方法的令牌无效或是过期了,则抛出异常。
- 通常对于已注册登录,但未进行验证(eg:邮箱验证)的用户,可以对其进行访问限制,让其只能访问有限页面。这个可以通过上文提及的 Flask 提供的
before_request钩子函数完成。而对蓝图来说,before_request钩子只能应用到属于蓝图的请求上。若想在蓝图中使用针对应用全局请求的钩子,必须使用before_app_request装饰器:
@auth.before_app_request
def before_request():
if current_user.is_authenticated \ # 已登录
and not current_user.confirmed \ # 未验证
and request.blueprint != 'auth' \ # 不是 auth 路由
and request.endpoint != 'static': # 不是请求静态资源
return redirect(url_for('auth.unconfirmed'))
@auth.route('/unconfirmed/')
def unconfirmed():
if current_user.is_anonymous or current_user.confirmed:
return redirect(url_for('main.index'))
return render_template('auth/unconfirmed.html')
注:如果before_request或before_app_request的回调 返回响应 或 重定向,Flask 会直接将其发送至客户端,而 不会调用相应的视图函数。因此,这些回调可在必要时 拦截请求。
- 管理账户:
☛ 修改密码:安全意识强的用户可能想定期修改密码。这是一个很容易实现的功能,只要用户处于登录状态,就可以放心显示一个表单,要求用户输入旧密码和替换的新密码。
☛ 重设密码:为避免用户忘记密码后无法登入,应用可以提供重设密码功能。为了安全起见,有必要使用令牌,类似于确认账户时用到的。用户请求重设密码后,应用向用户注册时提供的电子邮件地址发送一封包含重设令牌的邮件。用户点击邮件中的链接,令牌通过验证后,显示一个用于输入新密码的表单。
☛ 修改电子邮件地址:应用可以提供修改注册电子邮件地址的功能,不过接受新地址之前,必须使用确认邮件进行验证。使用这个功能时,用户在表单中输入新的电子邮件地址。为了验证新地址,应用发送一封包含令牌的邮件。服务器收到令牌后,再更新用户对象。服务器收到令牌之前,可以把新电子邮件地址保存在一个新数据库字段中作为待定地址,或者将其与 id 一起保存在令牌中。
第 9 章:用户角色
- 为系统创建一个用户角色模型,代码如下:
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
default = db.Column(db.Boolean, default=False, index=True)
permissions = db.Column(db.Integer)
users = db.relationship('User', backref='role', lazy='dynamic')
def __init__(self, **kwargs):
super(Role, self).__init__(**kwargs)
if self.permissions is None:
self.permissions = 0
其中:default字段是注册新用户时赋予用户的默认角色。因为应用将在 roles 表中搜索默认角色,所以我们为这一列设置了索引,提升搜索的速度。
permissions字段代表一组权限,其值是一个整数值。SQLAlchemy 设置字段是默认为None,因此这里通过构造函数将该值默认值设为0。具体权限数值如下所示:
| 操作 | 权限名 | 权限值 |
|---|---|---|
| 关注用户 | FOLLOW | 1 |
| 在他人的文章中发表评论 | COMMENT | 2 |
| 写文章 | WRITE | 4 |
| 管理他人发表的评论 | MODERATE | 8 |
| 管理员权限 | ADMIN | 16 |
使用 2 的幂表示权限值有个好处:每种不同的权限组合对应的值都是唯一的,方便存入角色的permissions字段。例如,若想为一个用户角色赋予权限,使其能够关注其他用户,并在文章中发表评论,则权限值为 FOLLOW + COMMENT = 3(使用 FOLLOW | COMMENT 效率或许更高)。通过这种方式存储各个角色的权限特别高效。此时,可以为用户角色模型添加对应的权限处理方法:
class Role(db.Model):
# ...
def add_permission(self, perm):
if not self.has_permission(perm):
self.permissions |= perm
def remove_permission(self, perm):
if self.has_permission(perm):
self.permissions -= perm
def reset_permissions(self):
self.permissions = 0
def has_permission(self, perm):
return self.permissions & perm == perm
- 如果想让视图函数只对具有特定权限的用户开放,可以使用自定义的装饰器:
def permission_required(permission):
def decorator(f):
@wraps(f)
def decorated_function(*args, **kwargs):
if not current_user.can(permission):
abort(403)
return f(*args, **kwargs)
return decorated_function
return decorator
def admin_required(f):
return permission_required(Permission.ADMIN)(f)
下面举几个例子展示:
@main.route('/admin')
@login_required
@admin_required
def for_admins_only():
return "For administrators!"
@main.route('/moderate')
@login_required
@permission_required(Permission.MODERATE)
def for_moderators_only():
return "For comment moderators!"
