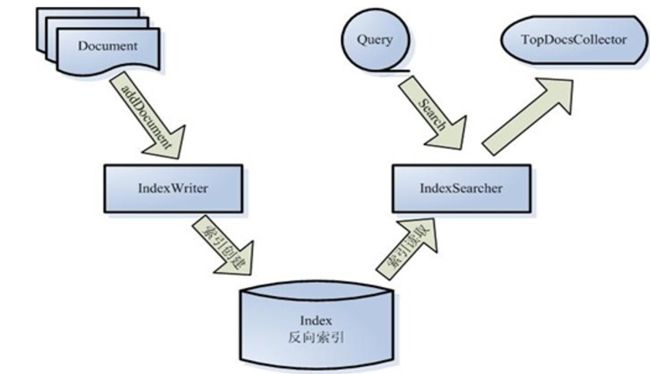
1、IndexWriter详解
问题1:索引创建过程完成什么事?
分词、存储到反向索引中。
Lucene索引创建API图示
Lucene索引创建代码示例
public static void main(String[] args) throws IOException {
// 创建使用的分词器
Analyzer analyzer = new IKAnalyzer4Lucene7(true);
// 索引配置对象
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 设置索引库的打开模式:新建、追加、新建或追加
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
// 索引存放目录
// 存放到文件系统中
Directory directory = FSDirectory.open((new File("f:/test/indextest")).toPath());
// 存放到内存中
// Directory directory = new RAMDirectory();
// 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);
// 创建document
Document doc = new Document();
// 往document中添加 商品id字段
doc.add(new StoredField("prodId", "p0001"));
// 往document中添加 商品名称字段
String name = "ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑联想";
doc.add(new TextField("name", name, Store.YES));
// 将文档添加到索引
writer.addDocument(doc);
//继续添加文档...
//刷新
writer.flush();
//提交
writer.commit();
//关闭 会提交
writer.close();
directory.close();
}
IndexWrite涉及类图

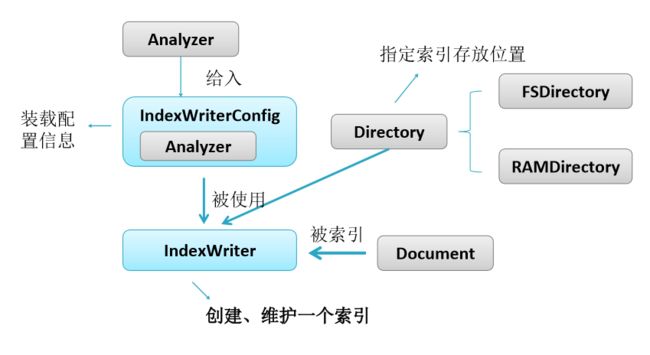
IndexWriterConfig 写索引配置:
- 使用的分词器。
- 如何打开索引(是新建,还是追加)。
- 还可配置缓冲区大小、或缓存多少个文档,再刷新到存储中。
- 还可配置合并、删除等的策略。
注意:用这个配置对象创建好 IndexWriter 对象后,在修改这个配置的对象信息不会对 IndexWriter对象起作用。
如果要在 IndexWriter 使用过程中修改它的配置信息,通过 IndxWriter 的getConfig() 方法获得 LiveIndexWriterConfig 对象,在这个对象中可查看该 IndexWriter 使用的配置信息,可进行少量的配置修改(看它的setter方法)
Directory 指定索引数据存放的位置:
- 内存
- 文件系统
- 数据库(需要编写代码指定)
保存文件系统的用法
Directory directory = FSDirectory.open(Path path);//path指定目录
IndexWriter 用来创建、维护一个索引。它的API使用流程
// 创建索引写对象
IndexWriter writer = new IndexWriter(directory, config);
// 创建document
// 将文档添加到索引
writer.addDocument(doc);
// 删除文档
//writer.deleteDocuments(terms);
//修改文档
//writer.updateDocument(term, doc);
// 刷新
writer.flush();
// 提交
writer.commit();
//回滚
//writer.rollback();
//关闭 会提交
writer.close();
注意:IndexWriter是线程安全的。如果你的业务代码中有其他的总部控制,请不要使用IndexWriter作为锁对象,以免死锁。
IndexWriter中还有一些 add方法 update方法 delete方法(可在源码中查看)
IndexWriter 涉及类图示
问题2:索引库会存储反向索引数据,会存储document吗?
