多线程并发知识库

JAVA线程实现/创建的四种方式
1.继承Thread类
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过Thread类的start()实例方法。start()方法是一个native方法,它将启动一个新线程,并执行run()方法。
public class MyThread extends Thread {
public void run() {System.out.println("MyThread.run()");
}
}
MyThread myThread1 = new MyThread();
myThread1.start();
2.实现Runnable接口
如果自己的类已经extends另一个类,就无法直接extends Thread,此时,可以实现一个Runnable接口。
public class MyThread extends OtherClass implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
//启动MyThread,需要首先实例化一个Thread,并传入自己的MyThread实例:
MyThread myThread = new MyThread();
Thread thread = new Thread(myThread);
thread.start();
//事实上,当传入一个Runnable target参数给Thread后,Thread的run()方法就会调用target.run() public void run() {
if (target != null) { target.run();
}
}
3.ExecutorService、Callable
//创建一个线程池
ExecutorService pool = Executors.newFixedThreadPool(taskSize);
// 创建多个有返回值的任务
Listlist = new ArrayList ();
for (int i = 0; i < taskSize; i++) {
Callable c = new MyCallable(i + " ");
// 执行任务并获取Future对象
Future f = pool.submit(c);
list.add(f);
}
// 关闭线程池
pool.shutdown();
// 获取所有并发任务的运行结果
for (Future f : list) {
// 从Future对象上获取任务的返回值,并输出到控制台
System.out.println("res:" + f.get().toString());
}
4.基于线程池的方式
线程和数据库连接这些资源都是非常宝贵的资源。那么每次需要的时候创建,不需要的时候销毁,是非常浪费资源的。那么我们就可以使用缓存的策略,也就是使用线程池。
// 创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
while(true) {
threadPool.execute(new Runnable() { // 提交多个线程任务,并执行
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running ..");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
4种线程池
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。
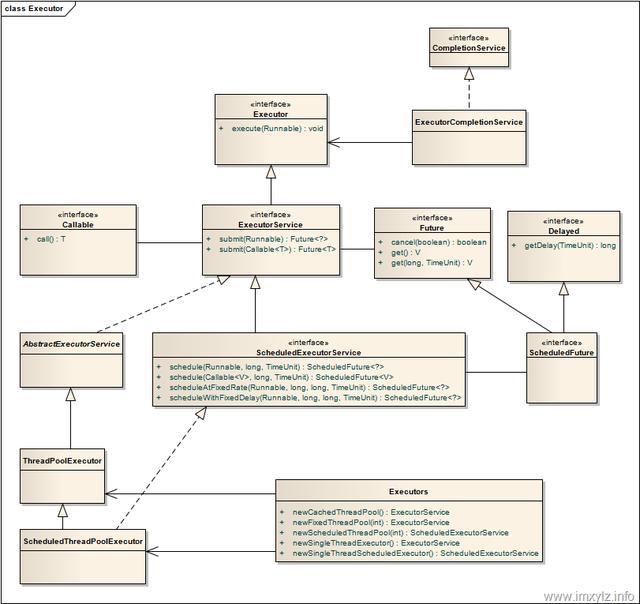
1.newCachedThreadPool
创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们。对于执行很多短期异步任务的程序而言,这些线程池通常可提高程序性能。调用 execute 将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。因此,长时间保持空闲的线程池不会使用任何资源。
2.newFixedThreadPool
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大多数 nThreads 线程会处于处理任务的活动状态。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新线程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之前,池中的线程将一直存在。
3.newScheduledThreadPool
newScheduledThreadPool 创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
ScheduledExecutorService scheduledThreadPool= Executors.newScheduledThreadPool(3); scheduledThreadPool.schedule(newRunnable(){
@Override public void run() {
System.out.println("延迟三秒"); }
}, 3, TimeUnit.SECONDS); scheduledThreadPool.scheduleAtFixedRate(newRunnable(){
@Override public void run() {
System.out.println("延迟1秒后每三秒执行一次");
} },1,3,TimeUnit.SECONDS);
4.newSingleThreadExecutor
Executors.newSingleThreadExecutor()返回一个线程池(这个线程池只有一个线程),这个线程池可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!
