一、Beautiful Soup4简介
这个第三方库可以帮助我们来处理请求下来的HTML页面中的数据,如果你之前有过前端开发的经验或者是熟悉HTML标记语言和CSS语言的话,那么基本上可以无缝对接地使用这个第三方库来帮助你处理数据,继而完成我们的爬虫。
这里我们会给出Beautiful Soup4的中文文档,学习Pyhton到现在,提供这么详细中文文档的第三方库,还真是不多。如果大家想详细了解学习这个库的话,可以直接访问官网中文文档。
但是如果你想快速掌握这个第三方库,那么就继续看下去吧。这篇文章会给大家介绍Beautiful Soup4常用的方法和属性,能够帮助你快速掌握该库,快速将其应用到你的项目中。
使用这个库之前,需要安装一下,如果你不知道如何安装,推荐大家查看博客:Pycharm配置环境及安装第三方库。
二、Beautiful Soup基本使用
Beautiful Soup4(后面简称bs4)这个库只能从HTML字符串中,来查找和过滤我们需要的数据,不能从本地文件中读取数据进行过滤。不过这对我们基本上没有影响,因为我们做爬虫的时候,大多数情况下,都是从网络上直接爬取HTML页面中的内容,然后进行查找筛选了,而不需存储到本地文件中。
比如我们以腾讯招聘页面中的一些数据为例,首先创建一个字符串,存储我们的原始数据,我们接下来的方法讲解,也是围绕这一字符串进行的。实例代码如下:
from bs4 import BeautifulSoup # 引入我们的bs4库
html_str = """
职位名称
职位类别
人数
地点
发布时间
MIG16-基础架构工程师(北京)
技术类
1
北京
2018-09-29
MIG16-数据系统高级开发工程师
技术类
1
北京
2018-09-29
MIG16-基础架构工程师(北京)
技术类
1
北京
2018-09-29
18796-专项技术测试(深圳)
技术类
2
深圳
2018-09-29
"""
现在有了一个字符串,我们便可以将其作为参数,调用BeautifulSoup(param_1,param_2)来生成一个Beautiful Soup对象。这个时候涉及到一个解析器的知识,也就是上述方法的第二个参数。解析器用来帮助我们解析文本结构,目前主要的解析器有以下几种:
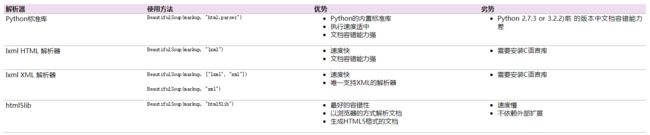
这里推荐大家使用xlml解析器,因为效率高。现在便可以将字符串生成Beautiful Soup对象了。示例代码如下:
bs = BeautifulSoup(html_str,'lxml')
接下来,我们便以这个Beautiful Soup对象为基础,讲解bs4库中常用的方法和属性。
三、Beautiful Soup常用的方法和属性
1.find_all() 方法:
find_all()方法搜索当前tag的所有符合过滤条件的tag子节点。在搜索子节点的时候,我们不仅可以制定要搜索的子节点的标签名,还可以添加过滤条件,更精确的选择我们需要的子节点。实例代码如下:
- 不加过滤条件,获取全部的tr标签
trs = bs.find_all('tr')
- 限制选择标签的数量,获取符合条件的前两个tr标签
trs = bs.find_all('tr',limit=2)
- 选择class为even的tr子节点,注意传入的参数是class_,不是class
trs = bs.find_all('tr',class_="even")
- 选择class=even,且id=feng的tr子节点
trs = bs.find_all('tr', class_="even", id="feng")
# 上述代码等价于
trs = bs.find_all('tr', {"class": "even", "id": "feng"})
2.find() 方法:
find()方法和find_all()方法的参数和用法几乎一样,只不过find()方法只选取符合条件的第一个标签。同时,下面三条数据是等价的。
tr = bs.find("tr")
tr = bs.find_all("tr", limit=1)
tr = bs.find_all("tr")[0]
3.get_text()方法:
如果只想得到tag中包含的文本内容,那么可以使用get_text()方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为Unicode字符串返回。
tr = bs.find_all("tr")[0]
print(tr.get_text())
# 上述代码返回的字符串如下:
# 职位名称
# 职位类别
# 人数
# 地点
# 发布时间
我们还可以传入一个参数作为分隔符,让获取的字符串更好的显示出来,示例代码如下:
tr = bs.find_all("tr")[0]
print(tr.get_text("----"))
# 上述代码返回的字符串如下:
# ----职位名称----
# ----职位类别----
# ----人数----
# ----地点----
# ----发布时间----
我们还可以传入参数strip=True删除返回的字符串左右两边的空格,示例代码如下:
tr = bs.find_all("tr")[0]
print(tr.get_text("----",strip=True))
# 上述代码返回的字符串如下:
# 职位名称----职位类别----人数----地点----发布时间
4.获取节点属性的方法:
