outline
- 一.HDFS相关
- 二.mapreduce相关
- 三.Hadoop的调度策略
- 四.Hadoop的安全机制
一.HDFS相关
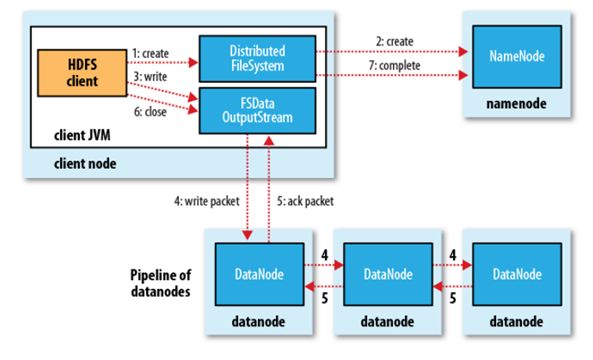
(1)HDFS的文件读写过程
read
(1)客户端调用FileSyste对象的open()方法在分布式文件系统中打开要读取的文件。
(2)分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置。
(3)分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法。
(4)DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端。
(5) 到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode。

write
(1) 客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
(2) 分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件。
(3)Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信,客户端开始写入数据。
(4)FSDataOutputStream将数据分成一个一个的数据包,写入内部队列“数据队列”,DataStreamer负责将数据包依次流式传输到由一组namenode构成的管线中。
(5)DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除。
(6)客户端完成数据的写入,对数据流调用close()方法。
(7)namenode确认完成。
(2)HDFS如何保证一致性
HDFS在写数据务必要保证数据的一致性与持久性,目前HDFS提供的两种两个保证数据一致性的方法 hsync()方法和hflush()方法。
hflush: 保证flush的数据被新的reader读到,但是不保证数据被datanode持久化。
hsync: 与hflush几乎一样,不同的是hsync保证数据被datanode持久化
(3)副本存储机器的选择
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
二.mapreduce相关
(1)mapreduce的shuffle
Mapreduce的过程整体上分为5个阶段:InputFormat--MapTask --shuffle--ReduceTask--OutPutFormat
作用:
完整地从map task端拉取数据到reduce 端。
在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
减少磁盘IO对task执行的影响。
map端
map的输出写缓存
写磁盘(溢写)会进行排序(先根据分区号,然后根据key排序)+ Combiner(合并)
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做Merge(归并);

Combiner---函数(相当于map阶段的reduce):适用于输入key/value和输出key/value类型完全一致
是用于本地合并数据的函数
reduce端:
reduce会对应一个分区(Partition),即,不同的reduce处理不同分区的数据
分区即是把能被同一个reduce操作的数据放在一起,
排序即是在各个分区中将数据按照key进行排序
reduce端:
当MapTask完成任务数超过总数的5%后,开始调度执行ReduceTask任务,然后ReduceTask默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。
这些拷贝的数据会首先保存到内存缓冲区中,当达到一定的阀值的时候,开始启动内存到磁盘的Merge,也就是溢写过程,一致运行直到map端没有数据生成,最后启动磁盘到磁盘的Merge方式生成最终的那个文件。在溢写过程中,然后锁定80M的数据,然后在延续Sort过程,然后记性group(分组)将相同的key放到一个集合中,然后在进行Merge
当Reducer的输入文件已定,整个Shuffle才最终结束。
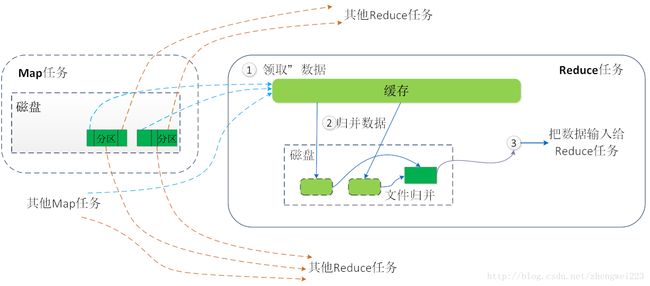
shuffle总结
MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。
(2)mapreduce的优化方法
maptask得并行度决定机制
一个 job 的 map 阶段并行度由客户端在提交 job 时决定, 客户端对 map 阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多 个 split),然后每一个 split 分配一个 mapTask 并行实例处理
这段逻辑及形成的切片规划描述文件,是由 FileInputFormat实现类的 getSplits()方法完成的。
该方法返回的是 List
(3)数据倾斜的处理方式
1.增加reduce 的jvm内存
2.Combiner
3.复合键:在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。
如下图--把小的键值对合并成大的键值对:

(4)Partition 分区
默认分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据
Partitioner决定了Map节点输出将被分区到拿个Reduce节点
(5)MR的join操作
map端join
使用hadoop中的DistributedCache(分布式缓存)把小数据分布到各个计算节点,每个map节点都要把小数据库加载到内存,按关键字建立索引。
reduce端join
1, map阶段没有对数据瘦身,shuffle的网络传输和排序性能很低。
2, reduce端对2个集合做乘积计算,很耗内存,容易导致OOM。
优化
- 使用mapreduce专为join设计的包
jar: mapreduce-client-core.jar
package: org.apache.hadoop.mapreduce.lib.join - Hive有对join进行优化
三.Hadoop的调度策略
hadoop的调度策略的实现
Hadoop在standalone模式下只有FIFO Scheduler 和 Fair Scheduler;
Hadoop-yarn模式下有FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler策略
Capacity Scheduler
以队列为单位划分资源,每个队列设定一定比例的最低保证和使用上限;
Capacity Scheduler为每个人分配一个队列,每个队列占用的集群资源可以是相同的也可以是不同的,队列内部还是采用FIFO调度的策略。
Fair Scheduler
Fair Scheduler中有一个基于任务数量的负载均衡机制,该机制尽可能将系统中的任务分配到各个节点
四.Hadoop的安全机制
如何实现hadoop的安全机制
kerberos
参考资料
HDFS知识点总结
mapreduce并行度调优
MapReduce实现的Join
YARN中FIFO、Capacity以及Fari调度器的详细介绍