集群版服务器启动
启动类是org.apache.zookeeper.server.quorum.QuorumPeerMain,启动参数就是配置文件的地址
配置文件说明
tickTime=4000
initLimit=10
syncLimit=5
dataDir=D:\\zk-test\\datadir\\server1
clientPort=2181
maxClientCnxns=60
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883
tickTime值,单位ms,默认3000
- 用途1:用于指定session检查的间隔,服务器会每隔一段时间检查一次连接它的客户端的session是否过期。该间隔就是tickTime。
- 用途2:用于给出默认的minSessionTimeout和maxSessionTimeout,如果没有给出maxSessionTimeout和minSessionTimeout(为-1),则minSessionTimeout和maxSessionTimeout的取值分别是tickTime的2倍和20倍。如下:
minSessionTimeout == -1 ? tickTime * 2 : minSessionTimeout;
maxSessionTimeout == -1 ? tickTime * 20 : maxSessionTimeout;
- 用途3:作为initLimit和syncLimit时间的基数
initLimit:在初始化阶段和Leader的通信的读取超时时间,即当调用socket的InputStream的read方法时最大阻塞时间不能超过initLimit*tickTime。设置如下:
@Override
public void run() {
try {
while (!stop) {
try{
Socket s = ss.accept();
// start with the initLimit, once the ack is processed
// in LearnerHandler switch to the syncLimit
s.setSoTimeout(self.tickTime * self.initLimit); // read最大阻塞时间
s.setTcpNoDelay(nodelay);
BufferedInputStream is = new BufferedInputStream(
s.getInputStream());
initLimit还会作为初始化阶段收集相关响应的总时间,一旦超过该时间,还没有过半的机器进行响应,则抛出InterruptedException的timeout异常
syncLimit:在初始化阶段之后的请求阶段和Leader通信的读取超时时间,即对Leader的一次请求到响应的总时间不能超过syncLimit*tickTime时间。Follower和Leader之间的socket的超时时间初始化阶段是前者,当初始化完毕又设置到后者时间上。设置如下:
syncLimitCheck.start();
// now that the ack has been processed expect the syncLimit
sock.setSoTimeout(leader.self.tickTime * leader.self.syncLimit);
syncLimit还会作为与Leader的连接超时时间,如下:
protected void connectToLeader(InetSocketAddress addr, String hostname)
throws IOException, ConnectException, InterruptedException {
sock = new Socket();
sock.setSoTimeout(self.tickTime * self.initLimit);
for (int tries = 0; tries < 5; tries++) {
try {
sock.connect(addr, self.tickTime * self.syncLimit);
sock.setTcpNoDelay(nodelay);
break;
} catch (IOException e) {}
- dataDir:用于存储数据快照的目录
- dataLogDir:用于存储事务日志的目录,如果没有指定,则和dataDir保持一致
- clientPort:对客户端暴漏的连接端口
- maxClientCnxns值,用于指定服务器端最大的连接数。
- 集群的server配置,一种格式为server.A=B:C:D,还有其他格式,具体可以去看QuorumPeerConfig源码解析这一块
A:即为集群中server的id标示,很多地方用到它,如选举过程中,就是通过id来识别是哪台服务器的投票。如初始化sessionId的时候,也用到id来防止sessionId出现重复。
B:即该服务器的host地址或者ip地址。
C:一旦Leader选举成功后,非Leader服务器都要和Leader服务器建立tcp连接进行通信。该通信端口即为C
D:在Leader选举阶段,每个服务器之间相互连接(上述serverId大的会主动连接serverId小的server),进行投票选举的事宜,D即为投票选举时的通信端口