线程生命周期(状态)
当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。在线程的生命周期中,它要经过新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和死亡(Dead)5种状态。尤其是当线程启动以后,它不可能一直"霸占"着CPU独自运行,所以CPU需要在多条线程之间切换,于是线程状态也会多次在运行、阻塞之间切换
1. 新建状态(NEW)
当程序使用new关键字创建了一个线程之后,该线程就处于新建状态,此时仅由JVM为其分配内存,并初始化其成员变量的值
2.就绪状态(RUNNABLE)
当线程对象调用了start()方法之后,该线程处于就绪状态。Java虚拟机会为其创建方法调用栈和程序计数器,等待调度运行。
3.运行状态(RUNNING)
如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程执行体,则该线程处于运行状态。
4.阻塞状态(BLOCKED)
阻塞状态是指线程因为某种原因放弃了cpu 使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cpu timeslice 转到运行(running)状态。阻塞的情况分三种:
等待阻塞(o.wait->等待对列):
运行(running)的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)中。同步阻塞(lock->锁池)
运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
其他阻塞(sleep/join)
运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
5.线程死亡(DEAD)
线程会以下面三种方式结束,结束后就是死亡状态。
正常结束1. run()或call()方法执行完成,线程正常结束。
异常结束2. 线程抛出一个未捕获的Exception或Error。
调用stop 3. 直接调用该线程的stop()方法来结束该线程—该方法通常容易导致死锁,不推荐使用。

终止线程4种方式
1.正常运行结束
程序运行结束,线程自动结束。
2.使用退出标志退出线程
一般run()方法执行完,线程就会正常结束,然而,常常有些线程是伺服线程。它们需要长时间的运行,只有在外部某些条件满足的情况下,才能关闭这些线程。使用一个变量来控制循环,例如:最直接的方法就是设一个boolean类型的标志,并通过设置这个标志为true或false来控制while循环是否退出,代码示例:
public class ThreadSafe extends Thread {
public volatile boolean exit = false;
public void run() {
while (!exit){
//do something
}
}
}
定义了一个退出标志exit,当exit为true时,while循环退出,exit的默认值为false.在定义exit时,使用了一个Java关键字volatile,这个关键字的目的是使exit同步,也就是说在同一时刻只能由一个线程来修改exit的值。
3.Interrupt方法结束线程
使用interrupt()方法来中断线程有两种情况:
1. 线程处于阻塞状态:如使用了sleep,同步锁的wait,socket中的receiver,accept等方法时,会使线程处于阻塞状态。当调用线程的interrupt()方法时,会抛出InterruptException异常。阻塞中的那个方法抛出这个异常,通过代码捕获该异常,然后break跳出循环状态,从而让我们有机会结束这个线程的执行。通常很多人认为只要调用interrupt方法线程就会结束,实际上是错的, 一定要先捕获InterruptedException异常之后通过break来跳出循环,才能正常结束run方法。
2. 线程未处于阻塞状态:使用isInterrupted()判断线程的中断标志来退出循环。当使用interrupt()方法时,中断标志就会置true,和使用自定义的标志来控制循环是一样的道理。
public class ThreadSafe extends Thread {
public void run() {
while (!isInterrupted()){ //非阻塞过程中通过判断中断标志来退出
try{
Thread.sleep(5*1000);//阻塞过程捕获中断异常来退出
}catch(InterruptedException e){
e.printStackTrace();
break;//捕获到异常之后,执行break跳出循环
}
}
}
}
4.stop方法终止线程(线程不安全)
程序中可以直接使用thread.stop()来强行终止线程,但是stop方法是很危险的,就象突然关闭计算机电源,而不是按正常程序关机一样,可能会产生不可预料的结果,不安全主要是:thread.stop()调用之后,创建子线程的线程就会抛出ThreadDeatherror的错误,并且会释放子线程所持有的所有锁。一般任何进行加锁的代码块,都是为了保护数据的一致性,如果在调用thread.stop()后导致了该线程所持有的所有锁的突然释放(不可控制),那么被保护数据就有可能呈现不一致性,其他线程在使用这些被破坏的数据时,有可能导致一些很奇怪的应用程序错误。因此,并不推荐使用stop方法来终止线程。
