一、基础知识
- Cochrane图书馆是最权威的循证医学数据库
- Cochrane系统评价的指导是按照《Cochrane Handbook for Systematic Reviews of Interventions》进行,格式固定,一定要用RevMAN录入与分析数据,撰写系统评价计划书和全文。
----》可下2019载中文版,Cochrane干预措施系统评价手册
二、报告规范
- 基本步骤:提出问题-》收集资料-》评价资料-》分析和解释结果-》发表
- 报告规范标准参考:
- 1999年QUOROM(Quality of Reporting of Meta-analysis)
- 2009年PRISMA(Preferred Reporting Items for Systematic Reviews and Meta-analyses)
- Cochrame制定的专用报告格式
- MOOSE(Meta-analysis of observational Studies in Epidemiology)
-->都有中文版可以找
- 制作步骤参考:
- 《Cochrane Handbook for Systematic Reviews of Interventions》-->提出了10个步骤
- 《Systematic Reviews in Health Care: Meta0analysis in Context》-->提出了8个步骤
- 上面两个是基于随机对照试验的系统评价设计的,还可以参考诊断性研究的手册《Cochrane handbook for Diagnostic Test Accuracy Reviews》-->参考:http://srdta.cochrane.org/handbook-dta-reviews
三、原始研究类型和报告规范
参考书目《临床流行病学:临床科研设计、测量与评价》、《The lancet handbook of essential concepts in clinical research》、《A dictionary of epidemiology》
-
分类
- 是否认为干预:实验性研究(experimental study)与观察性研究(observational study)。具体细节原文描述。
-
RCT(Randomized controlled trial)随机对照试验
- 有试验组合对照组。
- 结果一般是阳性或阴性,组成四格表。
- 报告规范《Consolidated Standards of Reporting Trials》CONSORT声明,可参考2010年版本。
- 针对其他试验类型CONSORT有很多扩展版。可以参考http://www.consort-statement.org/home
-
非随机实验性研究(none-randomized experimental study)
- 非随机交叉试验
- 非随机同期对照试验
- 前-后对照试验
- 报告规范TREND声明(The transparent reporting of evaluations with nonrandomized designs),参考:http://www.cdc.gov.trendstatement/
-
观察性研究(observational study)
- 分为分析学研究(analytic study)和描述性研究(descriptive study)。
- 队列研究(cohort study),也叫发病率研究(incidence study),纵断面研究(longitudinal study),前瞻性研究(forward-looking study/perspective study),随访性研究(follow-up study),并行性研究(concurrent study)
- 病例-对照研究(case-control study)
- 描述性研究
- 报告规范:STROBE(Strengthening the Reporting of Observational Studies in Epidemiology),参考 http://www.strobe-statement.org
- 另一个规范是STREGA(Strengthing the Reporting of Genetic Association Studies)
-
筛查试验(screening test)与诊断性实验(diagnostic test/trial)
- 涉及的指标: 灵敏度(sensitivity,Sen)/真阳性率,特异度(specificity,Spe)/真阴性率,阳性预测值(positive predictive values, PPV),阴性预测值(negative predictive values,NPV)以及似然比(likelihood ratio,LR)
- 报告规范:STARD(The Standards for Reporting of Dignostic Accuracy),参考:http://www.stard-statement.org/
-
动物实验
- 报告规范: 《动物实验研究报告指南》(Animals in Research: Reporting in Vivo Experiments,ARRIV),参考 http://www.nc3rs.org.uk/page.asp?id=1357
四、常用中英文数据库
- 原始研究的获取:
- 全文数据库: 中国知网(cnki),威立(Wiley),爱思唯尔(Elservier)
- 文献传递服务机构: 清华大学文献馆际互借系统,中国高等教育文献保障系统(CALIS),国家科技图书文献中心(NSTL)
- 免费资源: DOAJ(www.doaj.org), www.freefulltext.com, intl.highwire.org, www.pubmedcentral.org, www.plos.org, www.freefullpdf.com
- 常用数据库:
- Cochrane图书馆
- PubMed:www.ncbi.nlm.nih.gov/pubmed
- EMBASE: www.embase.com
- OVID: gateway.ovid.com
- 中国生物医学文献数据库: www.sinomed.ac.cn
五、原始研究的质量评价工具
第一节、相关术语
主要工具:
- 单个评价条目(components/items)
- 清单(checklist/list)
- 量表(scale)
-
随机化(randomization)
- 两种形式:随机抽样(random sample)与 随机分组(random allocation)--->随机分入实验组(intervention)或对照组(control)/比较组(comparsion)
- 正误方法:正确的随机方法可以分为手工方法和计算机随机方法。手工方法可以是掷硬币,掷骰子,抽签/抓阄等计算机随机是产生随机数。
-
分配隐藏(allocation concealment)
- 这是指在双臂或多臂随机对照试验中采用的一种方法,使研究对象及研究者不知道对象的任何情况,避免因为认为因素影响随机分组。
- 正误方法:顺序编号、不透明的封口信封、药房控制、编号或编码的容器,中心随机法(电话告知研究办公室),或其他描述分配隐藏包括隐藏可信因素的方法。
-
盲法(blinding)or 面罩法(masking)
- 研究对象和研究者对研究对象的分配、接受试验及来源处于未知状态
- 可以分为:单盲(single blinding),双盲(double blinding),三盲(triple blinding),四盲(quadruple blinding)
- 正误方法:单模拟(simple-dummy)与双模拟(double-dummy)
基线可比性(baseline characteristics)
损耗(attrition)包括失访(lost to follow-up),退出(dropout/withdraw),无应答(non-response)
意向性治疗分析(intention-to-treat analysis ITT)
-
点估计值(point estimation):也是效应值的点估计,指直接使用统计量估计总体参数的方法。比如从总体中抽样N个样本,样本的中位数就可以当做是总体的中位数。但是点估计不能告诉所估计的未知总体中位数的可信程度,可信程度用可信区间(confidence interval,CI)表示。
--》一般衡量点估计是否优良三个标准: 无偏性(unbiasdness),一致性(consistency),有效性(validity)
暴露(exposure):研究对象接触过某种待研究的物质。
第二节、质量评价的相关概念
质量:实验设计产生无偏倚的可能性或者设计与研究过程中反映结论有效性的一些列因素,这些因素与临床试验的内部有效性、外部有效性和统计分析(external validity)有关。