上面代码几个装饰器修饰 按顺序 实现了请求路由,登录管理和权限检验几个功能。
第 10 章:用户资料
- 所有社交网站都会给用户提供资料页面,简要显示用户在网站中的活动情况。用户可以把资料页面的 URL 分享给别人,告诉别人自己在这个网站上。因此,这个页面的 URL 要简短易记。
第 11 章:博客文章
- 如果需要维护两个完全相同的 HTML 片段副本,则可以采用 Jinja2 提供
的include()指令创建一个模板文件,然后使用include()指令导入即可:
Posts by {{ user.username }}
{% include '_posts.html' %}
注:_posts.html 模板名中的下划线前缀不是必须使用的,这只是一种习惯用法,以区分完整模板和局部模板
- 实际开发中,对于生产环境和开发环境,同一项目的依赖可能会有一些不同(比如,开发环境会增加一些测试依赖,而这些依赖对于生产环境是必须剔除的),因此,为了区分生产环境的依赖和开发环境的依赖,我们可以用 requirements 子目录替换 requirements.txt 文件,在该目录中分别存储不同环境中的依赖。在这个新目录中,我们可以创建一个 dev.txt 文件,列出开发过程中所需的依赖,再创建一个 prod.txt 文件,列出生产环境所需的依赖。由于两个环境所需的依赖大部分是相同的,可以创建一个 common.txt 文件,在 dev.txt 和 prod.txt 中使用
-r参数将其导入。
# 示例 11-7 requirements/dev.txt:开发需求文件
-r common.txt
faker==0.7.18
通常对于支持 Markdown 编辑的文本,提交表单后,POST 请求应当只发送纯 Markdown 文本,而不是发送对应的 HTML 页面。因为随表单一起发送生成的 HTML 预览有安全隐患,因为攻击者能很轻松地修改 HTML 代码,使其和 Markdown 源不匹配,然后再提交表单。为了安全起见,应该只提交 Markdown 源文本,然后在服务器上使用 Markdown(使用 Python 编写的 Markdown 到 HTML 转换程序)将其转换成 HTML。得到 HTML 后,再使用 Bleach 进行清理,确保其中只包含几个允许使用的 HTML 标签。
把 Markdown 格式的博客文章转换成 HTML 的过程可以在 HTML 模板中完成,但这么做效率不高,因为每次渲染页面都要转换一次。为了避免重复工作,我们可在创建博客文章时做一次性转换,把结果缓存在数据库中。转换后的博客文章 HTML 代码缓存在 Post 模型的一个新字段中,在模板中可以直接调用。文章的 Markdown 源文本还要保存在数据库中,万一需要编辑时使用。
from markdown import markdown
import bleach
class Post(db.Model):
# ...
body_html = db.Column(db.Text)
# ...
@staticmethod
def on_changed_body(target, value, oldvalue, initiator):
allowed_tags = ['a', 'abbr', 'acronym', 'b', 'blockquote', 'code',
'em', 'i', 'li', 'ol', 'pre', 'strong', 'ul',
'h1', 'h2', 'h3', 'p']
target.body_html = bleach.linkify(bleach.clean(
markdown(value, output_format='html'),
tags=allowed_tags, strip=True))
db.event.listen(Post.body, 'set', Post.on_changed_body)
on_changed_body() 函数注册在 body 字段上,是 SQLAlchemy “set”事件的监听程序,这意味着只要 body 字段设了新值,这个函数就会自动被调用。on_changed_body() 函数把 body 字段中的文本渲染成 HTML 格式,将结果保存在 body_html 中,自动且高效地完成 Markdown 文本到 HTML 的转换。
真正的转换过程分 3 步完成。首先,markdown() 函数初步把 Markdown 文本转换成 HTML。然后,把得到的结果和允许使用的 HTML 标签列表传给 clean() 函数。clean() 函数删除所有不在白名单中的标签。转换的最后一步由 linkify() 函数完成,这个函数由 Bleach 提供,把纯文本中的 URL 转换成合适的 链接。最后一步是很有必要的,因为 Markdown 规范没有为自动生成链接提供官方支持,但这是个十分便利的功能。
- 博客文章的固定链接实现:用户有时希望能在社交网络中和朋友分享某篇博客文章的链接。为此,每篇文章都要有一个专页,使用唯一的 URL 引用。
@main.route('/post/')
def post(id):
post = Post.query.get_or_404(id)
return render_template('post.html', posts=[post])
第 12 章:关注者
- 关系数据库中,多对多的关系建立需要添加第三张表作为桥接。比如,现有一张学生表和课程表,一个学生可以选择多门课程,一门课程可以被多个学生选择。因此,学生表与课程表之间的关系是多对多关系。无法通过在学生表中添加一个指向课程表的外键建立两者联系,因为一个学生可以选择多门课程,一个外键不够用;同理,无法在课程表中添加一个指向学生的外键。而通过额外建立一张学生-课程关联表,即可建立关联数据库多对多关系:

上图中的关联表是 registrations,表中的每一行表示一个学生注册的一门课程。
查询多对多的关系分为两步:比如想知道某位学生选择了哪些课程,则第一步需先从学生表和关联表 registrations 之间的一对多关系(一个学生对应关联表的 registrations 多条数据)找出所有课程,第二步则反过来,将第一步找到的课程 id 在课程表中找到对应条目即可。
通过遍历两个关系来获取查询结果的做法听起来有难度,不过像前例这种简单关系,SQLAlchemy 就可以完成大部分操作。
registrations = db.Table('registrations',
db.Column('student_id', db.Integer, db.ForeignKey('students.id')),
db.Column('class_id', db.Integer, db.ForeignKey('classes.id'))
)
