一、系统架构
本文以一个实际的产品为例,来说明 JPEG 在其中的应用。
 image
image
本系统为一个嵌入式 Linux 网络播放器,主要的功能为播放家庭网络中的多媒体文件,在家庭客厅等环境中有着大量的应用,它可以给用户提供更方便快捷的媒体文件的播放方式,并能充分利用家庭音响系统的巨大功能,而非 PC 环境下有限的外部设备,大大改善了媒体文件的播放体验。
系统主要的功能包括:
 image
image
本系统架构如下图:
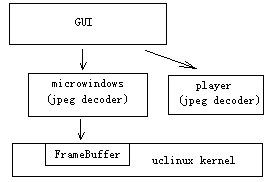 image
image
本系统是基于嵌入式 Linux 的一个应用,使用的是 ucLinux 2.4.22,并使用了 microwindows 作为 GUI 界面,底层使用了 Linux kernel 的 FrameBuffer 作为显示输出。
此系统在两个方面使用到了 JPEG 库:
1、 UI 的显示,即各种人机交互界面,考虑到用户体验,所以大量使用了贴图来美化 UI
2、 JPEG 图片文件的全屏播放,包括用户手中的各种照片等
二、JPEG 概述
JPEG 是 Joint Photographic Experts Group 的缩写,即 ISO 和 IEC 联合图像专家组,负责静态图像压缩标准的制定,这个专家组开发的算法就被称为 JPEG 算法,并且已经成为了大家通用的标准,即 JPEG 标准。 JPEG 压缩是有损压缩,但这个损失的部分是人的视觉不容易察觉到的部分,它充分利用了人眼对计算机色彩中的高频信息部分不敏感的特点,来大大节省了需要处理的数据信息。
人眼对构成图像的不同频率成分具有不同的敏感度,这个是由人眼的视觉生理特性所决定的。如人的眼睛含有对亮度敏感的柱状细胞1.8亿个,含有对色彩敏感的椎状细胞0.08亿个,由于柱状细胞的数量远大于椎状细胞,所以眼睛对亮度的敏感程度要大于对色彩的敏感程度。
总体来说,一个原始图像信息,要对其进行 JPEG 编码,过程分两大步:
1、 去除视觉上的多余信息,即空间冗余度
2、 去除数据本身的多余信息,即结构(静态)冗余度
1、去除视觉上的多余信息
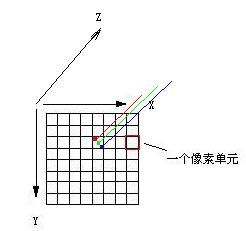
当你拿到一个原始未经处理的图像,是由各种色彩组成的,即在一个平面上,有各种色彩,而这个平面是由水平和垂直方向上的很多点组成的。实际上,每个点的色彩,也即计算机能表示的每个像素点的色彩,能分解成红、绿、蓝,即 RGB 三元色来表示,即这三种颜色的一定比例的混合就能得到一个实际的色彩值。
 image
image
所以,实际上,这个平面的图像,可以理解为除了水平 X 和垂直 Y 以外,还有一个色彩值的 Z 的三维的系统。Z 代表了三元色中各个分支 R/G/B 的混合时所占的具体数值大小,每个像素的 RGB 的混合值可能都有所不同,各个值有大有小,但临近的两个点的 R/G/B 三个值会比较接近。
 image
image
由于这个原始图像是由很多个独立的像素点组成的,也就是说它们都是分散的,离散的。比如有些图像的尺寸为640X480,就表示水平有640个像素点,垂直有480个像素点。
从上面的内容,我们可以知道两个相邻的点,会有很多的色彩是很接近的,那么如何能在最后得到的图片中,尽量少得记录这些不需要的数据,也即达到了压缩的效果。
这个就要涉及到图像信号的频谱特性了。
图像信号的频谱线一般在0-6MHz范围内,而且一幅图像内,包含了各种频率的分量。但包含的大多数为低频频谱线,只在占图像区域比例很低的图像边缘的信号中才含有高频的谱线。这个是对 JPEG 图像压缩的理论依据。
因此具体的方法就是,在对图像做数字处理时,可根据频谱因素分配比特数:对包含信息量大的低频谱区域分配较多的比特数,对包含信息量低的高频谱区域分配较少的比特数,而图像质量并没有可察觉的损伤,达到数据压缩的目的。
将原始图像这个色彩空间域,转换为频谱域,怎么转呢,这个就用到了数学上的离散余弦变换,即 DCT(Discrete Cosine Transform) 变换。