sleep与wait 区别
1. 对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
2. sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持着,当指定的时间到了又会自动恢复运行状态。
3. 在调用sleep()方法的过程中,线程不会释放对象锁。
4. 而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
start与run区别
1. start()方法来启动线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码。
2. 通过调用Thread类的start()方法来启动一个线程, 这时此线程是处于就绪状态, 并没有运行。
3. 方法run()称为线程体,它包含了要执行的这个线程的内容,线程就进入了运行状态,开始运行run函数当中的代码。 Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
JAVA后台线程
1. 定义:守护线程--也称“服务线程”,它是后台线程,它有一个特性,即为用户线程 提供 公共服务,在没有用户线程可服务时会自动离开。
2. 优先级:守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。
3. 设置:通过setDaemon(true)来设置线程为“守护线程”;将一个用户线程设置为守护线程的方式是在 线程对象创建 之前 用线程对象的setDaemon方法。
4. 在Daemon线程中产生的新线程也是Daemon的。
5. 线程则是JVM级别的,以Tomcat 为例,如果你在Web 应用中启动一个线程,这个线程的生命周期并不会和Web应用程序保持同步。也就是说,即使你停止了Web应用,这个线程依旧是活跃的。
6. example: 垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的Thread,程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
7. 生命周期:守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。也就是说守护线程不依赖于终端,但是依赖于系统,与系统“同生共死”。当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;如果还有一个或以上的非守护线程则JVM不会退出。
JAVA锁
乐观锁

乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,采取在写时先读出当前版本号,然后加锁操作(比较跟上一次的版本号,如果一样则更新),如果失败则要重复读-比较-写的操作。 java中的乐观锁基本都是通过CAS操作实现的,CAS是一种更新的原子操作,比较当前值跟传入值是否一样,一样则更新,否则失败。
悲观锁

悲观锁是就是悲观思想,即认为写多,遇到并发写的可能性高,每次去拿数据的时候都认为别人会修改,所以每次在读写数据的时候都会上锁,这样别人想读写这个数据就会block直到拿到锁。java中的悲观锁就是Synchronized,AQS框架下的锁则是先尝试cas乐观锁去获取锁,获取不到,才会转换为悲观锁,如RetreenLock。
自旋锁

自旋锁原理非常简单,如果持有锁的线程能在很短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞挂起状态,它们只需要等一等(自旋),等持有锁的线程释放锁后即可立即获取锁,这样就避免用户线程和内核的切换的消耗。 线程自旋是需要消耗cup的,说白了就是让cup在做无用功,如果一直获取不到锁,那线程也不能一直占用cup自旋做无用功,所以需要设定一个自旋等待的最大时间。 如果持有锁的线程执行的时间超过自旋等待的最大时间仍没有释放锁,就会导致其它争用锁的线程在最大等待时间内还是获取不到锁,这时争用线程会停止自旋进入阻塞状态。
自旋锁的优缺点自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换! 但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用cpu做无用功,占着XX不XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要cup的线程又不能获取到cpu,造成cpu的浪费。所以这种情况下我们要关闭自旋锁; 自旋锁时间阈值(1.6引入了适应性自旋锁) 自旋锁的目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。但是如何去选择自旋的执行时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用CPU资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要! 121623125152125125