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)
classes = db.relationship('Class',
secondary=registrations,
backref=db.backref('students', lazy='dynamic'),
lazy='dynamic')
class Class(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String)
多对多关系仍使用定义一对多关系的 db.relationship() 方法定义,但在多对多关系中,必须把 secondary 参数设为关联表。多对多关系可以在任何一个类中定义,backref 参数会处理好关系的另一侧。关联表就是一个简单的表,不是模型,SQLAlchemy 会自动接管这个表。
- 对于多对多关系建立,SQLAlchemy 会自动帮我们处理关联关系,但是这样做却有个限制:我们无法访问关联表相关字段信息。因为通常关联表中可能存在一些额外信息补充关系(比如关注表和用户表之间的建立信息,可能包含关注时间等字段)。解决的办法就是:提升关联表的地位,使其变成应用可访问的模型。
# 关注表模型
class Follow(db.Model):
__tablename__ = 'follows'
follower_id = db.Column(db.Integer, db.ForeignKey('users.id'),
primary_key=True)
followed_id = db.Column(db.Integer, db.ForeignKey('users.id'),
primary_key=True)
timestamp = db.Column(db.DateTime, default=datetime.utcnow)
# 用户表模型
class User(UserMixin, db.Model):
# ...
followed = db.relationship('Follow',
foreign_keys=[Follow.follower_id],
backref=db.backref('follower', lazy='joined'),
lazy='dynamic',
cascade='all, delete-orphan')
followers = db.relationship('Follow',
foreign_keys=[Follow.followed_id],
backref=db.backref('followed', lazy='joined'),
lazy='dynamic',
cascade='all, delete-orphan')
在这段代码中,followed 和 followers 关系都定义为单独的一对多关系。注意,为了消除外键间的歧义,定义关系时必须使用可选参数 foreign_keys 指定外键。而且,db.backref() 参数并不是指定这两个关系之间的引用关系,而是回引 Follow 模型。
回引中的 lazy 参数指定为 joined。这种 lazy 模式可以实现立即从联结查询中加载相关对象。例如,如果某个用户关注了 100 个用户,调用 user.followed.all() 后会返回一个列表,其中包含 100 个 Follow 实例,每一个实例的 follower 和 followed 回引属性都指向相应的用户。设定为 lazy='joined' 模式,就可在一次数据库查询中完成这些操作。如果把 lazy 设为默认值 select,那么首次访问 follower 和 followed 属性时才会加载对应的用户,而且每个属性都需要一个单独的查询,这就意味着获取全部被关注用户时需要增加 100 次额外的数据库查询。
cascade 参数配置在父对象上执行的操作对相关对象的影响。比如,层叠选项可设定为:将用户添加到数据库会话后,要自动把所有关系的对象都添加到会话中。层叠选项的默认值能满足多数情况的需求,但对这个多对多关系来说却不合适。删除对象时,默认的层叠行为是把对象连接的所有相关对象的外键设为空值。但在关联表中,删除记录后正确的行为应该是把指向该记录的实体也删除,这样才能有效销毁连接。这就是层叠选项值 delete-orphan 的作用。
第 13 章:用户评论
- 评论在数据库中的表示:评论和博客文章没有太大区别,都有正文、作者和时间戳,而且在这个特定实现中都使用 Markdown 句法编写。下图是评论表
comments和其他数据表之间的关系:

评论属于某篇博客文章,因此定义了一个从 posts 表到 comments 表的一对多关系。使用这个关系可以获取某篇博客文章的评论列表。comments 表还与 users 表之间有一对多关系。通过这个关系可以获取用户发表的所有评论,还能间接知道用户发表了多少篇评论。
- 评论表的数据库模型如下:
class Comment(db.Model):
__tablename__ = 'comments'
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.Text)
body_html = db.Column(db.Text)
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
disabled = db.Column(db.Boolean)
author_id = db.Column(db.Integer, db.ForeignKey('users.id'))
post_id = db.Column(db.Integer, db.ForeignKey('posts.id'))
@staticmethod
def on_changed_body(target, value, oldvalue, initiator):
allowed_tags = ['a', 'abbr', 'acronym', 'b', 'code', 'em', 'i','strong']
target.body_html = bleach.linkify(bleach.clean(
markdown(value, output_format='html'),
tags=allowed_tags, strip=True))
db.event.listen(Comment.body, 'set', Comment.on_changed_body)
Comment 模型的属性几乎和 Post 模型一样,不过多了一个 disabled 字段。这是个布尔值字段,协管员通过这个字段查禁不当评论。
- 为了完成对数据库的修改,User 和 Post 模型还要建立与
comments表的一对多关系:
class User(db.Model):