真实性(vaildity):内部真实性(internal validity)与外部真实性(external validity)
精确性(percision):又称为可靠性(reliability)或重复性(reproducibility)
偏倚:包括选择偏倚,实施偏倚,失访偏倚和测量偏倚
质量评价(quality assessment):评估单个研究在设计、实施、结果分析整个过程中可能出现的偏倚程度。
第三节、随机对照试验的质量评价工具
-
随机对照试验(randomized controoled trial, RCT)与临床对照试验(controlled clinical trial,CCT),判定标准主要包括:
- 在一个或多个患者中中进行的一种研究
- 比较两种干预措施
- RCT采用随机分配法,CCT采用半随机分配法
- 提示性术语有:随机(random)、交替(crossover/cross-over)、双盲(double-blind)或安慰剂(placebo)等
-
Cochrane风险偏倚评估工具
- Cochrane系统评价手册 认为“研究质量”和“研究偏倚”是有区别的,偏倚 能够更加真实反映a研究存在的缺陷。 参考“Cochrane风险偏倚评估工具(the Cochrane collaboration's tool for assessing risk of bias)”
-
PEDro量表
- PEDro(物理治疗证据数据库 Physiotherapy Evidence Database), http://www.pedro.org.au, 这个数据库旨在使用最佳证据与临床应用来强化物理治疗服务的有效性。
- PEDro量表(PEDro scale)是CEBP基于Delphi清单制作的RCT评价量表。
- PEDro(物理治疗证据数据库 Physiotherapy Evidence Database), http://www.pedro.org.au, 这个数据库旨在使用最佳证据与临床应用来强化物理治疗服务的有效性。
Delphi清单(Delphi list)
-
CASP清单
这是英国牛津循证医学 中心文献严格评价项目CASP (Critical Appraisal Skills Programme)
CASP Checklist参考 http://www.casp-uk.net
-
Jadad量表(Jadad scale)
简单明了,但是在Cochrane系统评价员手册5.0被指出有问题,不被推荐
建议将Jadad量表和Kenneth F. Schulz的隐蔽分组评价方法结合起来更合适。
-
Chalmers量表 (Chalmers scale)
- 实施繁琐,花费时间较长,当前应用好像较少
-
CONSORT声明
- CONSORT声明(Consolidated Standards of Reporting Trials Statement)
- 告RCT必备的基本项目清单和描述整个试验过程中受试者流程的流程图组成
- 主要针对的是两组平行设计的RCT
- 边振甲指定了针对中医药的CONSORT声明。
第四节、观察性研究的质量评价工具
观察性 研究(observational study)又称为 非实验性研究(non-experimental study),是指没有加入研究人员的 任何干预措施,允许事件自然发展的研究过程。
-
NOS量表
- The Newcastle-Ottawa Scale(NOS)适用于评价病例-对照研究和队列研究。
- http://www.ohri.ca/programs/clinical_epidemiology/oxford.asp
CASP清单
* Critical Appraisal Skill Program(CASP)-
JBI标准
- JBI PACES是澳大利亚循证护理 中心(Joanna Briggs institute ,JBI)的临床证据评鉴系统(Practical Application of Clinical Evidence System, PACES)
- http://www.joannabriggs.edu.au
- JBI PACES是澳大利亚循证护理 中心(Joanna Briggs institute ,JBI)的临床证据评鉴系统(Practical Application of Clinical Evidence System, PACES)
AHRQ(Agency for Healthcare Research and Quality)
-
Combie横断面研究评价工具
- 出自 Iain Crombie在 1996年的书《The Pocket Guide to Critical Appraisal》
STROBE声明:
* The Strengthening the Reporting of Observational Studies in Epidemiology
* 分子流行病学观察性研究科参考扩展版 STROBE-MESTREGA声明
* Strengthening the Reporting of Genetic Association Studies,这也是 属于 STROBE的扩展版
* http://www.medicine.uottawa.ca/public-health-genomics/web.eng.strega.html
第五节、非随机实验性研究的质量评价工具
MINORS条目(Methodological Index for Non-randomized Studies)
Reisch评价工具
TREND声明:The Transparent Reporting of Evaluations with Nonrandomized Designs, 参考: http://www.cdc.gov/trendstatement
第六节、诊断性研究及动物实验的质量评价工具
诊断性研究
诊断实验是指为给患者做出诊断而采用的各种实验室检查、仪器设备检查及其他方法
- QUADAS工具: Quality Assessment of Diagnostic Accuracy Studies
- CASP清单: Critical Appraisal Skill Program
- STARD声明: The Standards for Reporting of Diagnostic Accuracy
动物实验
- STAIR清单:The Initial Stroke Therapy Academic Industry Roundtable
- CAMARADES清单: Collaborative Approach to Meta Analysis and Review of Animal Data From Experimental Stroke, http://www.camarades.info
- ARRIV指南: Animals in Research: Reporting in Vivo Experiments
六、资料提取
主要参考 Cochrane handbook for Systematic Reviews of Interventions。
- 资料来源: 期刊,书籍,论文集,会议摘要,图书馆,网站,联系作者等等。
- 基本原则:客观、提前进行培训、预提取、多人提取以及妥当处理分歧。
- 设计资料提取表数据的转换
数据的转换
-
利用组内均数的可信区间计算标准差(SD)
- 一般使用95%可信区间
- 若数据符合正态分布:若样本量大(),则, 如果是90%可信区间则3.92换为3.29,若可信区间99%,则为5.15
- 若样本量小(),则, 其中t值可以在excel中用公式“”获得,其中 ,。
- 若样本量,两种方法都可以
- 数据不符合正态分布,则可以对原始数据进行对数转换,然后如果转换后的数据符合正态分布,则继续用上面的方法。
-
利用组间均数差以及标准误、可信区间、t值或P值计算标准差。
若原始研究仅仅提供了利用组间均数差(MD)以及标准误(SE)、可信区间、t值或P值,也可以换算出标准差(SD)。此时,需假设各组的SE相等,且进行Meta分析时计算出的SE将被同时应用到实验组和对照组,即输入的两组的SE是同一个值。
- 通过P值计算SD,第一、通过P计算t,还是可以通过上面的tinv公式计算,概率即P值,自由度=(NE+NC-2),如果没有报告具体P值,而是报告P<0.05,则可用P值得上限做概率估计,即P=0.05; 第二、通过t计算SE。 ; 第三、通过SE计算SD。
- 通过t值计算SD。报告了t值就直接用上面的后两步。
- 通过可信区间计算SD, 方法和组内计算的方法完全一致。
-
通过中位数和四分位数间距估算均数和标准差。
- 如果数据呈现正态分布,则直接用中位数代替均数进行Meta分析
- 如果非正态分布,不能用中位数代替均数。
