- Golang Memory Model
- 一、背景
- 1.1 一个 Code Review 引发的思考
- 1.2 什么是 Memory Model
- 二、CPU的高速缓存和流水线架构
- 2.1 CPU 缓存一致性
- 2.1.1 线程可见性问题
- 2.1.2 CPU 缓存一致性协议
- 2.1.3 为什么有 MESI 协议还会有缓存一致性问题
- 2.2 CPU 指令乱序执行
- 2.2.1 CPU 指令乱序执行验证 Demo
- 2.2.2 为什么CPU会乱序执行
- 2.2.3 什么是指令流水线
- 2.3.4 CPU 乱序执行
- 2.3.5 分支预测
- 2.3.5.1 分支预测 Demo
- 2.3.6 如何解决CPU会乱序执行
- 2.3.6.1 内存屏障(Memory barrier)
- 2.1 CPU 缓存一致性
- 三、 Golang 一致性原语
- 3.1 什么是Happens Before
- Init 函数
- Goroutine
- Channel
- Lock
- Atomic
- 3.2 Golang Happen Before 语义继承图
- 3.3 如何解决上面Golang Double Check的问题
- 3.1 什么是Happens Before
- 四、CPU Cache 扩展知识
- 4.1 CPU Cache 的产生背景
- 4.2 CPU Cache 模型
- 4.3 什么是 Cache Line
- 4.4 Flase Sharing 问题
- 4.5 如何解决False Sharding问题
- 4.6 CPU Cache 是如何存放数据的
- 4.7 CPU Cache 寻址过程
- 4.8 CPU Cache 三种寻址方式
- 4.9 CPU Cache 的组织方式
- VIVT(Virtual Index Virtual Tag)
- VIPT(Virtual Index Physical Tag)
- PIPT(Physical Index Physical Tag)
- 总结
- 参考资料
- 一、背景
一、背景
1.1 一个 Code Review 引发的思考
一个同学在 Golang 项目里面用 Double Check(不清楚的同学可以去百度搜下,Java中比较常见)的方式实现了一个单例。具体实现如下:
var (
lock sync.Mutex
instance *UserInfo
)
func getInstance() (*UserInfo, error) {
if instance == nil {
lock.Lock()
defer lock.Unlock()
if instance == nil {
instance = &UserInfo{
Name: "fan",
}
}
}
return instance, nil
}
这个代码第一眼看上去好像是标准的Double Check的写法,确没有什么问题,但是大佬Review代码的时候,指出这里会发生Data Race。我用 go run -race go_race2.go 检查的确有Data Race的警告:
==================
WARNING: DATA RACE
Read at 0x00000120d9c0 by goroutine 8:
main.getInstance()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:42 +0x4f
main.main.func1()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:24 +0x44
Previous write at 0x00000120d9c0 by goroutine 7:
main.getInstance()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:49 +0x169
main.main.func1()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:24 +0x44
Goroutine 8 (running) created at:
main.main()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:23 +0xab
Goroutine 7 (finished) created at:
main.main()
/Users/fl/go/src/github.com/fl/GolangDemo/GoTest/go_race2.go:23 +0xab
==================
警告中指明在多线程执行getInstance这个方法的时候,在if instance == nil { 这一行会发生data race。这个为什么在这一行会有data race,我们后面再说。
其实搞Java的同学很快可以看出这段代码的问题,Java中的Double Check来实现单例模式的时候都会使用volatile来修饰变量,volatile主要做的事就是保证线程可见性和禁止指令重排序。其实这两个主要就是Memory Model描述的事情。
1.2 什么是 Memory Model
Java和C++的同学可能会熟悉一些,其他很多同学第一次听到这个单词的时候,潜意识翻译成中文就是内存模型,好像是讲的一个内存数据结构相关的东西。某度上搜索Memory Model出来更多是不相干东西。我们看下wikipedia上的解释:
In computing, a memory model describes the interactions of threads through memory and their shared use of the data.
直接翻译过来就是:在计算中,内存模型描述了多线程如何通过内存的交互来共享数据
看下Golang官方文档的解释:The Go Memory Model
The Go memory model specifies the conditions under which reads of a variable in one goroutine can be guaranteed to observe values produced by writes to the same variable in a different goroutine.
翻译下就是:Go内存模型指定了某些条件,在这种条件下,可以保证一个共享变量,在一个goroutine(线程)中写入,可以在另外一个线程被观察到。
Memory Model 其实是一个概念,表示在多线程场景下,如何保证数据同步的正确性。 为什么多线程读取共享内存变量的时候会有数据同步正确性问题呢,这里主要涉及到CPU缓存一致性问题和CPU乱序执行的问题,
各个语言对Memory Model实现方式各不相同,对其他语言感兴趣的同学可以去搜索下相关资料。
Java Memory Model
C++ Memory Model
《C++ Concurrency in Action》第五章 (大佬推荐的书)
二、CPU的高速缓存和流水线架构
2.1 CPU 缓存一致性
2.1.1 线程可见性问题
我们先看一下这个线程可见性的测试DEMO
func main() {
running := true
go func() {
println("thread1 start")
count := 1
for running {
count++
}
println("thread1 end : count = ", count) //这个循环永远也不会结束,为什么?