DCT 是可逆的、离散的正交变换。变换过程本身虽然并不产生压缩作用,但是变换后的频率系数却非常有利于码率压缩。即这个变换过程得到一个 DCT 变换系数,而对这个系数可以再进行更进一步的处理,即所谓的量化。经过量化,就能达到数据压缩的作用了。
总体说来,这第一步,对图像进行编码,去除多余的信息,要用到 DCT 变换中的正向 DCT(FDCT),然后再对变换的系数做量化(Quantization),这个过程就是依据的经验值,来处理人眼视觉系统所不敏感的高频数据,从而极大地减少了需要处理的数据量,这个是结合数学方法与经验值而做的处理。
2、去除数据本身的多余信息
利用 Huffman 编码,来将最后的数据用无损的方式做压缩,这个是纯数学上的处理方式。
总体来说,上面的两步即:
如果处理的是彩色图像,JPEG 算法首先将 RGB 分量转化成亮度分量和色差分量,同时丢失一半的色彩信息(空间分辨率减半)。然后,用 DCT 来进行块变换编码,舍弃高频的系数,并对余下的系数进行量化以进一步减小数据量。最后,使用 RLE 行程编码和 Huffman 编码来完成压缩任务。
三、JPEG 原理详细分析
下面将更加详细地介绍这两步中的各个细节。
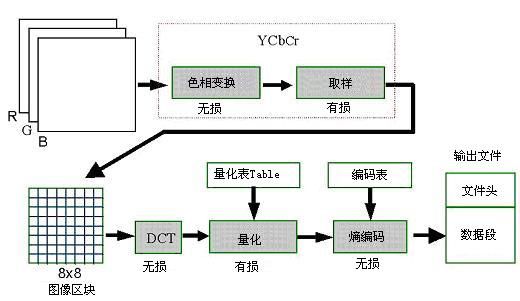
JPEG 编码中主要涉及到的内容主要包括:
1. Color Model Conversion (色彩模型)
2. DCT (Discrete Cosine Transform 离散余弦变换)
3. 重排列 DCT 结果
4. 量化
5. RLE 编码
6. 范式 Huffman 编码
7. DC 的编码
 image
image
1、色彩空间 color space
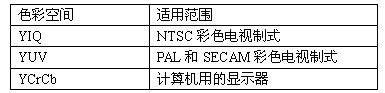
在图像处理中,为了利用人的视角特性,从而降低数据量,通常把 RGB 空间表示的彩色图像变换到其他色彩空间。
现在采用的色彩空间变换有三种:YIQ,YUV 和 YCrCb。
每一种色彩空间都产生一种亮度分量信号和两种色度分量信号,而每一种变换使用的参数都是为了适应某种类型的显示设备。
 image
image
YUV 不是哪个英文单词的缩写,而只是符号,Y 表示亮度,UV 用来表示色差,U、V 是构成彩色的两个分量;
YUV 表示法的重要性是它的亮度信号(Y)和色度信号(U、V)是相互独立的,也就是 Y 信号分量构成的黑白灰度图与用 U、V 信号构成的另外两幅单色图是相互独立的。由于 Y、U、V 是独立的,所以可以对这些单色图分别进行编码。此外,黑白电视能接收彩色电视信号也就是利用了 YUV 分量之间的独立性。
举例来说明一下:
要存储 RGB 8∶8∶8的彩色图像,即 R、G 和 B 分量都用8位二进制数(1个字节)表示,图像的大小为640×480像素,那么所需要的存储容量为640×480×(1+1+1)=921 600字节,即900KB,其中(1+1+1)表示 RGB 各占一个字节。
 image
image
如果用 YUV 来表示同一幅彩色图像,Y 分量仍然为640×480,并且 Y 分量仍然用8位表示,而对每四个相邻像素(2×2)的 U、V 值分别用相同的一个值表示,那么存储同样的一幅图像所需的存储空间就减少到640×480×(1+1/(22)+1/(22))=460 800字节,即450KB。也就是把数据压缩了一半。
 image
image
无论是用 YIQ、YUV 和 YCrCb 还是其他模型来表示的彩色图像,由于现在所有的显示器都采用 RGB 值来驱动,这就要求在显示每个像素之前,须要把彩色分量值转换成 RGB 值。
对电视机,在考虑人的视觉系统和电视阴极射线管(CRT)的非线性特性之后,RGB 和 YUV 的对应关系可以近似地用下面的方程式表示:
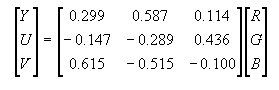 image
image
即:
Y=0.3R+0.59G+0.11B
U=B-Y