- 四分位数间距(interquartile range)是指上四分位数和下四分位数的差值,IQR反映偏态分布数据的离散程度,类似于正态分布数据的标准差。如果样本量大,近似正态分布,那么。 如果不满足条件,那么久不能用这个公式算SD。
-
合并亚组数据
二分类变量情况下:直接将各亚组的样本量和发生目标事件的病例数相加即可。
-
连续性变量的情况:假设亚组A的样本量为,均数为,标准差;亚组的相关数据为,。那么合并后的样本量 ,均数为;标准差为:
OR与RR值:
观察性研究中,因需要对相应的风险因素进行校正,故原始研究多提供了RR,OR以及95%可信区间。
RR值多用于队列研究
OR值多用于病例-对照研究及横断面研究
-
,其中表示非暴露组结局事件的发生率,表示暴露组结局事件的发生率。所以:
标准误(SE)的计算公式为:
- HR与RR:在队列研究中,因为有些涉及生存资料,所以报告的是HR以及其95%CI,这个时候可以认为,直接将HR看成RR,进行合并。
七、Meta分析中常用统计学指标及方法
第一节、相关概念
- 效应量(effect size/effect magnitude):这是指临床上有意义或实用价值的数值或观察指标变量,是单个研究结果的综合指标,需要根据研究的性质、资料的类型进行确定。
- 率(rate)、比值(ratio)、比例(proportion)
- 计数(dichotomous data),计量(measurement data),等级资料(ranked data)
- 计数资料:清点个数
- 计量资料:对连续型变量或者离散型变量进行测量
- 等级资料:对不同程度进行分等级,然后再分类。
- 计量资料:对连续型变量或者离散型变量进行测量
- 计数资料:清点个数
- 时间-事件数据(time-to-event data):既反映事件发生与否,又反映发生时间的数据。
- 生存分析(survival analysis):是将事件的结果和出现这个结果所经历的时间结合起来分析的一类统计分析方法。
- 危险度(risk)和几率(odds)
- risk: 某个时间将要发生的概率
- odds: 时间发生与不发生的比率
- 可信区间(confidence interval,CI)
- 也叫置信区间,主要用于估计总体参数,从获取的样本数据资料估计某个指标的总体值。
- 常用的有率的可信区间,两率差值的可信区间,均数的可信区间,两均数差值的可信区间,相对危险度可信区间等等。
- 循证医学常用的是率的可信区间,RR或者OR的可信区间,均数的可信区间,两均数差值的可信区间。
第二节、计数资料的效应量
-
表格
- 循证医学中计数资料常用的描述性指标有RD,OR,RR,RRR,ARR,NMT等。计数资料中的数据通常以两组发生事件数和未发生事件数来表示,即经典的表格。根据这些数据可以计算RR,OR或者RD。
事件数 未发生事件数 合计(N) 干预组/暴露组 A B 对照组/非暴露组 C D EER(experimental event rate)、CER(control event rate): EER即实验组中某时间发生率,CER即对照组中某时间的发生率。
*
-
RD(rate difference)及CI
* 两个发生率的差即RD,率差。比如EER-CER,他表达的是两组事件发生率的绝对差(absolute risk difference,ARD),其大小反映试验效应的大小。- RD的意义还取决于时间的临床重要性
- RD等于0,表示等效。当RD的可信区间不包含0,那么两个率是有差别的。反之,RD的CI包含0,则无统计学意义。
- 通常只有队列研究和随机对照试验的结果可以计算RD。
- RD的计算为:
- RD的CI计算:
- RD的标准误:
-
RR(relative risk)及CI
* RR也可以是risk ratio, 他是暴露组中发生结局的频率除以非暴露组中解决的频率,是前瞻性研究中较常见的指标。- 如果RR=1,表示两组中的频率相同,暴露与结局无关联。RR>1,表示结局在暴露组中更加频繁,暴露与危险性增加相关联。RR<1,提示一种保护性作用。
- RR的CI应该用自然对数进行计算,就是求RR的自然对数值以及他的标准误
- 的CI为:
- RR的CI为:
-
OR(odds ratio)及CI
- odds raatio也称为交叉乘积比(cross-product ratio)或相对比值(relative odds)
- OR是病例-对照研究中常见的衡量关联的方法,他显示在病例组中暴露的可能性除以对照组中暴露的可能性。
- OR=0,没什么意义。OR>1,提示暴露与为危险性增高有关系,OR<1,提示有保护作
- OR的CI同样需要通过自然对数计算:
- 的CI为:
- OR的CI为:
RRR(relative risk reduction)及CI
* RRR是相对危险减少率。
*
* RRR的CI=1-RR的CI、
* RRR反映了某试验因素使某个结果的发生率增加或减少的相对量,但是该指标无法衡量发生率增减的绝对量。-
RRI(relative risk increase)及CI
- RRI:相对危险增加率
- 试验组中某不利结果的发生率为,对照组中某不利结果的发生率为
- 这个指标可反映采用试验因素处理后,患者的不利结果增加的百分比。
- CI的计算与RRR相同
-
RBI(relative benefit increase)
- 相对收益增加率
- 试验组中某有利结果的发生率为,对照组中某有利结果的发生率为
- 反映采用试验因素处理后,患者有益结果增加的百分比。
AAR(absolute risk reduction)与CI
- 绝对危险减少率 ARR
- AAR=|CER-EER|
- AAR的CI:
- AAI(absolute risk increase)及CI
- 绝对危险度增加率(ARI),他是试验组中不利结果发生率与不利结果发生率的差值。
- 可以反映采用试验因素后,患者的不利结果增加的绝对值。
- ABI(absolute benefit increase)及CI
* 绝对收益增加率
* - NNT(the number needed to treat)及CI
* the number of patients who needed to treated to achieve one additional favorable outcome.
*
* NMT越小,防治效果就越好,临床意义就越大
* NMT的SE没法计算,但是NNT=1/ARR,故 NNT 95%CI 的计算可以利用ARR的CI
* NNT 95% CI的下限=1/ARR的上限值
* NNT 95% CI的上限=1/ARR的下限值 - NNH(the number need to harm)及CI
* NNH是对患者采用某种防治措施处理,出现1例副作用需要处理的病例数。 the number need to harm one more pateents from the therapy
*
* NNH越小,某治疗措施引起的副作用就越大。
* NNH的CI可由ARI的上下限导数计算得到。 - LHH(linkelihood of being helped vs harmd)
* LHH是防治性措施收益与危害的似然比
* LHH=NNH/NNT
* 他反映了防止措施给受试者带来的受益于危害的比例。
* LHH>1:利大于弊;LHH<1,弊大于利。
第三节、计量资料的效应量
- 数值资料的单个研究主要使用加权均数差(WMD)和标准化均数差(SMD)来描述其效应量。计量资料常用的描述指标有均数(mean, ),中位数(median,M)、几何均数(geometric mean, G)、标准差(standard deviation, S)、四分位距(interquartile range,IQR)等。
WMD和SMD的森林图无效线竖线的横轴尺度为0,每条横线为该研究的95%CI上下限的连线。其线条长短直观地表示了CI范围的大小。线条中央的小方块为WMD,SMD值得位置。 方块大小为该研究权重大小。若某个研究95%CI的线条横跨为无效竖线,则该研究没有统计学意义;反之,若该横线落在无效竖线的左侧或者右侧,该研究具有统计学意义。 - WMD(weighted mean difference)
- 加权均数差用于meta分析中所有研究具有相同连续性结局变量(eg,体重)和测量单位时。
- 计算WMD,需知道每个原始研究的均数、标准差和样本量
- RevMan定义计算WMD的权重为方差的倒数
- 两均数差(d)可计算为:
- d的方差,其中与分别是两组的样本量。
- 两均数差(d)的SE的计算:
- 95%CI位:
- WMD即为两均数的差值,他反映一试验原有的测量单位,真实反映了试验效应,消除了绝对值大小对结果的影响。
- SMD(standardized mean defference)
- 标准化均数差SMD为两组估计均数差值除以平均标准差。由于消除了量纲的影响,因而结果可以被合并。
- SMD的方法不适用于尺度方向不同的情况。
- 某个研究的标准化均数差d:
- 标准化均数差d的方差,也叫.
