概述
官方地址http://hive.apache.org/
官方文档地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
简单,容易上手提供了类似SQL查询语言HQL
为超大数据集设计的计算、存储拓展能力
统一的元数据管理
安装
官方下载地址 http://hive.apache.org/downloads.html
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
tar -zxvf ~/Downloads/apache-hive-1.2.2-bin.tar.gz -C /opt/module/
cd /opt/module/
mv apache-hive-1.2.2-bin/ hive
cdh版本安装地址
#wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
#tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C app/
#mv hive-1.1.0-cdh5.7.0/ hive
配置
设置环境变量
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
修改hive中config目录的配置
cp hive-env.sh.template hive-env.sh
设置 hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
拷贝MySQL驱动到lib目录下
# wget https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.48.tar.gz
# mkdir lib
# tar -zxvf mysql-connector-java-5.1.48.tar.gz -C lib
# cp ~/lib/mysql-connector-java-5.1.48/mysql-connector-java-5.1.48-bin.jar ~/app/hive/lib
Hadoop集群配置
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
设置数据库权限
cd /root/app/hive/conf
vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive_metastore?useSSL=false
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
hive
username to use against metastore database
javax.jdo.option.ConnectionPassword
hive
password to use against metastore database
在hive-site.xml文件中添加如下配置信息,显示当前数据库,以及查询表的头信息配置。
hive.cli.print.header
true
hive.cli.print.current.db
true
创建Mysql数据库和权限
# mycli -uroot -hlocalhost
mysql root@localhost:(none)> create database hive_metastore
mysql root@localhost:(none)> grant all privileges on hive.* to 'hive'@'localhost' identified by 'hive';
mysql root@localhost:(none)> flush privileges;
修改日志存储路径
$ cp hive-log4j.properties.template hive-log4j.properties
$ vim hive-log4j.properties
hive.log.dir=/opt/module/hive/logs
hive启动
启动hive之前,请先启动hadoop集群。
start-all.sh #启动hadoop
hive #启动hive
spark2.0问题
ls: 无法访问/root/app/spark/lib/spark-assembly-.jar: 没有那个文件或目录,
spark升级到spark2以后,原有lib目录下的大JAR包被分散成多个小JAR包,原来的spark-assembly-.jar已经不存在,所以hive没有办法找到这个JAR包。
111 # add Spark assembly jar to the classpath
112 if [[ -n "$SPARK_HOME" ]]
113 then
114 sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
115 CLASSPATH="${CLASSPATH}:${sparkAssemblyPath}"
116 fi
基本操作
创建数据库
hive> create database if not exists hive;
OK
Time taken: 0.215 seconds
查看数据库
hive> show databases;
OK
default
hive
Time taken: 0.043 seconds, Fetched: 2 row(s)
切换数据库
hive> use hive;
创建数据表
hive>create table wordcount (count string);
hive> create table student(id int,name string);
查看表
show tables;
查看表结构
hive> desc student;
OK
id int
name string
Time taken: 0.236 seconds, Fetched: 2 row(s)
插入数据
hive> insert into student values(1,"xiaoming");

查询数据
hive> select * from student;
OK
1 xiaoming
Time taken: 0.099 seconds, Fetched: 1 row(s)
加载本地数据
创建测试数据vim student.txt
1 zhangsan
2 wangwu
3 zhaosi
4 liliu
创建student表
hive> use default;
OK
Time taken: 1.018 seconds
hive> show tables;
OK
Time taken: 0.296 seconds
hive> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.384 seconds
加载本地数据到表中
hive> load data local inpath '/opt/module/data/student.txt' into table student;
Loading data to table default.student
Table default.student stats: [numFiles=2, numRows=0, totalSize=48, rawDataSize=0]
OK
Time taken: 0.997 seconds
查看加载数据结果
hive> select *from student;
OK
1 zhangsan
2 wangwu
3 zhaosi
4 liliu