V=R-Y
对计算机而言,计算机用的数字域的色彩空间变换与电视模拟域的色彩空间变换不同,它们的分量使用 Y、Cr 和 Cb 来表示,与 RGB 空间的转换关系如下:
 image
image
从这里,就可以看出,计算出来的 Y、Cr 和 Cb 分量,会出现大量的小数,即浮点数,从而导致了在 JPEG 编码过程中会出现大量的浮点数的运算,当然经过一定的优化,这些浮点数运算可以用移位与加法这些计算机能更快速处理的方式来对其进行编码。
RGB 与 YCrCb 之间的逆变换关系可写成如下的形式:
 image
image
总体来说,上面讲的这些内容,主要就是对原始图片,可以先进行色彩空间的处理,使采集到的图像数据有所减少。
请注意,实际上,JPEG 算法与色彩空间无关,色彩空间是涉及到图像采样的问题,它和数据的压缩并没有直接的关系。
因此“RGB 到 YUV 变换”和“YUV 到 RGB 变换”不包含在 JPEG 算法中。JPEG 算法处理的彩色图像是单独的彩色分量图像,因此它可以压缩来自不同色彩空间的数据,如 RGB,YcbCr 和 CMYK。
2、色彩深度 color depth
在图像中,它是由很多个点来组成的,那么存储每个像素点所用的位数就叫做像素深度。对一个图片,这个值是可以有所不同的,从而会使得图片的数据有多和少的区别。
一幅彩色图像的每个像素用 R,G,B 三个分量表示,若每个分量用8位,那么一个像素共用3X8=24位表示,就说像素的深度为24 bit,每个像素可以是2的24次方=16 777 216种颜色中的一种。表示一个像素的位数越多,它能表达的颜色数目就越多。
在用二进制数表示彩色图像的像素时,除 R,G,B 分量用固定位数表示外,往往还增加1位或几位作为属性(Attribute)位。例如,RGB 5∶5∶5表示一个像素时,用2个字节共16位表示,其中 R,G,B 各占5位,剩下一位作为属性位。在这种情况下,像素深度为16位,而图像深度为15 位。
在用32位表示一个像素时,若 R,G,B 分别用8位表示,剩下的8位常称为 alpha 通道(alpha channel)位,或称为覆盖(overlay)位、中断位、属性位。它的用法可用一个预乘 α 通道(premultiplied alpha)的例子说明。假如一个像素(A,R,G,B)的四个分量都用归一化的数值表示,(A,R,G,B)为(1,1,0,0)时显示红色。当像素为 (0.5,1,0,0)时,预乘的结果就变成(0.5,0.5,0,0),这表示原来该像素显示的红色的强度为1,而现在显示的红色的强度降了一半。
这个 alpha 值,在这里就用来表示该像素如何产生特技效果。
总体来说,图像的宽高、分辨率越高,就是组成一幅图的像素越多,则图像文件越大;像素深度越深,就是表达单个像素的颜色和亮度的位数越多,图像文件就越大。
只有黑白两种颜色的图像称为单色图像(monochrome),每个像素的像素值用1位存储,它的值只有“0”或者“1”,一幅640×480的单色图像需要占据37.5 KB的存储空间。
而灰度图像,即有色深的黑白图像,如果每个像素的像素值用一个字节表示,而不是仅仅只有一位,那么灰度值级数就等于256级,每个像素可以是0~255之间的任何一个值,一幅640×480的灰度图像就需要占用300 KB的存储空间,类似上面说到过的 Y 分量。
3、离散余弦变换 DCT
将图像从色彩域转换到频率域,常用的变换方法有:
 image
image
DCT变换的公式为:
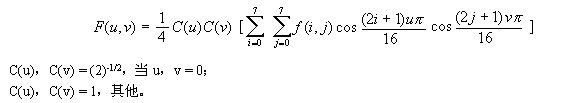 image
image
f(i,j) 经 DCT 变换之后,F(0,0) 是直流系数,其他为交流系数。
还是举例来说明一下。
8x8的原始图像:
 image
image
推移128后,使其范围变为 -128~127:
 image
image
使用离散余弦变换,并四舍五入取最接近的整数:
 image
image
上图就是将取样块由时间域转换为频率域的 DCT 系数块。
