函数
细节
- import 文件名 可以导入自己的文件调用其中的模块,如函数
import caculate
res = caculate.caculateNum(100)
print(res)
输出
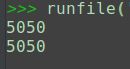
image.png
- 列表推导式实现一行输出
def caculateNum(num):
# res = 0
# for i in range(1, num+1):
# res += i
# return res
return sum([i for i in range(1, num+1)])
- 必须参数和关键字参数
#必须参数和关键字参数
def f(name, age):
print('I am %s , I am %d'%(name, age))
#关键字参数,此时允许函数调用和声明时顺序不一样
f(age=18, name='eric')
- 默认参数
#默认参数 缺省参数没有传入,默认值会生效
def f(name, age, sex = 'male'):
print('I am %s , I am %d'%(name, age))
print('Sex%s'%sex)
f(name='lisi', age=19)
f('张三', 88, 'female')
#是否显示指定参数:方便自己阅读为目的
输出
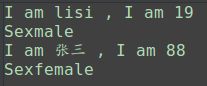
image.png
- 匿名函数
和条件判断式一起使用更加
# 匿名函数
# 语法 :
# lambda 参数: 表达式
#冒号前面是参数,可以有多个,冒号后面时表达式
#只能有一个,不写return 返回值是表达式的结果
#减少代码量,‘优雅
def rect(x, y):
return x * y
area = rect(3, 5)
print(area)
#使用lambda表达式
res = lambda x, y: x*y
print(res(4, 5))
store = []
s = "dangdangziying" if len(store) == 0 else store[0]
print(s)
def cal(x, y):
if x>y:
return x*y
else:
return x/y
calc = lambda x, y: x*y if x > y else x/y
print(calc(5, 4))
calc = lambda x, y: x*y if x > y else x/y
print(calc(2, 4))
输出
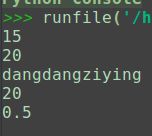
image.png
在列表排序中的使用
#列表排序中使用
stus = [
{'name': 'zhangsan', 'age': 33},
{'name': 'lisi', 'age': 12},
{'name': 'wangwu', 'age': 53},
{'name': 'zhaoliu', 'age': 18},
{'name': 'tianqi', 'age': 77}
]
print(stus)
#key值按照哪个元素为依据排序
res = sorted(stus, key=lambda x: x['age'], reverse=True)
print('排序后', res)
res = sorted(stus, key=lambda x: x['name'], reverse=True)
print('排序后', res)
输出

image.png
- 综合案例
三国中人物出现的次数
用wordcloud生成词云图片
# 案例三国小说人物出场频率统计
import jieba
from collections import Counter
from wordcloud import WordCloud
def parse():
# 定义无关词集合
excludes = {"将军", "却说", "丞相", "二人", "不可", "荆州", "不能", "如此", "商议",
"如何", "主公", "军士", "军马", "左右", "次日", "引兵", "大喜", "天下",
"东吴", "于是", "今日", "不敢", "魏兵", "陛下", "都督", "人马", "不知",
'玄德曰', '孔明曰', '刘备', '关公'
}
"""三国小说人物出场频率统计"""
with open('threekingdom.txt', 'r', encoding='utf-8') as f:
txt = f.read()
# print(txt)
words = jieba.lcut(txt)
print(words)
# 键是名字
counts = {}
for word in words:
if len(word) == 1:
continue
else:
# 向字典中增加元素 缺省值为0
counts[word] = counts.get(word, 0)+1
print(counts)
# 统计标准
counts['孔明'] = counts.get('孔明') + counts.get('孔明曰')
counts['玄德'] = counts.get('玄德曰') + counts.get('玄德')
counts['玄德'] = counts.get('玄德') + counts.get('刘备')
counts['关公'] = counts.get('关公') + counts.get('云长')
for word in excludes:
del counts[word]
# 统计出现频次最高的前20个词
items = list(counts.items())
# print(items)
items.sort(key=lambda x: x[1], reverse=True)
# print('排序后', items)
for i in range(20):
character, count = items[i]
print(character, count)
#方法2
roles = Counter(counts)
role = roles.most_common(10)
print(role)
# 构造词云字符串
li = []
for i in range(10):
character, count = items[i]
for _ in range(count):
li.append(character)
print(li)
cloud_txt = ",".join(li)
wc = WordCloud(
background_color='while',
font_path='msyh.ttc',
# 是否包含两个词的搭配,莫热门true
collocations=False
).generate(cloud_txt)
wc.to_file('三国词云.png')
parse()
# jieba分词
txt = '我来到北京清华大学'
# 将字符串分割成等量中文
seg_list = jieba.lcut(txt)
print(seg_list)
输出

image.png
这里得包不好导,在自己得电脑中
pip install xxxxx
然后file-setting-project-interpreter 然后右上角加号导入包到项目中