# ...
comments = db.relationship('Comment', backref='author', lazy='dynamic')
class Post(db.Model):
# ...
comments = db.relationship('Comment', backref='post', lazy='dynamic')
第 14 章:应用编程接口
近些年,Web 应用有种趋势,那就是业务逻辑被越来越多地移到客户端,开创出了一种称为富互联网应用(RIA,rich Internet application)的架构。在 RIA 中,服务器的主要功能(有时是唯一功能)是为客户端提供数据存取服务。在这种模式中,服务器变成了 Web 服务或应用编程接口(API,application programming interface)。
RIA 可采用多种协议与 Web 服务通信。远程过程调用(RPC,remote procedure call)协议,例如 XML-RPC,以及由其衍生的简单对象访问协议(SOAP,simplified object access protocol),在几年前比较受欢迎。最近,表现层状态转移(REST,representational state transfer) 架构崭露头角,成为 Web 应用的新宠,因为这种架构建立在大家熟识的万维网基础之上。
Web 服务的 REST 架构 6 大特征:
1. 客户端 – 服务器:客户端和服务器之间必须有明确的界线。
2. 无状态:客户端发出的请求中必须包含所有必要的信息。服务器不能在两次请求之间保存客户端的任何状态。
3. 缓存:服务器发出的响应可以标记为可缓存或不可缓存,这样出于优化目的,客户端(或客户端和服务器之间的中间服务)可以使用缓存。
4. 接口统一:客户端访问服务器资源时使用的协议必须一致、定义良好,且已经标准化。这是 REST 架构最复杂的一方面,涉及唯一的资源标识符、资源表述、客户端和服务器之间自描述的消息,以及超媒体(hypermedia)。
5. 系统分层:在客户端和服务器之间可以按需插入代理服务器、缓存或网关,以提高性能、稳定性和伸缩性。
6. 按需编程:客户端可以选择从服务器中下载代码,在客户端的上下文中执行。资源 是 REST 架构风格的核心概念。在 REST 架构中,资源是应用中你要着重关注的事物。例如,在博客应用中,用户、博客文章和评论都是资源。
每个资源都要使用唯一的 URL 表示。对 HTTP 协议来说,资源的标识符是 URL。博客应用为例,一篇博客文章可以使用 URL /api/posts/12345 表示,其中 12345 是这篇文章的唯一标识符,使用文章在数据库中的主键表示。URL 的格式或内容无关紧要,只要资源的 URL 只表示唯一的一个资源即可。
某一类资源的集合也要有一个 URL。博客文章集合的 URL 可以是 /api/posts/,评论集合的 URL 可以是 /api/comments/。
API 还可以为某一类资源的 逻辑子集 定义集合 URL。例如,编号为 12345 的博客文章,其中的所有评论可以使用 URL /api/posts/12345/comments/ 表示。表示资源集合的 URL 习惯在末端加上一个斜线,代表一种“子目录”
注:Flask 会特殊对待末端带有斜线的路由。如果客户端请求的 URL 的末端没有斜线,而唯一匹配的路由末端有斜线,Flask 会自动响应一个重定向,转向末端带斜线的 URL。反之则不会重定向。客户端应用在建立起的资源 URL 上发送请求,使用 请求方法 表示期望的 操作:
| 请求方法 | 目 标 | 说 明 | HTTP状态码 |
|---|---|---|---|
| GET | 单个资源的 URL | 获取目标资源 | 200 |
| GET | 资源集合的 URL | 获取资源的集合(如果服务器实现了分页,还可以是一页中的资源) | 200 |
| POST | 资源集合的 URL | 创建新资源,并将其加入目标集合。服务器为新资源指派 URL,并在响应的 Location 首部中返回 | 201 |
| PUT | 单个资源的 URL | 修改一个现有资源。如果客户端能为资源指派 URL,还可用来创建新资源 | 200 或 204 |
| DELETE | 单个资源的 URL | 删除一个资源 | 200 或 204 |
| DELETE | 资源集合的 URL | 删除目标集合中的所有资源 | 200 或 204 |
请求方法不止 GET、POST、PUT 和 DELETE。HTTP 协议还定义了其他方法,例如 HEAD 和 OPTIONS,这些方法由 Flask 自动实现。
在请求和响应的主体中,资源在客户端和服务器之间来回传送,但 REST 没有指定编码资源的方式。请求和响应中的 Content-Type 首部用于指明主体中资源的编码方式。当前 RESTFUL Web 服务常用的两种编码方式是 JavaScript 对象表示法(JSON,JavaScript object notation)和可扩展标记语言(XML,extensible markup language)。对基于 Web 的 RIA 来说,JSON 更具吸引力,因为 JSON 比 XML 简洁,而且 JSON 与 Web 浏览器使用的客户端脚本语言 JavaScript 联系紧密。
在设计良好的 RESTFUL API 中,客户端只需知道几个顶级资源的 URL,其他资源的 URL 则从响应中包含的链接上发掘。
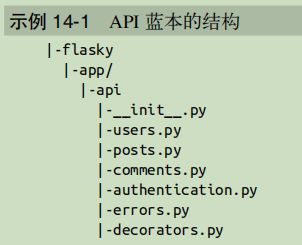
RESTFUL API 相关的路由是应用中一个自成一体的子集。因此,为了更好地组织代码,最好把这些路由放到独立的蓝本中。这个 API 蓝本的基本结构如下图所示:
- RESTFUL Web 服务将请求的状态告知客户端时,会在响应中发送适当的 HTTP 状态码,并将额外信息放入响应主体(JSON 数据)。但在处理 404 和 500 状态码时会遇到点小麻烦,因为这两个错误是由 Flask 自己生成的,而且 一般会返回 HTML 响应。这很可能会让 API 客户端困惑,因为客户端期望所有响应都是 JSON 格式。为所有客户端生成适当响应的一种方法是,在错误处理程序中根据客户端请求的格式改写响应,这种技术称为 内容协商:
@main.app_errorhandler(404)
def page_not_found(e):
if request.accept_mimetypes.accept_json and \
not request.accept_mimetypes.accept_html:
response = jsonify({'error': 'not found'})
response.status_code = 404
return response
return render_template('404.html'), 404
这个新版错误处理程序检查 Accept 请求首部(解码为 request.accept_mimetypes),根据首部的值决定客户端期望接收的响应格式。浏览器一般不限制响应的格式,但是 API 客户端通常会指定。仅当客户端接受的格式列表中包含 JSON 但不包含 HTML 时,才生成 JSON 响应。
HTTP 请求是无状态协议,即服务器在两次请求之间不能“记住”客户端的任何信息。要实现具备状态信息,客户端必须在发出的请求中包含所有必要信息,因此所有请求都必须包含用户凭据。实现具备状态的HTTP请求较常用的技术是使用 cookie 保存用户会话,服务端没有保存用户状态相关信息。但是在 RESTFUL Web 服务中使用 cookie 有点不现实,因为 Web 浏览器之外的客户端很难提供对 cookie 的支持。鉴于此,在 RESTFUL API 中使用 cookie 并不是一个很好的设计选择。
因为 REST 架构基于 HTTP 协议,所以发送凭据的最佳方式是使用 HTTP 身份验证,基本验证和摘要验证都可以。在 HTTP 身份验证中,用户凭据包含在每个请求的 Authorization 首部中。
HTTP 身份验证协议很简单,可以直接实现,不过 Flask-HTTPAuth 扩展提供了一个便利的包装,把协议的细节隐藏在装饰器之中,类似于 Flask-Login 提供的 login_required 装饰器。
from flask_httpauth import HTTPBasicAuth
auth = HTTPBasicAuth()
@auth.verify_password
def verify_password(email, password):
if email == '':
return False
user = User.query.filter_by(email = email).first()
if not user:
return False
g.current_user = user
return user.verify_password(password)
电子邮件和密码使用 User 模型中现有的方法验证。如果登录凭据正确,这个验证回调函数返回 True,否则返回 False。如果请求中没有身份验证信息,Flask-HTTPAuth 也会调用回调函数,把两个参数都设为空字符串。此时,email 的值是一个空字符串,回调函数立即返回 False 以阻断请求。某些应用遇到这种情况时可以返回 True,允许匿名用户访问。这个回调函数把通过身份验证的用户保存在 Flask 的上下文变量 g 中,供视图函数稍后访问。
- 如果身份验证凭据不正确,则服务器向客户端返回 401 状态码。默认情况下,Flask-HTTPAuth 自动生成这个状态码,但为了与 API 返回的其他错误保持一致,我们可以自定义这个错误响应:
from .errors import unauthorized
@auth.error_handler
def auth_error():
return unauthorized('Invalid credentials')
- 若想保护路由,可使用 auth.login_required 装饰器:
@api.route('/posts/')
@auth.login_required
def get_posts():
pass
不过,这个蓝本中的所有路由都要使用相同的方式进行保护,所以我们可以在 before_ request 处理程序中使用一次 login_required 装饰器,将其应用到整个蓝本:
from .errors import forbidden
@api.before_request
@auth.login_required
def before_request():
if not g.current_user.is_anonymous and \
not g.current_user.confirmed:
return forbidden('Unconfirmed account')
- 基于令牌的身份验证:每次请求,客户端都要发送身份验证凭据。为了避免总是发送敏感信息(例如密码),我们可以使用一种基于令牌的身份验证方案:在基于令牌的身份验证方案中,客户端先发送一个包含登录凭据的请求,通过身份验证后,得到一个访问令牌。这个令牌可以代替登录凭据对请求进行身份验证。出于安全考虑,令牌有过期时间。令牌过期后,客户端必须重新发送登录凭据,获取新的令牌。令牌短暂的使用期限,可以降低令牌落入他人之手所导致的安全隐患:
class User(db.Model):