DCT 将原始图像信息块转换成代表不同频率分量的系数集,这有两个优点:其一,信号常将其能量的大部分集中于频率域的一个小范围内,这样一来,描述不重要的分量只需要很少的比特数;其二,频率域分解映射了人类视觉系统的处理过程,并允许后继的量化过程满足其灵敏度的要求。
当u,v = 0 时,离散余弦正变换(DCT)后的系数若为F(0,0)=1,则离散余弦反变换(IDCT)后的重现函数 f(x,y)=1/8,是个常 数值,所以将 F(0,0) 称为直流(DC)系数;当 u,v≠0 时,正变换后的系数为 F(u,v)=0,则反变换后的重现函数 f(x,y) 不是常数,此时 正变换后的系数 F(u,v) 为交流(AC)系数。
DCT 后的64个 DCT 频率系数与 DCT 前的64个像素块相对应,DCT 过程的前后都是64个点,说明这个过程只是一个没有压缩作用的无损变换过程。
单独一个图像的全部 DCT 系数块的频谱几乎都集中在最左上角的系数块中。
DCT 输出的频率系数矩阵最左上角的直流 (DC)系数幅度最大,图中为-415;以 DC 系数为出发点向下、向右的其它 DCT 系数,离 DC 分量越远,频率越高,幅度值越小,图中最右下角为2,即图像信息的大部分集中于直流系数及其附近的低频频谱上,离 DC 系数越来越远的高频频谱几乎不含图像信息,甚至于只含杂波。
DCT 本身虽然没有压缩作用,却为以后压缩时的"取"、"舍" 奠定了必不可少的基础。
4、量化
量化过程实际上就是对 DCT 系数的一个优化过程。它是利用了人眼对高频部分不敏感的特性来实现数据的大幅简化。
量化过程实际上是简单地把频率领域上每个成份,除以一个对于该成份的常数,且接着四舍五入取最接近的整数。
这是整个过程中的主要有损运算。
以这个结果来说,经常会把很多高频率的成份四舍五入而接近0,且剩下很多会变成小的正或负数。
整个量化的目的是减小非“0”系数的幅度以及增加“0”值系数的数目。
量化是图像质量下降的最主要原因。
因为人眼对亮度信号比对色差信号更敏感,因此使用了两种量化表:亮度量化值和色差量化值。
 image
image
使用这个量化矩阵与前面所得到的 DCT 系数矩阵:
 image
image
如,使用−415(DC系数)且四舍五入得到最接近的整数
 image
image
总体上来说,DCT 变换实际是空间域的低通滤波器。对 Y 分量采用细量化,对 UV 采用粗量化。
量化表是控制 JPEG 压缩比的关键,这个步骤除掉了一些高频量;另一个重要原因是所有图片的点与点之间会有一个色彩过渡的过程,大量的图像信息被包含在低频率中,经过量化处理后,在高频率段,将出现大量连续的零。
5、“Z”字形编排
量化后的数据,有一个很大的特点,就是直流分量相对于交流分量来说要大,而且交流分量中含有大量的0。这样,对这个量化后的数据如何来进行简化,从而再更大程度地进行压缩呢。
这就出现了“Z”字形编排,如图:
 image
image
对于前面量化的系数所作的 “Z”字形编排结果就是:
底部 −26,−3,0,−3,−3,−6,2,−4,1 −4,1,1,5,1,2,−1,1,−1,2,0,0,0,0,0,−1,−1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 顶部
这样做的特点就是会连续出现多个0,这样很有利于使用简单而直观的行程编码(RLE:Run Length Coding)对它们进行编码。
8×8图像块经过 DCT 变换之后得到的 DC 直流系数有两个特点,一是系数的数值比较大,二是相邻8×8图像块的 DC 系数值变化不大。根据这个特点,JPEG 算法使用了差分脉冲调制编码(DPCM)技术,对相邻图像块之间量化 DC 系数的差值(Delta)进行编码。即充分利用相邻两图像块的特性,来再次简化数据。
即上面的 DC 分量-26,需要单独处理。
而对于其他63个元素采用zig-zag(“Z”字形)行程编码,以增加行程中连续0的个数。
6、行程编码
Run Length Coding,行程编码又称“运行长度编码”或“游程编码”,它是一种无损压缩编码。
