零售业是一个充分利用数据分析优化商业流程的行业。我们可以利用数据科学对商品的放置、库存管理、定制供应、商品捆绑等任务进行巧妙的处理。该数据集包含了商店的交易数据,是一个回归问题,共包含8523行12列的数据。
问题:
预测销量。
资源:
数据集:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/?spm=a2c4e.11153940.blogcont603256.9.333b1d6fYOsiOK
教程: https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/?spm=a2c4e.11153940.blogcont603256.10.333b1d6fYOsiOK
分析环境:
Python3
jupyter notebook
我们将通过以下阶段探讨这个问题:
- 假设生成 - 通过集思广益可能影响结果的因素来更好地理解问题
- 数据探索 - 查看分类和连续的特征摘要并对数据进行推断。
- 数据清理 - 在数据中输入缺失值并检查异常值
- 特征工程 - 修改现有变量并创建新变量以进行分析
- 模型构建 - 对数据进行预测模型
1. 假设生成
这是分析数据过程中非常关键的一步。这涉及了解问题,并对可能对结果产生良好影响的假设做出一些假设。这是在查看数据之前完成的,我们最终创建了一个不同分析的清单,如果数据可用,我们可能会执行这些分析。
问题陈述
理解问题陈述是首要的步骤:
BigMart的数据科学家已收集了不同城市10家商店的1559种产品的2013年销售数据。此外,还定义了每个产品和商店的某些属性。目的是建立一个预测模型,并找出每个产品在特定商店的销售情况。
使用此模型,BigMart将尝试了解在增加销售方面起关键作用的产品和商店的属性。
因此,我们的想法是找出产品的属性,以及影响产品销售的商店。让我们考虑一下可以做的一些分析并提出某些假设。
假设
在考虑问题的同时,我想出了以下假设。
商店等级假设:
- 城市类型:位于城市或一线城市的商店应该有更高的销售额,因为那里的人们收入水平较高。
- 人口密度:由于需求增加,位于人口稠密地区的商店应该有更高的销售额。
- 商店容量:规模非常大的商店应该有更高的销售额,因为他们就像一站式商店,人们更喜欢从一个地方获得一切
- 竞争对手:附近有类似场所的商店因竞争激烈而销售额较少。
- 营销:拥有良好营销部门的商店应该有更高的销售额,因为它将能够通过正确的优惠和广告吸引客户。
- 位置:位于热门市场内的商店应该有更高的销售额,因为更好地接触客户。
- 客户行为:保持正确产品组合以满足客户本地需求的商店将获得更高的销售额。
- 氛围:由礼貌和谦逊的人维护良好和管理的商店预计会有更高的客流量,从而提高销售额。
产品等级假设:
- 品牌:由于对客户的信任度较高,品牌产品应具有较高的销量。
包装:包装良好的产品可以吸引顾客并销售更多产品。 - 效用:与特定用途产品相比,日用产品应具有更高的销售趋势。
- 展示区域:在商店中提供更大货架的产品可能首先引起注意并且销售更多。
- 商店中的可见性:商店中商品的位置将影响销售。正好在入口处的人将首先吸引客户的眼球,而不是后面的客户。
- 广告:在大多数情况下,在商店中更好的广告宣传销售应该会更高。
- 促销优惠:产品附带有吸引力的优惠和折扣将销售更多。
这些只是我做过的一些基本假设,但你可以进一步思考并创造自己的一些假设。请记住,数据可能不足以测试所有这些,但形成这些数据可以让我们更好地理解问题,我们甚至可以查找开源信息(如果有的话)。
让我们继续进行数据探索,我们将详细了解数据。
2. 数据探索
我们将在这里进行一些基本的数据探索,并对数据做出一些推论。 我们将尝试找出一些异常,并在下一节中解决它们。
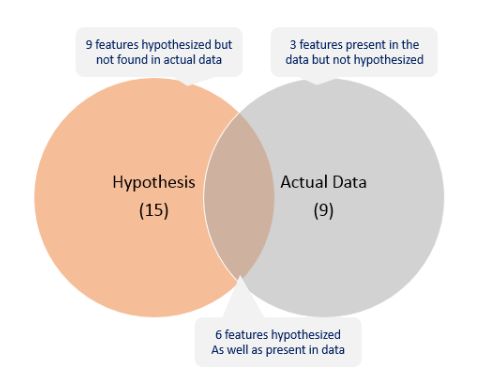
第一步是查看数据并尝试识别我们假设的信息与可用数据。 竞赛页面上的数据字典与输出假设之间的比较如下所示:
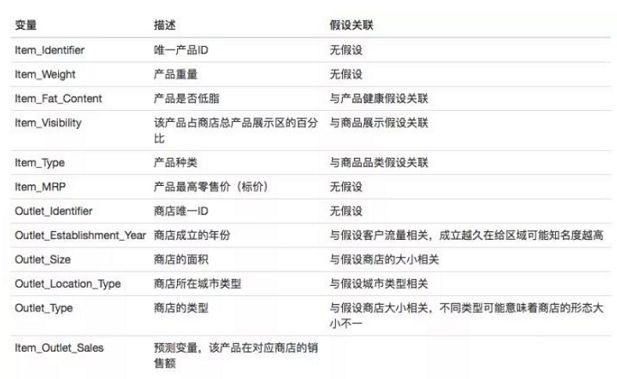
我们可以将调查结果总结如下:
寻找开源的数据尽可能以填补空白,让我们首先加载所需的库和数据。
import numpy as np
import pandas as pd
#加载文件
train = pd.read_csv('sales_train.csv')
test = pd.read_csv('sales_test.csv')
将训练和测试数据集合为一体,执行特征工程,然后再将它们分开,通常是一个好主意。 这节省了在测试和训练中两次执行相同步骤的麻烦。
train['source'] = 'train'
test['source'] = 'test'
data = pd.concat([train, test], ignore_index=True)
print(train.shape, test.shape, data.shape)
