学习目标/基础知识

学习目标
数组形状的改变
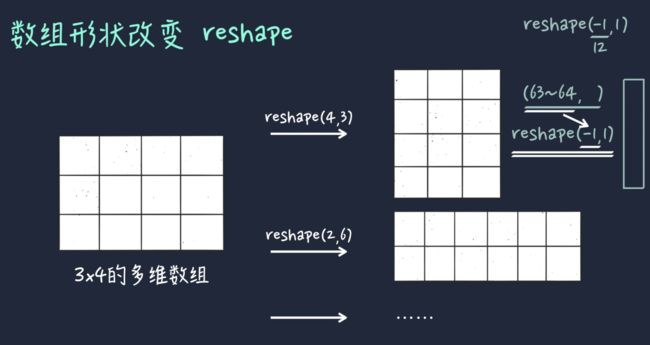
数组形状的改变
数组合并
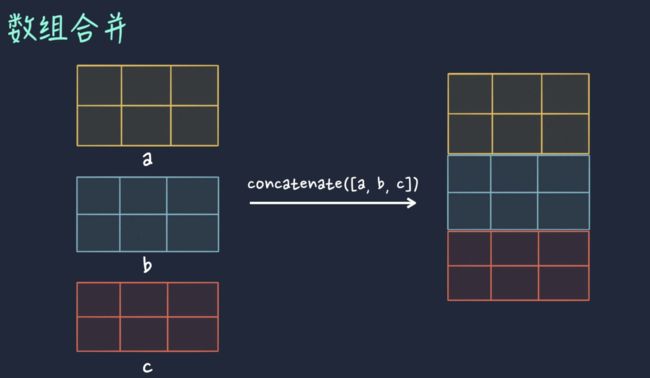
竖直方向合并数组
import os
import numpy as np
import matplotlib.pyplot as plt
data_path = '/Users/miraco/PycharmProjects/DataMining/bikeshare'
data_filenames = ['2017-q1_trip_history_data.csv', '2017-q2_trip_history_data.csv',
'2017-q3_trip_history_data.csv','2017-q4_trip_history_data.csv']
#结果保存路径
output_path = './bikeshare/output'
if not os.path.exists(output_path): #如果不存在就新建一个
os.makedirs(output_path)
def collect_and_process_data(): #数据获取和数据处理
member_type_list = []
for data_filename in data_filenames:
data_file = os.path.join(data_path, data_filename)
print(data_file)
# 读数据默认读取是浮点数, 但这个csv数据类型,各种还有年月日的,保险起见都用字符串类型
data_arr = np.loadtxt(data_file, delimiter=',', dtype='str', skiprows=1) # 读进来的数据
member_type_col = np.core.defchararray.replace(data_arr[:,-1],'"','') #获取最后一列并去掉双引号,
# 默认一位数据以行向量存储,想变成列向量就用reshape,不知道要多少行没事,该维度加上-1,python自动帮你算
member_type_col = member_type_col.reshape(-1,1)
member_type_list.append(member_type_col)
year_member_type = np.concatenate(member_type_list)
return year_member_type
def analyze_data(year_member_type): #数据分析
n_member = year_member_type[year_member_type == 'Member'].shape[0] #会员行数
n_casual = year_member_type[year_member_type == 'Casual'].shape[0] #非会员行数
return [n_member,n_casual]
def save_and_show_results(n_users): #数据保存和展示
plt.figure()
plt.pie(
n_users, #哪个变量要画饼
labels = ['Member','Casual'], #变量的标签
autopct = '%.2f%%', #显示数目百分比
shadow = True, #阴影饼状图
explode = [0,0.05], #使各个扇形彼此分离,列表内的值是距离圆心的offset
)
plt.axis('equal') #保证是个圆饼,不是扁饼,因为默认是扁的
plt.tight_layout()
plt.savefig(os.path.join(output_path,'piechart.png'))
plt.show()
def main():
year_member_type = collect_and_process_data()
n_users = analyze_data(year_member_type)
save_and_show_results(n_users)
if __name__ == '__main__':
main()
值得注意的地方
plt.pie(
n_users, #哪个变量要画饼
labels = ['Member','Casual'], #变量的标签
autopct = '%.2f%%', #显示数目百分比
shadow = True, #阴影饼状图
explode = [0,0.05], #使各个扇形彼此分离,列表内的值是距离圆心的offset
)
plt.axis('equal') #保证是个圆饼,不是扁饼,因为默认是扁的
知识点