第四节、Meta分析方法及模型
-
常用的Meta分析方法:包括倒方差法(generic inverse variance)、Mantel-Haenszel法(M-H法)、Peto法、Dersimonian-Laird法(D-L法)
Peto法适用于大型研究的小效应量的合并分析,包括生存资料(eg:死亡率)
倒方差法,M-H法和Peto法优于在分配权重方法上的差异,各研究的权重仍然可能出现很大的差异,但是对合并效应量的影响不会太大。
OR,RR,RD的选择一般按照小事件时候选择OR Peto法或M-H法。大事件选择RR。 另外RD在两种情况下都可以选。
-
常用的Meta分析方法
资料类型 合并效应量 模型选择 计算方法 计数资料 OR 固定效应模型 Peto 固定效应模型 M-H 随机效应模型 D-L RR 固定效应模型 M-H 随机效应模型 D-L RD 固定效应模型 M-H 随机效应模型 D-L 计量资料 WMD 固定效应模型 倒方差法 随机效应模型 D-L SMD 固定效应模型 倒方差法 随机效应模型 D-L 个案(时间-事件)资料 OR 固定效应模型 Peto
-
Meta分析的合并效应量
资料类型 研究设计类型 合并效应量 计数资料 随机对照试验 RR,OR,RD 非随机实验性研究 OR,RR,RD 队列研究 RR,OR,RD 病例对照研究 OR 横断面研究 OR 诊断准确性试验 OR 计量资料 随机对照试验 WMD,SMD 非随机实验性研究 WMD,SMD 队列研究 WMD,SMD 病例对照研究 WMD,SMD 横断面研究 WMD,SMD
-
Meta分析的效应模型。
- 主要分为固定效应模型(fixed-effect model)和随机效应模型(random-effects model)
- 研究间的同质性好()选固定效应模型,反之,选随机效应模型
- 区别在于:a. 使用情况不同。固定效应模型应用的前提是假设全部研究结果的方向和效应大小基本相同,也就是各个独立研究的结果趋向一致,一致性检验差异无显著性,所以用于无差异或差异较小的研究。随机效应模型相反。b.产生的结果不同,固定效应模型产生同质研究特集的结果推论,而随机效应模型产生研究全集的结果推论。 c.用随机效应模型方法可以代替固定效应模型。但固定不能完全代替随机。d. 固定效应模型常用M-H法,Peto法,以及使用率直接计算OR值法。
八、Meta分析中的异质性
第一节、异质性的含义及类型
- 异质性(heterogeneity):就是各个研究间的不相似性。
- 类型:临床异质性,方法学异质性,统计学异质性
第二节、异质性的识别
-
Q检验
如果Q检验无效假设为,即纳入研究效应量都相同。假设真正的效应量是一致的,但是由于存在抽样误差导致实际结果不一致,这时候仍然可以认为研究间效应是同质的。如果研究结果差异过大,超出抽样误差所能解释的范围,则需要考虑异质性存在。Q统计量可以定义为:
其中,为第i个研究的效应量,可以是OR,RR或RD。 为所有研究的平均效应量。、分别是第i个研究的标准误和权重。。
Q值为(对数)效应量的标准化的平方和,因此服从自由度的中心分布,K是纳入研究的个数。Q值越大,其对应的p值越小。若, 则,表明研究间存在异质性。
- Q检验的检验标准通常设定为,就是当时候,研究间存在异质性。
-
检验
- 这个统计量反映异质性部分在效应量总的变异中所占的比重。
- ,其中Q为异质性检验的卡方值,K为纳入Meta分析的研究个数。
- 的取值在0-100%之间,当为0时(实际为负值也视为0),表明没有观察到异质性。值越大则异质性越大。
- Higgins JPT分为了三个程度:低中高,对应为25%,50%,75%。
- Cochrane分为四个程度:0-40%轻度,40%-60%中度,50%-90%较大,75%-100%很大的异质性。
- 作为一个率,用于描述由各个研究所致的,而非抽样误差所引起的异质性占总变异的百分比。他克服了Q统计量对纳入研究个数的依赖,可以更好衡量多个研究结果间异质性程度大小。
- 在Cochrane中,只要不大于50%,异质性就可以接受。
-
检验
- 通过对统计量Q进行自由度(文献数)的校正,结果方差分布的参数估计可以得到:
, 其中K表示纳入meta分析的研究数。
-
H的标准误为:
-
按照正态近似法可以求得H统计量的可信区间为:
其中为标准正态分布分位点的值,比如.
H为1,表示无异质性,一般H>1.5,表示存在异质性; H<1.2则提示可认为各研究同质。若在1.2
图示法:森林图(forest plot), 星状图(radial plot),拉贝图(L' Abble plot),加尔布雷思图(Galbraith plot)
第三节:异质性的处理
-
处理流程:
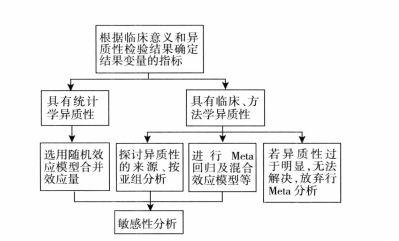 image.png
image.png
-
Meta回归
通过回归方程,反应1个或多个解释变量与结果变量之间的关系。只有研究数量大于10个才可以用回归。可以在Stata中用“metareg”实现。
其他软件还有Comprehensive Meta Analysis V2,Meta-Disc, MetaAnalyst。
-
亚组分析(subgroup analysis)
这是在出现异质性或要回答特定患者、特定干预措施或特定研究时,从临床异质性和方法学异质性的角度探讨异质性的来源,根本上解决同质性才能合并效应量的问题。可以按照不同年龄,病情程度,性别,设计方案,等等进行亚组分析。
-
敏感性分析(sensitivity analysis)
用于决定一个研究结果的敏感性,或者他对系统评价或meta分析如何改变的一种分析方法。可以有几种方法:
- 改变研究类型的纳入标准、研究对象、干预措施或终点指标;
- 纳入或排除某些含糊不清的研究,不管其是否符合纳入标准
- 使用某些结果不太确定的研究估计值重新分析数据
- 对缺失数据进行合理的估计后重新分析数据。
- 使用不同统计方法重新分析数据,比如随机效应模型代替固定效应模型。
- 从纳入研究中提出质量相对较差的文献后重新进行Meta分析,比较前后合并效应间是否有显著性差异。
- 按照不同的研究特征,比如不同的统计方法,研究的方法学质量高低、样本量大小、是否包括未发表的研究等,对纳入文献进行分层Meta分析。
-
选用随机效应模型
- 固定效应模型假设所有观察到的差异都是由偶然机会引起的一种合并效应量的计算模型,这些研究假定为测量相同的总体效应。
- 随机效应模型则是统计Meta分析中研究内抽样误差(方差)和研究间变异以估计结果的不确定性(可信区间)的模型。
- 随机效应模型比固定效应模型有更宽的可信区间。
-
改变效应量
仅仅改变结局指标的效应量,也可能达到充分去除异质性的效果。比如对二分类变量,结局指标的效应量由绝对测量标度(如危险差RR)变为相对测量标度(比如对数比OR)。对于连续型变量,由WMD改变为SMD,或者转换为对数形式。
-
放弃行Meta分析
如果异质性国语明显,就放弃Meta分析,只能对结果做一般的统计描述,即定性分析或狭义的系统评价。
九、系统评价/Meta分析中的偏倚
第一节、偏倚的含义及类型
- bias: 也称为系统误差(systematic error),他是指研究的结果或推论偏离真实值,或导致这种偏离的过程,也可以说是在资料的收集、分析、解释或发表过程中,能够导致结论系统地与真实值有所不同的任何趋势。
- 原始文献的bias: 选择偏倚selection bias, 实施偏倚performance bias, 损耗偏倚attrition bias, 测量偏倚detection bias,报告偏倚reporting bias, 其他偏倚 other bias.