结果:(8523, 13) (5681, 12) (14204, 13)
因此,我们可以看到数据具有相同的列,但行相当于test和train之和。 任何数据集中的关键挑战之一是缺失值。 让我们首先检查哪些列包含缺失值。
# data.apply(lambda x: sum(x.isnull()))
data.isnull().sum()
结果:
Item_Fat_Content 0
Item_Identifier 0
Item_MRP 0
Item_Outlet_Sales 5681
Item_Type 0
Item_Visibility 0
Item_Weight 2439
Outlet_Establishment_Year 0
Outlet_Identifier 0
Outlet_Location_Type 0
Outlet_Size 4016
Outlet_Type 0
source 0
dtype: int64
请注意,Item_Outlet_Sales是目标变量,缺失值是测试集中的值。 所以我们不用担心。 但是我们将在数据清理部分中将Item_Weight和Outlet_Size中的缺失值归为一类。
让我们看一下数值变量的一些基本统计数据。
data.describe()

一些观察:
- Item_Visibility的最小值为零。 这没有实际意义,因为当在商店中销售产品时不能为0。
- Outlet_Establishment_Years从1985年到2009年各不相同。这种形式的值可能不合适。 相反,如果我们可以将它们转换为特定商店的年龄,它应该对销售产生更好的影响。
- 可用Item_Weight和Item_Outlet_Sales的差数确认缺失值检查的结果。
让我们看看每个变量中唯一值的数量。
data.apply(lambda x: len(x.unique()))
结果:
Item_Fat_Content 5
Item_Identifier 1559
Item_MRP 8052
Item_Outlet_Sales 3494
Item_Type 16
Item_Visibility 13006
Item_Weight 416
Outlet_Establishment_Year 9
Outlet_Identifier 10
Outlet_Location_Type 3
Outlet_Size 4
Outlet_Type 4
source 2
dtype: int64
这告诉我们有1559种产品和10个网点/商店(问题陈述中也提到过)。 值得注意的另一件事是Item_Type有16个唯一值。 让我们进一步探讨每个名义变量中不同类别的频率。 出于显而易见的原因,我将排除ID和源变量。
#Filter categorical variables
categorical_columns = [x for x in data.dtypes.index if data.dtypes[x]=='object']
#Exclude ID cols and source:
categorical_columns = [x for x in categorical_columns if x not in ['Item_Identifier','Outlet_Identifier','source']]
#Print frequency of categories
for col in categorical_columns:
print('\nFrequency of Categories for varible %s'%col)
print(data[col].value_counts())
结果:
Frequency of Categories for varible Item_Fat_Content
Low Fat 8485
Regular 4824
LF 522
reg 195
low fat 178
Name: Item_Fat_Content, dtype: int64
Frequency of Categories for varible Item_Type
Fruits and Vegetables 2013
Snack Foods 1989
Household 1548
Frozen Foods 1426
Dairy 1136
Baking Goods 1086
Canned 1084
Health and Hygiene 858
Meat 736
Soft Drinks 726
Breads 416
Hard Drinks 362
Others 280
Starchy Foods 269
Breakfast 186
Seafood 89
Name: Item_Type, dtype: int64
Frequency of Categories for varible Outlet_Location_Type
Tier 3 5583
Tier 2 4641
Tier 1 3980
Name: Outlet_Location_Type, dtype: int64