例如:5555557777733322221111111
这个数据的一个特点是相同的内容会重复出现很多次,那么就可以用一种简化的方法来记录这一串数字,如
(5,6)(7,5)(3,3)(2,4)(l,7)
即为它的行程编码。
行程编码的位数会远远少于原始字符串的位数。
对经过“Z”字形编排过的数据,即可以用行程编码来对其进行大幅度的数据压缩。
我们来用一个简单的例子来详细说明一下:
57,45,0,0,0,0,23,0,-30,-16,0,0,1,0,0,0,0 ,0 ,0 ,0,..,0
可以表示为
(0,57) ; (0,45) ; (4,23) ; (1,-30) ; (0,-16) ; (2,1) ; EOB
即每组数字的头一个表示0的个数,而且为了能更有利于后续的处理,必须是 4 bit,就是说,只能是 0~15,这是的这个行程编码的一个特点。
7、范式 Huffman 编码
在直流 DC 系数经过上面的 DPCM 编码,交流 AC 系数经过 RLE 编码后,得到的数据,还可以再进一补压缩,即使用 Huffman 编码来处理。
范式 Huffman 编码即 Canonical Huffman Code,现在流行的很多压缩方法都使用了范式哈夫曼编码技术,如 GZIB、ZLIB、PNG、JPEG、MPEG 等。
对上面的例子中 RLC 后的结果,对它的存储,JPEG 里并不直接保存这个数值,这样主要是为了提高效率。
 image
image
对上面的例子内容,就可以得到:
57 为第 6 组的,实际保存值为 111001,编码为 (6,111001)
45编码为 (6,101101)
23为(5,10111)
-30为(5,00001)
这个时候前面的例子就变为:
(0,6),111001 ; (0,6),101101 ; (4,5),10111; (1,5),00001; (0,4) ,0111 ; (2,1),1 ; (0,0)
这样,括号里的数值正好再合成一个字节,高4位是前面0的个数,低4位描述了后面数字的位数;后面被编码的数字表示范围是 -32767..32767。
使用上面这个表简化后的内容,再到 Huffman 编码表里去查询,从而得到最后的编码。
如06对应 Huffman 表的111000,那么
69 = (4,5) --- 1111111110011001 (69=0x45=4*16+5 )
21 = (1,5) --- 11111110110
从而得到最后的结果:
111000 111001 ; 111000 101101 ; 1111111110011001 10111 ; 11111110110 00001…
使用范式 Huffman 编码表的好处就是使得出现频率高的数字小于8位,而出现频率低的数字大于8位,这样对整体而言,就会极大地减少数据量。
需要注意的是,在 JPG 文件中,一般有两个 Huffman 表,一个是 DC 用,一个是 AC 用,它们是类似的。
对 DC 编码的部分是单独来处理的,并且是放在上面这个串的最前面。
总体来说,到目前为止,我们就得到了最后需要真正存储用的简化后,也即压缩后的数据了。
四、JPEG文件存储格式
介绍了 JPEG 的原理,我们再来结合一个具体的实例来详细讨论上面所涉及到的细节。
我们先来制作一个简单的8X8大小的像素图,然后把它存成JPEG格式。
方法是用 windows 的画图工具,定义一个8X8大小的图,用一些色块填充进去,然后另存为 JPEG 格式,如 test8x8.jpg。如下图所示:
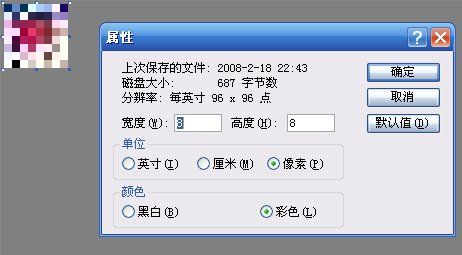 image
image
保存成的文件后缀为 jpg,但按标准来说,它是一种 JFIF 格式标准的文件,里面的图像的压缩方式是 JPEG。
JFIF 是一个文件格式标准,JPEG 是一个压缩标准,总体来说它们不是一个概念。
