在介绍kong插件之前 先了解下nginx的11个阶段和openresty的8个执行阶段
一. Nginx 处理请求的过程一共划分为 11 个阶段,按照执行顺序依次是 post-read、server-rewrite、find-config、rewrite、post-rewrite、preaccess、access、post-access、try-files、content 以及 log。
1、post-read
最先执行的 post-read 阶段在 Nginx 读取并解析完请求头(request headers)之后就立即开始运行。例如:使用了ngx_realip模块提供的set_real_ip_from和real_ip_header这两条配置指令
2、server-rewrite
由于 server-rewrite 阶段位于 post-read 阶段之后,所以 server 配置块中的set指令也就总是运行在ngx_realip模块改写请求的来源地址之后。
3、find-config
这个阶段并不支持 Nginx 模块注册处理程序,而是由 Nginx 核心来完成当前请求与 location 配置块之间的配对工作。换句话说,在此阶段之前,请求并没有与任何 location 配置块相关联。因此,对于运行在 find-config 阶段之前的 post-read 和 server-rewrite 阶段来说,只有 server 配置块以及更外层作用域中的配置指令才会起作用。这就是为什么只有写在 server 配置块中的ngx_rewrite模块的指令才会运行在 server-rewrite 阶段,这也是为什么前面所有例子中的ngx_realip模块的指令也都特意写在了 server 配置块中,以确保其注册在 post-read 阶段的处理程序能够生效。
4、rewrite
由于 Nginx 已经在 find-config 阶段完成了当前请求与 location 的配对,所以从 rewrite 阶段开始,location 配置块中的指令便可以产生作用。当ngx_rewrite模块的指令用于 location 块中时,便是运行在这个 rewrite 阶段。
5、post-rewrite
这个阶段也像 find-config 阶段那样不接受 Nginx 模块注册处理程序,而是由 Nginx 核心完成 rewrite 阶段所要求的“内部跳转”操作(如果 rewrite 阶段有此要求的话)。例如:通过rewrite指令把当前请求的 URI 无条件地改写为 /bar,同时发起一个“内部跳转”,最终跳进了 location /bar 中。这里比较有趣的地方是“内部跳转”的工作原理。“内部跳转”本质上其实就是把当前的请求处理阶段强行倒退到 find-config 阶段,以便重新进行请求 URI 与 location 配置块的配对。
6、preaccess
该阶段在 access 阶段之前执行,故名 preaccess.标准模块ngx_limit_req和ngx_limit_zone就运行在此阶段,前者可以控制请求的访问频度,而后者可以限制访问的并发度。
7、access
标准模块ngx_access、第三方模块ngx_auth_request以及第三方模块ngx_lua的access_by_lua指令就运行在这个阶段。
8、 post-access
这个阶段也和 post-rewrite 阶段类似,并不支持 Nginx 模块注册处理程序,而是由 Nginx 核心自己完成一些处理工作。post-access 阶段主要用于配合 access 阶段实现标准ngx_http_core模块提供的配置指令satisfy的功能。对于多个 Nginx 模块注册在 access 阶段的处理程序,satisfy配置指令可以用于控制它们彼此之间的协作方式。比如模块 A 和 B 都在 access 阶段注册了与访问控制相关的处理程序,那就有两种协作方式,一是模块 A 和模块 B 都得通过验证才算通过,二是模块 A 和模块 B 只要其中任一个通过验证就算通过。第一种协作方式称为 all 方式(或者说“与关系”),第二种方式则被称为 any 方式(或者说“或关系”)。默认情况下,Nginx 使用的是 all 方式。
9、try-files
这个阶段专门用于实现标准配置指令try_files的功能,并不支持 Nginx 模块注册处理程序。try_files指令接受两个以上任意数量的参数,每个参数都指定了一个 URI. 这里假设配置了 N 个参数,则 Nginx 会在 try-files 阶段,依次把前 N-1 个参数映射为文件系统上的对象(文件或者目录),然后检查这些对象是否存在。一旦 Nginx 发现某个文件系统对象存在,就会在 try-files 阶段把当前请求的 URI 改写为该对象所对应的参数 URI(但不会包含末尾的斜杠字符,也不会发生 “内部跳转”)。如果前 N-1 个参数所对应的文件系统对象都不存在,try-files 阶段就会立即发起“内部跳转”到最后一个参数(即第 N 个参数)所指定的 URI.通过root配置指令所指定的“文档根目录”进行映射。例如,当“文档根目录”是 /var/www/ 的时候,请求 URI /foo/bar 会被映射为文件 /var/www/foo/bar,而请求 URI /foo/baz/ 则会被映射为目录 /var/www/foo/baz/. 注意这里是如何通过 URI 末尾的斜杠字符是否存在来区分“目录”和“文件”的。