JVM对于自旋周期的选择,jdk1.5这个限度是一定的写死的,在1.6引入了适应性自旋锁,适应性自旋锁意味着自旋的时间不在是固定的了,而是由前一次在同一个锁上的自旋时间以及锁的拥有者的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间,同时JVM还针对当前CPU的负荷情况做了较多的优化,如果平均负载小于CPUs则一直自旋,如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞,如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞,如果CPU处于节电模式则停止自旋,自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差),自旋时会适当放弃线程优先级之间的差异。
自旋锁的开启
JDK1.6中-XX:+UseSpinning开启;
-XX:PreBlockSpin=10 为自旋次数;
JDK1.7后,去掉此参数,由jvm控制;
Synchronized同步锁
synchronized它可以把任意一个非NULL的对象当作锁。他属于独占式的悲观锁,同时属于可重入锁。
Synchronized作用范围
1. 作用于方法时,锁住的是对象的实例(this);
2. 当作用于静态方法时,锁住的是Class实例,又因为Class的相关数据存储在永久带PermGen(jdk1.8则是metaspace),永久带是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程;
3. synchronized作用于一个对象实例时,锁住的是所有以该对象为锁的代码块。它有多个队列,当多个线程一起访问某个对象监视器的时候,对象监视器会将这些线程存储在不同的容器中。
Synchronized核心组件
- Wait Set:那些调用wait方法被阻塞的线程被放置在这里;
- Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中;
- Entry List:Contention List中那些有资格成为候选资源的线程被移动到Entry List中;
- OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被称为OnDeck;
- Owner:当前已经获取到所资源的线程被称为Owner; 6) !Owner:当前释放锁的线程。
Synchronized实现
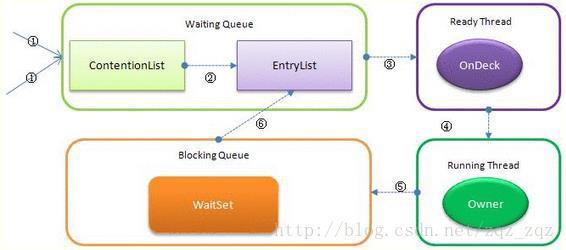
1. JVM每次从队列的尾部取出一个数据用于锁竞争候选者(OnDeck),但是并发情况下,ContentionList会被大量的并发线程进行CAS访问,为了降低对尾部元素的竞争,JVM会将一部分线程移动到EntryList中作为候选竞争线程。
2. Owner线程会在unlock时,将ContentionList中的部分线程迁移到EntryList中,并指定EntryList中的某个线程为OnDeck线程(一般是最先进入的那个线程)。
3. Owner线程并不直接把锁传递给OnDeck线程,而是把锁竞争的权利交给OnDeck,OnDeck需要重新竞争锁。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在JVM中,也把这种选择行为称之为“竞争切换”。
4. OnDeck线程获取到锁资源后会变为Owner线程,而没有得到锁资源的仍然停留在EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者notifyAll唤醒,会重新进入EntryList中。
5. 处于ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux内核下采用pthread_mutex_lock内核函数实现的)。
6. Synchronized是非公平锁。 Synchronized在线程进入ContentionList时,等待的线程会先尝试自旋获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源。
7. 每个对象都有个monitor对象,假说就是在竞争monitor对象,代码块加锁是在前后分别加上monitorenter和monitorexit指令来实现的,方法加锁是通过一个标记位来判断的
8. synchronized是一个重量级操作,需要调用操作系统相关接口,性能是低效的,有可能给线程加锁消耗的时间比有用操作消耗的时间更多。
9. Java1.6,synchronized进行了很多的优化,有适应自旋、锁消除、锁粗化、轻量级锁及偏向锁等,效率有了本质上的提高。在之后推出的Java1.7与1.8中,均对该关键字的实现机理做了优化。引入了偏向锁和轻量级锁。都是在对象头中有标记位,不需要经过操作系统加锁。
10. 锁可以从偏向锁升级到轻量级锁,再升级到重量级锁。这种升级过程叫做锁膨胀;
11. JDK 1.6中默认是开启偏向锁和轻量级锁,可以通过-XX:-UseBiasedLocking来禁用偏向锁。
ReentrantLock
ReentantLock继承接口Lock并实现了接口中定义的方法,它是一种可重入锁,除了能完成synchronized所能完成的所有工作外,还提供了诸如可响应中断锁、可轮询锁请求、定时锁等避免多线程死锁的方法。
Lock接口的主要方法
1. void lock(): 执行此方法时, 如果锁处于空闲状态, 当前线程将获取到锁. 相反, 如果锁已经被其他线程持有, 将禁用当前线程, 直到当前线程获取到锁.