# ...
def generate_auth_token(self, expiration):
s = Serializer(current_app.config['SECRET_KEY'],
expires_in=expiration)
return s.dumps({'id': self.id}).decode('utf-8')
@staticmethod
def verify_auth_token(token):
s = Serializer(current_app.config['SECRET_KEY'])
try:
data = s.loads(token)
except:
return None
return User.query.get(data['id'])
为了能够使用令牌验证请求,我们必须修改 Flask-HTTPAuth 提供的 verify_password 回调,除了普通的凭据之外,还要接受令牌:
@auth.verify_password
def verify_password(email_or_token, password):
if email_or_token == '':
return False
if password == '':
g.current_user = User.verify_auth_token(email_or_token)
g.token_used = True
return g.current_user is not None
user = User.query.filter_by(email=email_or_token).first()
if not user:
return False
g.current_user = user
g.token_used = False
return user.verify_password(password)
在这个新版本中,第一个参数可以是电子邮件地址,也可以是身份验证令牌。如果这个参数为空,那就和之前一样,假定是匿名用户。如果密码为空,那就假定 email_or_token 参数提供的是令牌,按照令牌的方式进行验证。如果两个参数都不为空,那么假定使用常规的邮件地址和密码进行验证。
最后,把身份验证令牌发送给客户端的路由也要添加到 API 蓝本中:
@api.route('/tokens/', methods=['POST'])
def get_token():
if g.current_user.is_anonymous or g.token_used:
return unauthorized('Invalid credentials')
return jsonify({'token': g.current_user.generate_auth_token(expiration=3600), 'expiration': 3600})
测试 Web 服务器:测试 Web 服务必须使用 HTTP 客户端。在命令行中测试 Web 服务最常使用的两个客户端是 cURL 和 HTTPie。这两个工具都很强大,但后者的命令行句法更简洁,可读性也更高,而且为 API 请求做了特别优化。
假设开发服务器运行在默认地址 http://127.0.0.1:5000 上。在另一个终端窗口中,可按照如下的方式发起 GET 请求:
http --json --auth : GET \
> http://127.0.0.1:5000/api/v1/posts
下面这个命令发送 POST 请求,添加一篇新博客文章:
http --auth : --json POST \
> http://127.0.0.1:5000/api/v1/posts/ \
> "body=I'm adding a post from the *command line*."