}()
go func() {
println("start thread2")
for {
running = false
}
}()
time.Sleep(time.Hour)
return
}
我分别用
Java Demo
Objective-C Demo
C Demo
测试了下,跟Golang的执行的效果一致,thread1 永远也不会停止。(C和Objective-C用Xcode跑的时候需要用Release模式,因为Debug和Release的-O优化级别不一样,-O优化详见)。
为什么在一个线程修改了共享变量,另外一个线程感知不到呢?这里我们需要了解下CPU的Cache结构。
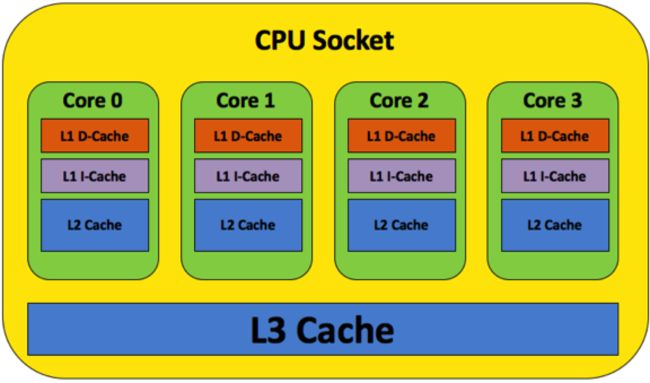
现代多核CPU的Cache模型基本都跟上图所示一样,L1 L2 cache是每个核独占的,只有L3是共享的,当多个CPU读、写同一个变量时,就需要在多个CPU的Cache之间同步数据,跟分布式系统一样,必然涉及到一致性的问题。
2.1.2 CPU 缓存一致性协议
在MESI(还有MSI、MESIF等等)协议中,每个Cache line(Cache Line的概念后面会补充介绍)有4个状态,可用2个bit表示,它们分别是:
- 失效(Invalid)缓存段,要么已经不在缓存中,要么它的内容已经过时。为了达到缓存的目的,这种状态的段将会被忽略。一旦缓存段被标记为失效,那效果就等同于它从来没被加载到缓存中。
- 共享(Shared)缓存段,它是和主内存内容保持一致的一份拷贝,在这种状态下的缓存段只能被读取,不能被写入。多组缓存可以同时拥有针对同一内存地址的共享缓存段,这就是名称的由来。
- 独占(Exclusive)缓存段,和 S 状态一样,也是和主内存内容保持一致的一份拷贝。区别在于,如果一个处理器持有了某个 E 状态的缓存段,那其他处理器就不能同时持有它,所以叫“独占”。这意味着,如果其他处理器原本也持有同一缓存段,那么它会马上变成“失效”状态。
- 已修改(Modified)缓存段,属于脏段,它们已经被所属的处理器修改了。如果一个段处于已修改状态,那么它在其他处理器缓存中的拷贝马上会变成失效状态,这个规律和 E 状态一样。此外,已修改缓存段如果被丢弃或标记为失效,那么先要把它的内容回写到内存中——这和回写模式下常规的脏段处理方式一样。
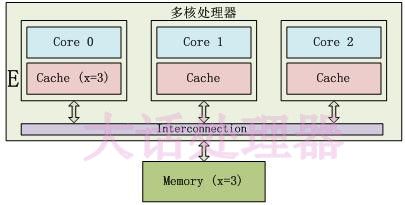
只有Core 0访问变量x,它的Cache line状态为E(Exclusive):
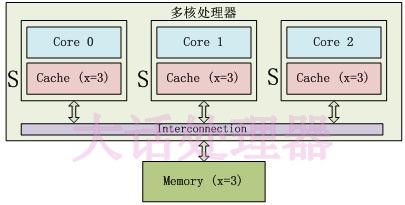
3个Core都访问变量x,它们对应的Cache line为S(Shared)状态:
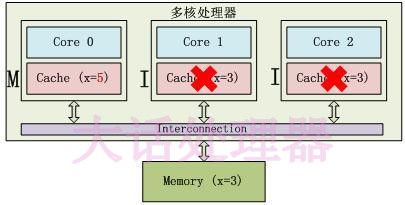
Core 0修改了x的值之后,这个Cache line变成了M(Modified)状态,其他Core对应的Cache line变成了I(Invalid)状态 :
在MESI协议中,每个Cache的Cache控制器不仅知道自己的读写操作,而且也监听(snoop)其它Cache的读写操作。每个Cache line所处的状态根据本核和其它核的读写操作在4个状态间进行迁移。
更多可以看 《大话处理器》Cache一致性协议之MESI 这篇文章介绍。
2.1.3 为什么有 MESI 协议还会有缓存一致性问题
由上面的MESI协议,我们可以知道如果满足下面两个条件,你就可以得到完全的顺序一致性:
- 缓存一收到总线事件,就可以在当前指令周期中迅速做出响应.
- 处理器如实地按程序的顺序,把内存操作指令送到缓存,并且等前一条执行完后才能发送下一条。
当然,实际上现代处理器一般都无法满足以上条件,主要原因有:
- 缓存不会及时响应总线事件。如果总线上发来一条消息,要使某个缓存段失效,但是如果此时缓存正在处理其他事情(比如和 CPU 传输数据),那这个消息可能无法在当前的指令周期中得到处理,而会进入所谓的“失效队列(invalidation queue)”,这个消息等在队列中直到缓存有空为止。
- 处理器一般不会严格按照程序的顺序向缓存发送内存操作指令。当然,有乱序执行(Out-of-Order execution)功能的处理器肯定是这样的。顺序执行(in-order execution)的处理器有时候也无法完全保证内存操作的顺序(比如想要的内存不在缓存中时,CPU 就不能为了载入缓存而停止工作)。
- 写操作尤其特殊,因为它分为两阶段操作:在写之前我们先要得到缓存段的独占权。如果我们当前没有独占权,我们先要和其他处理器协商,这也需要一些时间。同理,在这种场景下让处理器闲着无所事事是一种资源浪费。实际上,写操作首先发起获得独占权的请求,然后就进入所谓的由“写缓冲(store buffer)”组成的队列(有些地方使用“写缓冲”指代整个队列,我这里使用它指代队列的一条入口)。写操作在队列中等待,直到缓存准备好处理它,此时写缓冲就被“清空(drained)”了,缓冲区被回收用于处理新的写操作。
这些特性意味着,默认情况下,读操作有可能会读到过时的数据(如果对应失效请求还等在队列中没执行),写操作真正完成的时间有可能比它们在代码中的位置晚,一旦牵涉到乱序执行,一切都变得模棱两可。
可以看 缓存一致性(Cache Coherency)入门 这篇文章了解更多。
2.2 CPU 指令乱序执行
2.2.1 CPU 指令乱序执行验证 Demo
func main() {
count := 0
for {
x, y, a, b := 0, 0, 0, 0
count++
var wg sync.WaitGroup
wg.Add(2)
go func() {
a = 1
x = b
println("thread1 done ", count)
wg.Done()
}()
go func() {
b = 1
y = a
println("thread2 done ", count)
wg.Done()
}()
wg.Wait()
if x == 0 && y == 0 {
println("执行次数 :", count)
break
}
}
}
...