如果我们想要获取节点的属性,比如对于,我们想获取它的href属性值,即www.baidu.com。或者对于其他的节点元素,我们想要获取name、class、id等属性值的时候,我们可以采用下面的方法:
trs = bs.find_all("a")
for tr in trs:
print(tr["href"])
5.select()方法:
通过使用bs库中的select()方法,我们可以使用CSS选择器来选择我们需要的标签。也就是说,我们可以通过标签名,标签的class、标签的id,通过标签的name、href等属性来选择我们的元素。使用该方法返回的是一个迭代器,我们可以通过for...in...循环遍历。示例代码如下:
# 选择所有的p标签
p = bs.select("p")
# 选择class为box的标签
box = bs.select(".box")
# 选择id为text的标签
text = bs.select("#text")
# 选择div中的span标签
span = bs.select("div span")
# 选择div中的直接子元素img
img = bs.select("div > img")
# 通过属性来查找标签,比如查找href属性等于index.html的a节点
a = bs.select("a[href='index.html']")
这只是CSS选择器的一部分,其他的CSS也是很类似的。如果有web前端基础,那么你平时如何设置节点元素的样式,在这里你就按照同样的方法选择节点元素即可。
6.string属性:
如果一个节点只包含一个文本节点,或者是只包含一个节点,那么可以使用该属性获取该文本节点的文本内容,或者是这个节点的文本内容。例如:对于 hahaha
divs = bs.select("div")
for div in divs:
print(div.string)
但是如果一个节点下面有很多子孙节点,使用string属性在获取文本的时候,最终返回的是None。这个时候我们应该使用下面的属性。
7.strings属性:
如果一个节点下面有很多子孙节点,我们可以使用strings属性来获取其子孙节点的所有文本。该属性最终返回的是一个迭代器,我们可以通过for...in...循环来遍历。实例代码如下:
tr = bs.select("tr")[0]
for text in tr.strings:
print(text)
# 上述代码的结果可能是这样的,由于换行和空格的存在,可能会有空白文本
#
#
# 职位名称
#
#
# 职位类别
#
#
# 人数
#
#
# 地点
#
#
# 发布时间
8.stripped_strings属性:
在使用上述strings属性获取一个节点中后代文本的时候,可能或出现换行和空格等空白文本,这样在处理的时候会出现麻烦,如果不想获取换行和空格,那么我们可以使用stripped_strings属性。该属性和strings属性一样,返回的也是迭代器,不能直接打印,需要使用for...in...循环来遍历。示例代码如下:
tr = bs.select("tr")[0]
for text in tr.stripped_strings:
print(text)
# 过滤到空白文本,这个时候的文本是这样的
# 职位名称
# 职位类别
# 人数
# 地点
# 发布时间
9.contents属性:
该属性返回的是某个节点下的全部子元素,包括子元素的标签名和文本内容。返回的数据类型是列表,示例代码如下:
feng = bs.find("tr",id="test")
print(type(feng.contents)) # 打印出来的是
for text in feng.contents:
print(text)
10.children属性
该属性和contents属性的用法是一样的,但是返回的数据类型是迭代器,示例代码如下:
feng = bs.find("tr",id="test")
print(type(feng.children)) # 打印出来的是
for text in feng.children:
print(text)
四、Beautiful Soup4中四中常见的对象
1.Tag对象:
Beautiful Soup中所有的标签都是Tag类型,并且通过bs = BeautifulSoup(html_str, 'lxml')方法常见的bs对象在本质上也是Tag类型。我们我们前面说到的find_all()、find()等方法,也都是Tag对象的方法。
2.BeautifulSoup对象
通过bs = BeautifulSoup(html_str, 'lxml')方法常见的bs是BeautifulSoup对象,BeautifulSoup继承自Tag对象。所以我们之前说bs在本质上是Tag类型,而且BeautifulSoup对象的find_all()、find()也是继承自Tag对象的。
3.NavigableString对象
该对象继承自Python中的str对象,用起来和str一样,没什么说的。
4.Comment对象
这个对象继承自NavigableString对象,也没什么说的。
这些知识点知识个人总结,使我们在使用Python做爬虫的时候常用的一些方法和属性。
如果想获取更过的知识,大家可以访问文章开头给出的Beautiful Soup4的官方文档进行学习。