一,原理简介:
- 手机端安装一个server程序
- 然后把手机端的端口转到PC端,
- PC端写python脚本进行通信,python脚本中需要hook的代码采用javascript语言。
frida使用的是动态二进制插桩技术(DBI),首先来了解一下插桩技术:
插桩技术是指将额外的代码注入程序中以收集运行时的信息,可分为两种:
(1)源代码插桩[Source Code Instrumentation(SCI)]:顾名思义,在程序源代码的基础上增加(注入)额外的代码,从而达到预期目的或者功能;
 源代码插桩实例
源代码插桩实例
(2)二进制插桩(Binary Instrumentation):额外代码注入到二进制可执行文件中,通过修改汇编地址,改变程序运行内容,运行后再返回到原来程序运行出处,从而实现程序的额外功能。
●静态二进制插桩[Static Binary Instrumentation(SBI)]:在程序执行前插入额外的代码和数据,生成一个永久改变的可执行文件。
●动态二进制插桩[Dynamic Binary Instrumentation(DBI)]:在程序运行时实时地插入额外代码和数据,对可执行文件没有任何永久改变。*
DBI能做什么?
(1)访问进程的内存
(2)在应用程序运行时覆盖一些功能
(3)从导入的类中调用函数
(4)在堆上查找对象实例并使用这些对象实例
(5)Hook,跟踪和拦截函数等等
frida原理和xposed差不多,文章写完才发现发现这里有一篇m4bln大神的文章对原理解释更清楚,解析了frida的源码,从dalvik和art的启动底层原理讲起,Frida源码分析
下面重点讲下frida的使用。
二,安装
首先通过上面的介绍,明白frida是通过本地设备与远程设备端通信实现hook脚本传递注入的,所以可以确定要有本地客户端和远程服务端两部分组成:
1,本地客户端是基于Python的,首先安装python环境,然后使用
pip install frida
所以在远程端一定要有一个服务端用来接收我们发过去的js代码,即frida-server官方地址 , 其中包括各种平台
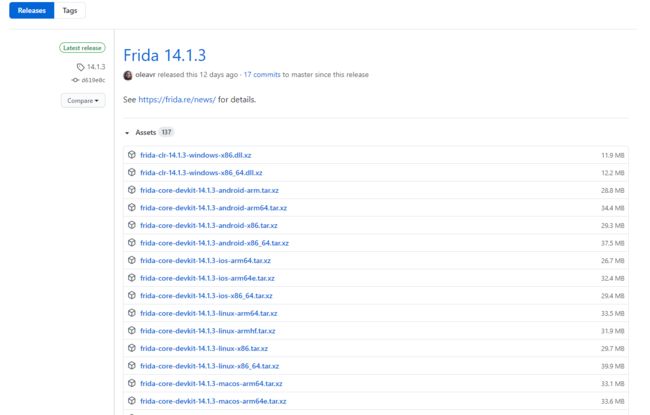
这里我们需要根据我们要hook设备的系统选择相应的下载包,这里我们选择Android系统

其实我们在这里还可以看到有很多其他的Android的选择,如下,其实每类服务端都适用于不同的场景,
比如:gadget适用于当无法获取root权限时可以将gadget.so植入目标apk中重打包,通过修改应用,使得server以应用的权限启动;还有frida-gum、frida-gumjs、frida-inject、frida-devkit等。