thread2 done 11061
thread1 done 11061
执行次数 : 11061 // 执行了11061次以后出现了 x=0、y=0的情况
上面demo中我在线程1和线程2中,先分别让a = 1、b = 1,再让x = b、y = a,如果CPU是按顺序执行这些指令的话,无论线程一和线程二中的如何而组合先后执行,永远也不会得到 x = 0、 y = 0的情况。CPU 为什么会发生乱序呢?我们先了解下CPU 指令流水线
2.2.2 为什么CPU会乱序执行
我们知道对于CPU性能有以下公式
CPU性能=IPC(CPU每一时钟周期内所执行的指令多少)×频率(MHz时钟速度)
由上述公式我们可以知道,提高CPU性能要么就提高主频,要么就提高IPC(每周期执行的指令数).提升IPC有两种做法,一个是增加单核并行的度,一个是加多几个核。单核CPU增加并行度的主要方式是采用流水线设计。
2.2.3 什么是指令流水线
先看 wikipedia 解释
指令流水线(英语:Instruction pipeline)是为了让计算机和其它数字电子设备能够加速指令的通过速度(单位时间内被运行的指令数量)而设计的技术。
流水线在处理器的内部被组织成层级,各个层级的流水线能半独立地单独运作。每一个层级都被管理并且链接到一条“链”,因而每个层级的输出被送到其它层级直至任务完成。 处理器的这种组织方式能使总体的处理时间显著缩短。
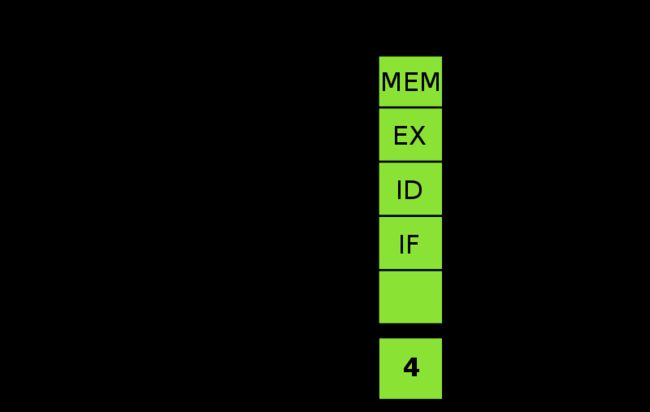
流水线化则是实现各个工位不间断执行各自的任务,例如同样的四工位设计,指令拾取无需等待下一工位完成就进行下一条指令的拾取,其余工位亦然。
理想很丰满,现实很骨感,上述图示中的状态只是极为理想中的情况。流水线在运作过程中会遇到以下的问题:
- RISC 指令集具备指令编码格式统一、指令都在一周期内完成等特点,在流水线设计设计上有得天独厚的优势。但是非等长不定周期的 CISC(例如 x86 的指令长度为 1 个字节到 17 个字节不等)想要达到上图中紧凑高效的流水线形式就比较困难了,在执行的过程中肯定会存在气泡(存在空闲的流水线工位)。
- 如果连续指令之间存在依赖关系(如 a=1,b=a)那么这两条指令不能使用流水线,必须等 a=1执行完毕后才能执行 b=a。在这里也产生了很大的一个气泡。
- 如果指令存在条件分支,那么CPU不知道要往哪里执行,那么流水线也要停掉,等条件分支的判断结果出来。大气泡~
为了解决上述的问题,工程师们设计了以下的技术:
- 乱序执行
- 分支预测
2.3.4 CPU 乱序执行
乱序执行就是说把原来有序执行的指令列表,在保证执行结果一致的情况下根据指令依赖关系及指令执行周期重新安排执行顺序。例如以下指令(a = 1; b = a; c = 2; d = c)在CPU中就很可能被重排序成为以下的执行顺序(a = 1;c = 2;b = a;d = c;),这样的话,4条指令都可以高效的在流水线中运转了。
注意:CPU只会没有依赖关系的语句进行乱序执行。并不会对 x = 1 ,y = x 这种语句进行乱序
虽然乱序执行提高了CPU的执行效率,但是却带来了另外一个问题。就是在多核多线程环境中,若线程A执行(a = 1,x = b)优化成了(x = b, a= 1)的话,线程B执行(b = 1,y = a)被优化成了(y = 1, b = 1), 所以就得到了(x = 0,y = 0)这种结果
2.3.5 分支预测
分支预测(Branch predictor):当处理一个分支指令时,有可能会产生跳转,从而打断流水线指令的处理,因为处理器无法确定该指令的下一条指令,直到分支指令执行完毕。流水线越长,处理器等待时间便越长,分支预测技术就是为了解决这一问题而出现的。因此,分支预测是处理器在程序分支指令执行前预测其结果的一种机制。
采用分支预测,处理器猜测进入哪个分支,并且基于预测结果来取指、译码。如果猜测正确,就能节省时间,如果猜测错误,大不了从头再来,刷新流水线,在新的地址处取指、译码。
分支预测有很多方式,详见Wikipedia
2.3.5.1 分支预测 Demo
func main() {
data := make([]int, 32678)
for i := 0; i < len(data); i++ {
data[i] = rand.Intn(256)
}
sort.Sort(sort.IntSlice(data))// Sort和非Sort
now := time.Now()
count := 0
for i := 0; i < len(data); i++ {
if data[i] > 128 {
count += data[i]
}
}
end := time.Since(now)
fmt.Println("time : ", end.Microseconds(), "ms count = ", count)
}
sort :time : 112 ms count = 3101495
非Sort:time : 290 ms count = 3101495
简单地分析一下:
有序数组的分支预测流程:
T = 分支命中
N = 分支没有命中
data[] = 0, 1, 2, 3, 4, ... 126, 127, 128, 129, 130, ... 250, 251, 252, ...
branch = N N N N N ... N N T T T ... T T T ...