JFIF 是 JPEG File Interchange Format 的缩写,也即 JPEG 文件交换格式。JFIF 是一个图片文件格式标准,它是一种使用 JPEG 图像压缩技术存储摄影图像的方法。JFIF 代表了一种"通用语言"文件格式,它是专门为方便用户在不同的计算机和应用程序间传输 JPEG 图像而设计的语言。
JFIF 文件格式定义了一些内容是 JPEG 压缩标准未定义的,如 resolution/aspect ratio,color space 等。
 image
image
我们可以打开 JPEG 文件查看里面的内容,即可看到上面的各个标记段:
 image
image
从图上可以看出:
在头部有 FFD8 ,表示图像的开始;结束部分有 FFD9 ,表示图像的结束。
在中间有两个量化表 DQT 对应的标记 FFDB ;
还有图像大小信息对应的 FFC0
再后面有四个 Haffman 表对应的 FFC4 ;
一般一个 JPG 文件里会有 2 类 Haffman 表:一个用于 DC 一个用于 AC ,也即实际有 4个表,亮度的 DC,AC 两个,色度的 DC,AC 两个。
然后是图像数据段标记 FFDA;
我们再来看看各个标记的细部,具体分析一下各个部分的含义。
1、图片的识别信息
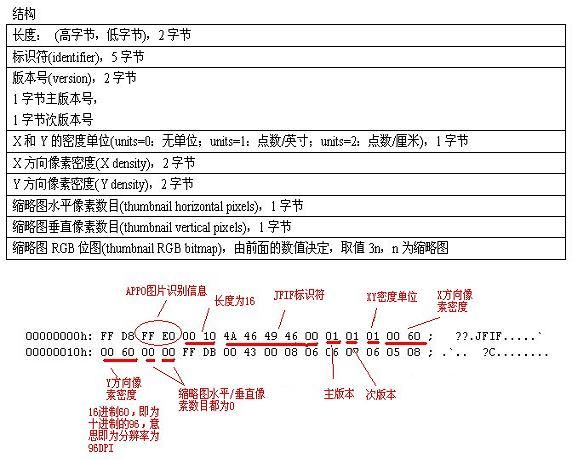 image
image
上面的内容,在标记 FFE0 后,即为长度16。然后是5字节的 JFIF 标识符号,说明这是一个 JPEG 压缩的文件。然后是主/次版本号码。下一个为 XY 像素的单位,这里为1,表示单位为点数/英寸。然后是 XY 方向的像素密度,这里是 96DPI,最后是缩略图有关信息,这里为0。
2、量化表的实例
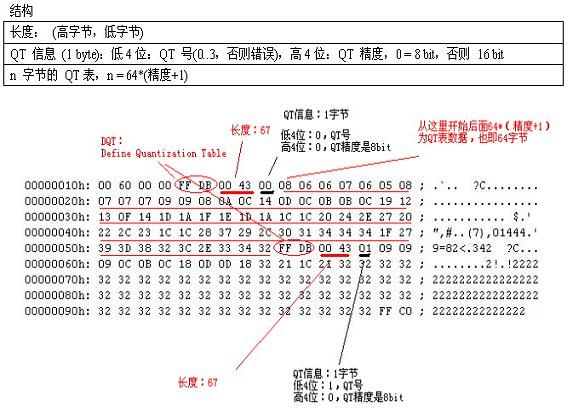 image
image
上面这个内容,FFDB 标记后的长度值为67,接下来的是 QT 信息,占一个字节;这里是0,表示这个 QT 表编号为0,并且精度是8bit。然后后面就是64个8x8的 QT 表的各个 item 了。
也即第一个 DQT 量化表的内容表示为十进制是:
 image
image
这个表即为 JPEG 亮度量化表。
第二个量化表的内容为:
 image
image
这个表的内容即为 JPEG 色度量化表。
当你打开不同的 JPEG 文件,你会看到这两个表可能也是会有区别的。这个主要是使用了不同的量化方式的结果。
3、图像信息段
 image
image
上面这个内容,FFC0 标记后即是长度,为17,然后是一个字节的数据精度,通常是为8,代表样本位数。接下来是图片的高度,占两字节,这里即为8,然后是图片的宽度,也为8,这也就是我们定义的8x8的内容。然后是 component 的个数,这里是3,表示 YUV。接下来是三组数据,每组数据里,第一个是 component ID,第二个是采样系数,这里 Y 的采样系数为22,说明垂直是2,水平是2。再后面就是量化表的编号了。
4、Haffman 表的实例
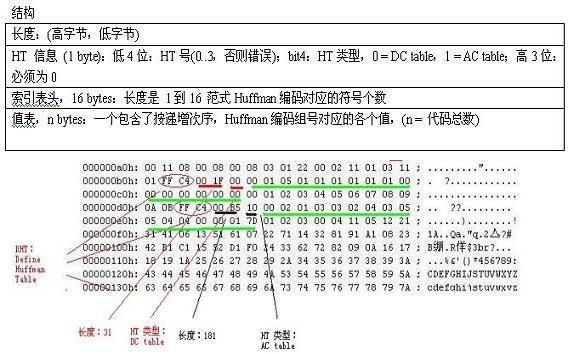 image
image
上面这个内容,FFC4 标记后的内容为数据长度,再接着的1字节为 Huffman Table 的信息,低4位是 HT ID 号,第5位是 HT 表类型标记,再高三位是为0。
第一个 DHT 表,00,类型为 DC table,HT ID 号为 0;
第二个 DHT 表,10,类型为 AC table,HT ID 号也为 0;
第三个 DHT 表,01,类型为 DC table,HT ID 号为 1;
第四个 DHT 表,11,类型为 AC table,HT ID 号为 1;
即前两个表为Y亮度分量的 DC/AC 表,后两个为 UV 色度分量的 DC/AC 表。
以第一个表为例,因为长度只有 31,那么 00 后面的 16 字节,即绿色部分:
 image
image
组号为 1 的组中,代码有 0 个;
组号为 2 的,代码有 1 个;
组号为 3 的代码有 5 个;