三,使用:
下面主要针对frida-server和frida-Gadget两种来展开使用记录。
1,frida-server
下面是frida官网给出的Android环境下hook的使用demo:
其中中间绿色部分是js代码,上下部分是python语言;
python语言部分只是单纯的为了将js代码发送到设备而已,核心功能还是在js部分实现;
1,js语言是弱语言,不对变量类型做强检查,所以我们可以都用var表示;
2,java中的类都用java.use获取;
3,js代码function大括号内部是用于hook的主要代码,其余部分基本不变
import frida, sys
def on_message(message, data):
if message['type'] == 'send':
print("[*] {0}".format(message['payload']))
else:
print(message)
jscode = """
Java.perform(function () {
// Function to hook is defined here
var MainActivity = Java.use('com.example.seccon2015.rock_paper_scissors.MainActivity');
// Whenever button is clicked
var onClick = MainActivity.onClick;
onClick.implementation = function (v) {
// Show a message to know that the function got called
send('onClick');
// Call the original onClick handler
onClick.call(this, v);
// Set our values after running the original onClick handler
this.m.value = 0;
this.n.value = 1;
this.cnt.value = 999;
// Log to the console that it's done, and we should have the flag!
console.log('Done:' + JSON.stringify(this.cnt));
};
});
"""
process = frida.get_usb_device().attach('com.example.seccon2015.rock_paper_scissors')
script = process.create_script(jscode)
script.on('message', on_message)
print('[*] Running CTF')
script.load()
sys.stdin.read()
下面以姜维在CSDN上给出的几个例子来讲解记录一下这部分js代码的用法:
java层hook:
1,hook构造方法
原方法:
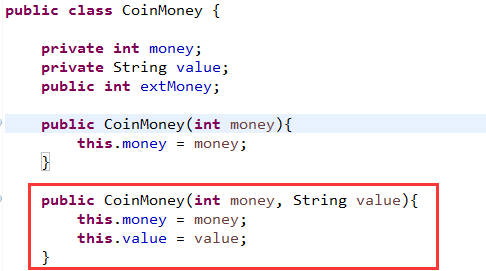
hook代码:

首先脚本中使用Java.use方法通过类名获取类类型,然后构造方法是固定写法:
$init;这个要记住,然后因为需要重载所以用overload(……)形式即可,参数和参数之间用逗号隔开即可,这里用
return重新调用了原来方法。
2,hook普通方法(static、private、public等)
原方法:

hook代码:

这里的用法和构造方法基本一致,就是把
$init换成了方法名而已;
3,修改参数和返回值
参数和返回值的修改在上面内容很容易看出来,就是在方法拦截后通过arguments参数去获取传入参数,然后修改,返回值的话直接修改return函数就好了,这里重点讲的是自定义类型的参数:

构造一个新对象的方法有很多,这里选择最简单的
$new即可,上面那行注释也是可以用的,这里的返回值直接修改成了我们构造出来的这个对象coinObj,但是如果要修改一个对象的内部值的话,直接用对象名加参数是不行的,那么就需要用反射了:

其中
java.cast(Object.getClass(),).getDeclaredField("")的固定用法记住即可;
4,打印方法的堆栈信息
可以用来查看方法的调用链关系,这里提供两种思路,一种是自己编写一个打印堆栈的方法,弄成dex注入到程序中,需要打印的时候直接调用;第二种就是简单粗暴的直接在打印的地方构造一个异常对象然后抛出,但是这种方法会因为异常直接导致程序崩溃,不过无所谓了,我们可以看到调用关系就好了;
Native层hook:
1,hook未导出的函数

首先计算出目标函数实际地址=函数偏移+so基址+1,+1是因为要标识arm和thumb指令区别;
然后通过实际地址构造NativePointer对象;
通过拦截器模式attach到目标开始hook,这里的onEnter和onLeave与xposed中的before和after很像,其实功能也一样,都是在函数开始前和结束后;
var nativePointer = new NativePointer(实际地址)
这里读取到的参数其实一个指针,也就是一个地址,想要获取内容需要用到Memory.readCString(地址)来打印参数;读取返回值的时候,因为C语言中是多数情况是通过参数来返回函数结果的,我们就把参数地址里的内容打印出来,如果有多个参数就全打印出来再分析,这里是将返回结果的字节数组按字节打印,然后拼接在一起在打印出来的;
2,hook导出的函数