- 系统评价/Meta分析中的偏倚
- Felson分类:抽样偏倚,选择偏倚和研究内偏倚
- Cochrane分类:发表偏倚 publication bias, 时滞偏倚 time lag bias, 多重/重复发表偏倚(multiple/duplicate publication bias),发表位置偏倚(location bias),引用偏倚 citation bias, 语言偏倚 language bias, 结果报告偏倚 outcome reporting bias。
第二节、报告偏倚的评价
-
漏斗图(funnel plot)
- 漏斗图是假设效应量的精度随着样本量的增加而增加,因此样本量小的研究精度低,分布在漏斗图的地步,且向周围分散。样本量大的精度高,分布在漏斗图的顶部,且向中间集中
- 发表偏倚会导致漏斗图不对称(底部出现一个角落缺失)。
- 其他导致不对称可能原因有低质量小样本试验(poor methodological quality of smaller studies), 真实的异质性(true heterogeneity),假象(artefactual),机遇(chance)
-
Egger线性回归法
- Egger线性回归法是为了口服漏斗法的不足,而开发的一种简便的线性回归法检验漏斗图的对称性的定量方法。
- 具体方法:先计算纳入Meta分析的每个研究的标准正态离差(standard normal deviate, SND)和精确性(precision)。假设有个研究纳入,和为第个研究的效应和方差,那么, ; 以精度为自变量,SND为因变量建立回归方程,即 。小样本量研究精确性低,在x轴上接近0,标准误大,则SND也较小,在y轴上也接近0,所以小样本量研究代表的散点在回归直线中应该是接近远点。大样本量研究精确性高,SND较大。理论上,如果纳入Meta分析的研究同质性好,并且没有报告偏倚,则回归直线的截距 ,即该回归直线经过原点,而回归系数b则代表了效应的大小和方向,这也对应了对称的漏斗图。如果回归直线不经过原点,则截距代表了漏斗图的不对称程度,越大,不对称的程度越高。实际操作中,求出线性回归方程的截距以及95% CI,再对是否为0进行假设检验,以进一步推断漏斗图是否对称,从而判断是否存在报告偏倚。
- 在Stata软件中,Egger回归法以标准化的效应量(或者)为因变量y,以效应估计量的精确性(比如标准误的倒数)为自变量x,建立线性回归方程。
-
Begg秩相关法
Begg rank correlation test是检验标准化的效应()与效应方差()之间的相关关系。一般情况下,方差与样本量成反比,秩相关检验也是检验效应和样本量的相关性。在不存在报告偏倚的无效假设下,标准化的效应可认为是独立同分布的。
假设和分别是Meta分析中第i个研究的效应量及其方差,和分别为标准化的效应量及的方差,则:
,其中,, .
按照每个纳入研究中和的大小排列秩次,再按的值对子排序,然后比较所有可能的对和的秩次,计算这两组秩的相关性。
如果用表示,按照和相同顺序排队候的对子数。那么由下式计算正态统计量:
, 若,则提示存在报告偏倚,反之则没有报告偏倚。
-
减补法(trim and fill method)
这是先减掉初步估计后漏斗图的不对称部分,用剩余对称部分估计漏斗图的中心值,然后沿着中心两侧补上被剪切部分以及相应的遗漏部分,最后基于贴补后的漏斗图估计合并效应量的真实值。
-
失安全系数(fail-safe number)
这是一种敏感性分析方法,他是当分析结果具有统计学意义的时候,计算需要多少阴性结果的报告才可以使得结论逆转。计算公式是:, 其中为每个有统计学意义的研究的Z值,未显著性水平的单侧Z值,一般选, 为1.645。失安全系数越大,说明Meta分析的结果越稳定,结果被推翻的可能性很小。
-
Macaskill's 检验
Macaskill's检验也叫做漏斗图回归法(funnel plot regression method),他的原理是直接以效应值( )为因变量,样本量( )为自变量建立回归方程。如果不存在发表偏倚,那么斜率应该是0,截距代表总体的效应值。如果得到的回归方程,经过假设检验后斜率不是0,那么可能有发表偏倚;如果斜率接近0,并且无统计学意义,那么可以认为效应量和研究例数之间无数量依存关系,即Meta分析不存在发表偏倚。权重为效应量的方差的倒数。漏斗图回归也可以认为是将漏斗图顺时针旋转90度后在进行回归。
-
Richy法
这个方法引入了物理学力矩(moment of force)原理。他计算这样一个统计量:
其中表示每个研究的效应值,为平均效应值,为精度。