上述配置是每台服务器都要知道的集群配置,同时要求在dataDir目录中创建一个myid文件,里面写上上述serverid中的一个id值,即表明某台服务器所属的编号
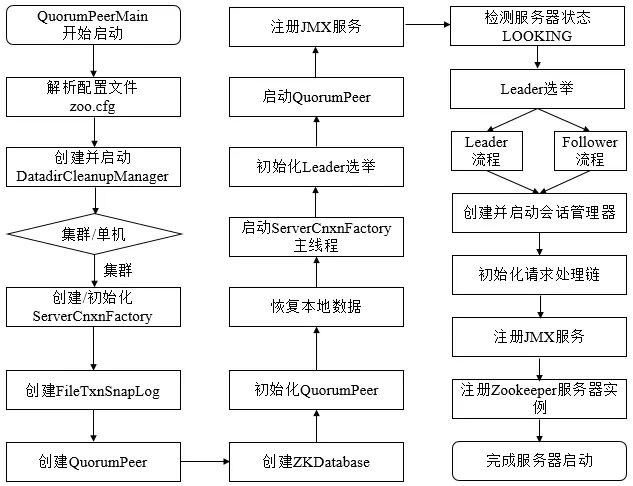
启动过程主要分为:
- 预启动
- 初始化
- Leader选举
- Leader和Follower启动期交互过程
- Leader和Follower启动
预启动
- 统一由QuorumPeerMain作为启动类
- 解析配置文件zoo.cfg
- 创建并启动历史文件清理器DatadirCleanupFactory
- 判断当前是集群模式还是单机模式的启动, 在集群模式中,在zoo.cfg文件中配置了多个服务器地址,可以选择集群启动。
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]); // 配置文件解析
}
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start(); // 启动后台清理日志线程
if (args.length == 1 && config.servers.size() > 0) { // 集群版
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
初始化
- 创建ServerCnxnFactory。
- 初始化ServerCnxnFactory。
- 创建Zookeeper数据管理器FileTxnSnapLog。
- 创建QuorumPeer实例。
Quorum是集群模式下特有的对象,是Zookeeper服务器实例(ZooKeeperServer)的托管者,QuorumPeer代表了集群中的一台机器
在运行期间,QuorumPeer会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举。 - 创建内存数据库ZKDatabase。
ZKDatabase负责管理ZooKeeper的所有会话记录以及DataTree和事务日志的存储。 - 初始化QuorumPeer。
将核心组件如FileTxnSnapLog、ServerCnxnFactory、ZKDatabase注册到QuorumPeer中,同时配置QuorumPeer的参数,如服务器列表地址、Leader选举算法和会话超时时间限制等。 - 恢复本地数据。
- 启动ServerCnxnFactory主线程。
单机版的服务器启动,就是创建了一个ZooKeeperServer对象。

可见Leader服务器要使用LeaderZooKeeperServer,Follower服务器要使用FollowerZooKeeperServer。而集群版服务器启动后,可能是Leader或者Follower。在运行过程中角色还会进行自动更换,即自动更换使用不同的ZooKeeperServer子类。此时就需要一个代理对象,用于角色的更换、所使用的ZooKeeperServer的子类的更换。这就是QuorumPeer:
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns()); // 初始化ServerCnxnFactory
quorumPeer = new QuorumPeer(config.getServers(),
new File(config.getDataDir()),
new File(config.getDataLogDir()),
config.getElectionAlg(),
config.getServerId(),
config.getTickTime(),
config.getInitLimit(),
config.getSyncLimit(),
config.getQuorumListenOnAllIPs(),
cnxnFactory,
config.getQuorumVerifier()); // 创建QuorumPeer实例,
quorumPeer.setClientPortAddress(config.getClientPortAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory())); // 创建内存数据库
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
quorumPeer.start();
quorumPeer.join();
这里面很多的配置属性都交给了QuorumPeer,由它传递给底层所使用的ZooKeeperServer子类。
- ServerCnxnFactory cnxnFactory:负责和客户端建立连接和通信
- FileTxnSnapLog logFactory:通过dataDir和dataLogDir目录,用于事务日志记录和内存DataTree和session数据的快照。
- Map
int electionType:选举算法的类型。默认是3,采用的是FastLeaderElection选举算法。 - long myid:就是本机器配置的id,即myid文件中写入的数字。
- QuorumVerifier quorumConfig:用于验证是否过半机器已经认同了。默认采用的是QuorumMaj,即最简单的数量过半即可,不考虑权重问题