第 15 章:测试
编写单元测试主要有两个目的:
☛ 实现新功能时,单元测试能够确保新添加的代码按预期方式运行。
☛ 一个更重要的目的是,每次修改应用后,运行单元测试能保证现有代码的功能没有 回归,即新改动没有影响原有代码的正常运行。获取代码覆盖度报告:编写测试组件很重要,但知道测试的状况同样重要。代码覆盖度工具用于统计单元测试检查了应用的多少功能,并提供一份详细的报告,说明应用的哪些代码没有测试到。这个信息非常重要,因为它能指引你为最需要测试的部分编写新测试。
Flask 测试客户端:应用的某些代码严重依赖运行中的应用所创建的环境。比如,Flask 中的视图函数只能在请求上下文和运行中的应用里运行。通常来说,我们无法直接对某些特定环境中的代码进行测试,但对于 Flask 来说,其内建了一个测试客户端用于解决(至少部分解决)这一问题。测试客户端能复现应用运行在 Web 服务器中的环境,让测试充当客户端来发送请求:
import unittest
from app import create_app, db
from app.models import User, Role
class FlaskClientTestCase(unittest.TestCase):
def setUp(self):
self.app = create_app('testing')
self.app_context = self.app.app_context()
self.app_context.push()
db.create_all()
Role.insert_roles()
self.client = self.app.test_client(use_cookies=True)
def tearDown(self):
db.session.remove()
db.drop_all()
self.app_context.pop()
def test_home_page(self):
response = self.client.get('/')
self.assertEqual(response.status_code, 200)
self.assertTrue('Stranger' in response.get_data(as_text=True))
- 使用 Selenium 进行端到端测试:Flask 测试客户端不能完全模拟运行中的应用所在的环境。例如,如果应用依赖在客户端浏览器中运行的 JavaScript 代码的话,就不能使用 Flask 测试客户端,因为返回给测试的响应中的 JavaScript 代码不会执行。而 Selenium 是一个 Web 浏览器自动化工具,支持 3 种主要操作系统中的多数主流 Web 浏览器。借助 Selenium,就可以进行真实的 HTTP 请求,并进行自动化测试操作。
第 16 章:性能
如果应用的性能随着时间推移不断降低,很有可能是因为数据库查询变慢了,随着数据库规模的增长,这一情况会变得更糟。
优化数据库有时很简单,只需添加更多的索引即可;有时却很复杂,需要在应用和数据库之间加入缓存。
一次请求往往可能要执行多条数据库查询,所以经常很难分辨哪一条查询较慢。Flask-SQLAlchemy 提供了一个选项,可以记录一次请求中与数据库查询有关的统计数据:
from flask_sqlalchemy import get_debug_queries
@main.after_app_request
def after_request(response):
for query in get_debug_queries():
if query.duration >= current_app.config['FLASKY_SLOW_DB_QUERY_TIME']:
current_app.logger.warning(
'Slow query: %s\nParameters: %s\nDuration: %fs\nContext: %s\n' %
(query.statement, query.parameters, query.duration,
query.context))
return response
这个功能使用 after_app_request 处理程序实现,它和 before_app_request 处理程序的工作方式类似,只不过在视图函数处理完请求之后执行。Flask 把响应对象传给 after_app_request 处理程序,以防需要修改响应。
- 默认情况下,
get_debug_queries()函数只在调试模式中可用。但是数据库性能问题很少发生在开发阶段,因为开发过程中使用的数据库较小。因此,在生产环境中使用该选项才更能发挥它的作用。若想在生产环境中监控数据库性能,我们必须修改配置:
class Config:
# ...
SQLALCHEMY_RECORD_QUERIES = True
FLASKY_SLOW_DB_QUERY_TIME = 0.5
# ...
- 性能问题的另一个可能诱因是高 CPU 消耗,由执行大量运算的函数导致。源码分析器能找出应用中执行最慢的部分。分析器监视运行中的应用,记录调用的函数以及运行各函所消耗的时间,然后生成一份详细的报告,指出运行最慢的函数。
第 17 章:部署
Flask 自带的 Web 开发服务器不够稳健、安全和高效,不适合在生产环境中使用。
如今流行把应用托管在“云端”,不过这有多层意思。最简单的情况下,云托管的意思是把应用部署到一台或多台虚拟服务器上。而更高级的部署方法是基于容器。一个容器把应用隔离在一个映像(image)中,里面包含应用及其全部依赖。你可以安装容器平台,例如 Docker,在支持的任何系统中安装并运行预先生成好的容器映像。
另一种部署方式,正式的说法是平台即服务(PaaS,platform as a service),它让应用开发者从安装和维护运行应用的软硬件平台的日常工作中解脱出来。在 PaaS 模型中,服务提供商完全接管了运行应用的平台。应用开发者只需把应用代码上传到服务提供商维护的服务器中,整个过程往往只需几秒钟。多数 PaaS 提供商都支持按需添加或删除服务器,动态“缩放”应用,以满足不同量级的请求。Heroku 是最早出现的 PaaS 提供商之一,从 2007 年就开始运营。Heroku 平台的灵活性极高,且支持多种编程语言(包括 Python)。若想把应用部署到 Heroku 上,开发者要使用 Git 把应用推送到 Heroku 特殊的 Git 服务器上。这个服务器将自动触发安装、升级、配置和部署等操作。
密钥用的随机字符串有多种生成方法,使用 Python 可以这样生成:
(venv) $ python -c "import uuid; print(uuid.uuid4().hex)"
d68653675379485599f7876a3b469a57
用户通过 Web 表单提交的用户名和密码,有被恶意的第三方截获的风险。在开发过程中,这不是什么问题,但是把应用部署到生产服务器上之后,我们要设法降低这种风险。为了避免用户的凭据在传输过程中泄露,有必要使用安全的 HTTP,使用公钥加密客户端和服务器之间的所有通信。
为了确保应用的安全,我们只需拦截发给 http:// 的请求,将其重定向到 https://。使用 Flask-SSLify 扩展可以很好地完成这个功能:
def create_app(config_name):
# ...
if app.config['SSL_REDIRECT']:
from flask_sslify import SSLify
sslify = SSLify(app)
