数据结构与算法
“程序(Program)=数据结构(Data Structure)+算法(Algorithm)”
数据结构介绍
数据结构是计算机专业中一门综合性的基础课程,它是介于数学,计算机硬件和计算机软件的三者之间一门核心课程,同时,数据结构是设计数据库,程序,操作系统,游戏等等设计方面的重要基础,是绝大多数计算机专业考研的指定科目,也是大公司面试时常考科目,同时,也是高中及大学的学课竞赛中必备知识,优秀的数据结构和算法,可见数据结构在计算机课程中的重要性。
数据结构发展史
- 起源:
1968年美国唐•欧•克努特教授开创了数据结构的最初体系,他所著的《计算机程序设计技巧》第一卷《基本算法》是第一本较系统地阐述数据的逻辑结构和存储结构语其操作的著作。我们一般认为本书开创了数据结构的系统概念。
70年代初,数据结构作为一门独立的课程开始进入大学课堂。
数据结构的发展经历三个阶段:无结构阶段,结构化阶段和面向对象阶段(和程序发展的三个阶段不谋而合了)
- 无结构阶段
40~60年代见,计算机的主要应用还没有如此普及,当时计算机主要是正对科学计算,程序设计技术以机器语言和汇编语言为主,程序处理的是存粹的数值,数据之间的关系主要是以来数学公式或者数学模型,此时数据结构概念并没有明确形成。
3)结构化阶段
60~80年代,计算机开始广泛应用于非数值处理领域,数据表示成为程序设计的重要问题,人们认识到程序设计规范化的重要性,提出了程序结构模块化,并开始注意数据表示与操作的结构化。数据结构及抽象数据类型就是在这种情况下形成的,随着数据规模的加大,程序的设计越来越依附于数据结构的设计,此时数据结构开始广泛普及。
此间也有非常多的数据结构相关的文献产出,最为著名的是图灵奖获得者沃斯的一个著名公式:程序=数据结构+算法。
4)面向对象阶段
80年代初期到现在,随着计算机不断普及,计算机性能以及需求不断增加,面向对象的程序设计被逐步提出,在对象的世界中 ,程序设计中大大减少了重复设计的部分,数据结构在这个阶段逐渐变得丰富,大量的封装类出现,减少了程序设计者的负担,数据结构因此变得更加友好。
算法介绍
计算机的算法与数据结构密切相关,算法无不依赖于数据结构,而数据结构也关系到算法的效率,直接决定了一个程序的好坏。
算法(Algorithm)是指用来操作数据、解决程序问题的一组方法。对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,比如排序就有前面的十大经典排序和几种奇葩排序,虽然结果相同,但在过程中消耗的资源和时间却会有很大的区别,比如快速排序与猴子排序。
那么我们应该如何去衡量不同算法之间的优劣呢?
主要还是从算法所占用的「时间」和「空间」两个维度去考量。
- 时间维度:是指执行当前算法所消耗的时间,我们通常用「时间复杂度」来描述。
- 空间维度:是指执行当前算法需要占用多少内存空间,我们通常用「空间复杂度」来描述。
何为算法
请你回答一下如何使用计算机C语言编程计算1到100的和(1+2+3+……+100),相信大多数人会直接给出以下答案:
#include
int main() {
int ans=0,i;
for(i=1;i<=100;i++){
ans+=i;
}
printf("%d",ans);
return 0;
}
这几乎是计算机中最为简单的程序了,但是,这样去完成这个功能真的好么?早在300年前的小学生高斯在课堂上被老师要求去计算这个结果,在同班同学还在手推写结果的时候,高斯早就已经做完了,他利用等差数列求和的算法,轻易打败了同班同学。
相关代码如下:
#include
int main() {
int ans=(1+100)*100/2;
printf("%d",ans);
return 0;
}
相比第一份答案,我们进行了100次的运算,才得出我们想要的结果,而对于第二份答案,我们仅进行了1次运算就得到了想要的结果,而在实际中计算机的计算远远不止这点计算量,以此如果我们去计算1到1000000的和呢?使用了等差数列还是一步算好,而这就是算法的魅力。
复杂度概念
1. 时间空间复杂度定义
- 时间复杂度
时间复杂度表示一个程序运行所需要的时间,其具体需要在机器环境中才能得到具体的值,但我们一般并不需要得到详细的值,只是需要比较快慢的区别即可,为此,我们需要引入时间频度(语句频度)的概念。
时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。一般情况下,算法中的基本操作重复次数的是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
2)空间复杂度
一个程序的空间复杂度是指运行完一个程序所需内存的大小,其包括两个部分。
a)固定部分。这部分空间的大小与输入/输出的数据的个数多少、数值无关。主要包括指令空间(即代码空间)、数据空间(常量、简单变量)等所占的空间。这部分属于静态空间。