组号为 4/5/6/7/8/9 的代码各 1 个。
总共 12 个。
再看后续的数据:
00 01 02 03 04 05 06 07 08 09 0A 0B
即对应:
 image
image
其他未出现的组号,对应的数据未使用到。也就是说前面提到过的范式 Huffman 编码里,目前只使用部分数据即可,原因是这个 8x8 的图像数据很小。
第二个 DHT 表就更复杂些了,长度有 181。
5、图像数据段
 image
image
这里 SOS 段,长度为 12,后面所含有的 component 数量为 3 个,也即 Y UV。然后后面是各 component 的编号,及对应所使用的 Huffman 表的 ID 是多少。
在这个段的后面就是所有压缩后的数据。直到结束的问题,即 FFD9,EOI(End Of Image)。
五、JPEG 压缩过程的优化
JPEG 在目前的应用范围是非常广泛的,各种嵌入式系统中也大量地使用了 JPEG 压缩,如 IPCAM 摄像头、数字相机、移动存贮等。在这些领域由于传输数据的带宽限制或者是存贮数据的容量的限制,常常需要使用图像压缩技术来将原始大量的图像数据压缩后在进行传输或存贮,以充分利用带宽与存贮空间,达到更好的利用效率。这样,在嵌入系统中,就会使用到 JPEG 压缩。而且由于嵌入系统的资源有限的特点,在很多情况下,很需要再对 JPEG 编码压缩的过程做更进一步的优化,我们这里详细讨论一下如何实现这些优化。
浮点运算的优化
我们回头查看一下 JPEG 压缩中的 DCT 变换过程,公式:
 image
image
由于公式中有两个 i/j=0~7 的部分,这样要获得一个 DCT 系数,需要做 8 x 8=64 次乘法和 8 x 8=64 次加法, 而完成整个 8 x 8 像素的 DCT 需要 8 x 8 x 8 x 8=4096 次乘法和 8 x 8 x 8 x 8=4096 次加法. 计算量是相当的大。
对于有些无浮点运算的嵌入式系统或无专门的数学运算协处理器的系统,会造成大量的运算,极大地占用CPU的资源。
上面的公式属于 DCT 的二维计算方式,经过简化,可以将其简化为两个一维的公式:
 image
image
这样,上面的过程就可以简化为分别计算行和列的 DCT 变换。
对于一行来说需要计算的是 (8 x 8) 次乘法和 (8 x 8) 次加法,8 行就是 8 x (8 x 8) 次乘法和 8 x (8 x 8) 次加法,然后列也是相同,那么总数就为 2 x (8 x (8 x 8))=1024 次乘法和 2 x (8 x (8 x 8))=1024 次加法, 运算量变为二维计算的1/4。
但是这样的运算数量还是太大,还需要进一步优化。
在很多嵌入系统中,很多情况下需要不使用浮点运算,这样就需要再找出一维 DCT 的一些规律,然后对其进行进一步的优化。
在对一维 DCT 的运算中,还可以分为奇数列/行和偶数列/行
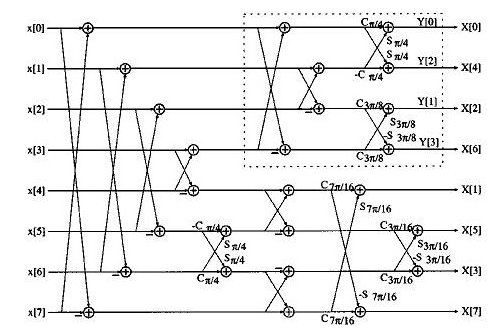 image
image
对上面的处理,就又出现了多种优化:ChenDCT,LeeDCT,AAN 算法和 LLM 算法。
其中 AAN 算法只需要 29 次加法和 5 次乘法。(注意,它是指每次一维运算要 29 次加法和 5 次乘法,一共是需要 2982 次加法和 582 次乘法的)。
 image
image
其中 Y[0]-Y[7] 都是 18 的矩阵,X[1]-X[7] 也都是 18 的矩阵。
{a, b, c, d, e, f, g} = 1/2 { cos(pi/4), cos(pi/16), cos(pi/8), cos(3pi/16), cos(5pi/16), cos(3pi/8), cos(7pi/16) }
再对上面的含有 pi 的系数进行整数优化,从而避免浮点运算,就会得到:
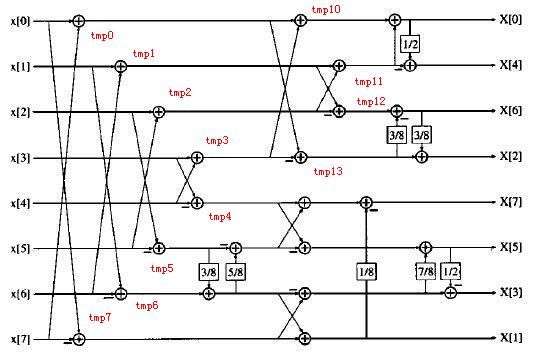 image
image
其中:
3/8=1/4+1/8
5/8=1/2+1/8