# ...
对 SSL 的支持只需在生产模式中启用,而且仅当平台支持时才启用。为了便于启停 SSL,我们添加了一个名为 SSL_REDIRECT 的环境变量。
反向代理服务器 接收来自多个应用的请求,然后把请求转发给相应的应
用。PaaS 是一种相当高层级的部署方式,容器没有 PaaS 自动化程度高,但是更灵活,而且不限于特定的云服务提供商。
容器是一种特殊的虚拟设备,运行在宿主操作系统的内核之上。与标准的虚拟设备不同,容器没有虚拟化的内核和硬件。因为虚拟化在内核终止,所以容器比虚拟设备更轻量、更高效,但是要求操作系统支持此项功能。Linux 内核完全支持容器。
使用 Docker 容器部署 Flasky 有个缺点:应用默认使用的 SQLite 数据库在容器内非常难升级,因为容器一旦停止运行,数据库就不见了。更好的方案是在应用的容器之外托管数据库服务器。这样升级应用时只需换个新容器,数据库就能轻松地保留下来。
Docker 推荐采用模块化方式构建应用,一个容器针对一个服务。
$ docker run --name mysql -d -e MYSQL_RANDOM_ROOT_PASSWORD=yes \
-e MYSQL_DATABASE=flasky -e MYSQL_USER=flasky \
-e MYSQL_PASSWORD= \
mysql/mysql-server:5.7
这个命令创建一个名为 mysql 的容器,在后台运行。
容器化应用通常由多个容器组成。比如,主应用和数据库服务器分别运行在单独的容器中。当应用变复杂后,不可避免需要用到多个容器,随着应用所需的容器数量不断增长,如果只使用 Docker,那么管理和协调容器的任务将变得难上加难。这种情况下,使用构建在 Docker 基础上的编排框架
Compose能助你一臂之力。
Docker 一起安装的Compose工具集提供了基本的编排功能。使用Compose时,构成应用的各容器在一个配置文件中描述,这个文件通常命名为 docker-compose.yml。这里定义的所有容器,可以使用docker-compose命令一次性全部启动。YAML 是一种简洁的格式,通过 键-值 映射和 列表 表示层次结构。
传统部署方式:需购买或租用服务器(物理服务器或虚拟服务器),并在服务器上手动设置所有需要的组件。
架设服务器:在能够托管应用之前,在服务器上必须完成多项管理任务。
1. 安装数据库服务器,例如 MySQL 或 Postgres。也可使用 SQLite 数据库,但由于它在修改现有的数据库模式方面有种种限制,不建议在生产服务器中使用。
2. 安装邮件传输代理(mail transport agent,MTA),例如 Sendmail 或 Postfix,用于向用户发送邮件。不要妄图在线上应用中使用 Gmail,因为这个服务的配额少得可怜,而且服务条款明确禁止商用。
3. 安装适用于生产环境的 Web 服务器,例如 Gunicorn 或 uWSGI。
4. 安装一个进程监控工具,例如 Supervisor,在服务器崩溃或恢复电力后立即重启。
5. 为了启用安全的 HTTP,安装并配置 SSL 证书。
6. (可选,但强烈推荐)安装前端反向代理服务器,例如 nginx 或 Apache。反向代理服务器能直接服务于静态文件,并把其他请求转发给应用的 Web 服务器。Web 服务器监听 localhost 中的一个私有端口。
7. 提升服务器的安全性。这一过程包含多项任务,目标在于降低服务器被攻击的概率,例如安装防火墙、删除不用的软件和服务,等等。
注:不要手动执行这些任务。可以使用自动化框架(例如 Ansible、Chef 或 Puppet)编写一个部署脚本。配置日志:在基于 Unix 的服务器中,日志可发送给守护进程 syslog。我们可以专门为 Unix 创建一个新配置,继承自
ProductionConfig:
class UnixConfig(ProductionConfig):
@classmethod
def init_app(cls, app):
ProductionConfig.init_app(app)
# 写入syslog
import logging
from logging.handlers import SysLogHandler
syslog_handler = SysLogHandler()
syslog_handler.setLevel(logging.WARNING)
app.logger.addHandler(syslog_handler)
这样配置之后,应用的日志将写入配置的 syslog 消息文件,通常是 /var/log/messages 或 /var/log/syslog,具体要看所用的 Linux 发行版本。如果需要的话,还可以配置 syslog 服务,把应用的日志写入别的文件或者发给其他设备。