b)可变空间,这部分空间的主要包括动态分配的空间,以及递归栈所需的空间等。这部分的空间大小与算法有关。
2. 度量时间复杂度的两种方法
1)事后统计法
顾名思义,就是指在程序运行结束之后直接查看运行时间的方式进行时间复杂度的统计,通常采用利用计算机的计时器对不同算法编制的程序进行运行时间的比较,从而确认一个算法的效率。
但这种方法有很多缺陷:
a)特别依赖计算机环境,同一套算法可能在不同的计算机上面有着截然不同的效果,老式的计算机和现代电脑的算力完完全全不是一个级别的处理速度。
b)算法的测试困难,有时一套算法需要海量的数据才能真正比较出效果,而为了设计这样的海量数据以及正确性,则需要花费大量的时间,而对于不同的数据,同一算法又有不一样的效果,故对于数据的使用很难去抉择。
也正是因为有这样的缺陷,
2)事先估计法
与事后统计法不一样,事先统计法采取在计算机编译程序前对该算法进行预估的方式估算。我们可以通过利用时间频度以及函数的思维进行对时间复杂度的解析。
3)函数符号:
〇表示最坏情况,Ω表示最好情况,θ表示平均情况,我们常用的分析使用O进行表示即可。对于一个算法的时间复杂度而言,n表示其执行问题的规模,O(n)表示执行该问题需要的时间量级,如O(n)表示线性级别,O(n2)表示平方级别,其中n主要的判断方式为算法中循环结构的执行次数。
以下为一些常用的基本公式:
a)O(a)=O(1) 其中a为常数
b)O(an)=O(n) 其中a为常数
c)O(an2++bn+c)=O(n2) 其中a,b,c均为常数,结果只与最大项n有关
3.复杂度的度量方法
接上文,在理解了时间复杂度的概念后,就可以根据实际的代码进行度量了,以下举例了几个常用的时间复杂度的表示,对于如何度量其最重要的是观察程序中的循环结构,每一个循环结构代表执行循环中的指令n次,而其余指令一般而言一行代码代表执行一次,对于一个程序而言,执行的次数相差较小其实没有什么区别,都是一瞬间执行完毕。
1. 度量时间复杂度
**a) **O(1) 即 O(C) ,C代表常数
#include
int main(){
printf("Hello World"); //执行一次
return 0; //执行一次
}
对于如上代码,执行了两次,即O(2)=O(1),我们可以称其时间复杂度为O(1),或者常数级时间复杂度
b) O(n)
#include
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i 对于如上代码,我们一共执行了n*1+2次,即O(n*1+2),由上文我们的公式得到其复杂度为O(n),或称之为线性阶时间复杂度。
c) O(n^2)
#include
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i 对于如上代码,我们一共执行了n*n*1+2次,即O(n*n*1+2),由上文我们的公式得到其复杂度为O(n2),或称之为平方阶时间复杂度,此外还有三层循环结构嵌套组成的O(n3)级别的时间复杂度,称之为立方阶时间复杂度,随着嵌套的增多,甚至还有O(n!)级,称之为阶层级时间复杂度,但是这种级别复杂度极高,程序运行极其缓慢。
d) O(logn)
#include
int main(){
int i=1,n=10000; //执行一次
while(i<=n){ //执行logn次
i*=2;
}
return 0; //执行一次
}
与上文的线性增长不同,其 i 的增长是倍增的形式,也就是说 i 会随着运行次数的增加变大的趋势变更大,这样会比那些简单的用加法上涨的变量更快到达循环结构的边界,这样的代码时间复杂度一般为log级别,对于本样例,有O(logn+2)=O(logn),称之为对数阶时间复杂度。
e) O(n*logn)
#include
int main(){
int n=10000,ans=0; //执行一次
for(int i=0;i 对于上文的对数级别的时间复杂度,一样可以实用别的循环进行嵌套,比如本样例O(n*(logn+1)+2)=O(n*logn)级别
除此之外还有很多种时间复杂度的组合,比如说O(2^n)这样的指数阶时间复杂度,有时甚至需要引入多个变量乃进行表示,不过最核心的还是要观察循环结构的处理。
2.各个复杂度的比较
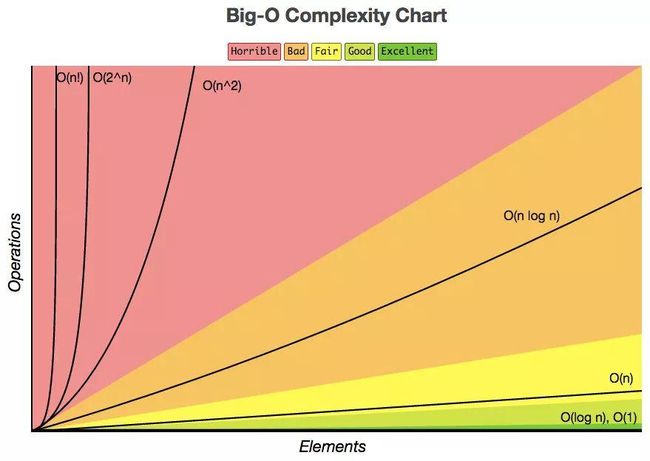
可以见到,平方以及立方级别的复杂度几乎已经是平贴着y轴的一条直线了,而O(n*log(n))与O(n)还保持着一定的速率进行增长,log(n)又是另一个极端,它变成了一个几乎贴着x轴的直线,这样算法的效率就轻易看得出了。
综上可以直观的得出:
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n)