= NNNNNNNNNNNN ... NNNNNNNTTTTTTTTT ... TTTTTTTTTT (非常容易预测)
无序数组的分支预测流程:
data[] = 226, 185, 125, 158, 198, 144, 217, 79, 202, 118, 14, 150, 177, 182, 133, ...
branch = T, T, N, T, T, T, T, N, T, N, N, T, T, T, N ...
= TTNTTTTNTNNTTTN ... (完全随机--无法预测)
2.3.6 如何解决CPU会乱序执行
2.3.6.1 内存屏障(Memory barrier)
内存屏障(Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,它使得 CPU 或编译器在对内存进行操作的时候, 严格按照一定的顺序来执行, 也就是说在memory barrier 之前的指令和memory barrier之后的指令不会由于系统优化等原因而导致乱序。
内存屏障是底层原语,是内存排序的一部分,在不同体系结构下变化很大而不适合推广。需要认真研读硬件的手册以确定内存屏障的办法。x86指令集中的内存屏障指令是:
lfence (asm), void _mm_lfence (void) 读操作屏障
sfence (asm), void _mm_sfence (void)[1] 写操作屏障
mfence (asm), void _mm_mfence (void)[2] 读写操作屏障
有部分语言的一致性原语是通过上面几个命令来保证的。
三、 Golang 一致性原语
3.1 什么是Happens Before
Happens Before 是Memory Model中一个通用的概念。主要是用来保证内存操作的可见性。如果要保证E1的内存写操作能够被E2读到,那么需要满足:
- E1 Happens Before E2;
- 其他所有针对此内存的写操作,要么Happens Before E1,要么Happens After E2。也就是说不能存在其他的一个写操作E3,这个E3 Happens Concurrently E1/E2。
让我们再回头来看下官方文档 The Go Memory Model,里面讲到, golang 中有数个地方实现了 Happens Before 语义,分别是 init函数、goruntine 的创建、goruntine 的销毁、channel 通讯、锁、sync、sync/atomic.
Init 函数
- 如果包
P1中导入了包P2,则P2中的init函数Happens Before所有P1中的操作 -
main函数Happens After所有的init函数
Goroutine
-
Goroutine的创建Happens Before所有此Goroutine中的操作 -
Goroutine的销毁Happens After所有此Goroutine中的操作
Channel
-
channel底层实现主要是由ringbuf、sendqueue、recequeue、mutex组成。 - 内部实现主要是使用锁来保证一致性,但这把锁并不是标准库里的锁,而是在 runtime 中自己实现的一把更加简单、高效的锁。
Lock
Go里面有Mutex和RWMutex两种锁,RWMutex是在Mutex基础上实现的。所以这里主要说下Mutex。
Mutex是一个公平锁,有正常模式和饥饿模式两种状态。看下mutex结构体
type Mutex struct {
// 第0位:表示是否加锁,第1位:表示有 goroutine被唤醒,尝试获取锁; 第2位:是否为饥饿状态。
state int32
// semaphore,锁的信号量。
// 一般通过runtime_SemacquireMutex来获取、runtime_Semrelease来释放
sema uint32
}
在看下Mutex加锁是怎么实现的
func (m *Mutex) Lock() {
// 先CAS判断是否加锁成功,成就返回
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// lockSlow 里面主要是尝试自旋、正常模式、饥饿模式切换
m.lockSlow()
}
sync.Mutex底层都是使用Atomic来读写锁的状态。所以我们可以理解为,Mutex都是基于Atomic来实现Happens Before语义。我们下面来看下Atomic是如何实现的。
Atomic
func main() {
i := int64(2)
atomic.AddInt64(&i, 2)
}
go tool compile -S -l -N main2.go
0x0037 00055 (main2.go:8) MOVQ $2, (AX)
0x003e 00062 (main2.go:9) PCDATA $0, $1
0x003e 00062 (main2.go:9) PCDATA $1, $0
0x003e 00062 (main2.go:9) MOVQ "".&i+16(SP), AX
0x0043 00067 (main2.go:9) MOVL $2, CX
0x0048 00072 (main2.go:9) PCDATA $0, $0
0x0048 00072 (main2.go:9) LOCK
0x0049 00073 (main2.go:9) XADDQ CX, (AX)
0x004d 00077 (main2.go:10) PCDATA $0, $-2
用go tool compile -S导出汇编可以看出第9行代码atomic.AddInt64其实是一条带Lock前缀的XADDQ指令。让我们看一看 LOCK 的具体意义,在 英特尔开发人员手册 中,我们到了如下的解释:
The I/O instructions, locking instructions, the LOCK prefix, and serializing instructions force stronger orderingon the processor.
Memory mapped devices and other I/O devices on the bus are often sensitive to the order of writes to their I/O buffers. I/O instructions can be used to (the IN and OUT instructions) impose strong write ordering on suchaccesses as follows. Prior to executing an I/O instruction, the processor waits for all previous instructions in theprogram to complete and for all buffered writes to drain to memory. Only instruction fetch and page tables walkscan pass I/O instructions. Execution of subsequent instructions do not begin until the processor determines thatthe I/O instruction has been completed.
从描述中,我们了解到:LOCK 指令前缀提供了强一致性的内(缓)存读写保证,可以保证 LOCK 之后的指令在带 LOCK 前缀的指令执行之后才会执行。同时,我们在手册中还了解到,现代的 CPU 中的 LOCK 操作并不是简单锁 CPU 和主存之间的通讯总线, Intel 在 cache 层实现了这个 LOCK 操作,因此我们也无需为 LOCK 的执行效率担忧。
更多可以参考探索 Golang 一致性原语
3.2 Golang Happen Before 语义继承图
+----------+ +-----------+ +---------+
| sync.Map | | sync.Once | | channel |
++---------+++---------+-+ +----+----+
| | | |
| | | |
+------------+ | +-----------------+ | |
| | | | +v--------+ | |
| WaitGroup +---+ | RwLock| Mutex | | +------v-------+
+------------+ | +-------+---------+ | | runtime lock |
| | +------+-------+
| | |
| | |
| | |
+------+v---------------------v +------v-------+
| LOAD | other atomic action | |runtime atomic|
+------+--------------+-------+ +------+-------+
| |
| |
+------------v------------------v+
| LOCK prefix |
+--------------------------------+
3.3 如何解决上面Golang Double Check的问题
var (
lock sync.Mutex
instance *UserInfo
)
func getInstance() (*UserInfo, error) {
if instance == nil {
//---Lock
lock.Lock()
defer lock.Unlock()
if instance == nil {
instance = &UserInfo{
Name: "fan",
}
}
}//---Unlock()
return instance, nil
}
再看下这段有问题的代码,由上面的Golang Happy Before一致性原语我们知道,instance修改在lock临界区里面,其他的线程是可见的。那为什么在 if instance == nil还是会发生Data Race呢?