会存储在索引库中一些需要展示或使用的信息
问题3: document会以什么结构存储?
是以正向索引来存储的
 正向索引与反向索引
正向索引与反向索引
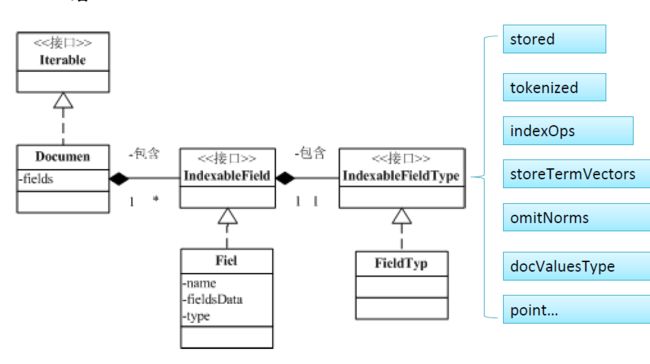
2、Document详解
要索引的数据记录、文档在lucene中的表示,是索引、搜索的基本单元。一个Document由多个字段Field构成。就像数据库的记录-字段。
IndexWriter按加入的顺讯为Document指定一个递增的id(从0开始),称为文档id。反向索引中存储的是这个id,文档存储中正向索引也是这个id。业务数据的主键id只是文档的一个字段。
Document API图示


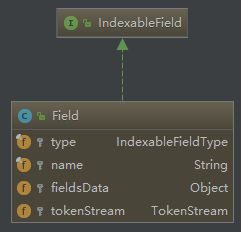
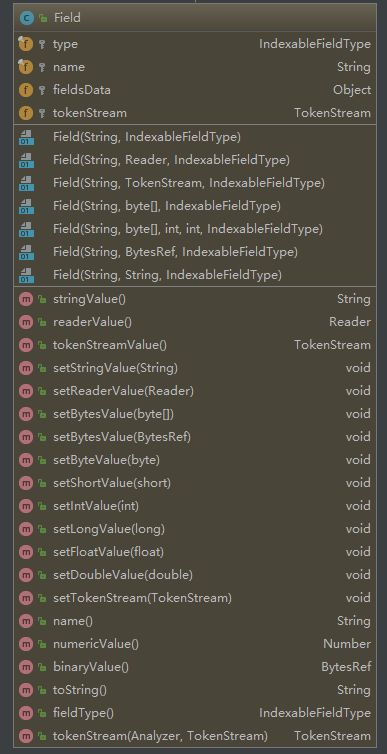
Field
字段:由字段名name、字段值value(fieldsData)、字段类型 type(IndexableField) 三部分构成。
字段值可以是文本(String、Reader 或 预分析的 Tokenstream)、二进制(byte)或数组。
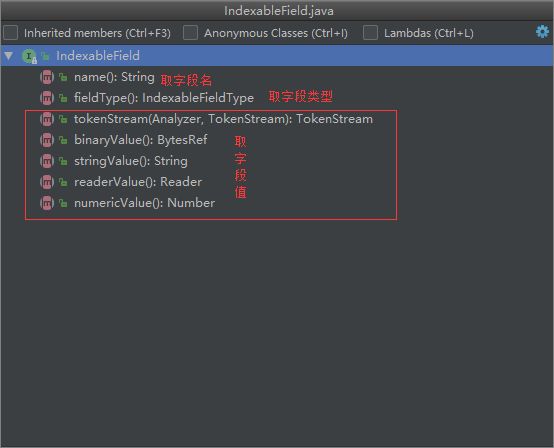
IndexableField Field API图示
Duocumnt - Field 数据举例
- 新闻:新闻id,新闻标题、新闻内容、作者、所属分类、发表时间
- 网页搜索的网页:标题、内容、链接地址
- 商品: id、名称、图片链接、类别、价格、库存、商家、品牌、月销量、详情…
在这里我们收集数据创建document对象来为其创建索引,数据的所有属性不需要都加入到document中。
需要被用做搜索条件的和要在搜索结果列表中使用的字段才需要加入到document中。
在这里我们查询条件中使用的字段才该被索引,只有在搜索结果列表中要使用的字段才应该被存储。
网页的标题、内容会被作为搜索条件,需要索引。网页的标题、链接需要显示或使用则需要存储。全部的内容做索引,但是不需要全部内容做展示所以只存储部分内容即可。
在这里我们需要模糊查询的进行分词。精确查询或范围查询的则不需要分词
IndexableFieldType
- 字段类型:描述该如何索引存储该字段
字段可选择性地保存在索引中,这样在搜索结果中,这些字段值就可以获得。
一个Document应该包含一个或多个存储字段来查询(唯一标识)数据库(文档)中对应的一条数据。
注意:未存储的字段,从索引中取得的document中是没有这些字段的。

标准化说明:比如一个单词为复数的形式:Bikes。标准化过后则为:bike。(中文基本不需要标准化)
IndexOptions 索引说明
- NONE
- Not indexed 不索引
- DOCS
- 反向索引中只存储了包含该词的 文档id,没有词频、位置
- DOCS_AND_FREQS
- 反向索引中会存储 文档id、词频
- DOC_AND_FREQS_AND_POSITIONS
- 反向索引中存储 文档id、词频、位置
- DOC_AND_FREQS_AND_POSITIONS_AND_OFFSETS
- 反向索引中存储 文档id、词频、位置、偏移量
github地址
注意:
- 如果要在搜索结果中做关键字高亮,那么就需要词频。
- 如果要实现短语查询、临近查询(跨度查询),那么就需要出现的位置和偏移量。
- 但是在反向索引中 位置、偏移数据 存储量非常大。
- 为了提升反向索引的效率,短语查询、临近查询这样的字段的位置、偏移数据是不应该保存到反向索引中的。这也你前面看到 IndexOptions为什么有那些选项的原因。

在lucene4.0以前,反向索引中总会存储这些数据,4.0后改进为可选择的。
一个字段分词器分词后,每个词项会得到一系列属性信息,如 出现频率、位置、偏移量等,这些信息构成一个词项向量 termVectors。
storeTermVectors
对于不需要在搜索反向索引时用到,但在搜索结果处理时需要位置、偏移量、附加数据(payLoad)的字段,我们可以单独为该字段存储(文档id→词项向量)的正向索引。

- boolean storeTermVectors() 是否存储词项向量
- boolean storeTermVectorPositions() 是否在词项向量中存储位置
- boolean storeTermVectorOffsets() 是否在词项向量中存储偏移量