这里省去了手动计算地址的过程,只需要传入so名字和函数名字即可,如果是c++的话则需要注意,因为C++支持重载,所以导出函数名会不同;
这里通过函数名可以知道就是一个native函数了,那么他第一个参数肯定是JNIEnv指针,第二个参数是jclass类型,这个是标准的如果是静态方法第二个参数没啥用,后面的参数就是真的传递到native层的值了,比如这里Java层的方法:
放到native层就变成4个参数了:

只有后面两个才是我们需要的,然后查看hook返回结果:

这里可以看到传入参数都返回了,但是函数return值是空的,这是因为这里的返回值是一个jString类型,看过jni.h文件的同学应该知道,jni里有一套自己的数据类型定义,虽然格式都和java一致,但是他属于自定义类型;

这里new一个NativeFunction的用法可以查看api:

至于获取jString的方法官网也有说明,很简单:
var env =Java.vm.getEnv();
var jstring = env.newStringUtf("HelloWorld");

2,frida-Gadget
frida-gadget作为一个动态库文件无法直接在linux/Android环境下运行,需要用过将apk反编译成smali代码,然后通过System.loadlibrary("frida-Gadget");的形式将so动态库运行起来,此时Frida-server就是以应用的权限运行起来的,在应用的沙箱中是拥有全部权限的,包括拦截、插桩等操作;
1,程序首先要打开可调试状态开关,
比如AndroidManifest文件中的Application中增加android:debuggable="true"标签
2,将frida-gadget.so放到目标apk的lib文件夹下,将so的名字改成lib***.so的格式

3,植入点通常放在Application的入口处,因为尽可能早的hook住程序就可以避免漏过方法执行;
在smali代码下表现为Application中的构造函数处,.methods static constructor
static{
// //loadlibary里 要把SO文件名的lib和后缀去掉。libfgma.so --> fgma
System.loadLibrary("fgma");
}


如果一个应用有多个进程的话则不必将so的植入点放到最初application的构造函数中,可以选择将植入点选在新进程开启后的合适的地点,最好还是构造函数初始化过程,但不限于最早组件,可选择适当时机启动的组件,如下,并在加载后使进程休眠20s的时间,用来等待粘贴js代码;

4,程序运行到so启动时会卡住,此时是在等待客户端像服务端发送建立连接的命令
此时在pc端命令行输入adb shell netstat -ls查看网络端口会发现有27042的消息端口;
如果在pc端命令行输入frida -U Gadget命令即可与之建立连接,此过程相当于frida-server模式下的python注入过程,在此建立连接之后我们可以直接输入js代码去执行目的代码,
例如:
//打印目的内存值
var tar = new NativePointer(0x94b778d9);send(hexdump(this.tar));
//获取目的函数模块
var nativePointer = Module.findExportByName(null,'SeedDecryptAndIDEncrypt');
//打印目的函数地址
send("smm native pointers:" + nativePointer);
//连接目的函数进程
Interceptor.attach(nativePointer,{
onEnter: function(args){
//打印目标函数传入参数值
send("sDIDE args: args[0]:" + args[0] + ", args[1]:" + args[1] + ", args[2]:" + args[2] + ", args[3]:" + args[3]);
//打印目的函数参数作为地址指向的内存的数值
send("smm sDIDE Memory args: args[0]:" + Memory.readInt(args[0]).toString() +
", args[2]:" + Memory.readInt(args[2]).toString() +
", args[3]:" + Memory.readInt(args[3]).toString());
},
onLeave: function(retval){
//打印目标函数的返回值
send("smm SeedDecryptAndIDEncrrypt retval:" + retval.toString());
}
});
注意此处的方法名使用单引号,findExportByName()函数的第一个参数可以用so名字或者为空;
以上就是frida的主要用法,其实frida的功能还有很多,而且不限于Android平台,总之,大佬们的总结是个好东西,官网api也是个好东西。