真正的原因是是在instance = &UserInfo{Name: "fan"}这句代码,这句代码并不是原子操作,这个赋值可能是会有几步指令,比如
- 先
new一个UserInfo - 然后设置
Name=fan - 最后把了
new的对象赋值给instance
如果这个时候发生了乱序,可能会变成
- 先了
new一个UserInfo - 然后再赋值给
instance - 最后再设置
Name=fan
A进程进来的时候拿到锁,然后对instance进行赋值,这个时候instance对象是一个半初始化状态的数据,线程B来的时候判断if instance == nil发现不为nil就直接吧半初始化状态的数据返回了,所以会有问题。
下面是instance = &UserInfo{Name: "fan"}这个代码对应的Golang的汇编指令
0x00bc 00188 (main2.go:29) LEAQ type."".UserInfo(SB), AX
0x00c3 00195 (main2.go:29) PCDATA $0, $0
0x00c3 00195 (main2.go:29) MOVQ AX, (SP)
0x00c7 00199 (main2.go:29) CALL runtime.newobject(SB)
0x00cc 00204 (main2.go:29) PCDATA $0, $2
0x00cc 00204 (main2.go:29) MOVQ 8(SP), DI
0x00d1 00209 (main2.go:29) PCDATA $1, $2
0x00d1 00209 (main2.go:29) MOVQ DI, ""..autotmp_2+72(SP)
0x00d6 00214 (main2.go:29) MOVQ $3, 8(DI)
0x00de 00222 (main2.go:29) PCDATA $0, $-2
0x00de 00222 (main2.go:29) PCDATA $1, $-2
0x00de 00222 (main2.go:29) CMPL runtime.writeBarrier(SB), $0
0x00e5 00229 (main2.go:29) JEQ 233
0x00e7 00231 (main2.go:29) JMP 286
0x00e9 00233 (main2.go:29) LEAQ go.string."fan"(SB), CX
0x00f0 00240 (main2.go:29) MOVQ CX, (DI)
0x00f3 00243 (main2.go:29) JMP 245
0x00f5 00245 (main2.go:28) PCDATA $0, $1
0x00f5 00245 (main2.go:28) PCDATA $1, $1
0x00f5 00245 (main2.go:28) MOVQ ""..autotmp_2+72(SP), AX
0x00fa 00250 (main2.go:28) PCDATA $0, $-2
0x00fa 00250 (main2.go:28) PCDATA $1, $-2
0x00fa 00250 (main2.go:28) CMPL runtime.writeBarrier(SB), $0
0x0101 00257 (main2.go:28) JEQ 261
0x0103 00259 (main2.go:28) JMP 272
0x0105 00261 (main2.go:28) MOVQ AX, "".instance(SB)
0x010c 00268 (main2.go:28) JMP 270
0x010e 00270 (main2.go:29) JMP 186
0x0110 00272 (main2.go:28) LEAQ "".instance(SB), DI
0x0117 00279 (main2.go:28) CALL runtime.gcWriteBarrier(SB)
0x011c 00284 (main2.go:28) JMP 270
0x011e 00286 (main2.go:29) LEAQ go.string."fan"(SB), AX
0x0125 00293 (main2.go:29) CALL runtime.gcWriteBarrier(SB)
0x012a 00298 (main2.go:29) JMP 245
知道了原因,我们可以直接用Atomic.Value来保证可见性和原子性就行了,改造代码如下:
var flag uint32
func getInstance() (*UserInfo, error) {
if atomic.LoadUint32(&flag) != 1 {
lock.Lock()
defer lock.Unlock()
if instance == nil {
// 其他初始化错误,如果有错误可以直接返回
instance = &UserInfo{
Age: 18,
}
atomic.StoreUint32(&flag, 1)
}
}
return instance, nil
}
再次用go run -race go_race2.go 检查发现已经没有警告了。
四、CPU Cache 扩展知识
4.1 CPU Cache 的产生背景
计算机中的所有运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入,这些数据只能来自于计算机主存(通常指RAM)。
CPU的处理速度和内存的访问速度差距巨大,直连内存的访问方式使得CPU资源没有得到充分合理的利用,于是产生了在CPU与主存之间增加高速缓存CPU Cache的设计。
4.2 CPU Cache 模型
CPU Cache模型,缓存分为三级L1/L2/L3,由于指令和数据的行为和热点分布差异很大,因此将L1按照用途划分为L1i(instruction)和L1d(data).
