本文选择了一句比较有代表性的查询语句,分别用不同的执行引擎执行,hive on mr 用时278s,hive on tez用时44s,spark SQL 用时24s,而presto只要18s。本文详细分析在执行这段查询的过程中,每个执行引擎的效率差异是在哪个阶段体现出来的,又能体现多少程度,原因又是什么。
本文分析用的benchmark 是TPC-DS,查询语句如下:
select i_item_desc
,i_category
,i_class
,i_current_price
,i_item_id
,sum(ws_ext_sales_price) as itemrevenue
,sum(ws_ext_sales_price)*100/sum(sum(ws_ext_sales_price)) over
(partition by i_class) as revenueratio
from
web_sales
,item
,date_dim
where
web_sales.ws_item_sk = item.i_item_sk
and item.i_category in ('Jewelry', 'Sports', 'Books')
and web_sales.ws_sold_date_sk = date_dim.d_date_sk
and date_dim.d_date between '2001-01-12' and '2001-02-11'
group by
i_item_id
,i_item_desc
,i_category
,i_class
,i_current_price
order by
i_category
,i_class
,i_item_id
,i_item_desc
,revenueratio
limit 100;
这段sql包含了两个inner join,有window function,aggregation,group by,order by。比较有代表性的一个查询。
其中表的数据量为:
web_sales: 716446671 rows, 48.1G
item: 300000 rows, 18.6M
date_dim: 73049 rows, 352.8 K
分析之前的几点声明:
1.执行效率的分析必须保证可用资源一致。这次评测通过yarn队列的资源限制保证hive和spark的最大可用资源一致。presto不基于yarn,只配置了单个查询最大可用内存小于hive和spark。
2.查询效率跟集群状态相关,这里取的是重复多次后的最快时间
3.各stage的时间是从log中获取的,从一个task执行完,到打印出log可能有延迟,所以时间可能有少量误差
4.很多配置项会影响执行过程,执行效率,这次分析使用的是我们集群当前的配置,并不保证所有的配置已经完全利用了各平台的特性
5.不同引擎对不同类型的查询优化程度不一样,要完整评测的话需要测试更多类型的查询
先看hive on mr ,hive on mr的执行流程为
1.SQL -> AST -> OPTree->执行计划
2.执行计划包含多个mr job,向MR框架依次提交执行
