Prometheus时序数据库

系统环境
[ccli@pek tool]$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.1 (Maipo)
[ccli@pek tool]$ uname -a
Linux pek 3.10.0-229.1.2.el7.x86_64 #1 SMP Fri Mar 6 17:12:08 EST 2015 x86_64 x86_64 x86_64 GNU/Linux
软件下载源
https://github.com/prometheus/prometheus/releases/
https://github.com/prometheus/node_exporter/releases
https://grafana.com/grafana/download?platform=linux
https://prometheus.io/download/
Prometheus 部署
下载/安装
wget https://github.com/prometheus/prometheus/releases/download/v2.7.0/prometheus-2.7.0.linux-amd64.tar.gz
tar zxvf prometheus-2.7.0.linux-amd64.tar.gz
配置
主配置文件ccli.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
- "memory_over.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'testnodeexporter'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9100']
Rule Files
node_down.yml
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: caizh
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
memory_over.yml
groups:
- name: example
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
user: caizh
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 80% (current value is:{{ $value }})"
Node_exporter 部署
下载/安装
wget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
tar zxvf node_exporter-0.17.0.linux-amd64.tar.gz
Grafana 部署
下载/安装
wget https://dl.grafana.com/oss/release/grafana-5.4.3.linux-amd64.tar.gz
tar zxvf grafana-5.4.3.linux-amd64.tar.gz
AlertManagement 部署
下载/安装
wget https://github.com/prometheus/alertmanager/releases/download/v0.16.0/alertmanager-0.16.0.linux-amd64.tar.gz
tar zxvf alertmanager-0.16.0.linux-amd64.tar.gz
配置
global:
smtp_smarthost: 'xxx.email.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxx'
smtp_require_tls: false
route:
group_by: ['alertname']
group_interval: 1m
repeat_interval: 1h
receiver: live-monitoring
receivers:
- name: 'live-monitoring'
email_configs:
- to: '[email protected]'
Alert Mechanism Verification
Start alertmanager
./alertmanager --config.file='test.yml'
Start prometheus
./prometheus --config.file='ccli.yml'
Start node_exporter
./node_exporter
View Graph
http://192.168.0.224:9090/targets
Get status targets

Click Alerts

Stop node_exporter
kill node_exporter progress
View Alerts


接收到邮件sample

Draw Grafana Dashboard
Start prometheus
./prometheus --config.file='ccli.yml'
Start node_exporter
./node_exporter
Start Grafana
./bin/grafana-server -config conf/defaults.ini
Login Grafana by url
http://192.168.0.224:3000/
你会进入登录页面:

输入用户名admin, 密码admin,会提示是否change password, 选择skip,进入home Dashboard

点击Add data source, 如图:

选择Prometheus作为数据源,输入prometheus url, here 在192.168.0.224上搭建的 (你可以输入你自己Prometheus 机器ip),Access选择Browser, 然后save/test, 因此如图:

选择左边+号添加dashboard, 如图:

然后点击添加Graph, 如图:

然后edit dashboard, 如图:

Click General Tab, 编辑Panel Titel, enter test_cpu, 如图:

Click Metrics, 选择datasouce: Prometheus, query 选择node_cpu_seconds_total, 然后点击右上方save按钮,如图:
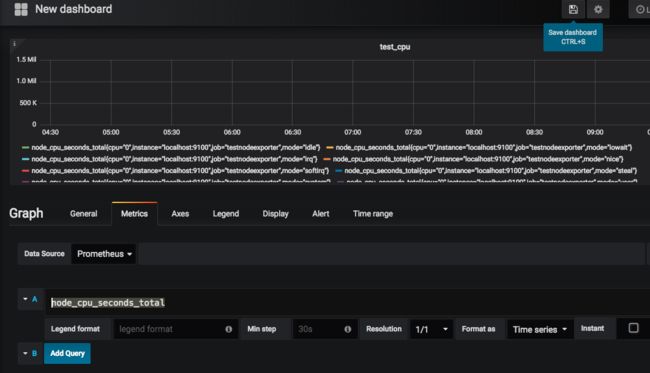
最后命名dashboard,如图:

对已经建好的dashboard,你可以添加更多panel,如图:

Reference
https://songjiayang.gitbooks.io/prometheus/content/exporter/nodeexporter_query.html