在多核CPU的结构中,L1和L2是CPU私有的,L3则是所有CPU共享的。
4.3 什么是 Cache Line
Cache line 是 Cache 和 RAM 交换数据的最小单位,通常为 64 Byte。当 CPU 把内存的数据载入 Cache 时,会把临近的共 64 Byte 的数据一同放入同一个Cache line,因为空间局部性:临近的数据在将来被访问的可能性大。
由于CPU Cache缓存数据最小的单位是一个Cache Line(64节),如果两个Core读取了同一个Cache Line,并对Cache Line中的数据频繁读写,就会有Flase Sharing的问题。
4.4 Flase Sharing 问题
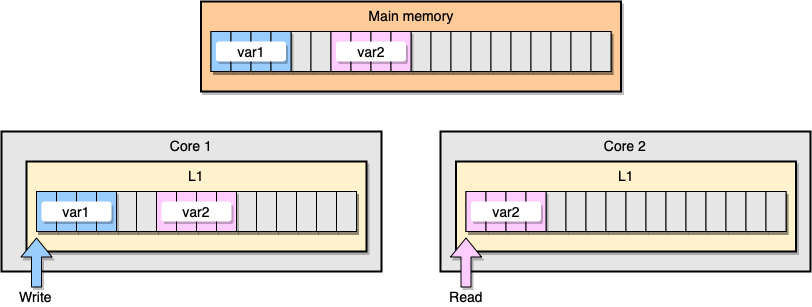
上图中 thread1 位于 core1 ,而 thread2 位于 core2 ,二者均想更新彼此独立的两个变量,但是由于两个变量位于不同核心中的同一个 L1 缓存行中,此时可知的是两个缓存行的状态应该都是 Shared ,而对于同一个缓存行的操作,不同的 core 间必须通过发送 RFO 消息来争夺所有权 (ownership) ,如果 core1 抢到了, thread1 因此去更新该缓存行,把状态变成 Modified ,那就会导致 core2 中对应的缓存行失效变成 Invalid ,当 thread2 取得所有权之后再去更新该缓存行时必须先让 core1 把对应的缓存行刷回 L3 缓存/主存,然后它再从 L3 缓存/主存中加载该缓存行进 L1 之后才能进行修改。然而,这个过程又会导致 core1 对应的缓存行失效变成 Invalid ,这个过程将会一直循环发生,从而导致 L1 高速缓存并未起到应有的作用,反而会降低性能;轮番夺取所有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据,而从前面的内容可以知道,L3 的读取速度相比 L1/L2 要慢了数十倍,性能下降很大;更坏的情况是跨槽读取,L3 都不能命中,只能从主存上加载,那就更慢了。
CPU 缓存的最小的处理单位永远是缓存行 (Cache Line),所以当某个核心发送 RFO 消息请求把其他核心对应的缓存行设置成Invalid 从而使得 var1 缓存失效的同时,也会导致同在一个缓存行里的 var2 失效,反之亦然。
Cache Line缓存测试
func main() {
arr := make([][]int, 64*1024)
for i := 0; i < len(arr); i++ {
arr[i] = make([]int, 1024)
}
now := time.Now()
for i := 0; i < len(arr); i++ {
for j := 0; j < 1024; j++ {
arr[i][j]++
}
}
timeSpan := time.Since(now).Microseconds()
fmt.Println("横向遍历耗时:", timeSpan)
now = time.Now()
for j := 0; j < 1024; j++ {
for i := 0; i < len(arr); i++ {
arr[i][j]++
}
}
timeSpan = time.Since(now).Microseconds()
fmt.Println("纵向遍历耗时:", timeSpan)
}
横向遍历耗时: 485995 //因为横向写数据的时候,会一直命中CPU缓存,所以比纵向更快一些
纵向遍历耗时: 1705150
4.5 如何解决False Sharding问题
对一些热点数据,如果想避免cache line被其他Core设置为失效,可以通过Pading的方式把每个项凑齐cache line的长度,即可实现隔离,虽然这不可避免的会浪费一些内存。
我们可以看到golang的源码里面 p struct的也用了CacheLinePad的方式来避免了False Sharding的问题
type p struct {
上面省略
.....
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad cpu.CacheLinePad
}
CacheLinePad 是cpu包下面定义的一个64字节的数组
const CacheLinePadSize = 64
// CacheLinePad is used to pad structs to avoid false sharing.
type CacheLinePad struct{ _ [CacheLinePadSize]byte }
这样能保证p的数据不管怎么拼接都不会跟其他数据在同一个cache line中。
4.6 CPU Cache 是如何存放数据的
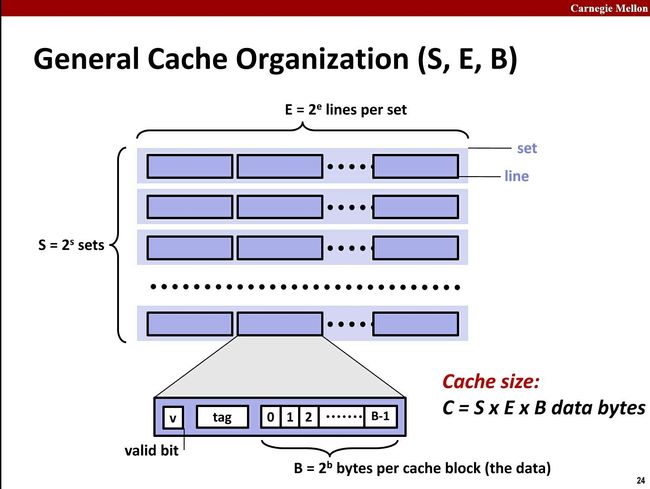
由上图可以知Cache是由Set组成,Set由Cache Line组成,Cache Line由Valid Bit(MESI协议中这个是2个字节),Tag和Data组成。其中Data是真正要缓存的内存地址中的数据,而Tag是用来搜索Cache Line的标签。
假设L1 Cache总大小为32KB,8路组相连(每个Set有8个Cache Line),每个Cache Line的大小为64Byte。
我们可以得到一个
Set大小 = 8 * Cache Line(64) = 512Byte
Set个数 = 32*1024 /512 = 64