2. boolean tryLock():如果锁可用, 则获取锁, 并立即返回true, 否则返回false. 该方法和lock()的区别在于, tryLock()只是"试图"获取锁, 如果锁不可用, 不会导致当前线程被禁用, 当前线程仍然继续往下执行代码. 而lock()方法则是一定要获取到锁, 如果锁不可用, 就一直等待, 在未获得锁之前,当前线程并不继续向下执行.
3. void unlock():执行此方法时, 当前线程将释放持有的锁. 锁只能由持有者释放, 如果线程并不持有锁, 却执行该方法, 可能导致异常的发生.
4. Condition newCondition():条件对象,获取等待通知组件。该组件和当前的锁绑定,当前线程只有获取了锁,才能调用该组件的await()方法,而调用后,当前线程将缩放锁。
5. getHoldCount() :查询当前线程保持此锁的次数,也就是执行此线程执行lock方法的次数。
6. getQueueLength():返回正等待获取此锁的线程估计数,比如启动10个线程,1个线程获得锁,此时返回的是9
7. getWaitQueueLength:(Condition condition)返回等待与此锁相关的给定条件的线程估计数。比如10个线程,用同一个condition对象,并且此时这10个线程都执行了condition对象的await方法,那么此时执行此方法返回10
8. hasWaiters(Condition condition):查询是否有线程等待与此锁有关的给定条件(condition),对于指定contidion对象,有多少线程执行了condition.await方法
9. hasQueuedThread(Thread thread):查询给定线程是否等待获取此锁
10. hasQueuedThreads():是否有线程等待此锁
11. isFair():该锁是否公平锁
12. isHeldByCurrentThread(): 当前线程是否保持锁锁定,线程的执行lock方法的前后分别是false和true
13. isLock():此锁是否有任意线程占用
14. lockInterruptibly():如果当前线程未被中断,获取锁
15. tryLock():尝试获得锁,仅在调用时锁未被线程占用,获得锁
16. tryLock(long timeout TimeUnit unit):如果锁在给定等待时间内没有被另一个线程保持,则获取该锁。
线程基本方法
线程相关的基本方法有wait,notify,notifyAll,sleep,join,yield等。

1.线程等待(wait)
调用该方法的线程进入WAITING状态,只有等待另外线程的通知或被中断才会返回,需要注意的是调用wait()方法后,会释放对象的锁。因此,wait方法一般用在同步方法或同步代码块中。
2. 线程睡眠(sleep)
sleep导致当前线程休眠,与wait方法不同的是sleep不会释放当前占有的锁,sleep(long)会导致线程进入TIMED-WATING状态,而wait()方法会导致当前线程进入WATING状态
3. 线程让步(yield)
yield会使当前线程让出CPU执行时间片,与其他线程一起重新竞争CPU时间片。一般情况下,优先级高的线程有更大的可能性成功竞争得到CPU时间片,但这又不是绝对的,有的操作系统对线程优先级并不敏感。
4.线程中断(interrupt)
内部的一个中断标识位。这个线程本身并不会因此而改变状态(如阻塞,终止等)。
1. 调用interrupt()方法并不会中断一个正在运行的线程。也就是说处于Running状态的线程并不会因为被中断而被终止,仅仅改变了内部维护的中断标识位而已。
2. 若调用sleep()而使线程处于TIMED-WATING状态,这时调用interrupt()方法,会抛出InterruptedException,从而使线程提前结束TIMED-WATING状态。
3. 许多声明抛出InterruptedException的方法(如Thread.sleep(long mills方法)),抛出异常前,都会清除中断标识位,所以抛出异常后,调用isInterrupted()方法将会返回false。
4. 中断状态是线程固有的一个标识位,可以通过此标识位安全的终止线程。比如,你想终止一个线程thread的时候,可以调用thread.interrupt()方法,在线程的run方法内部可以根据thread.isInterrupted()的值来优雅的终止线程。
5. Join等待其他线程终止
join() 方法,等待其他线程终止,在当前线程中调用一个线程的 join() 方法,则当前线程转为阻塞状态,回到另一个线程结束,当前线程再由阻塞状态变为就绪状态,等待 cpu 的宠幸。
6. 为什么要用join()方法?
