分三步走:
一、机器的规划
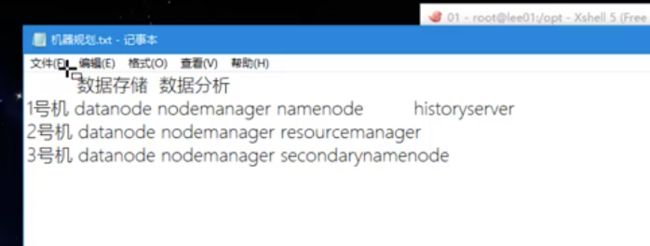
datanode 和nodemanager每台机器都搭配 一个作为数据存储 ,一个数据分析
领导者: 一号机分配namenode
二号机 resourcemanager
三号机secondarymanager
一号机多一个historyserver
二、搭建
分三小步:1.前期准备
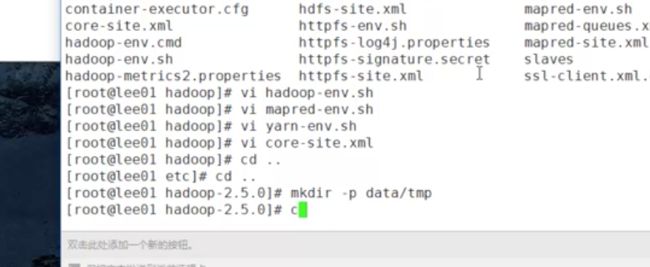
2.修改那三个-env.sh文件
3.修改相关的 -site.xml文件
开始:
解压到app目录下, 然后删除share下的doc

修改的三个文件:
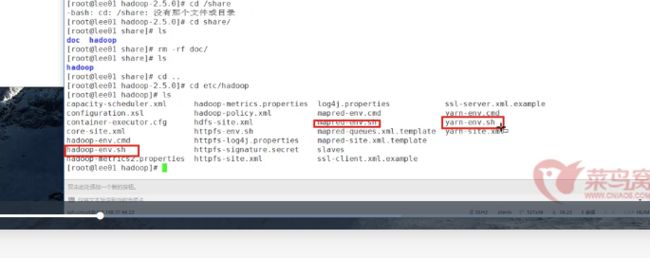
1· hadoop-env.sh
2· yarn-env.sh
3· mapred-env.sh文件
配置上java 的路径
export JAVA_HOME="java的解压路径"
然后是修改四个-site.xml文件 请参考《hadoop的搭建笔记》那里
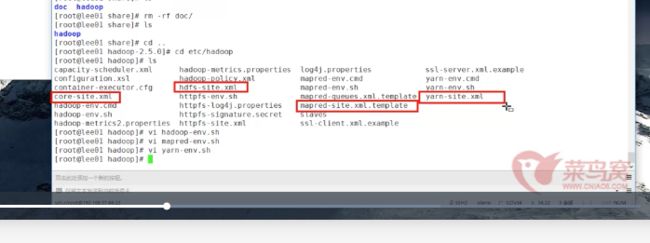
1.core-site.xml
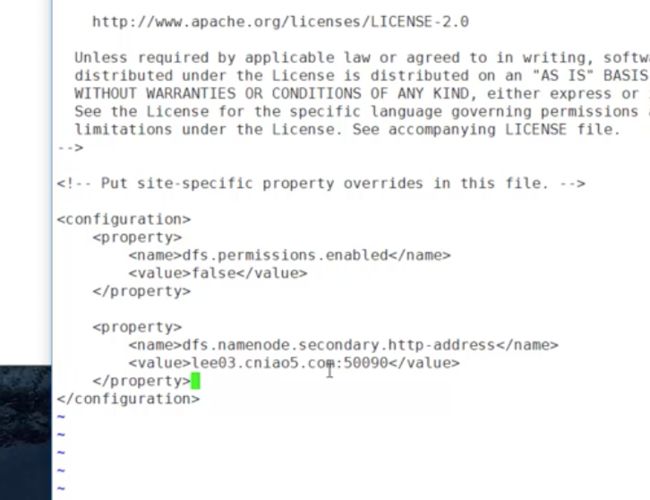
2.hdfs-site.xml
3.yarn-site.xml
4.mapred-site.xml
1.core-site.xml:
2.hdfs-site.xml
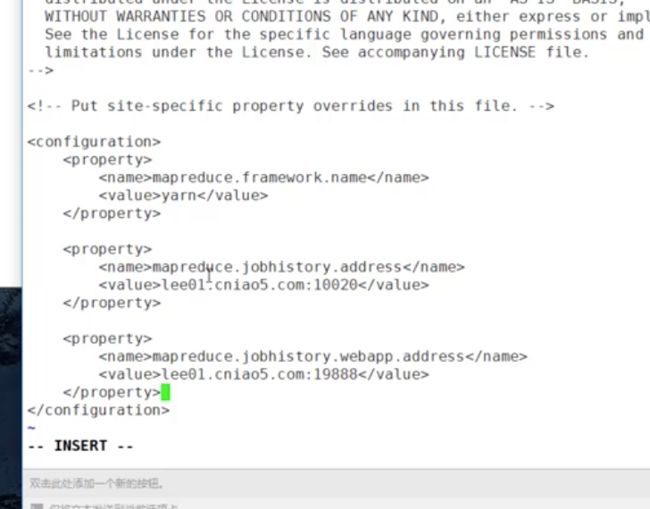
3.mapred-site.xml
//历史服务器 在一号机上 所以要加上
mapreduce.jobhistory.address
yanmei001:10020
mapreduce.jobhistory.webapp.address
yanmei001:19888
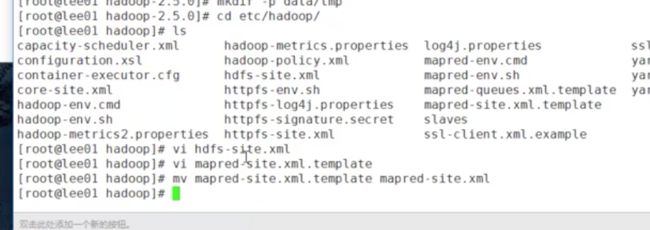
记得改mapred-site.xml的名字
用mv 移动的时候就可以改名了
4.yarn-site.xml

解释点:
到这搭建就完成了 ,不过只是在一号机器上搭建了 ,
其他机器怎么办了,两个方法 :
1.去解压重复以上步骤
2.直接拷贝过去 (先在个机器上建好存储拷贝内容的文件夹)
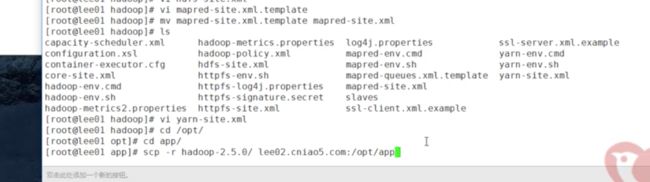
命令: scp -r hadoop-2.5.0/ yanmei002:/opt/app //2号机器
scp -r hadoop-2.5.0/ yanmei003:/opt/app //3号机器
完了以后记得格式化namenode
bin/hdfs namenode -format
查看data/tmp文件

第三步、启动各个进程
按照机器规划来启动各个进程
启动hadoop类型:
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
启动yarn:
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
启动历史服务器:
启动:sbin/mr-jobhistory-daemon.sh start historyserver
关闭命令:
sbin/mr-jobhistory-daemon.sh stop historyserver