Frequency of Categories for varible Outlet_Size
Medium 4655
Small 3980
High 1553
Name: Outlet_Size, dtype: int64
Frequency of Categories for varible Outlet_Type
Supermarket Type1 9294
Grocery Store 1805
Supermarket Type3 1559
Supermarket Type2 1546
Name: Outlet_Type, dtype: int64
输出给出了以下观察结果:
- Item_Fat_Content:一些'Low Fat'值错误编码为'low fat'和'LF'。 此外,一些“Regular”被称为“regular”。
- Item_Type:并非所有类别都有实质性的数字。 结合它们看起来可以提供更好的结果。
- Outlet_Type:可以组合超市Type2和Type3。 但是我们应该在做之前检查一下这是不是一个好主意。
3. 数据清理
此步骤通常涉及估算缺失值和处理异常值。 虽然异常值去除在回归技术中非常重要,但是基于树的高级算法不受异常值的影响。 所以我会留给你试试看。 我们将重点关注这里的插补步骤,这是非常重要的一步。(这里重点处理缺失值)
输入缺失值
我们发现了两个缺少值的变量 - Item_Weight和Outlet_Size。让我们用特定物品的平均重量来估算Item_Weight。
# 确定每件商品的平均重量:
item_avg_weight = data.pivot_table(values='Item_Weight', index='Item_Identifier')
# 获取指定缺少Item_Weight值的布尔变量
miss_bool = data['Item_Weight'].isnull()
#插补前后的缺失值确认
print('Orignal #missing: %d'% sum(miss_bool))
data.loc[miss_bool,'Item_Weight'] = data.loc[miss_bool,'Item_Identifier'].apply(lambda x: item_avg_weight.loc[x])
print('Final #missing: %d'% sum(data['Item_Weight'].isnull()))
结果:
Orignal #missing: 2439
Final #missing: 0
确认这列没有缺失值,让我们将Outlet_Size与特定类型插座的Outlet_Size模式联系起来。
from scipy.stats import mode
#Determing the mode for each
outlet_size_mode = data.pivot_table(values='Outlet_Size', index='Outlet_Type',aggfunc=(lambda x:mode(x.astype(str)).mode[0]) )
print('Mode for each Outlet_Type:')
print(outlet_size_mode)
#Get a boolean variable specifying missing Item_Weight values
miss_bool = data['Outlet_Size'].isnull()
#Impute data and check #missing values before and after imputation to confirm
print('\nOrignal #missing: %d'% sum(miss_bool))
data.loc[miss_bool,'Outlet_Size'] = data.loc[miss_bool,'Outlet_Type'].apply(lambda x: outlet_size_mode.loc[x])
print(sum(data['Outlet_Size'].isnull()))
结果:
Mode for each Outlet_Type:
Outlet_Size
Outlet_Type
Grocery Store nan
Supermarket Type1 Small
Supermarket Type2 Medium
Supermarket Type3 Medium
Orignal #missing: 4016
0
这确认了数据中没有缺失值。 让我们继续进行特征工程。
4.特征工程
我们在数据探索部分探讨了数据的一些细微差别。 让我们继续解决它们并使我们的数据准备好进行分析。 我们还将使用本节中的现有变量创建一些新变量。
第1步:考虑组合Outlet_Type
在分析期间,我们决定考虑结合超市Type2和Type3变量。 但这是个好主意吗?