- ZKDatabase zkDb:即该服务器的内存数据库,最终还是会传递给ZooKeeperServer的子类。
- LearnerType:就两种,PARTICIPANT, OBSERVER。PARTICIPANT参与投票,可能成为Follower,也可能成为Leader。OBSERVER不参与投票,角色不会改变。
然后就是启动QuorumPeer,之后阻塞主线程,启动过程如下:
@Override
public synchronized void start() {
loadDataBase();//从事务日志目录dataLogDir和数据快照目录dataDir中恢复出DataTree数据
cnxnFactory.start();//开启对客户端的连接端口,启动ServerCnxnFactory主线程
startLeaderElection();//创建出选举算法
super.start();//启动QuorumPeer线程,在该线程中进行服务器状态的检查
}
QuorumPeer本身继承了Thread,在run方法中不断的检测当前服务器的状态,即QuorumPeer的ServerState state属性。ServerState枚举内容如下:
public enum ServerState {
LOOKING, FOLLOWING, LEADING, OBSERVING;
}
- LOOKING:即该服务器处于Leader选举阶段
- FOLLOWING:即该服务器作为一个Follower
- LEADING:即该服务器作为一个Leader
- OBSERVING:即该服务器作为一个Observer
在QuorumPeer的线程中操作如下:
服务器的状态是LOOKING,则根据之前创建的选举算法,执行选举过程
选举过程一直阻塞,直到完成选举。完成选举后,各自的服务器根据投票结果判定自己是不是被选举成Leader了,如果不是则状态改变为FOLLOWING,如果是Leader,则状态改变为LEADING。
服务器的状态是LEADING:则会创建出LeaderZooKeeperServer服务器,然后封装成Leader,调用Leader的lead()方法,也是阻塞方法,只有当该Leader挂了之后,才去执行下setLeader(null)并重新回到LOOKING的状态
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead(); // 阻塞
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
服务器的状态是FOLLOWING:则会创建出FollowerZooKeeperServer服务器,然后封装成Follower,调用follower的followLeader()方法,也是阻塞方法,只有当该集群中的Leader挂了之后,才去执行下setFollower(null)并重新回到LOOKING的状态
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader(); // 阻塞
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
leader和follower启动过程
protected Leader makeLeader(FileTxnSnapLog logFactory) throws IOException {
return new Leader(this, new LeaderZooKeeperServer(logFactory,
this,new ZooKeeperServer.BasicDataTreeBuilder(), this.zkDb));
}
首先是根据已有的配置信息创建出LeaderZooKeeperServer:
LeaderZooKeeperServer(FileTxnSnapLog logFactory, QuorumPeer self,
DataTreeBuilder treeBuilder, ZKDatabase zkDb) throws IOException {
super(logFactory, self.tickTime, self.minSessionTimeout,
self.maxSessionTimeout, treeBuilder, zkDb, self);
}
然后就是封装成Leader对象
Leader(QuorumPeer self,LeaderZooKeeperServer zk) throws IOException {
this.self = self;
try {
if (self.getQuorumListenOnAllIPs()) {
ss = new ServerSocket(self.getQuorumAddress().getPort());
} else {
ss = new ServerSocket();
}
ss.setReuseAddress(true);
if (!self.getQuorumListenOnAllIPs()) {
ss.bind(self.getQuorumAddress());
}
Leader和LeaderZooKeeperServer各自的职责是什么呢?