知识点
练习
使用饼状图可视化不同气温的天数占比
题目描述:将1-3个月份的气温数据进行合并,并使用饼状图可视化所有数据的零上气温和零下气温的天数占比情况。
题目要求:
使用NumPy进行数组合并
使用Matplotlib进行可视化
数据文件:
数据源下载地址:https://video.mugglecode.com/data_temp.zip,下载压缩包后解压即可
201801_temp.csv、201802_temp.csv、201803_temp.csv分别包含了2018年1-3月北京的气温(每日的最低温度)。每行记录为1天的数据。
每个文件中只包含一列气温数据:temperature为摄氏温度
使用Matplotlib提供的pie()(https://matplotlib.org/api/_as_gen/matplotlib.pyplot.pie.html)进行饼状图可视化。
import os
import numpy as np
import matplotlib.pyplot as plt
file_list = ['/Users/miraco/PycharmProjects/DataMining/bikeshare/data_temp/201802_temp.csv',
'/Users/miraco/PycharmProjects/DataMining/bikeshare/data_temp/201801_temp.csv',
'/Users/miraco/PycharmProjects/DataMining/bikeshare/data_temp/201803_temp.csv'
]
output_path = './bikeshare/output'
if not os.path.exists(output_path): #如果不存在就新建一个
os.makedirs(output_path)
#数据读取
data_list = []
for file in file_list:
data = np.loadtxt(file, skiprows= 1, delimiter= ',', dtype = 'int')
data_list.append(data.reshape(-1,1))
all_data = np.concatenate(data_list)
total_count = [
all_data[all_data[0:] <= 0].shape[0],
all_data[all_data[0:] > 0].shape[0]
]
np.savetxt(
os.path.join(output_path,'temperrate.csv'),
np.array([total_count]),#.reshape(1,-1),
header='Over 0, Under 0',
delimiter=',',
comments='',
fmt= '%d'
)
plt.figure(figsize = (4,4))
plt.axis('equal')
plt.pie(
total_count,
labels = ['colder\n than 0', 'warmer\n than 0'],
autopct = '%.2f%%',
shadow = True,
explode = [0.1,0]
)
plt.tight_layout()
plt.title('3 months temperature statistics')
plt.savefig(os.path.join(output_path,'temperature_pie.png'))
plt.show()
存在的问题
问题1:
存数据的时候一开始我是这样写的:
np.array([total_count])
但是这时候生成的数据是列向量,我想变成行的。那么排查一下问题。
问题在数据转换的时候,就是np.array(total_count)时候,这个会自动转化成列向量的,怎么办呢?
total_count的内容是[73 17],但是np.array(total_count)会转换成[73 17],这是个列向量,不是行向量,如果是行向量的话,应该是[[73 17]],那么怎么办?
-
transpose()?
这个对一维数组不起作用,省省吧。
2.reshape(1,-1)
这个可以有。 -
total_count列表直接外套一个中括号,构建行。
这个可以有。
试试打印下来:
print(np.array(total_count))
print(np.array(total_count).transpose())
print(np.array(total_count).reshape(1,-1))
print(np.array([total_count]))
>>>
[73 17]
[73 17]
[[73 17]]
[[73 17]]
问题2
画布太小,字显示不全,即便用了`plt.tight_layout()怎么办呢?

画布太小,字显示不全
所以要调整画布大小,善用字间换行。
plt.figure(figsize = (4,4))
labels = ['colder\n than 0', 'warmer\n than 0']