本篇内容,是本人查阅国内外各类作者的文章和视频后,对此作出的总结。如果文章有错漏的地方,欢迎大家指正。
这篇文章的主要内容为,推导出在关系型数据库中,为何选用B+树作为索引实现。
磁盘如何存储数据
对于机械硬盘,磁盘内至少包含一个盘片。盘片上有一圈圈同心圆,相邻两个同心圆围成每个环形被称为磁道(track),也就是图片中粉色部分。同时,从磁盘转轴往外辐射出一条条辐线,辐线与磁道相交的地方,形成一个个弧形段,被称为扇区(Sector),也就是图片中粉色环和蓝色扇形相交的部分。如果机械硬盘包含多个盘片,则不同盘片上同一位置的磁道组成一个柱面(Cylinder),不过这个概念对于这篇文章来说不太重要。
重点是,扇区是磁盘读写的最小单位,这是一个物理单位,通常来说,一个扇区的大小是512B,这取决于机械硬盘的制造商。不过尽管硬盘读写的最小单位是扇区,但对于操作系统来说,读写硬盘的最小单位是块(Block)/簇(Cluster),这是一个逻辑单位,块是Linux的叫法,簇是Windows的叫法。一个块包含多个连续的扇区,这个包含的扇区数是可调的,每个分区的块大小可以是不同的,通常为8个,也就是一个块的大小为4kiB。之所以操作系统要增加块这个概念,原因很明显是为了将硬盘的物理设计和操作系统的逻辑设计解耦,也给予用户更多的选择空间。因为对于机械硬盘来说,随机读取不同磁道上扇区是非常缓慢的,但读取连续的扇区的速度是非常快的。所以,一个块包含越多扇区,每次能读取到的内容就会更多。但是因为块是操作系统中最小的读写单位,所以,一个文件即使什么内容也没有,也将会占用一个块。若系统中有很多小文件,块的大小设计得非常大,就会浪费很多磁盘空间。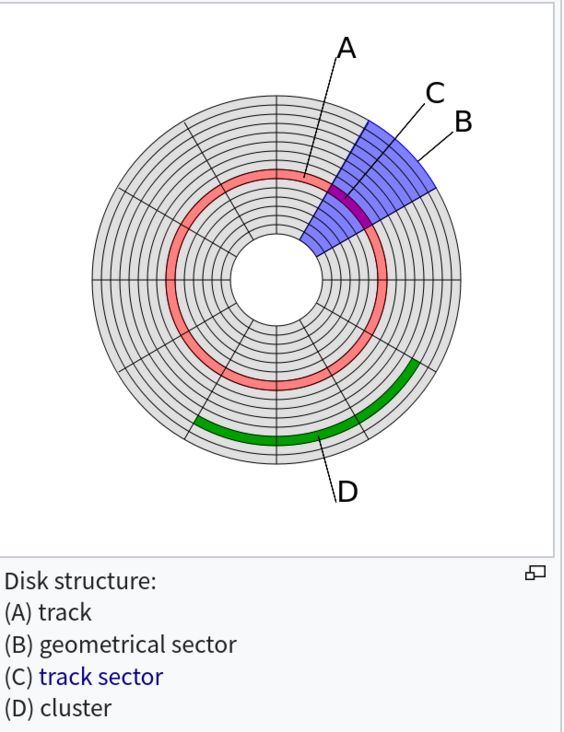
那程序是如何从硬盘读取内容的呢?程序读取数据只能够通过内存读取,而内存也有最小的读写单位,就是页(Page),通常一个页的大小是4kiB。程序要读取文件,操作系统要从硬盘上读取整数块的数据,填入整数页的内存中,供程序使用。之所以要增加页这个概念,原因很明显是为了屏蔽不同分区上块的大小的不同,对程序读取文件造成的影响。
了解上面的前提后,我们知道一个事实,程序通过操作系统从磁盘读取一个字节,至少需要读取一个块(4kiB)。硬盘上的一个字节,可以表示为块号+块内偏移量。
实际上,对于InnoDB存储引擎来说,读写是按照“索引页节点”来的。此“页”并非操作系统中的“页”,而是存储引擎所使用的数据结构,通常设置为16kiB,你可以在MySQL内通过SHOW VARIABLES LIKE 'innodb_page_size%'知道当前的页设置大小。不过这并不影响整篇文章的结论推导。
为何需要使用索引
现在我们假设有这样一张数据表,它包含id,姓名两个字段,数据大小如下。
| 字段名 | 字段大小(B) |
|---|---|
| id | 4 |
| name | 1020 |
嗯,名字字段的大小为1020B,仅仅是为了方便计算。假设我们这张表有100条数据。