7/8=1-1/8
上面的除以 2,除以 8,都可以通过移位来实现,即右移一位和右移三位。即总数为 30 次加法,12 次移位即可。
这样就在很大程度上将原本需要使用乘法,浮点运算的过程全部转换成了简单的加法和移位处理了,这样使用数学的方法,用近似的值来完成整个转换过程,会有很好的性能和处理效果。
在处理上面的数据中,可以使用一些中间变量来记录中间结果,这样就可以减少反复计算中间值,而直接使用已经计算得到了的中间值。
tmp0 = x[0] + x[7];
tmp7 = x[0] - x[7];
tmp1 = x[1] + x[6];
tmp6 = x[1] - x[6];
tmp2 = x[2] + x[5];
tmp5 = x[2] - x[5];
tmp3 = x[3] + x[4];
tmp4 = x[3] - x[4];
tmp10 = tmp0 + tmp3;
tmp13 = tmp0 - tmp3;
tmp11 = tmp1 + tmp2;
tmp12 = tmp1 - tmp2;
/* 对偶数项进行运算 X 0,4,6,2 */
X[0]=tmp1+tmp11;
X[4]=tmp10 /2 - tmp11
X[6]=tmp12-(tmp13/4+ tmp13/8);
X[2]=tmp12/4+tmp12/8-tmp13;
其他的各个值也是类似处理的。
六、JPEG 在本嵌入式 Linux 应用中遇到的问题
在本系统中,提供给用户一些播放图片和预览图片的功能,在这个过程中就需要使用到对 JPEG 的处理。
1、JPEG 出错的处理
在对图片做预览处理的时候,有些图片原始尺寸很大,那么就需要将其转换成较小的缩略图,在转换为缩略图进行显示时,遇到了一个问题,即有时需要显示的图片,会导致系统无响应。
后来查找原因,定位到 JPEG 文件的数据不完整,才导致 jpeg decoder 出现无响应。
在前面的部分,有说到 JPEG 文件的格式中,JPEG 结束的标记 EOI (End Of Image) 为“FFD9”。
如果需要显示的图片,在传输过程中,或转换过程中,出现了没有 EOI 数据,那么应该在程序中,将其废弃,避免出现系统无响应。
2、JPEG 解码的效率优化
在解码 JPEG 时,可以使用 software decode 或 hardware decode 来处理。Hardware decode 的优点是充分利用 DSP 所提供的硬件解码功能,其解码速度会较 software decode 有数量级的提高。但有时使用 hardware decode 有一些限制,如各种 DSP 提供的 SDK 会是直接访问硬件,将 jpeg 直接输出到显示设备,从而会导致 hardware decode 与应用系统集成的麻烦。
而使用 software decode,就能在应用层完全掌握 jpeg decode 的数据缓冲结果,并可做一些图片的叠加效果或对其进行半透明混合处理,从而会有较高的灵活性。并且使用 decode buffer cache,来将已经解码的数据进行保存,在 UI 后续的使用中,就可不必反复去解码 JPEG 图片,从而也能有效提高绘图效率。
七、总结
上面的内容是本人对 JPEG 原理做的一个详细的实例分析,还介绍了 JPEG 编码过程中对浮点运算的优化处理,它特别适用于在资源有限的嵌入系统中避免大量的浮点运算。
在对 JPEG 原理做了一个详细的分析后,大家会对 JPEG 涉及到的各个细节有了一个更加明确的认识。当你自己动手结合 JPEG 编码过程来分析时,将会有一个清楚的全局观。
本文结合应用实例,对在嵌入式 Linux 应用中遇到的 JPEG 有关的问题,做了一个说明,大家在自己的设计过程中也可以作为参考。
现在,你如果再回头去看 JPEG 的原理,你现在应该能看懂它整个过程的来龙去脉了。
版权申明:
本文转自https://www.ibm.com/developerworks/cn/linux/l-cn-jpeg/ 版权为原作者拥有。此次转载仅作为学习参考记录。侵权删!