Time taken: 0.355 seconds, Fetched: 4 row(s)
wordcount
hive> load data local inpath '/home/hadoop/data/hello.txt' into table wordcount;
执行job
select word,count(1) from wordcount lateral view explode(split(count,'\t')) wc as word group by word;
MapReduce 加载
[root@aliyun conf]# cd ~/app/hadoop/
[root@aliyun hadoop]# mkdir input
[root@aliyun hadoop]# cd input
[root@aliyun input]# vim test.txt
hello world
hello hadoop
# hadoop fs -put input/ /input
19/08/21 20:59:12 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
# hadoop fs -ls /input
19/08/21 20:59:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 root supergroup 25 2019-08-21 20:59 /input/test.txt
# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input /output
查看结果
[root@aliyun hadoop]# hadoop fs -ls /output
19/08/21 21:02:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 1 root supergroup 0 2019-08-21 21:01 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 25 2019-08-21 21:01 /output/part-r-00000
[root@aliyun hadoop]# hadoop fs -cat /output/part-r-00000
19/08/21 21:03:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hadoop 1
hello 2
world 1
hive
hive> use hive;
hive> create table docs(line string);
hive> load data inpath '/input/' overwrite into table docs;
hive> create table word_count as
> select word, count(1) as count from
> (select explode(split(line,' '))as word from docs) w
> group by word
> order by word;
hive> select *from word_count;
OK
hadoop 1
hello 2
world 1
Time taken: 0.178 seconds, Fetched: 3 row(s)
Hive数据仓库位置配置
1)Default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下。
2)在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
3)修改default数据仓库原始位置(将hive-default.xml.template如下配置信息拷贝到hive-site.xml文件中)。
配置同组用户有执行权限
hdfs dfs -chmod g+w /user/hive/warehouse
查看student数据存储
$ hadoop fs -ls /user/hive/warehouse/student
19/08/26 00:56:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rwxrwxr-x 1 baxiang supergroup 11 2019-08-26 00:18 /user/hive/warehouse/student/000000_0
-rwxrwxr-x 1 baxiang supergroup 37 2019-08-26 00:50 /user/hive/warehouse/student/student.txt
baxiangs-Mac-mini:data baxiang$ hadoop fs -text /user/hive/warehouse/student/student.txt
19/08/26 00:57:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 zhangsan
2 wangwu
3 zhaosi
4 liliu
脚本执行
$ vim student.sql
SELECT * FROM student;
$ hive -f student.sql
$ hive -f student.sql >student_all.txt //执行文件中的sql语句并将结果写入文件中
数据查看
查看hdfs数据
hive (default)> dfs -ls /user/hive/;
Found 1 items
drwxrwxr-x - baxiang supergroup 0 2019-08-26 00:12 /user/hive/warehouse
查看本地数据
hive (default)> ! cat /opt/module/data/student.sql;
SELECT * FROM student;
HiveJDBC
启动hiveserver2
$ hiveserver2
启动beeline
beeline
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: root
Enter password for jdbc:hive2://localhost:10000: ****
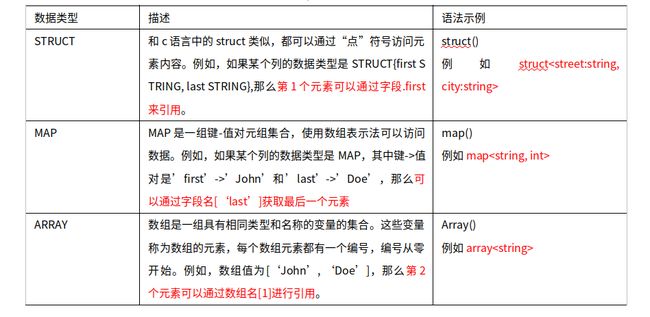
数据类型

管理表
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
hadoop dfs -mkdir /student;
hadoop dfs -put /opt/module/data/student.txt /student;
hadoop fs -ls /student
Found 1 items
-rw-r--r-- 1 baxiang supergroup 42 2019-08-27 15:43 /student/student.txt
创建表
hive (default)> create external table stu(
> id int,
> name string)
> row format delimited fields terminated by '\t'
> location '/student';
OK
Time taken: 0.599 seconds
hive (default)> select *from stu;
OK
stu.id stu.name
1 xiaoming
2 xiaowang
3 xiaohong