我们知道单机版使用的ZooKeeperServer不需要处理集群版中Follower与Leader之间的通信。ZooKeeperServer最主要的就是RequestProcessor处理器链、ZKDatabase、SessionTracker(只是实现不一样)。这几部分是单机版和集群版服务器都共通的,主要不同的地方就是RequestProcessor处理器链的不同。所以LeaderZooKeeperServer、FollowerZooKeeperServer和ZooKeeperServer最主要的区别就是RequestProcessor处理器链。
集群版还要负责处理Follower与Leader之间的通信,所以需要在LeaderZooKeeperServer和FollowerZooKeeperServer之外加入这部分内容。所以就有了Leader对LeaderZooKeeperServer等封装,Follower对FollowerZooKeeperServer的封装。前者加上加入ServerSocket负责等待Follower的socket连接,后者加入Socket负责去连接Leader。
看下Leader处理socket连接的过程:
@Override
public void run() {
try {
while (!stop) {
try{
Socket s = ss.accept();
// start with the initLimit, once the ack is processed
// in LearnerHandler switch to the syncLimit
s.setSoTimeout(self.tickTime * self.initLimit);
s.setTcpNoDelay(nodelay);
BufferedInputStream is = new BufferedInputStream(
s.getInputStream());
LearnerHandler fh = new LearnerHandler(s, is, Leader.this);
fh.start();
} catch (SocketException e) {
if (stop) {
LOG.info("exception while shutting down acceptor: "
+ e);
// When Leader.shutdown() calls ss.close(),
// the call to accept throws an exception.
// We catch and set stop to true.
stop = true;
} else {
throw e;
}
} catch (SaslException e){
LOG.error("Exception while connecting to quorum learner", e);
}
}
} catch (Exception e) {
LOG.warn("Exception while accepting follower", e);
}
}
可以看到每来一个其他ZooKeeper服务器的socket连接,就会创建一个LearnerHandler,具体的处理逻辑就全部交给LearnerHandler了
leader 选举
- 初始化leader选举算法:
集群模式特有,Zookeeper首先会根据自身的服务器ID(SID)、最新的ZXID(lastLoggedZxid)和当前的服务器epoch(currentEpoch)来生成一个初始化投票
在初始化过程中,每个服务器都会给自己投票。然后,根据zoo.cfg的配置,创建相应Leader选举算法实现
Zookeeper提供了三种默认算法(LeaderElection、AuthFastLeaderElection、FastLeaderElection),可通过zoo.cfg中的electionAlg属性来指定,从3.4.0版本开始,zk只支持FastLeaderElection选举算法。
在初始化阶段,Zookeeper首先会创建Leader选举所需的网络I/O层QuorumCnxManager,同时启动对Leader选举端口的监听,等待集群中其他服务器创建连接。
synchronized public void startLeaderElection() {
try {
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch(IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
for (QuorumServer p : getView().values()) {
if (p.id == myid) {
myQuorumAddr = p.addr; // 给自己投票
break;
}
}
if (myQuorumAddr == null) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
if (electionType == 0) {
try {
udpSocket = new DatagramSocket(myQuorumAddr.getPort());
responder = new ResponderThread();
responder.start();
} catch (SocketException e) {
throw new RuntimeException(e);
}
}
this.electionAlg = createElectionAlgorithm(electionType); // 创建投票算法,并leader选举所需的网络IO层 QuorumCnxManager,
}
- 注册JMX服务。
- 检测当前服务器状态: 运行期间,QuorumPeer会不断检测当前服务器状态。在正常情况下,Zookeeper服务器的状态在LOOKING、LEADING、FOLLOWING/OBSERVING之间进行切换。在启动阶段,QuorumPeer的初始状态是LOOKING,因此开始进行Leader选举。
- Leader选举。
通过投票确定Leader,其余机器称为Follower和Observer。
@Override
public void run() {
setName("QuorumPeer" + "[myid=" + getId() + "]" +
cnxnFactory.getLocalAddress());
LOG.debug("Starting quorum peer");
try {
jmxQuorumBean = new QuorumBean(this);
MBeanRegistry.getInstance().register(jmxQuorumBean, null); // 注册jmx服务
for(QuorumServer s: getView().values()){
ZKMBeanInfo p;
if (getId() == s.id) {
p = jmxLocalPeerBean = new LocalPeerBean(this);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxLocalPeerBean = null;
}
} else {
p = new RemotePeerBean(s);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
}
}
}
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxQuorumBean = null;
}
try {
/*
* Main loop
*/
while (running) {
switch (getPeerState()) { // 检查当前服务器状态
case LOOKING:
LOG.info("LOOKING");
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader()); // 开始选举
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e );
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception",e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
try {
MBeanRegistry.getInstance().unregisterAll();
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
}
}