一、相似度Similarity
序列的分析离不开相似度这个指标,相似度比较高的序列往往具有相似的结构、执行相似的功能。所以用未知序列blast得到的结果可以对未知序列进行推测。
当两个序列非常相似时,生物学家称之为同源。然而有一点不明确,就是什么程度的相似可以称之为“非常”相似呢?书上说一般长度为100以上核苷酸序列或者氨基酸序列,序列之间的一致度(identical)大于70%(nt)或25%(aa)可以推测同源。
不过有时,一致度或相似度很高的两个序列也有可能非同源,这种进化上的“趋同”现象可能是随机产生的,这样的一对序列可称为同功序列。或者序列相似度很低,但是蛋白质三维结构几乎一样的情况也有。分析的时候还要结合E-value,两序列中可对应的序列长度占两序列的比例,插入和删除的残基个数等一起判断是否是同源。推荐阅读往期推送【现学现卖】序列比对之identity VS similarity,【现学现卖】序列比对之bit-score VS E-value。
二、最棒的序列比对工具没有之一——BLAST
之前第六章主要介绍了分析一条氨基酸序列理化性质,结构域的方法。这章说说序列比对,比对就不得不用BLAST。NCBI中蛋白质相关的blast有:blastp(用氨基酸序列在氨基酸数据库中比对),tblastn(用氨基酸序列在核苷酸数据库中比对)。
1. NCBI-blastp
https://blast.ncbi.nlm.nih.gov/Blast.cgi?PROGRAM=blastp&PAGE_TYPE=BlastSearch&LINK_LOC=blasthome
以序列号P09405的氨基酸序列为例进行blastp。
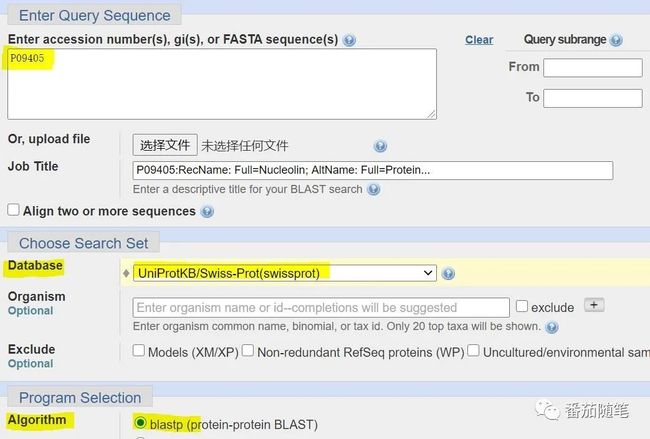
很快返回结果页面,点击按钮可以展开一些折叠的结果,还有filter工具筛选你感兴趣的东西。
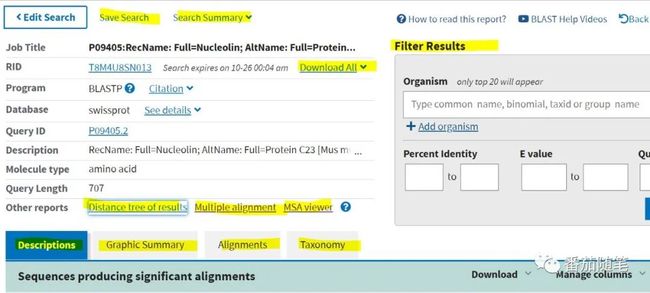
上图标记黄色的都可以点开看看,比如Graphic Summary打开后如下图。彩色部分展示的是数据库中得到的序列与查询序列(query sequence)比对的位置,不同的颜色体现相似程度/得分。前面的几个序列与查询序列匹配程度很高,后面短的粉色部分的信息也并不是没有用处,比如可以帮助我们找到蛋白质结构域。