data.pivot_table(values='Item_Outlet_Sales',index='Outlet_Type')

这显示了它们之间的显着差异,我们将保留原样。
第2步:修改Item_Visibility
我们注意到这里的最小值是0,这没有实际意义。 让我们将其视为缺少信息,并将其与该产品的平均可见性代替。
#Determine average visibility of a product
visibility_avg = data.pivot_table(values='Item_Visibility', index='Item_Identifier')
#Impute 0 values with mean visibility of that product:
miss_bool = (data['Item_Visibility'] == 0)
print('Number of 0 values initially: %d'%sum(miss_bool))
data.loc[miss_bool,'Item_Visibility'] = data.loc[miss_bool,'Item_Identifier'].apply(lambda x: visibility_avg.loc[x])
print('Number of 0 values after modification: %d'%sum(data['Item_Visibility'] == 0))
结果:
Number of 0 values initially: 879
Number of 0 values after modification: 0
看到已经没有了零值。
在第1步中,我们假设具有较高visibility的产品可能销售更多。 但是,除了按绝对值比较产品外,我们还应该考察该特定商店中产品的可见性,以及所有商店中该产品的平均可见度。 这将给出一些关于与其他商店相比在商店中对该产品的重视程度的一些想法。 我们可以使用上面提到的'visibility_avg'变量来实现这一点。
#Determine another variable with means ratio
data['Item_Visibility_MeanRatio'] = data.apply(lambda x: x['Item_Visibility']/visibility_avg.loc[x['Item_Identifier']], axis=1)
print(data['Item_Visibility_MeanRatio'].describe())
结果:
count 14204.000000
mean 1.061884
std 0.235907
min 0.844563
25% 0.925131
50% 0.999070
75% 1.042007
max 3.010094
Name: Item_Visibility_MeanRatio, dtype: float64
因此,已成功创建新变量。同样,这只是如何创建新功能的一个示例。我强烈建议您尝试更多这些,因为良好的功能可以大大提高模型性能,并且它们总是被证明是最佳模型和平均模型之间的差异。
第3步:创建一个广泛的项目类型
之前我们看到Item_Type变量有16个类别,可能证明在分析中非常有用。 所以将它们结合起来是一个好主意。 一种方法是手动为每个分配一个新类别。 但这里有一个问题。 如果您查看Item_Identifier,即每个项目的唯一ID,它将以FD,DR或NC开头。 如果你看到类别,这些看起来像食物,饮料和非消耗品。 所以我使用了Item_Identifier变量来创建一个新列:
#Get the first two characters of ID:
data['Item_Type_Combined'] = data['Item_Identifier'].apply(lambda x: x[0:2])
#Rename them to more intuitive categories:
data['Item_Type_Combined'] = data['Item_Type_Combined'].map({'FD':'Food',
'NC':'Non-Consumable',
'DR':'Drinks'})
data['Item_Type_Combined'].value_counts()
结果:
Food 10201
Non-Consumable 2686
Drinks 1317
Name: Item_Type_Combined, dtype: int64
另一个想法可能是根据销售情况组合类别。 平均销售额高的人可以合并在一起。可以试试。
第4步:确定商店的运营年限
制作一个新列,描述商店的运营年限:(此为学习,以教程贴时间为准)
#Years:
data['Outlet_Years'] = 2013 - data['Outlet_Establishment_Year']
data['Outlet_Years'].describe()
结果:
count 14204.000000
mean 15.169319
std 8.371664
min 4.000000
25% 9.000000
50% 14.000000
75% 26.000000
max 28.000000
Name: Outlet_Years, dtype: float64
这表明商店运营年限为4-28年。
第5步:修改Item_Fat_Content的类别
我们在Item_Fat_Content变量的类别中发现了拼写错误和表示差异。 这可以更正为:
#Change categories of low fat:
print( 'Original Categories:')
print(data['Item_Fat_Content'].value_counts())
print('\nModified Categories:')
data['Item_Fat_Content'] = data['Item_Fat_Content'].replace({'LF':'Low Fat',
'reg':'Regular',
'low fat':'Low Fat'})