Cache Line Count = 32*1024 / 64 = 512个
虚拟地址64位最终通过MMU转换为物理地址52位,所以52位地址各个位表现形式如下:
Tag 40 | SetIndex: 6 | Offset:6
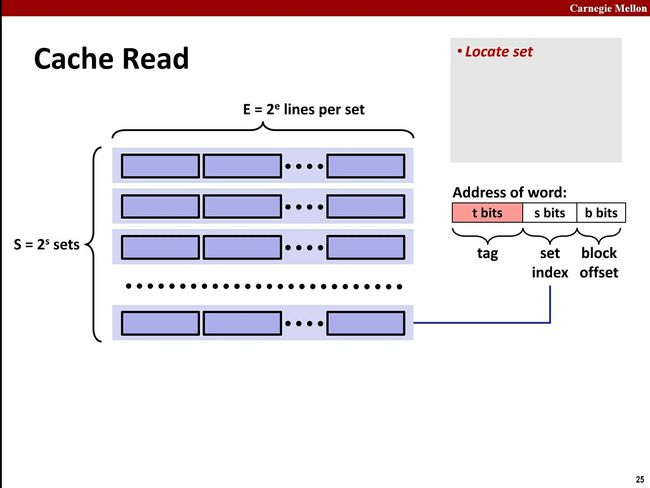
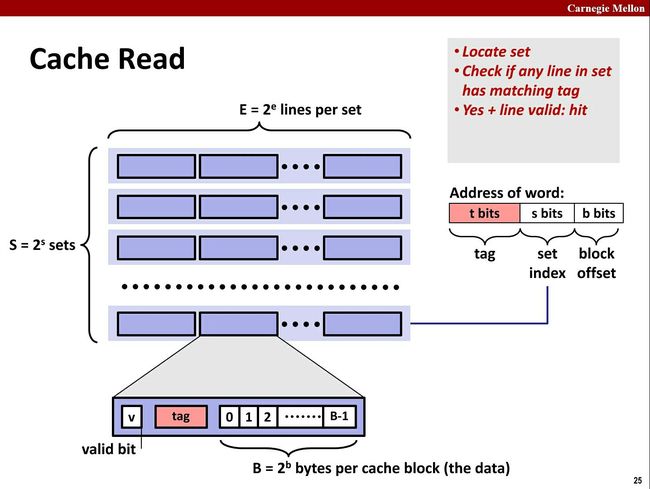
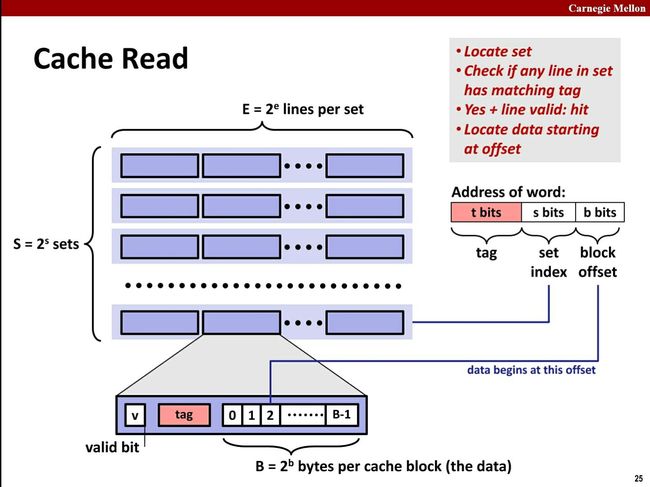
4.7 CPU Cache 寻址过程
先看下内存地址表示的含义
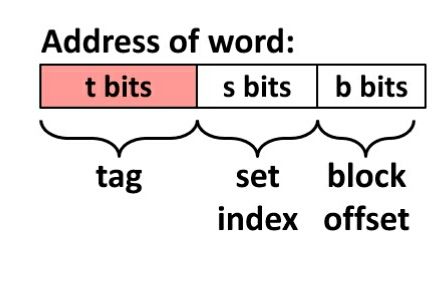
内存被分成了TAG、Set Index、Block Offset 三部分。
- 根据地址中的Set Index找到对应的缓存中对应的Set
- 根据Tag与Set中所有CacheLine的Tag一一对比,遇到相等的表示找到缓存。
- 查看Cache Line 的Validate Bit是不是有效的。有效的表示命中Cache。
- 根据Block Offset读取Cache Line中Block Data对应的值。
4.8 CPU Cache 三种寻址方式
- 直接映射(
direct mapped cache),相当于每个set只有1个cache line(E=1)。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cache line中。 - 组关联(
set associative cache),多个set,每个set多个cache line。一般每个set有n个cache line,就说n-ways associative cache。 - 全相联(
fully associative cache),相当于只有1个set,每个内存单元都能映射到任意的cache line。带有这样cache的处理器几乎没有。可以想见这种方式不适合大的缓存。想想看,如果4M 的大缓存 linesize为32Byte,采用全相联的话,就意味着4 * 1024 * 1024/32 = 128K 个line挨个比较,来确定是否命中,这是多要命的事情。
4.9 CPU Cache 的组织方式
VIVT(Virtual Index Virtual Tag)
使用虚拟地址做索引,虚拟地址做Tag。早期的ARM处理器一般采用这种方式,在查找cache line过程中不借助物理地址,这种方式会导致cache别名(cache alias)问题。比如当两个虚拟地址对应相同物理地址,并且没有映射到同一cache行,那么就会产生问题。另外,当发生进程切换时,由于页表可能发生变化,所以要对cache进行invalidate等操作,效率较低。
歧义(ambiguity)
相同的虚拟地址映射不同的物理地址就会出现歧义,操作系统如何避免歧义的发生呢?当我们切换进程的时候,可以选择flush所有的cache。flush cache操作有两种: - 使主存储器有效。针对write back高速缓存,首先应该使主存储器有效,保证已经修改数据的cacheline写回主存储器,避免修改的数据丢失。 - 使高速缓存无效。保证切换后的进程不会错误的命中上一个进程的缓存数据。
因此,切换后的进程刚开始执行的时候,将会由于大量的cache miss导致性能损失。所以,VIVT高速缓存明显的缺点之一就是经常需要flush cache以保证歧义不会发生,最终导致性能的损失。VIVT高速缓存除了面对歧义问题外,还面临另一个问题:别名(alias)。
别名(alias)
当不同的虚拟地址映射相同的物理地址,而这些虚拟地址的index不同,此时就发生了别名现象(多个虚拟地址被称为别名)。通俗点来说就是指同一个物理地址的数据被加载到不同的cacheline中就会出现别名现象
针对共享数据所在页的映射方式采用nocache映射。例如上面的例子中,0x2000和0x4000映射物理地址0x8000的时候都采用nocache的方式,这样不通过cache的访问,肯定可以避免这种问题。但是这样就损失了cache带来的性能好处。这种方法既适用于不同进程共享数据,也适用于同一个进程共享数据。 如果是不同进程之间共享数据,还可以在进程切换时主动flush cache(使主存储器有效和使高速缓存无效)的方式避免别名现象。但是,如果是同一个进程共享数据该怎么办?除了nocache映射之外,还可以有另一种解决方案。这种方法只针对直接映射高速缓存,并且使用了写分配机制有效。在建立共享数据映射时,保证每次分配的虚拟地址都索引到相同的cacheline。这种方式,后面还会重点说。
VIPT(Virtual Index Physical Tag)
使用虚拟地址做索引,物理地址做Tag。在利用虚拟地址索引cache同时,同时会利用TLB/MMU将虚拟地址转换为物理地址。然后将转换后的物理地址,与虚拟地址索引到的cache line中的Tag作比较,如果匹配则命中。这种方式要比VIVT实现复杂,当进程切换时,不在需要对cache进行invalidate等操作(因为匹配过程中需要借物理地址)。但是这种方法仍然存在cache别名的问题(即两个不同的虚拟地址映射到同一物理地址,且位于不同的cache line),但是可以通过一定手段解决。
VIPT Cache什么情况不存在别名