递归算法的时间复杂度(recursive algorithm time complexity),最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均时间复杂度(average case time complexity)和均摊时间复杂度(amortized time complexity)。
递归算法的时间复杂度
如果递归函数中,只进行一次递归调用,递归深度为depth;
在每个递归的函数中,时间复杂度为T;
则总体的时间复杂度为O(T * depth)。
在前面的学习中,归并排序 与 快速排序 都带有递归的思想,并且时间复杂度都是O(nlogn) ,但并不是有递归的函数就一定是 O(nlogn) 级别的。从以下两种情况进行分析。
① 递归中进行一次递归调用的复杂度分析
二分查找法
int binarySearch(int arr[], int l, int r, int target){
if( l > r )
return -1;
int mid = l + (r-l)/2;
if( arr[mid] == target )
return mid;
else if( arr[mid] > target )
return binarySearch(arr, l, mid-1, target); // 左边
else
return binarySearch(arr, mid+1, r, target); // 右边
}
在这个递归函数中,每一次没有找到target时,要么调用 左边 的 binarySearch函数,要么调用 右边 的 binarySearch函数。也就是说在此次递归中,最多调用了一次递归调用而已。根据数学知识,需要logn次才能递归到底。因此,二分查找法的时间复杂度为 O(logn)。
求和

int sum (int n)
{ if (n == 0)
return 0;
return n + sum( n - 1 );
}
在这段代码中比较容易理解递归深度随输入 n 的增加而线性递增,因此时间复杂度为 O (n)。
求幂

//递归深度:logn
//时间复杂度:O(logn)
double pow(double x, int n){
if (n == 0)
return 1.0;
double t = pow(x,n/2);
if (n % 2)
return x*t*t;
return t * t;
}
递归深度为 logn,因为是求需要除以 2 多少次才能到底。
快速幂的思想
快速幂的计算,首先我们可以使用递归的方法来进行求解,下面是求解的式子:
1)如果b是奇数,那么有 a ^ b = a * a ^ (b - 1);
2)如若b是偶数,那么有a ^ b = a ^ (b / 2) * a ^ (b / 2);
从上面的式子我们可以知道对于b是奇数的情况下是能够转化为偶数的,而b是偶数的情况下我们是可以先转换为b / 2的情况,在经过若干次的转换之后那么最后到达了递归的边界就是b变成了0的情况,这个时候我们直接返回1就可以了,a ^ 0 = 1
③ 比如要求解出 2 ^ 10,我们需要经过下面的步骤:
1)由10是偶数因此先要求解 2 ^ 5,然后2 ^ 10 = 2 ^ 5 * 2 ^ 5;
2)对于2 ^ 5来说,5是奇数,所以先要求解出2 ^ 4,2 ^ 5 = 2 * (2 ^ 4)
3)对于2 ^ 4来说,4是偶数,所以先要求解出2 ^ 2,2 ^ 4 = 2 ^ 2 * 2 ^ 2
4)对于2 ^ 2来说,2是偶数,所以先要求解出2 ^ 1,2 ^ 2 = 2 ^ 1 * 2 ^ 1
5)对于2 ^ 0来说,1是奇数,所以先要求解出2 ^ 0,2 ^ 1 = 2 * 2 ^ 0
6)2 ^ 0 = 1递归结束
② 递归中进行多次递归调用的复杂度分析
递归算法中比较难计算的是多次递归调用。
先看下面这段代码,有两次递归调用。
// O(2^n) 指数级别的数量级,后续动态规划的优化点
int f(int n) {
if (n == 0)
return 1;
return f(n-1) + f(n - 1);
}

递归树中节点数就是代码计算的调用次数。
比如 当 n = 3 时,调用次数计算公式为
1 + 2 + 4 + 8 = 15
一般的,调用次数计算公式为
2^0 + 2^1 + 2^2 + …… + 2^n
= 2^(n+1) – 1
= O(2^n)

与之有所类似的是 归并排序 的递归树,区别点在于
-
- 上述例子中树的深度为
n,而 归并排序 的递归树深度为logn。
- 上述例子中树的深度为
-
- 上述例子中每次处理的数据规模是一样的,而在 归并排序 中每个节点处理的数据规模是逐渐缩小的
因此,在如 归并排序 等排序算法中,每一层处理的数据量为 O(n) 级别,同时有 logn 层,时间复杂度便是 O(nlogn)。
参考自
https://zhuanlan.zhihu.com/p/137041568
https://www.dotcpp.com/course/ds/