print(data['Item_Fat_Content'].value_counts())
结果:
Original Categories:
Low Fat 8485
Regular 4824
LF 522
reg 195
low fat 178
Name: Item_Fat_Content, dtype: int64
Modified Categories:
Low Fat 9185
Regular 5019
Name: Item_Fat_Content, dtype: int64
在第3步中,我们看到有一些非消耗品,不应该为它们指定脂肪含量。 因此,我们还可以为此类观察创建单独的类别。
#Mark non-consumables as separate category in low_fat:
data.loc[data['Item_Type_Combined']=="Non-Consumable",'Item_Fat_Content'] = "Non-Edible"
data['Item_Fat_Content'].value_counts()
结果:
Low Fat 6499
Regular 5019
Non-Edible 2686
Name: Item_Fat_Content, dtype: int64
第6步:分类变量的数值和单热编码
由于scikit-learn只接受数值变量,因此我将所有类别的名义变量转换为数字类型。 另外,我也希望Outlet_Identifier作为变量。 所以我创建了一个与Outlet_Identifier相同的新变量'Outlet'并对其进行了编码。 Outlet_Identifier应保持原样,因为它在提交文件中是必需的。
让我们首先使用sklearn的预处理模块中的'LabelEncoder'将所有分类变量编码为数字。
#Import library:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
#New variable for outlet
data['Outlet'] = le.fit_transform(data['Outlet_Identifier'])
var_mod = ['Item_Fat_Content','Outlet_Location_Type','Outlet_Size','Item_Type_Combined','Outlet_Type','Outlet']
le = LabelEncoder()
for i in var_mod:
data[i] = le.fit_transform(data[i])
One-Hot-Coding是指创建虚拟变量,每个类别对应一个分类变量。 例如,Item_Fat_Content有3个类别 - “低脂肪”,“常规”和“不可食用”。 一个热编码将删除此变量并生成3个新变量。 每个都有二进制数 - 0(如果类别不存在)和1(如果存在类别)。 这可以使用Pandas的'get_dummies'功能来完成。
#One Hot Coding:
data = pd.get_dummies(data, columns=['Item_Fat_Content','Outlet_Location_Type','Outlet_Size','Outlet_Type',
'Item_Type_Combined','Outlet'])
让我们现在看一下列的数据类型:
data.dtypes
结果:
Item_Identifier object
Item_MRP float64
Item_Outlet_Sales float64
Item_Type object
Item_Visibility float64
Item_Weight float64
Outlet_Establishment_Year int64
Outlet_Identifier object
source object
Item_Visibility_MeanRatio float64
Outlet_Years int64
Item_Fat_Content_0 uint8
Item_Fat_Content_1 uint8
Item_Fat_Content_2 uint8
Outlet_Location_Type_0 uint8
Outlet_Location_Type_1 uint8
Outlet_Location_Type_2 uint8
Outlet_Size_0 uint8
Outlet_Size_1 uint8
Outlet_Size_2 uint8
Outlet_Size_3 uint8
Outlet_Type_0 uint8
Outlet_Type_1 uint8
Outlet_Type_2 uint8
Outlet_Type_3 uint8
Item_Type_Combined_0 uint8
Item_Type_Combined_1 uint8
Item_Type_Combined_2 uint8
Outlet_0 uint8
Outlet_1 uint8
Outlet_2 uint8
Outlet_3 uint8
Outlet_4 uint8
Outlet_5 uint8
Outlet_6 uint8
Outlet_7 uint8
Outlet_8 uint8
Outlet_9 uint8
dtype: object
在这里我们可以看到所有变量现在都是uint8类型,每个类别都有一个新变量。让我们看一下由Item_Fat_Content组成的3列。
data[['Item_Fat_Content_0','Item_Fat_Content_1','Item_Fat_Content_2']].head(10)

可以注意到,每行只有一列与原始变量中的类别相对应。
第7步:导出数据
最后一步是将数据转换回训练和测试数据集。 将这两者作为修改后的数据集导出通常是个好主意,这样它们就可以重复用于多个会话。
#Drop the columns which have been converted to different types:
data.drop(['Item_Type','Outlet_Establishment_Year'],axis=1,inplace=True)
#Divide into test and train:
train = data.loc[data['source']=="train"]
test = data.loc[data['source']=="test"]
#Drop unnecessary columns:
test.drop(['Item_Outlet_Sales','source'],axis=1,inplace=True)
train.drop(['source'],axis=1,inplace=True)
#Export files as modified versions:
train.to_csv("train_modified.csv",index=False)
test.to_csv("test_modified.csv",index=False)
有了这个,我们来到本节的最后。
5.模型构建
现在我们已准备好数据,是时候开始制作预测模型了。 我将带你通过6个模型,包括线性回归,决策树和随机森林。
让我们从制作基线模型开始。 基线模型是不需要预测模型的模型,它就像一个明智的猜测。 例如,在这种情况下,我们可以将销售额预测为总体平均销售额。
#Mean based:
mean_sales = train['Item_Outlet_Sales'].mean()
#Define a dataframe with IDs for submission:
base1 = test[['Item_Identifier','Outlet_Identifier']]
base1['Item_Outlet_Sales'] = mean_sales
#Export submission file
base1.to_csv("alg0.csv",index=False)
采取整体意味着最简单的方法。你也可以尝试:
- 按产品平均销售额
- 特定商店类型的产品平均销售额
- 这些应提供更好的基线解决方案
由于我将制作许多模型,而不是一次又一次地重复代码,我想定义一个通用函数,它将算法和数据作为输入并生成模型,执行交叉验证并生成提交
#Define target and ID columns:
target = 'Item_Outlet_Sales'
IDcol = ['Item_Identifier','Outlet_Identifier']
from sklearn import cross_validation, metrics
def modelfit(alg, dtrain, dtest, predictors, target, IDcol, filename):
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain[target])
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
#Perform cross-validation:
cv_score = cross_validation.cross_val_score(alg, dtrain[predictors], dtrain[target], cv=20, scoring='mean_squared_error')
cv_score = np.sqrt(np.abs(cv_score))
#Print model report:
print ("\nModel Report")
print ("RMSE : %.4g" % np.sqrt(metrics.mean_squared_error(dtrain[target].values, dtrain_predictions)))
print ("CV Score : Mean - %.4g | Std - %.4g | Min - %.4g | Max - %.4g" % (np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
#Predict on testing data:
dtest[target] = alg.predict(dtest[predictors])
#Export submission file:
IDcol.append(target)
submission = pd.DataFrame({ x: dtest[x] for x in IDcol})
submission.to_csv(filename, index=False)
线性回归模型
from sklearn.linear_model import LinearRegression, Ridge, Lasso
predictors = [x for x in train.columns if x not in [target]+IDcol]
# print predictors
alg1 = LinearRegression(normalize=True)
modelfit(alg1, train, test, predictors, target, IDcol, 'alg1.csv')
coef1 = pd.Series(alg1.coef_, predictors).sort_values()
coef1.plot(kind='bar', title='Model Coefficients')
结果:
Model Report
RMSE : 1128
CV Score : Mean - 1129 | Std - 43.62 | Min - 1075 | Max - 1212

我们可以看到这比基线模型更好。 但是如果你注意到系数,它们的幅度非常大,这意味着过度拟合。 为了迎合这一点,我们使用岭回归模型。
岭回归模型:
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg2 = Ridge(alpha=0.05,normalize=True)
modelfit(alg2, train, test, predictors, target, IDcol, 'alg2.csv')
coef2 = pd.Series(alg2.coef_, predictors).sort_values()