| id | name |
|---|---|
| 1 | yizdu |
| 2 | udziy |
| ... | ... |
| 100 | izdyu |
那我们需要存储它使用到多少个硬盘块呢?很明显,(100*(1020+4))/4096=25。也就是25个块。
那当我们从硬盘中读取某个id值对应的姓名,那该怎么办呢?一个块内的扇区在硬盘碟片上是连续的,但一个文件被分成一个个块储存在碟片上时,是随机的,我们没办法通过每条数据的大小,在硬盘上直接跳转。所以,如果我们要找到某个id,就需要从头开始,读取至少1个,至多25个块。
这种情况就像读取一本没有目录的书一样,每次都需要遍历一遍才能找到所需内容,为了避免这种情况,我们可以给像给书加上目录一样,给表加上索引。
我们现在设计一张索引表,包含id和指针,这里我们假设指针大小为6,其实这也是innodb存储引擎的指针大小。
| 字段名 | 字段大小(B) |
|---|---|
| id | 4 |
| pointer | 6 |
然后我们就构建出下面这张表,很明显,这张表的大小为1000B,只需使用一个块就能存储。
| id | pointer |
|---|---|
| 1 | 块号+偏移量 |
| 2 | 块号+偏移量 |
| ... | ... |
| 100 | 块号+偏移量 |
有了这张表后,我们只需要读取一张索引表,然后再通过指针指向的磁盘块号和偏移量即可找到目的数据。只需要读取2个块。
顺便一提,这种索引表存储数据地址的方式也叫非聚簇索引,是MyISAM存储引擎所采用的方案。
如果索引表也很大怎么办
假设我们这个表有1万条数据,那索引表就会占用25个块。那又没有什么办法提高呢?那我们可以为索引再建立一个索引。
索引的索引,可以设计为,某个范围内的id所对应的磁盘块号。
| 字段名 | 字段大小(B) |
|---|---|
| id | 4 |
| pointer | 6 |
比如,在我们索引表中,每条记录占用10B,所以一个块可以存409条索引。我们可以设计这样的索引的索引,id为1-409的跳转到块111,id为410-818的跳到块222,以此类推,我们只需要读取索引的索引,根据id即可跳转到相应范围的索引表上,不需要完整读取整个索引表。
| id | pointer |
|---|---|
| 1 | 块号 |
| 410 | 块号 |
| ... | ... |
| 10000 | 块号 |
如果用图表示的话就是大概这样,画得不好,凑合着看吧。那我们这张索引的索引,会占用多少空间呢?很明显,只需要((10000/409)*10)/4096=0.0596...。所以,我们最后读取表中的数据,只需要读取3个块,效率大大提升了。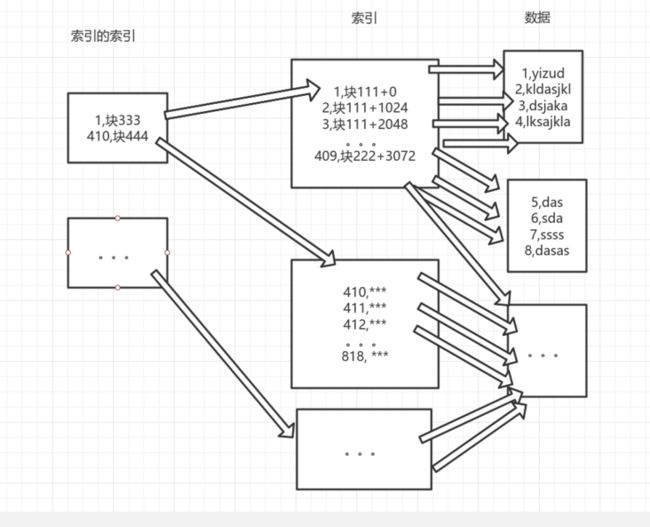
如何让建立索引、索引的索引的这个过程更加自动化
如果索引的索引也很大呢,那很明显是需要设计索引的索引的索引了,但是如何让这个过程更加智能和自动化呢?