10、content
Nginx 的 content 阶段是所有请求处理阶段中最为重要的一个,因为运行在这个阶段的配置指令一般都肩负着生成“内容”(content)并输出 HTTP 响应的使命。正因为其重要性,这个阶段的配置指令也异常丰富。echo、Nginx 变量漫谈(二)中接触到的echo_exec指令,Nginx 变量漫谈(三)中接触到的proxy_pass指令,Nginx 变量漫谈(五)中介绍过的echo_location指令,以及Nginx 变量漫谈(七)中介绍过的content_by_lua。
11、log
log阶段处理,比如记录访问量/统计平均响应时间。log_by_lua
参考资料:https://openresty.org/download/agentzh-nginx-tutorials-zhcn.html
二. OpenResty 执行阶段
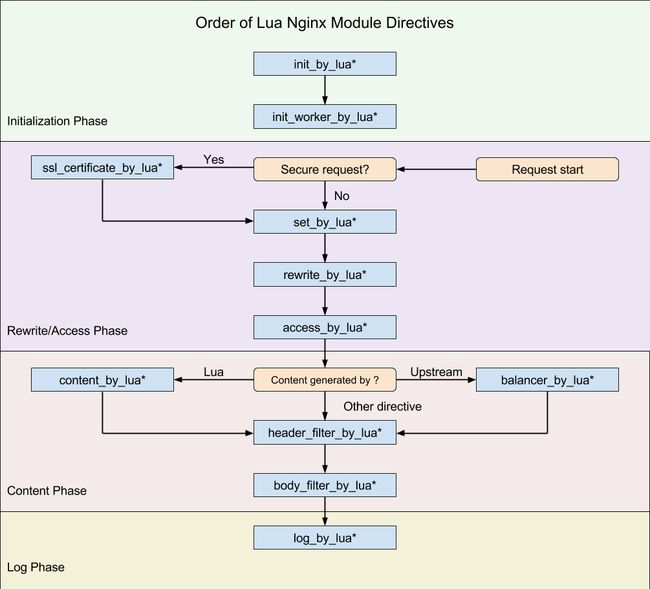
set_by_lua: 流程分支处理判断变量初始化
rewrite_by_lua: 转发、重定向、缓存等功能(例如特定请求代理到外网)
access_by_lua: IP准入、接口权限、A/B测试
content_by_lua: 内容生成
header_filter_by_lua: 应答HTTP过滤处理(添加修改头部信息)
body_filter_by_lua: 应答BODY过滤处理(例如完成应答内容统一成大写)
log_by_lua: 会话完成后本地异步完成日志记录(日志可以记录在本地,还可以同步到其他机器)
openresty最佳实践:
https://www.beibq.cn/book/m169355-11782
https://www.kancloud.cn/kancloud/openresty-best-practices/50428
三.kong插件机制
概述
插件可以认为是 Kong 管理 API 的核心,其模块化和可扩张性做得很好,尤其是其灵活的加载机制使得 Kong 能够针对不同 API 启用、组合任意插件。Kong 默认自带的插件集,按照功能的不同大致可以分为六大类:Authentication 认证、Security 安全、Traffic Control 流量控制、Analytics & Monitoring 分析监控、Transformations 请求报文处理、Logging 日志等。
无论是为了理解这些插件的工作原理,亦或者是定制开发属于自己的插件,熟悉插件的加载机制无疑都是一个关键的前提。
Kong 从 0.11.0 版本开始区分了社区版和商业版,节点之间的消息通信也改为了数据库轮训机制(原先是通过 serf 实现的),通过最终一致性实现了节点的无状态,任何时候节点只需连上数据库即可工作。之前的版本都相对来说太重,部署过于复杂。所以我这里将基于Kong 0.12.3版本分析其插件加载机制。
1. 插件的应用方式
Kong 按照插件的不同应用方式,大致可以分为两大类四小类:
全局插件 →GLOBAL
既不独自应用于 API,又不独自应用于 Consumer 的插件,而是应用于所有 API 和 Consumer 的插件。
局部插件 →LOCAL
应用于 API 的插件
仅仅应用于 API 的插件 →api
应用于 API 且指定 Consumer 的插件 →api & consumer
特定用户且特定 API 需要执行的插件。这个貌似不太好理解,我这里来举个例子:
假设现在有两个 API: /foo, /bar; 两个 Consumer: c1, c2
如果想让 c1 在调用 /foo 时启用插件 rate-limit,这里只需要为 /foo 添加 rate-limit 插件并指定 c1 Consumer 即可。
这里并不能单独为 c1 配置 consumer 插件,因为这样会使 c1 消费 /bar 时也调用 rate-limit 插件,显然是不符合需求的。
应用于 Consumer 的插件 →consumer
这四种方式插件的组合将伴随在 API 请求响应生命周期不同阶段中逐个被执行。同时 Kong 也将严格约束这四种方式在启用插件时的行为。比如:同一种方式只能添加同一个插件一次、不同方式之间可以添加同一个插件。
2. 插件的生效策略
所谓生效策略就是 Kong 组织上述提到的四种不同的插件应用方式的策略。结果是:API 最终要执行的插件等于LOCAL插件和GLOBAL插件的并集。也就是说:
API 最终要运行的插件=api & consumer+consumer+api+GLOBAL=LOCAL+GLOBAL
但是这里还有一个问题没有解决,就是虽然在同一种方式上同一插件只能应用一次,但是由于有上述四种不同的插件应用方式的存在。那么完全可能有同一插件在不同方式上均应用的情况,比如:rate-limit 插件既应用于consumer上,又应用于api上,那么这时候哪个生效?