coef2.plot(kind='bar', title='Model Coefficients')
结果:
Model Report
RMSE : 1129
CV Score : Mean - 1130 | Std - 44.58 | Min - 1076 | Max - 1217
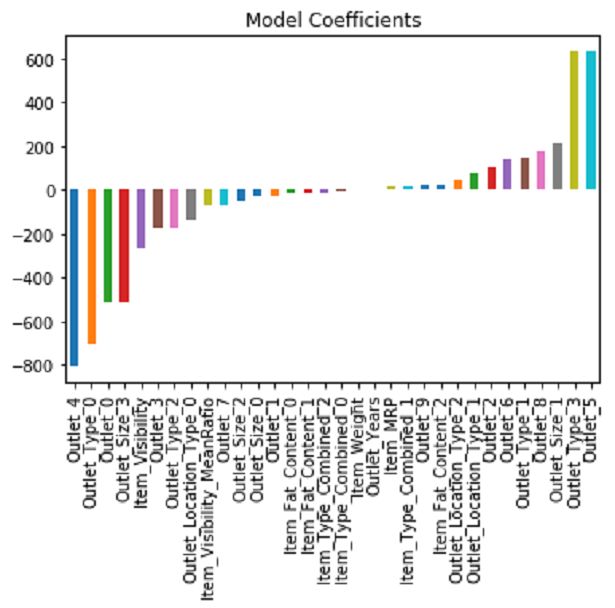
虽然回归系数现在看起来更好,但得分大致相同。 您可以调整模型的参数以获得更好的结果,但我认为不会有显着的改进。 即使交叉验证得分相同,我们也不能指望更好的表现。
决策树模型
from sklearn.tree import DecisionTreeRegressor
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg3 = DecisionTreeRegressor(max_depth=15, min_samples_leaf=100)
modelfit(alg3, train, test, predictors, target, IDcol, 'alg3.csv')
coef3 = pd.Series(alg3.feature_importances_, predictors).sort_values(ascending=False)
coef3.plot(kind='bar', title='Feature Importances')
结果:
Model Report
RMSE : 1058
CV Score : Mean - 1091 | Std - 45.42 | Min - 1003 | Max - 1186

在这里你可以看到RMSE是1058,平均CV误差是1091.这告诉我们模型略微过度拟合。 让我们尝试使用前4个变量制作决策树,max_depth为8,min_samples_leaf为150。
predictors = ['Item_MRP','Outlet_Type_0','Outlet_5','Outlet_Years']
alg4 = DecisionTreeRegressor(max_depth=8, min_samples_leaf=150)
modelfit(alg4, train, test, predictors, target, IDcol, 'alg4.csv')
coef4 = pd.Series(alg4.feature_importances_, predictors).sort_values(ascending=False)
coef4.plot(kind='bar', title='Feature Importances')
结果:
Model Report
RMSE : 1071
CV Score : Mean - 1096 | Std - 43.3 | Min - 1027 | Max - 1172

您可以使用其他参数进一步微调模型。
随机森林模型
让我们尝试一个随机的森林模型,看看我们是否得到了一些改进。
from sklearn.ensemble import RandomForestRegressor
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg5 = RandomForestRegressor(n_estimators=200,max_depth=5, min_samples_leaf=100,n_jobs=4)
modelfit(alg5, train, test, predictors, target, IDcol, 'alg5.csv')
coef5 = pd.Series(alg5.feature_importances_, predictors).sort_values(ascending=False)
coef5.plot(kind='bar', title='Feature Importances')
结果:
Model Report
RMSE : 1073
CV Score : Mean - 1083 | Std - 43.86 | Min - 1021 | Max - 1162

您可能会觉得这是一个非常小的改进,但随着我们的模型变得更好,实现甚至微小的改进变得成倍地难以实现。 让我们尝试另一个随机森林,其中max_depth为6和400棵树。 增加树的数量使得模型稳健,但计算量很大。
predictors = [x for x in train.columns if x not in [target]+IDcol]
alg6 = RandomForestRegressor(n_estimators=400,max_depth=6, min_samples_leaf=100,n_jobs=4)
modelfit(alg6, train, test, predictors, target, IDcol, 'alg6.csv')
coef6 = pd.Series(alg6.feature_importances_, predictors).sort_values(ascending=False)
coef6.plot(kind='bar', title='Feature Importances')
结果:
Model Report
RMSE : 1068
CV Score : Mean - 1083 | Std - 43.77 | Min - 1019 | Max - 1161

同样,这是一个渐进的变化,应该尝试进一步调整参数以获得更高的准确性。也可以用GBM和XGBoost等更好的算法来得到更好的效果。
有了这个,我们来到本节的最后。
结束笔记
本文带我们完成了解决数据科学问题的整个过程。我们开始在不查看数据的情况下对数据做出一些假设。然后我们继续进行数据探索,在那里我们发现了需要修复的数据中的一些细微差别。接下来,我们进行了数据清理和特征工程,其中我们估算了缺失值并解决了其他不规则性,创建了新功能,并通过单热编码使数据模型友好。最后,我们制作了回归,决策树和随机森林模型,并对如何调整它们以获得更好的结果进行了一瞥。
文章最后留下了一些问题:你觉得这篇文章有用吗?你能提出一些更有趣的假设吗?您创建了哪些其他功能?你能用GBM和XGBoost获得更好的分数吗?