我们知道VIPT的优点是查找cache和MMU转换虚拟地址同时进行,所以性能上有所提升。歧义问题虽然不存在了,但是别名问题依旧可能存在,那么什么情况下别名问题不会存在呢?Linux系统中映射最小的单位是页,一页大小是4KB。那么意味着虚拟地址和其映射的物理地址的位<11...0>是一样的。针对直接映射高速缓存,如果cache的size小于等于4KB,是否就意味着无论使用虚拟地址还是物理地址的低位查找cache结果都是一样呢?是的,因为虚拟地址和物理地址对应的index是一样的。这种情况,VIPT实际上相当于PIPT,软件维护上和PIPT一样。如果示例是一个四路组相连高速缓存呢?只要满足一路的cache的大小小于等于4KB,那么PIPT方式的cache也不会出现别名问题。
VIPT Cache的别名问题
假设系统使用的是直接映射高速缓存,cache大小是8KB,cacheline大小是256字节。这种情况下的VIPT就存在别名问题。因为index来自虚拟地址位<12...8>,虚拟地址和物理地址的位<11...8>是一样的,但是bit12却不一定相等。 假设虚拟地址0x0000和虚拟地址0x1000都映射相同的物理地址0x4000。那么程序读取0x0000时,系统将会从物理地址0x4000的数据加载到第0x00行cacheline。然后程序读取0x1000数据,再次把物理地址0x4000的数据加载到第0x10行cacheline。这不,别名出现了。相同物理地址的数据被加载到不同cacheline中。
如何解决VIPT Cache别名问题
我们接着上面的例子说明。首先出现问题的场景是共享映射,也就是多个虚拟地址映射同一个物理地址才可能出现问题。我们需要想办法避免相同的物理地址数据加载到不同的cacheline中。如何做到呢?那我们就避免上个例子中0x1000映射0x4000的情况发生。我们可以将虚拟地址0x2000映射到物理地址0x4000,而不是用虚拟地址0x1000。0x2000对应第0x00行cacheline,这样就避免了别名现象出现。因此,在建立共享映射的时候,返回的虚拟地址都是按照cache大小对齐的地址,这样就没问题了。如果是多路组相连高速缓存的话,返回的虚拟地址必须是满足一路cache大小对齐。在Linux的实现中,就是通过这种方法解决别名问题。
PIPT(Physical Index Physical Tag)
使用物理地址做索引,物理地址做Tag。现代的ARM Cortex-A大多采用PIPT方式,由于采用物理地址作为Index和Tag,所以不会产生cache alias问题。不过PIPT的方式在芯片的设计要比VIPT复杂得多,而且需要等待TLB/MMU将虚拟地址转换为物理地址后,才能进行cache line寻找操作。
CPU发出的虚拟地址经过MMU转换成物理地址,物理地址发往cache控制器查找确认是否命中cache。虽然PIPT方式在软件层面基本不需要维护,但是硬件设计上比VIVT复杂很多。因此硬件成本也更高。同时,由于虚拟地址每次都要翻译成物理地址,因此在查找性能上没有VIVT方式简洁高效,毕竟PIPT方式需要等待虚拟地址转换物理地址完成后才能去查找cache。顺便提一下,为了加快MMU翻译虚拟地址的速度,硬件上也会加入一块cache,作用是缓存虚拟地址和物理地址的映射关系,这块cache称之为TLB(Translation Lookaside Buffer)。当MMU需要转换虚拟地址时,首先从TLB中查找,如果cache hit,则直接返回物理地址。如果cache miss则需要MMU查找页表。这样就加快了虚拟地址转换物理地址的速度。如果系统采用的PIPT的cache,那么软件层面基本不需要任何的维护就可以避免歧义和别名问题。这是PIPT最大的优点。现在的CPU很多都是采用PIPT高速缓存设计。在Linux内核中,可以看到针对PIPT高速缓存的管理函数都是空函数,无需任何的管理。
更多可以访问 Cache组织方式
总结
本文涉及到很多CPU底层实现逻辑,如果看完还是一头雾水可以选择无视。因为需要用到这些知识点的机会本就少之又少。正如 The Go Memory Model 所言:
If you must read the rest of this document to understand the behavior of your program, you are being too clever.
Don't be clever.
参考资料
https://www.zhihu.com/question/24612442
https://zhuanlan.zhihu.com/p/29108170
https://www.infoq.cn/article/cache-coherency-primer
https://zh.wikipedia.org/wiki/%E5%86%85%E5%AD%98%E5%B1%8F%E9%9A%9C
https://blog.csdn.net/hanzefeng/article/details/82893317
https://www.cnblogs.com/linhaostudy/p/9193162.html
https://hacpai.com/article/1459654970712
http://cenalulu.github.io/linux/all-about-cpu-cache/
https://mp.weixin.qq.com/s/viQp36FeMZSqUoFy3VrBNw
https://blog.csdn.net/hx_op/article/details/89244618
https://wweir.cc/post/%E6%8E%A2%E7%B4%A2-golang-%E4%B8%80%E8%87%B4%E6%80%A7%E5%8E%9F%E8%AF%AD