- boolean storeTermVectorPayloads() 是否在词项向量中存储附加信息
FieldType 实现类中有对应的set方法
概念说明:Token trem 词条:三个词都是同一个意思: 分词得到的词项
代码:IndexTermVectorsDemo
什么是附加信息Payloads
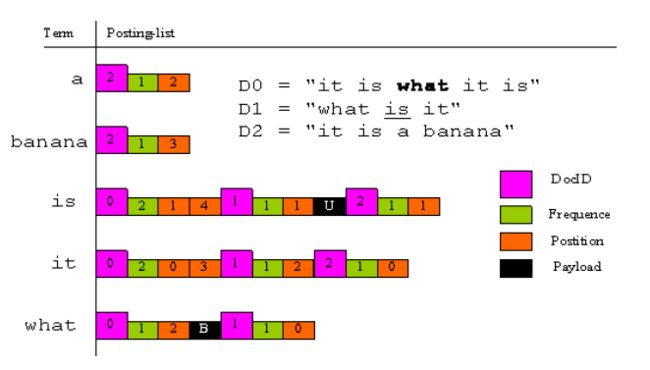
比如:a 词语 出现在第二个文档(D2) 出现了一次 出现的位置为2
is 词语 出现在第零个文档(D0)出现了二次 位置为1和4,出现在第一个文档(D1)出现了1次 位置为1 并且有下划线,出现在第二个文档(D3)出现了1次 位置为1。
练习1
商品id:字符串,不索引、但存储
String prodId = "p0001";
商品名称:字符串,分词索引(存储词频、位置、偏移量)、存储
String name = "ThinkPad X1 Carbon 20KH0009CD/25CD 超极本轻薄笔记本电脑";
图片链接:仅存储
String imgUrl = "http://www.dongnao.com/aaa";
商品简介:字符串,分词索引(不需要支持短语、临近查询)、存储,结果中
支持高亮显示
String simpleIntro = "集成显卡 英特尔 酷睿 i5-8250U 14英寸";
品牌:字符串,不分词索引,存储
String brand = "ThinkPad";
docValuesType
IndexableFieldType 中的 docValuesType 方法 就是让你来为需要排序、分组、聚合的字段指定如何为该字段创建文档→字段值得正向索引的。(以空间换时间)
IndexableFieldType API docValuseType图示

DocValuesType 选项说明
- NONE 不开启docvalue
- NUMERIC 单值、数值字段,使用。
- BINARY 单值、字节数组,使用。
- SORTED 单值、字符,使用。会预先对值字节进行排序、去重排序。
- SORTED_NUMERIC 单值、数值数组,使用。会预先对数值数组进行排序
- SORTED_SET 多字段使用。会预先对值字节进行排序、去重存储。
DocValuesType 是强调类型要求的:字段的值必须保证同类型。
具体使用选择:
- 字符串+单值 会选择 SORTED 作为docvalue存储
- 字符串+多值 会选择 SORTED_SET 作为docvalue存储
- 数值或日期或枚举字段+单值 会选择 NUMERIC 作为docvalue存储
- 数值或日期或枚举字段+多值 会选择 SORTED_SET 作为docvalue存储
强调:需要排序、分组、聚合、分类查询(面查询)的字段才创建docValues
练习2
1、修改品牌字段:支持统计查询
2、增加商品类别字段:字符串(类别名),索引不分词,不存储、支持分
类统计,多值(一个商品可能属于多个类别)。
type = {“电脑”,”笔记本电脑”}
3、增加价格字段:整数,单位分,不索引、存储,需要支持排序
多值字段只需要同字段多次加入即可
练习一、二github代码
如何加入数值字段(int)
Field的构造方法和set方法

在Field类中没有对应的构造方法去设置数值字段,但是在 set 方法中有设置数值字段的功能。
//设置数值的源码
/**
* Expert: change the value of this field. See
* {@link #setStringValue(String)}.
*/
public void setIntValue(int value) {
if (!(fieldsData instanceof Integer)) {
throw new IllegalArgumentException("cannot change value type from " + fieldsData.getClass().getSimpleName() + " to Integer");
}
fieldsData = Integer.valueOf(value);
}
在上面的源码中可以看出在设置数值类型值的时候会先去判断 fieldsData 是否为Integer类型。fieldsData 是通过构造方法设置的,而构造方法并没有设置数值属性的值。(所以需要自己实现)
- 因为 IndexableField 的实现类为 Field。所以扩展数值字段的Field,首先查看 IndexableField 的 API