, 相当于物理中的力乘以力矩的概念,利用非参数方法求出所有MF的95% CI,如果X的值在这个区间外,就认为存在发表偏倚。
敏感性分析(sensitivity analysis)
-
其他方法
包括Hackshaw's法、Sugita's法等,但是不成熟。
十、诊断准确性试验及Meta分析的统计学基础
第一节、诊断试验研究的基本要点
确定正确金标准,也就是学术界可以明确肯定和排除某种疾病最佳、最准确的诊断方法。
选择合适的研究对象
盲法的实施以及同步对比实验结果
-
诊断试验研究样本量估计
可以按照有关总体率的样本含量估计方法,以灵敏度来估计病例组、特异度估计对照组样本容量:
其中,p为灵敏度或特异度, 为灵敏度或特异度,为容许误差的大小,为型错误的概率,为与检验水准相对应的界值。
第二节、诊断试验的评价指标
-
对于二分类结果,我们将测定值分为阴性和阳性两种,那么可以将金标准及诊断实验的检测结果整理为表格。诊断实验及金标准的检测结果:
诊断试验结果(T) 金标准诊断(D) 合计 病例(D+) 对照(D-) 阳性(T+) TP 真阳性 FP 假阳性 TP+FP 阴性(T-) FN 假阴性 TN 真阴性 FN+TN 合计 TP+FN FP+TN N
-
灵敏度(sensitivity,Sen)
也叫做真阳性率,即实际有病并且按照诊断试验被正确判断有病的概率。反应诊断试验检出有病的能力。
-
特异度(specificity ,Spe)
也叫做真阴性率,就是实际无病并且按照诊断试验被正确判断为无病的概率。反映诊断试验排除无病的能力。
-
假阴性率(false negative rate, FNR)
也叫漏诊率或者第二类错误(),他是实际有病但是被诊断试验错判为无病的概率,因此灵敏度越高,漏诊越少。
-
假阳性率(false positive rate, FPR)
也叫误诊率或者第一类错误,就是实际无病却被诊断试验错判为有病的概率,因此特异度越高,误诊越少。
-
正确诊断指数(Youden's index)
他是灵敏度和特异度之和减去1。
-
似然比(likelihood rate, LR)
病例组与对照组中出现阳性或阴性结果的概率之比,反映了测定结果的诊断价值。包括阳性似然比(positive likelihood ratio, LR+)和阴性似然比(negative likelihood ratio, LR-)。
LR=1说明在病例组和对照组中诊断试验的检测结果的概率是相同的,则该方法无诊断价值。 LR+越大,检测方法证实疾病的能力越强;LR-越小,检测方法排除疾病的能力越强。 一般似然比大于10可以确诊疾病,而小于0.1排除患病的可能。
-
预测值(predictive value, PV)
是反映诊断试验结果与实际(金标准结果)符合的概率,包括阳性预测值(positive PV, PV+)和阴性预测值(negative PV, PV-)。阳性预测值是试验结果中真正患病的概率,阴性预测值是阴性结果中真正未患病的概率。
通过Bayes公式可以推到预测值与患病率、灵敏度以及特异度相关的。当灵敏度和特异度确定后,阳性预测值与患病率成正比,阴性预测值与患病率成反比。
第三节、 ROC曲线
ROC(receiver operating characteristic curve),也叫受试者工作特征曲线。基本思想是不固定诊断截断值,将灵敏度和特异度看为一个连续变化的过程,以不同诊断截断值下的诊断试验的灵敏度作为纵坐标,假阳性率作为横坐标,按照连续分组(一般大于5组)测定数据,分别计算灵敏度和特异度,将绘制的各点连接成曲线,即为ROC曲线。
ROC曲线必然经过原点和(1,1),这两个点的连线也叫做机会线。ROC曲线越偏向左上角,即向左上角远离机会线,曲线下的面积越大。
-
AUC(area under curve),ROC曲线下的面积。
ROC曲线主要的作用是评价诊断试验的效能,主要采用AUC及其置信区间来判断诊断试验的准确性。AUC可以说明阳性和阴性结果重叠的程度。
数学解释是:a、所有可能特异度下灵敏度的平均值。b、所有可能灵敏度下特异度的平均值。c、某一诊断试验中,某一特定值对患病的可能性大小。
AUC本质是异常组观察值大于正常组观察值的概率,即 , 为随机抽取一个患者的检验指标的取值,为随机抽取一个非患者的检验指标的取值。
AUC的范围是[0.5,1],一般认为AUC在[0.5,0.7]之间诊断价值较低,[0.5,0.9]之间诊断价值中等,0.9以上认为诊断价值较高。