其实从上面那幅图,我们大概可以看出些端倪。需要获取某个数据,要从最上层的索引开始比较查找,最后深入到最下层节点,即可获得相应数据。这很明显就是一种树。
那么,该选择什么类型的树比较好呢?常见的用于搜索的树,有二叉搜索树(BST),AVL树,红黑树,B树,B+树。
其实从上面的推论,我们可以看出,优化索引的目的,最终是为了减少磁盘读取的块数。因为磁盘IO对于CPU运算、内存读取来说,都太慢了,是数据库的瓶颈。而对于常见的各种二叉树,他们每个节点只能有两个子节点,如果使用二叉树构建索引树,那将其存储到磁盘后,每个块只能包含一个索引键。这会带来两个问题,1,一个块的空间不止可以存储一个索引键,块内其他的空间被浪费了。2,这棵索引树会比较高,则将会导致较多的硬盘读取次数。(如果你问我为什么一个块不能存储多个节点,那我不知道了)
所以,为了减少磁盘读取次数,要尽可能降低树高,而降低树高就需要用到多路搜索树,常见的多路搜索树有B树和B+树。
B树
这里我们先说一下B树,后面再来谈论B+树。B树是一种多路平衡搜索树。
关于一棵 m 阶级B树,有这样几个定义:
- 每个节点最多能有m棵子树
- 每个非叶非根节点,至少有
celi(m/2)棵子树(celi为向上取整) - 如果根节点不同时是叶节点,那至少有2棵子树
- 有k个子树的节点,拥有k-1个关键字
- 所有叶节点都在同一层
我们可以去这个网站Data Structure Visualizations,观察B树的插入、删除、分裂和合并节点的过程。这里我们并不具体讨论B树的分裂、合并节点算法。
这里我们有一棵3阶B树,它是这样的。我们能明显看出,因为分叉多了,整棵树可以变得更矮。如果每个节点代表一个硬盘块,可以看出,需要读取的磁盘块数最少1块,最多3块。同时所有叶节点都在同一层,这意味着不会有某个查询,需要多于logM(N)的查询时间。这里的M是B树上每个节点的平均叉数,N为数据量,这结论可以从二叉搜索树推导而出。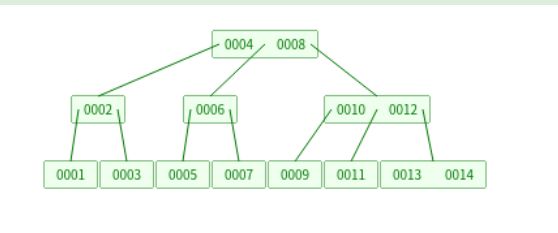
B+树
B+树是B树的升级版。关于B+树的定义,实际上在不同教材、书籍里,细节上会有不同。考虑到B树及其各种变体(B+,B*树)本就是为了在工程上实践使用的,不仅不同教材上的描述不同,不用数据库存储引擎也会有各种变体实现。因此缺少严格的学术定义。
关于一棵 m 阶级B+树,有这样几个定义:
- 每个节点最多能有m棵子树
- 每个非叶非根节点,至少有
celi(m/2)棵子树(celi为向上取整) - 如果根节点不同时是叶节点,那至少有2棵子树
- 所有叶节点都在同一层
目前为止这都和B树的定义一样 - 所有的数据,都储存于叶节点。且按照顺序排列,通过指针相连接
- 所有非叶节点,只是作为索引,并不储存数据
接下来是比较有争议和让人困惑的部分:
对于国外的大部分教材来说,有k棵子树的节点,拥有k-1个关键字。这和B树很相似,很容易理解。
对于InnoDB引擎的索引树实现,和国内的大部分教材来说(比如严蔚敏的《数据结构》)来说,有k棵子树的节点,拥有k个关键字。同时,每个非叶节点包含其子树的最大(或最小)关键字。这种B+树是长这样子的。这种设计的B+树,本人其实不太理解它的构建过程细节。考研里也仅要求了解其基本概念和性质,缺少相关教材描述。不过这些差异并不是大问题,不影响接下来的结论推导。为了方便讲解和画图,下面我仍然使用国外教材定义的B+树。
这里我们有一棵3阶B树,它是这样的。可以看出,因为所有数据都在叶节点,因此访问任何一个数据都需要访问logM(N)次(M仍是平均分叉数、N是数据量)。同时,因为非叶节点都只是索引,所有的数据都在叶节点上,因此有一定的数据冗余,造成某些情况下,同样的数据量和阶数,B+树会比B树高。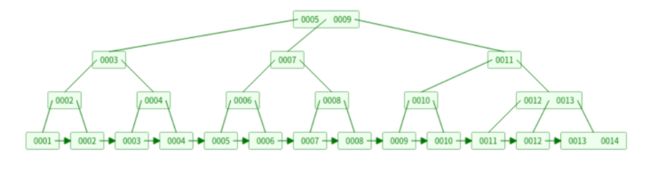
为什么选择B+树
似乎B+树看上去比B树性能要差,那为何它是数据库索引的常见实现?