再查看Field类中对应的实现,发现与 Field 类中 set 方法的实现逻辑是一致的,都需要先判断值类型。
@Override
public Number numericValue() {
if (fieldsData instanceof Number) {
return (Number) fieldsData;
} else {
return null;
}
}
@Override
public BytesRef binaryValue() {
if (fieldsData instanceof BytesRef) {
return (BytesRef) fieldsData;
} else {
return null;
}
}
@Override
public String stringValue() {
if (fieldsData instanceof String || fieldsData instanceof Number) {
return fieldsData.toString();
} else {
return null;
}
}
@Override
public Reader readerValue() {
return fieldsData instanceof Reader ? (Reader) fieldsData : null;
}
@Override
public TokenStream tokenStream(Analyzer analyzer, TokenStream reuse) {
if (fieldType().indexOptions() == IndexOptions.NONE) {
// Not indexed
return null;
}
if (!fieldType().tokenized()) {
if (stringValue() != null) {
if (!(reuse instanceof StringTokenStream)) {
// lazy init the TokenStream as it is heavy to instantiate
// (attributes,...) if not needed
reuse = new StringTokenStream();
}
((StringTokenStream) reuse).setValue(stringValue());
return reuse;
} else if (binaryValue() != null) {
if (!(reuse instanceof BinaryTokenStream)) {
// lazy init the TokenStream as it is heavy to instantiate
// (attributes,...) if not needed
reuse = new BinaryTokenStream();
}
((BinaryTokenStream) reuse).setValue(binaryValue());
return reuse;
} else {
throw new IllegalArgumentException("Non-Tokenized Fields must have a String value");
}
}
if (tokenStream != null) {
return tokenStream;
} else if (readerValue() != null) {
return analyzer.tokenStream(name(), readerValue());
} else if (stringValue() != null) {
return analyzer.tokenStream(name(), stringValue());
}
throw new IllegalArgumentException("Field must have either TokenStream, String, Reader or Number value; got " + this);
}
我们可以发现上面源码如果类型不匹配我们返回的都是null,而且五个方法对应了五种不同的值类型,文本(String、Reader 或 预分析的 TokenStream)、二进值(byte[])或数组。
而它返回null则表示它不是该类型的值。
在IndexWriter(创建索引)中这五个方法是按照怎样的顺序去执行的?