很多情况下,主线程生成并启动了子线程,需要用到子线程返回的结果,也就是需要主线程需要在子线程结束后再结束,这时候就要用到 join() 方法。
System.out.println(Thread.currentThread().getName() + "线程运行开始!");
Thread6 thread1 = new Thread6();
thread1.setName("线程B");
thread1.join();
System.out.println("这时thread1执行完毕之后才能执行主线程");
7. 线程唤醒(notify)
Object 类中的 notify() 方法,唤醒在此对象监视器上等待的单个线程,如果所有线程都在此对象上等待,则会选择唤醒其中一个线程,选择是任意的,并在对实现做出决定时发生,线程通过调用其中一个 wait() 方法,在对象的监视器上等待,直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程,被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争。类似的方法还有 notifyAll() ,唤醒再次监视器上等待的所有线程。
8. 其他方法:
1. sleep():强迫一个线程睡眠N毫秒。
2. isAlive(): 判断一个线程是否存活。
3. join(): 等待线程终止。
4. activeCount(): 程序中活跃的线程数。
5. enumerate(): 枚举程序中的线程。
6. currentThread(): 得到当前线程。
7. isDaemon(): 一个线程是否为守护线程。
8. setDaemon(): 设置一个线程为守护线程。(用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束)
9. setName(): 为线程设置一个名称。
10. wait(): 强迫一个线程等待。
11. notify(): 通知一个线程继续运行。
12. setPriority(): 设置一个线程的优先级。
13. getPriority()::获得一个线程的优先级。
线程上下文切换
巧妙地利用了时间的轮转的方式, CPU给每个任务都服务一定的时间,然后把当前任务的状态保存下来,在加载下一任务的状态后,继续服务下一任务,任务的状态保存及再加载, 这段过程就叫做上下文切换。时间的轮转的方式使多个任务在同一颗CPU上执行变成了可能。
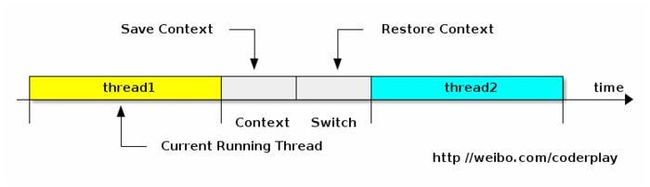
1. 进程
(有时候也称做任务)是指一个程序运行的实例。在Linux系统中,线程就是能并行运行并且与他们的父进程(创建他们的进程)共享同一地址空间(一段内存区域)和其他资源的轻量级的进程。
2. 上下文
是指某一时间点 CPU 寄存器和程序计数器的内容。
3. 寄存器
是 CPU 内部的数量较少但是速度很快的内存(与之对应的是 CPU 外部相对较慢的 RAM 主内存)。寄存器通过对常用值(通常是运算的中间值)的快速访问来提高计算机程序运行的速度。
4. 程序计数器
是一个专用的寄存器,用于表明指令序列中 CPU 正在执行的位置,存的值为正在执行的指令的位置或者下一个将要被执行的指令的位置,具体依赖于特定的系统。
5. PCB-“切换桢”
上下文切换可以认为是内核(操作系统的核心)在 CPU 上对于进程(包括线程)进行切换,上下文切换过程中的信息是保存在进程控制块(PCB, process control block)中的。PCB还经常被称作“切换桢”(switchframe)。信息会一直保存到CPU的内存中,直到它们被再次使用。 121623125152125125
6. 上下文切换的活动:
1. 挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处。
2. 在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复。
3. 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程在程序中。
7. 引起线程上下文切换的原因
1. 当前执行任务的时间片用完之后,系统CPU正常调度下一个任务;
2. 当前执行任务碰到IO阻塞,调度器将此任务挂起,继续下一任务;
3. 多个任务抢占锁资源,当前任务没有抢到锁资源,被调度器挂起,继续下一任务;
4. 用户代码挂起当前任务,让出CPU时间;
5. 硬件中断;
同步锁与死锁
1. 同步锁
当多个线程同时访问同一个数据时,很容易出现问题。为了避免这种情况出现,我们要保证线程同步互斥,就是指并发执行的多个线程,在同一时间内只允许一个线程访问共享数据。 Java中可以使用synchronized关键字来取得一个对象的同步锁。