我们关注B树和B+树最大的不同点,即
- 所有的数据,都储存于叶节点。且按照顺序排列,通过指针相连接
- 所有非叶节点,只是作为索引,并不储存数据
对于5。因为所有的数据都被顺序地排列于叶节点层上,如果对B+树索引进行范围查询和全表扫描,将会是很容易的事情。而对于B树,需要进行中序遍历,这将可能造成更多的随机IO,以及更复杂的算法实现。
对于6。这个是最关键的一点。因为B+树中非叶节点只是作为索引,不包含数据。所以对于每个磁盘来说,使用B+树,每个块可以存入更多的关键字,这将使得索引树变得更矮。
假设B树和B+树都使用4字节的主键和6字节的指针,为了方便计算,关键字数和子树数相同。那在一个4kiB的磁盘块里。B+树能存4096/(4+6)=409条索引,B树因为每个节点包含数据,因此至少需要一个指向数据的指针,所以一个块只能存4096/(4+6+6)=256条索引。能看出,使用B+树,索引树可以变得更加矮,效率大概比B树高了一倍。因此,即使理论上B+树在同阶情况下,树可能比B树高,但实际储存到磁盘上,B+树能获得更大的阶数。
此外,B+树的查询复杂度是稳定logM(N),不同于B树的最少1,最大logM(N),可能有读者对此会有疑问,为什么需要有稳定性。其实本人也有这样的疑问,个人参考各个博主的观点和自己的思考后。个人认为最大的收益在于数据库管理系统的查询优化。大部分数据管理系统,比如MySQL,会对查询进行隐式的优化,决定是否走索引,走哪个索引。进行一条查询语句,可能有多种查询方式,MySQL会在多种方式中,比较各种成本花销,最后选择一种它认为最佳的方案。而B+树的稳定查询复杂度,使得计算成本变得可预期。
额外的知识点
InnoDB 中,主键索引树通常有多高?
在InnoDB中,储存节点的单位并不是磁盘块,而是InnoDB所设计的“页”。同时,InnoDB使用的是聚簇索引,即叶子节点包含数据表中整行的数据。文章开头讲过,这个页大小通常是16kiB。而对于常见的INT型id主键,需4个字节。InnoDB中指针需要6个字节。
因此,对于以INT作为主键的情况下,假设每条数据大小为1kiB。InnoDB每个页能存1638条索引,16条数据。所以,树高为1时,能存16条数据,这个情况下,只有一个页充当根或叶节点。树高为2时(只有根和叶节点),能存1638*16条数据。树高为3时,能存1638*1638*16条数据,树高为4时,能存1638*1638*1638*16条数据。当然这个是每个节点都达到最大阶数的情况下的理论值,实际情况会小一点,不过无关紧要,因为能看出树高为3时,就已经能存储4千万条数据了。
InnoDB 每次搜索索引,需要多少次磁盘 IO
树高多少,就需要读取多少次节点。大部分博客都会说硬盘IO次数等同于树高,但这只会在树节点大小等同于磁盘块数的情况下成立。InnoDB中,数据页大小为16kiB,根页常驻内存。操作系统中常见的块大小为4kiB。因此理论上,真正的磁盘IO数量应该为树高*(数据页大小/块大小)-1,-1是因为根页常驻内存。
参考
- [1] Data Structure Visualizations
- [2] 10.2 B Trees and B+ Trees. How they are useful in Databases
- [3] B+树查询的稳定性为什么重要?
- [4] B+Tree index structures in InnoDB
- [5] B+Trees – How SQL Server Indexes are Stored on Disk
- [6] How Database B-Tree Indexing Works
- [7]修改Innodb的数据页大小以优化MySQL的方法
- [8]MySQL innodb_page_size