在Alignments里,上方是查询序列,下方是匹配序列,中间那栏,如果是字母则表示匹配,如果是➕表示是相似氨基酸残基,如果是空则表示未匹配上。

2. NCBI-blastn
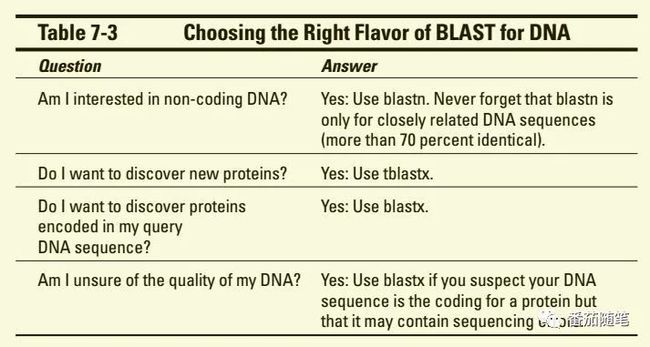
BLASTing DNA序列和蛋白质序列很类似,而且如果你知道DNA序列的ORF,可以翻译成氨基酸序列使用blastp,获得更加准确的结果。
DNA序列比对可用blastn,还有tblastx和blastx,这里面的t表示translated,就是你输入DNA序列,在blast之前会有工具将其翻译,再进行blast比对。tblastx数据库是TDNA数据库(系统将nt翻译为aa的一个数据库),blastx数据库是氨基酸序列库。至于不同情况用什么工具,见下图。
3. 用BLAST方式思考问题(一些BLAST可以解决的问题)
(1)在基因组中寻找目标基因
可以将基因组分为多条两端互相重叠的序列(2-5kb),然后用blastx在NR库(the Non Redundant protein database)中检索。
(2)预测蛋白质功能
用blastp在Swiss-Prot数据库中检索,你输入的蛋白序列可能拥有和高分结果相似的功能。
(3)预测蛋白质三级结构
用blastp在PDB数据库中检索,道理同(2)
4. 使用BLAST前可以设定的参数
一般情况下进行BLAST,会对organism进行限定,其他参数维持默认。那么什么情况下需要修改默认参数呢?比如没有返回结果或者结果的E-value数值大,可以更改矩阵或空位罚分;或者返回太多结果,则可以限定所使用的数据库、关键词、E值等。
(1)blastp
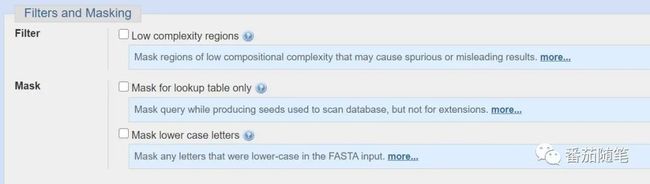
一些蛋白质序列的某一部分复杂程度比较低(low-complexity/ low-entropy),一种或几种氨基酸残基在一段区域内富集。这样两个序列比对会产生高分结果,但是它们很可能毫不相干。为了避免这个问题,可以勾选Algorithm parameters——filters and mask高级选项——“low complexity regions”,过滤这样的比对结果。
(2)blastn
对于DNA序列,限定的参数页面如下,其中word size是指开始一段比对的序列长度,size越大,比对速度越快、精度越低。

三、PSI-BLAST简单介绍
在blastp下方算法选择里,还有PSI-BLAST。即Position-Specific Iterated BLAST,位点特异性迭代BLAST。
先BLAST 到一系列相似序列,并对其中每一个位置上的元素构建PSSM矩阵。继续进行第二轮blast,再加上新搜索出来的序列结果构建新的PSSM矩阵。这样迭代,直到无法搜索出新的结果为止或者直到获得了足够的序列为止。
BLAST的结果都是相近序列,使用PSI-BLAST可以帮助我们找到远缘序列。

其他操作和BLAST类似,点击BLAST返回结果页面如下。

然后可以点击Run PSI-Blast iteration 2开始迭代,直到没有新的序列产生或产生的序列数目满意为止。迭代产生的序列,系统会自动标黄。
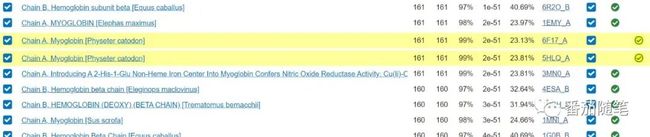
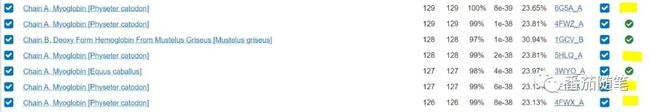
这里需要解释一下,如果选择了这条序列构建PSSM矩阵,那么迭代之后,序列后面会有绿色圆形对勾,如果像我这次没有勾选(荧光黄色的4条序列),则这些序列不参与构建矩阵。实际操作时,如果第N次迭代新增加的序列结果明显不对,则不勾选它构建矩阵,剩下的序列构建的矩阵进行下一次分析。
当输入的查询蛋白质序列包含多个结构域时,输出结果可能不太可信。因为很多八竿子打不着的蛋白质也会有相似结构域。这时候可以根据第六章里面寻找结构域的方法,找到结构域的位置,将长蛋白质序列根据结构域分割为片段,进行blast。这种分割分析也适用于大于200aa的蛋白质序列。
往期相关内容:
【陪你学·生信】序
【陪你学·生信】一、生信能帮我们做什么
【陪你学·生信】二、一些你肯定会用到的生信工具和基本操作
【陪你学·生信】三、核苷酸序列数据库的使用
【陪你学·生信】四、蛋白质相关的数据库
【陪你学·生信】五、当你有一段待分析的DNA序列(基础操作介绍)
【陪你学·生信】六、当你有一段待分析的氨基酸序列(基础操作介绍)