AUC面积估计有非参数法和参数法两种。非参数法中Hanley-McNeil法是根据诊断试验的结果计算相应截断点的真阳性率及假阳性率,绘制非光滑的ROC,由梯形规则计算AUC。参数法估计采用双正态模型。
AUC应与完全随机情况下获得的面积(AUC=0.5)进行统计学假设检验,可以根据z统计量进行判断,即, z统计量服从标准正态分布,z>1.96时,P<0.05。如有两个AUC进行比较,则, 。
-
举例:
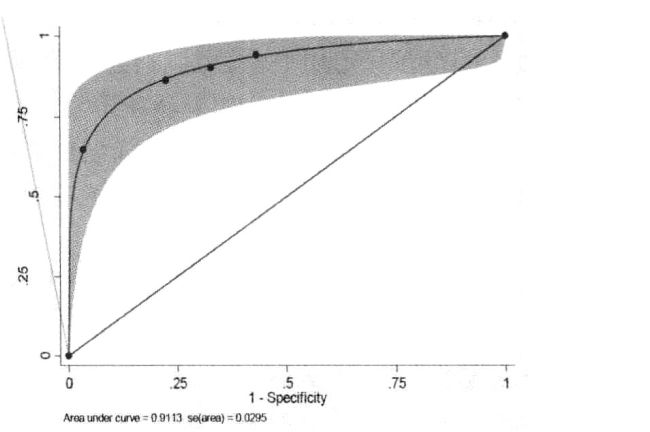 image.png
image.png
第四节、诊断试验的Meta分析统计基础
-
单个指标的合并。
同一诊断试验的多个不同研究最简单的合并方法即为灵敏度,特异度及似然比的加权平均。
仅仅适用于无阈值效应的情况。
灵敏度和特异度的异质性可以采用单个率进行合并,计算Cochran-Q值,按照标准卡方检验进行评价。诊断似然比、DOR可以按照OR值的标准Meta分析方法进行合并。
当存在阈值效应时,灵敏度和特异度之间存在一定相关性,可以通过计算灵敏度和特异度(一般取logit转换)的Spearman相关系数来进行统计检验。
如果存在相关性,也即存在阈值效应时,采用加权平均合并后会低估相应的效应值,此时SROC及其他模型更加合适。
-
举例
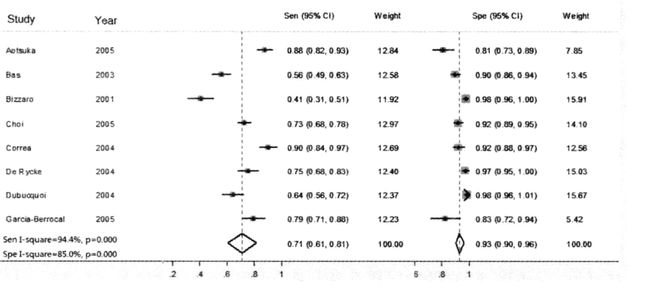 image.png
image.png
-
综合受试者工作特征法(SROC)
-
先构建变量D和S。
D即为诊断优势比的对数值。S被解释为诊断阈值的度量,其越大则提示纳入的标准中有不同的诊断阈值。
SROC回归系数的估计可以有普通最小二乘法,加权最小二乘法和稳健法。
-
SROC曲线的构建以及曲线下的面积(AUC)
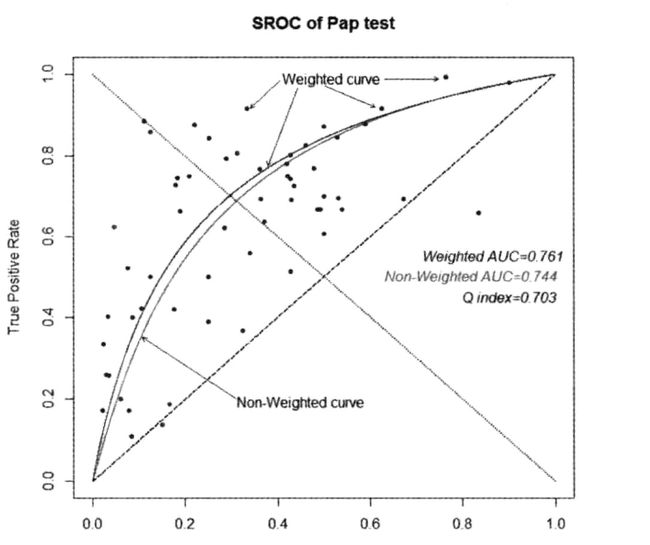 image.png
image.png
-
-
双变量模型及分层综合受试者工作特征曲线
- 分层综合受试者工作特征曲线法(Hierarchical SROC, HSROC),他扩展了logistic回归模型,更加完整地解释了TPR及FPR研究内和研究间的变异。
- 双变量模型:基本原理是将各个研究的灵敏度及特异度经过logit变换后使其符合正态分布,两者有特定的期望及方差。
十一、系统评价/Meta分析相关图形的解读
以下绘制图形的数据源:

[图片上传失败...(image-b62739-1578754779852)]
[图片上传失败...(image-3785ce-1578754779852)]
-
森林图(forest plot)
- 可以使用RevMan绘制
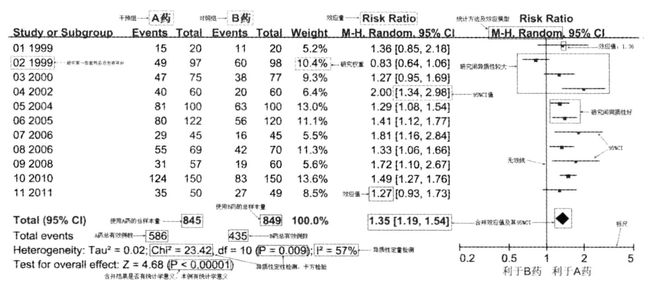 image.png
image.png平行与横轴的每个线段表示被纳入研究的效应量和可信区间,以及Meta分析合并效应量和CI。
用正方形点表示每个研究结果,点的大小是权重。线段长度是CI。
注意图上的说明:从左往右,从上往下依次是干预组,对照组,效应量,统计方法和效应模型,研究第一作者姓名及其年份,研究权重,研究间的异质性较大,95% CI值,研究同质性好,95%CI,无效线,效应值,使用A药的总样本量,使用B药的总样本量,合并效应值及其95%CI,A药的有效例数,B药的有效例数,标尺,异质性检测,卡方检验,异质性定量检测,合并结果是否有统计学意义,本例具有统计学意义,利于B药,利于A药品
-
漏斗图(funnel plot)
 image.png
image.png- Funnel plot是一种定性测量发表偏倚的常用方法。
-
星状图(radial plot)
radial plot可以探索纳入研究的异质性以及每个研究在总体估计中贡献的大小。radial plot是关于标准化效应的值与标准误倒数的散点图。Galbraith图是在radial plot的基础上发展的,因此基于固定效应模型Galbraith与radial plot基本相同。
如果纳入研究对应点集中于一侧,且与原点的回归线的斜率接近,则说明纳入的研究同质性较好。
 image.png
image.png -
拉贝图(L'Abbe plot)
- 常用于随机对照试验的二分类变了数据的Meta分析异质性检验,可以直观地看出干预组事件发生率相对于对照组事件的发生率的关系。
- 他是根据每个研究的干预组事件发生率相对于对照组事件的发生率作图,若研究结果同质,则所有点呈现线性分布;若偏离该线太远,则表面结果存在异常,异常点可以用于敏感性分析。
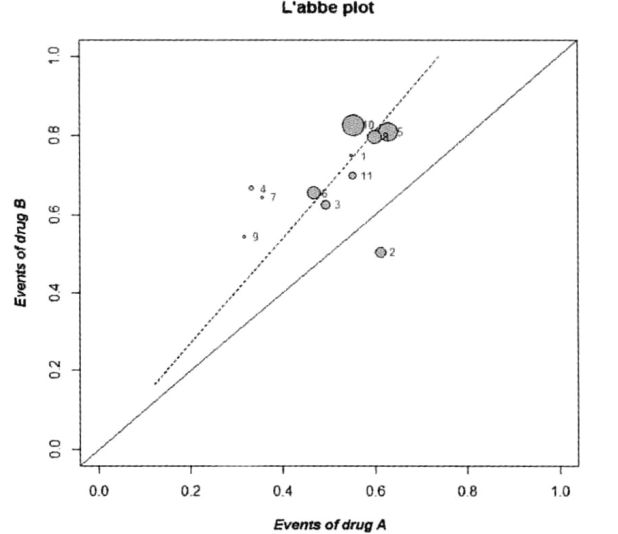 image.png
image.png -