org.apache.lucene.index.DefaultIndexingChain lucene源码得出
问1:反向索引时是如何使用这五个方法的?
- 不分词:stringValue() [Sring Number],binaryValue();
- 分词:tokenStream、readerValue、stringValue,异常
问2:存储时是如何使用这五个方法的?
numericValue、binaryValue、stringValue
问3:docValues时是如何使用这五个方法的?
docValues:number、sort_number、numeric
其他:binry
- 上面的答案顺序就是代码中会执行的先后顺序
因为如果 docValues 中没有指定为 number 类型,那么也可以通过binry字节类型来加载。所以我们即使不是binary类型值,也要重写binayValue()获取。
加入数值字段方式:
- 扩展Field,提供构造方法传入数值类型值,赋给字段值字段;
- 改写binaryValue() 方法,返回数值的字节引用。
代码示例
在IndexableFieldType中最后定义的pointDimensionCount与pointNumBytes的作用是
Lucene6以后引入了点的概念来表示数值字段,废除了原来的IntField等。在Point
字段类中提供了精确、范围查询的便捷方法。
注意:只是引入点的概念,并未改变数值字段的本质。
既然是点,就有空间概念:维度。一维:一个值,二维:两个值的;……
pointDimensionCount() 返回点的维数
pointNumBytes() 返回点中数值类型的字节数。
一般适用于经纬度定位,地图等。
Lucene预定义的字段子类,你可灵活选用
- TextField: Reader or String indexed for full-text search
- StringField: String indexed verbatim as a single token
- IntPoint: int indexed for exact/range queries.
- LongPoint: long indexed for exact/range queries.
- FloatPoint: float indexed for exact/range queries.
- DoublePoint: double indexed for exact/range queries.
- SortedDocValuesField: byte[] indexed column-wise for sorting/faceting
- SortedSetDocValuesField: SortedSet
sorting/faceting - NumericDocValuesField: long indexed column-wise for sorting/faceting
- SortedNumericDocValuesField: SortedSet
indexed column-wise for
sorting/faceting - StoredField: Stored-only value for retrieving in summary results
- 请仔细看它们的源码是怎么设置字段的值、类别的。
注意:这里没有设置存储、词项向量的。
如果单个子类不满足需要,可多个组合。请参考 示例代码:IndexWriteDemo
如果组合不了,就直接用Field + FieldType
Field中提供那么多的setXXValue()方法,是什么意图?
setXXXValue()方法主要是为了重用Filed对象的,因为我们去给文档创建索引的时候是去循环创建很多的文档那么里面的字段是可以重复利用的。使用setXXXValue()就只需要改变里面的字段即可。
加入索引时,每个数据记录需要都创建一个Document吗?
Document只是一个容器里面放的是要索引或者存储的字段,那么创建之后就是可以重复利用的。所以只需要一个字段就可以了。
IndexWriter 索引更新API

说明:
- Term 词项 指定字段的词项
- 删除流程:根据Term、Query找到相关的文档id、同时删除索引信息,再根据文档id删除对应的文档存储。
- 更新流程:先删除、再加入新的doc。
- 注意:只可根据索引的字段进行更新。
示例代码:IndexUpdateDemo
总结