答案是:consumer上的 rate-limit 生效。Kong 在处理上述四种方式插件冲突的优先级是:
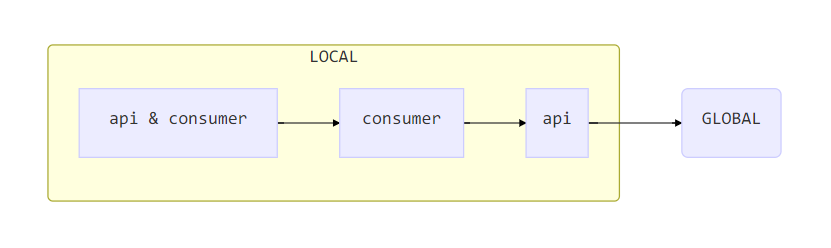
注意:这里并不是插件的执行顺序,而是处理插件冲突的优先级。
3. 插件的执行顺序
插件的执行顺序由插件自身的优先级唯一确定(既和插件应用的四种方式无关,也无关于插件的生效策略),其并不会随 API 的不同而改变。待确定插件执行的顺序之后,插件将随着 API 请求响应生命周期中的不同阶段逐个执行其相应的hook。

上图并不能视为插件的执行顺序,而是请求生命周期不同阶段的执行顺序,这里可以理解为插件的执行阶段。在不同的阶段中,插件均需按顺序执行其对应的hook。
值得一提的是,目前 Kong 默认自带的插件均运行在 access 以及之后的阶段。
4. 一个请求的一生
当一个请求在自己生命周期的不同阶段时,均需要按顺序(自身的优先级)遍历所有已安装插件(包括自己自定义的),以检查自己是否被启用(属于GLOBAL插件或者是LOCAL插件),并执行其对应的hook。我把它称之为 「phase 循环」。
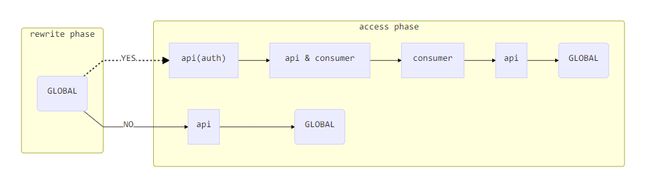
理解「phase 循环」对于掌握 Kong 插件机制至关重要!比如:
rewrite 循环
当一个请求进入到 rewrite 阶段时,所有已安装插件(包括自己自定义的)将会按照顺序(自身的优先级)检查自己是否属于GLOBAL插件。如果属于则执行其rewrite方法,否则检查下一个插件,直到检查完全部插件为止。
access 循环
接下来进入到 access 阶段,在这个阶段将完成插件生效策略的筛选。同样所有已安装插件继续按照顺序(当然还是自身的优先级)检查自己是否属于api插件,如果属于并且恰巧还是 auth 插件(auth 插件拥有较高的优先级执行都比较早),那么接下来将依次检查自己是否属于api & consumer、consumer、api、GLOBAL插件并执行其access方法;否则将直接检查自己是否属于api、GLOBAL插件。
filter 循环
经过上面两个阶段之后,就已经完成了插件生效策略的筛选。当前请求应该被执行的插件已经确定,并被缓存在自身中,并随着生命周期的结束而被销毁。当然这是一步很重的操作。不过也从这个阶段开始,Kong 在遍历所有插件时将直接从上面的缓存中查找,并执行相应的filter方法,而不再经过生效策略的筛选,这当然也是出于性能上的考量。
结语
通过理解上面概念,我现在来回答这个终极问题:到底是LOCAL插件先被执行,还是GLOBAL插件先被执行?
答案是:乱序的。因为插件的执行顺序由插件自身的优先级唯一确定。注意这里需要和插件的生效策略区分开来,后者的生效顺序总是LOCAL优先于GLOBAL。