加尔布雷斯图(Galbraith plot)
- Galbraith plot能以点状、编号、作者姓名等标明各研究的具体位置,可以很直观看出异质性来源的异常点。
- 回归线(非加权回归线)穿过原点代表合并效应量,在这条直线的上线两个单位处两条与合并效应量的斜率平行的线是95% CI。
- 如果Meta分析纳入研究间没有明显的异质性,那么所有点会落在CI内部,并且围绕在原点回归线附近。
- 下面图中表示纳入研究的精度都大于3.4,其中研究2有明显异质性。
- 用R画图可以有右侧的logRR尺度。
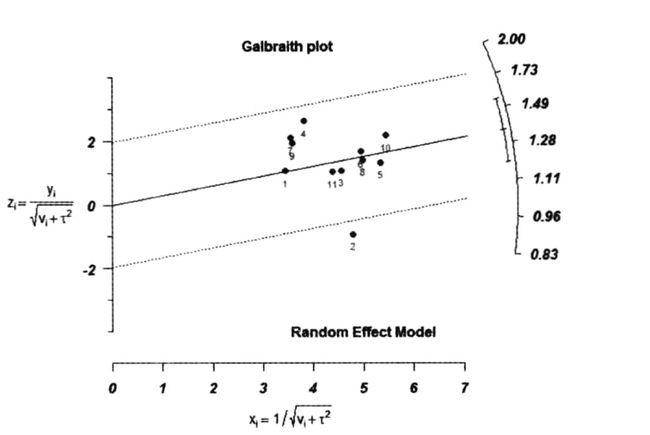 image.png
image.png -
风险偏倚图(risk of bias graph 和risk of bias summary)
- risk of bias graph,是根据偏倚的6个领域多纳入研究产生偏倚风险的项目所占百分比的判断。
- 下图中低风险48%,中风险约27%,高风险约25%
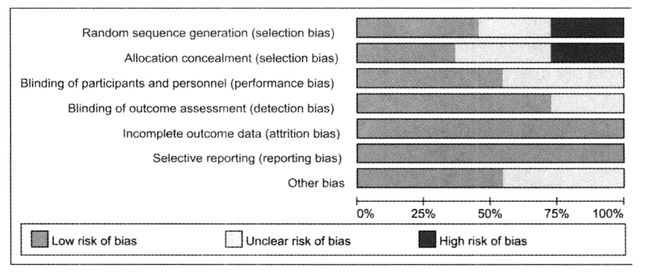 image.png
image.png- risk oof bias summary,反映了作者对纳入研究中每个偏倚风险项目的判断。
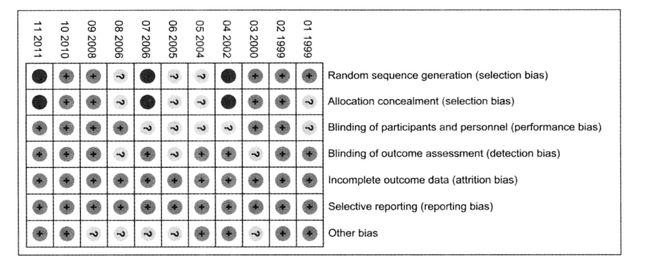 image.png
image.png -
文献筛选流程图
主要直观反映文献筛选的整个过程,RevMan中提供了模板。
举个例子:
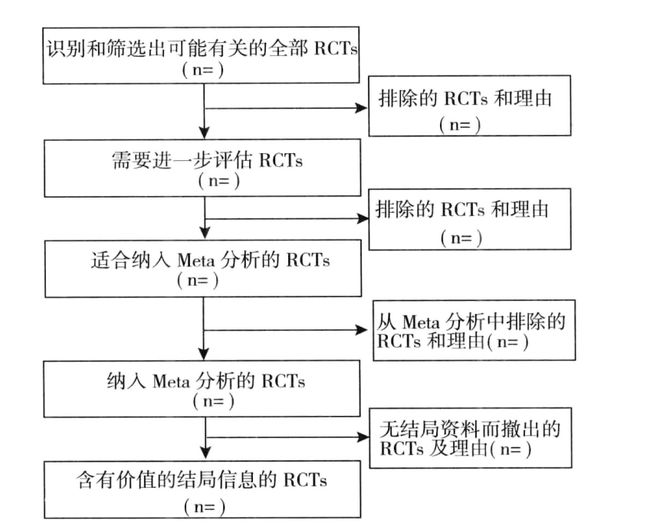 image.png
image.png -
Egger线性回归图
- 他的原理是先计算每个研究的效应值,以及相应的标准误,计算每个研究的方差.以为因变量,标准误为自变量,为权重,进行加权线性回归。
- 理论上,如果样本来自一个无偏倚的总体,则每个纳入研究的散点分布能形成一条过原点的直线。
- Egger法对偏倚的检测统计量为对应的t值和P值,同时通过95%CI是否包含0来判断是否有发表偏倚。
- 如果截距对应的,或者95% CI不包含0,则有发表偏倚。
- 下图中,左侧竖线即为截距对应的CI,由于95 % CI (-2.28,4.04),P=0.543,因此不存在发表偏倚。
 image.png
image.png
-
Begg漏斗图
- 他是检验标准化效应值和方差的关系,实质为漏斗图的倒置.
- 解释与漏斗图一样。
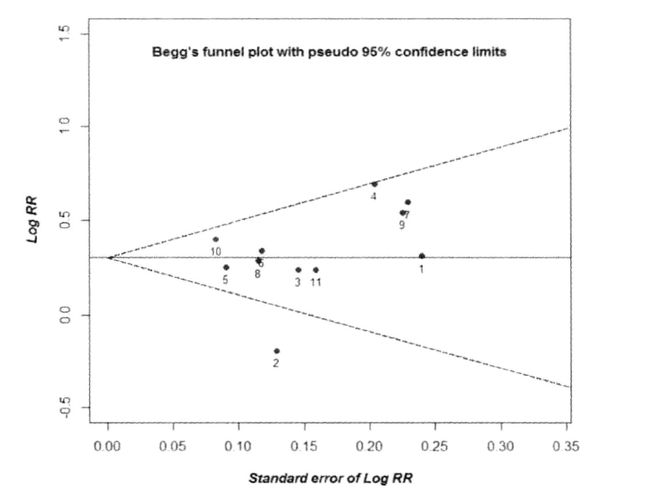 image.png
image.png -
Meta回归图
- 这是通过建立回归方程来反映1个或多个解释变量(explanatory variable)与结果变了(outcomevariable)之间的关系。
 image.png
image.png SROC图

十二、GRADE系统
GRADE(Grades of Recommendations Assessment ,Development and Evaluation),“推荐分级的评价、制定与评估”工作组。 地址:www.gradeworkinggroup.org/society/index.htm。高分SCI一般都建议采用GRADE系统。
-
GRADE系统将证据质量分为高,中,低,极低,4个等级,推荐强度分为”强推荐和弱推荐“。
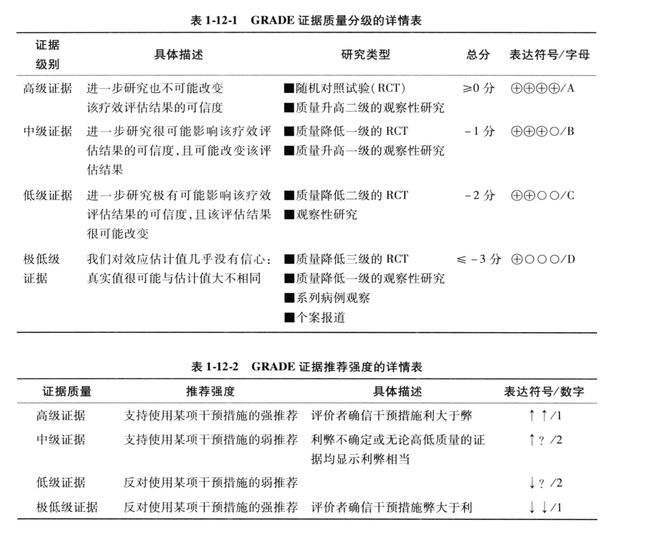 image.png
image.png -
GRADE证据降级和升级因素
 image.png
image.png
十三、系统评价/Meta分析的质量评价工具
- AMSTAR量表
- AMSTAR(A measurement tool for the "assessment of multiple systematic reviews")
- 用于评价方法学质量
- OQAQ量表
- OQAQ(Oxman-Guyatt Overview Quality Assessment Questionnaire)
- 用于评价真实性
- 不涉及发表质量和研究的重要性,主要针对系统评价中容易产生偏倚的几个关键环节。
- CASP清单
- CASP(Critical Appraisal Skills Programme)
- 这是对质量评价的工具
- SQAC量表
- SQAC(Sacks Quality Assessment Checklist)
- 用于评价随机对照试验的Meta分析质量的工具。
- 不被推荐使用
- 报告规范:QUOROM,PRISMA,MOOSE