Time taken: 0.07 seconds, Fetched: 3 row(s)
删除表
外部表删除后,hdfs中的数据还在,但是metadata中stu_external的元数据已被删除
hive (default)> drop table stu;
OK
Time taken: 0.514 seconds
hive (default)> dfs -cat /student/student.txt;
1 xiaoming
2 xiaowang
3 xiaohong
相互转换
hive (default)> desc formatted test;
Table Type: MANAGED_TABLE
hive (default)> alter table test set tblproperties('EXTERNAL'= 'TRUE');
hive (default)> desc formatted test;
Table Type: EXTERNAL_TABLE
分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
hive (default)> create table part_month(
> id int,name string,code int
> )
> partitioned by (month string)
> row format delimited fields terminated by '\t';
OK
hive (default)> load data local inpath '/opt/module/data/part.txt' into table part_month partition(month='201908');
Loading data to table default.part_month partition (month=201908)
Partition default.part_month{month=201908} stats: [numFiles=1, numRows=0, totalSize=69, rawDataSize=0]
OK
Time taken: 0.727 seconds
hive (default)> load data local inpath '/opt/module/data/part.txt' into table part_month partition(month='201907');
Loading data to table default.part_month partition (month=201907)
Partition default.part_month{month=201907} stats: [numFiles=1, numRows=0, totalSize=69, rawDataSize=0]
OK
Time taken: 0.619 seconds
查询结果
hive (default)> select *from part_month where month='201907';
OK
part_month.id part_month.name part_month.code part_month.month
10 ACCOUNTING 1700 201907
20 RESEARCH 1800 201907
30 SALES 1900 201907
40 OPERATIONS 1700 201907
Time taken: 0.209 seconds, Fetched: 4 row(s)
创建分区
Time taken: 0.052 seconds, Fetched: 3 row(s)
hive (default)> alter table part_month add partition(month='201706');
OK
Time taken: 0.57 seconds
hive (default)> alter table part_month add partition(month='201705') partition(month='201704');
OK
Time taken: 0.623 seconds
删除分区
hive (default)> alter table part_month drop partition(month='201704');
Dropped the partition month=201704
OK
Time taken: 0.383 seconds
查看分区数量
hive (default)> show partitions part_month;
OK
partition
month=201907
month=201908
month=201909
Time taken: 0.052 seconds, Fetched: 3 row(s)
修改
重命名表
ALTER TABLE table_name RENAME TO new_table_name
hive (default)> alter table test rename to tb_test;
OK
Time taken: 0.213 seconds
增加字段
hive (default)> alter table tb_test add columns(create_at timestamp);
OK
Time taken: 0.245 seconds
hive (default)> desc tb_test;
修改类型
hive (default)> alter table tb_test change column create_at create_time string;
OK
Time taken: 0.203 seconds
向表中装载数据(Load)
hive> load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
创建测试数据
1 xiaoming
2 xiaowang
3 xiaohong
创建表
create table student(id string, name string) row format delimited fields terminated by '\t';
加载测试数据
hive (default)> load data local inpath '/opt/module/data/student.txt' into table student;
Loading data to table default.student
Table default.student stats: [numFiles=1, totalSize=33]
OK
Time taken: 0.32 seconds
加载hdfs数据
➜ ~ hadoop fs -mkdir /test
➜ ~ hadoop fs -put /opt/module/data/student.txt /test
覆盖原先的数据
hive (default)> load data inpath '/test/student.txt' overwrite into table student;
Loading data to table default.student
Table default.student stats: [numFiles=1, numRows=0, totalSize=33, rawDataSize=0]
OK
Time taken: 0.509 second
清除表数据
Truncate只能删除管理表,不能删除外部表中数据
hive (default)> truncate table student;