2. 死锁
何为死锁,就是多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。
3. 线程池原理
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。他的主要特点为:线程复用;控制最大并发数;管理线程。
1. 线程复用 每一个 Thread 的类都有一个 start 方法。 当调用start启动线程时Java虚拟机会调用该类的 run 方法。 那么该类的 run() 方法中就是调用了 Runnable 对象的 run() 方法。 我们可以继承重写 Thread 类,在其 start 方法中添加不断循环调用传递过来的 Runnable 对象。 这就是线程池的实现原理。循环方法中不断获取 Runnable 是用 Queue 实现的,在获取下一个 Runnable 之前可以是阻塞的。
.2. 线程池的组成
一般的线程池主要分为以下4个组成部分:
1. 线程池管理器:用于创建并管理线程池
2. 工作线程:线程池中的线程
3. 任务接口:每个任务必须实现的接口,用于工作线程调度其运行
4. 任务队列:用于存放待处理的任务,提供一种缓冲机制 Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor ,Callable和Future、FutureTask这几个类。

ThreadPoolExecutor的构造方法如下:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue
workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); }
1. corePoolSize:指定了线程池中的线程数量。
2. maximumPoolSize:指定了线程池中的最大线程数量。
3. keepAliveTime:当前线程池数量超过corePoolSize时,多余的空闲线程的存活时间,即多次时间内会被销毁。
4. unit:keepAliveTime的单位。
5. workQueue:任务队列,被提交但尚未被执行的任务。
6. threadFactory:线程工厂,用于创建线程,一般用默认的即可。
7. handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
3. 拒绝策略
线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列也已经排满了,再也塞不下新任务了。这时候我们就需要拒绝策略机制合理的处理这个问题。 JDK内置的拒绝策略如下:
1. AbortPolicy : 直接抛出异常,阻止系统正常运行。
2. CallerRunsPolicy : 只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
3. DiscardOldestPolicy : 丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
4. DiscardPolicy : 该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢失,这是最好的一种方案。 以上内置拒绝策略均实现了RejectedExecutionHandler接口,若以上策略仍无法满足实际需要,完全可以自己扩展RejectedExecutionHandler接口。
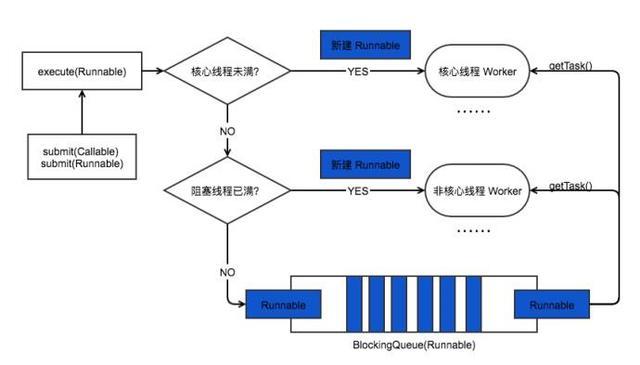
4. Java线程池工作过程
1. 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
2. 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a) 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b) 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
c) 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务; d) 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常RejectExecutionException。
3. 当一个线程完成任务时,它会从队列中取下一个任务来执行。
4. 当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。