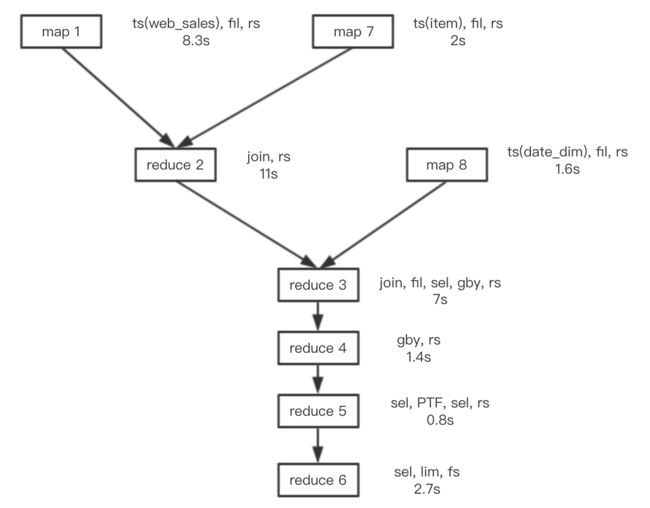
下图是执行计划中各个job执行所占的时间:

hive on mr的执行时间是278s,其中有130s(各个stage间的时间)用在了job提交、资源分配和运行环境初始化。可见几乎一半的时间没有用在job执行上面。
来看hive on tez,hive on tez的执行流程为
1.SQL -> AST -> OPTree->执行计划
2.执行计划包含一个DAG,向tez提交DAG执行
下图为DAG执行时间
hive on tez的执行时间是44s,DAG运行时间29s,编译sql生成执行计划用了3s。对比hive on mr,我们可以看出:
第一,hive on mr中的job提交、资源分配和运行环境初始化从130s减少到12s,因为hive on tez整个DAG是一个job,job提交只有一次,job内的container重用。
第二,job执行从126s减少到29s,这是因为tez灵活的DAG模型
1.使三个map的vertex可以并发执行
2.不再拘泥于map、reduce成对出现,可以有一串reduce
3.edge的channel可以是自定义的,不必非得是hdfs
再看spark sql,spark sql的执行流程为
1.SQL -> AST -> OPTree->RDD
2.遇到action生成job,生成一个job直接提交;job根据RDD transformation的宽依赖划分stage
job间可以并发执行,stage 顺序执行
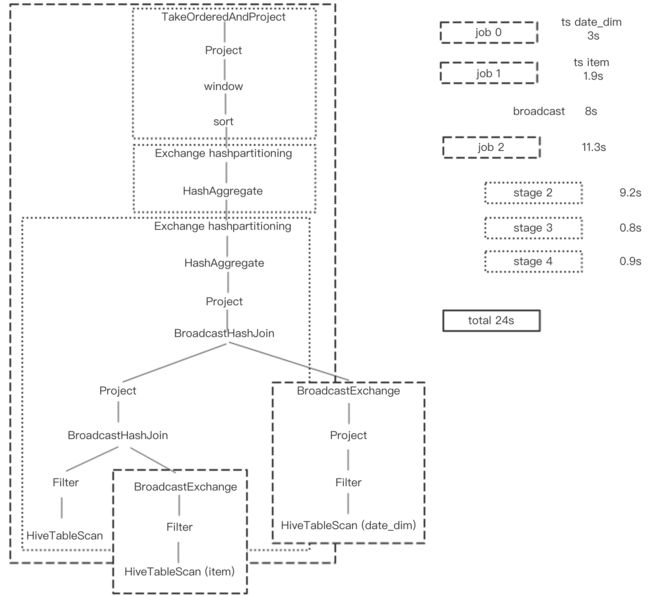
spark 执行时间为24s
1.其job执行占了22.3s(job1和job2并行), 其container的重用已经做到了极致,所有资源都是一开始申请好的。
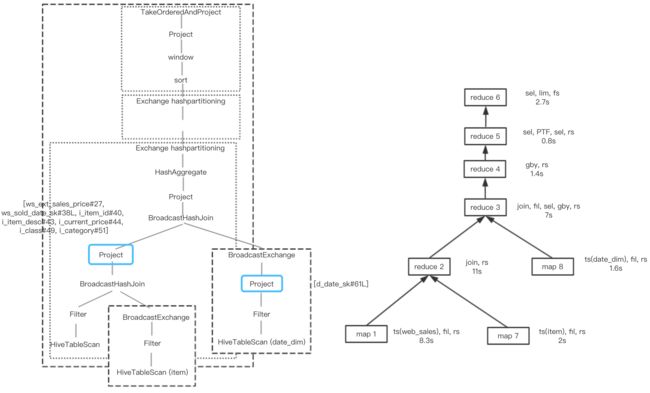
2.其对web_sales的读取并join(broad cast + job2 stage2)比tez(map1,reduce2,reduce3)快了9s,因为:
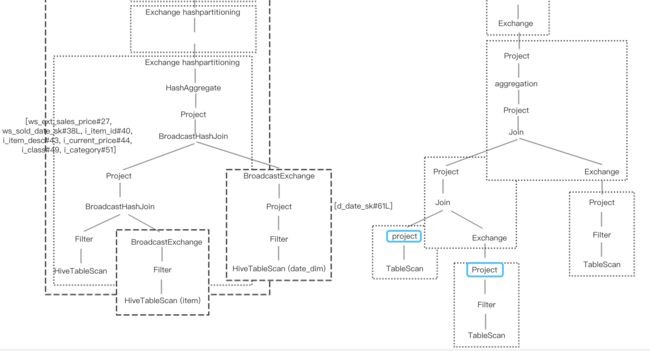
1)多了两个project的pushdown,见下图,在spark的执行计划中,在broadcast date_dim表的数据之前以及第二次broadcast join之间都进行了project,进行了column pruning;而在hive on tez的执行计划中,可见并没有相应的select operator。
2)spark 的broadcast 采用P2P方式,速度更快
再看presto,presto不依赖yarn进行资源管理,presto集群分为coordinator和worker节点,SQL提交到coordinator
1.SQL -> AST -> OPTree -> execution plan -> subplans
2.每个subplan 提交到多个worker上执行,下图是presto上的执行计划
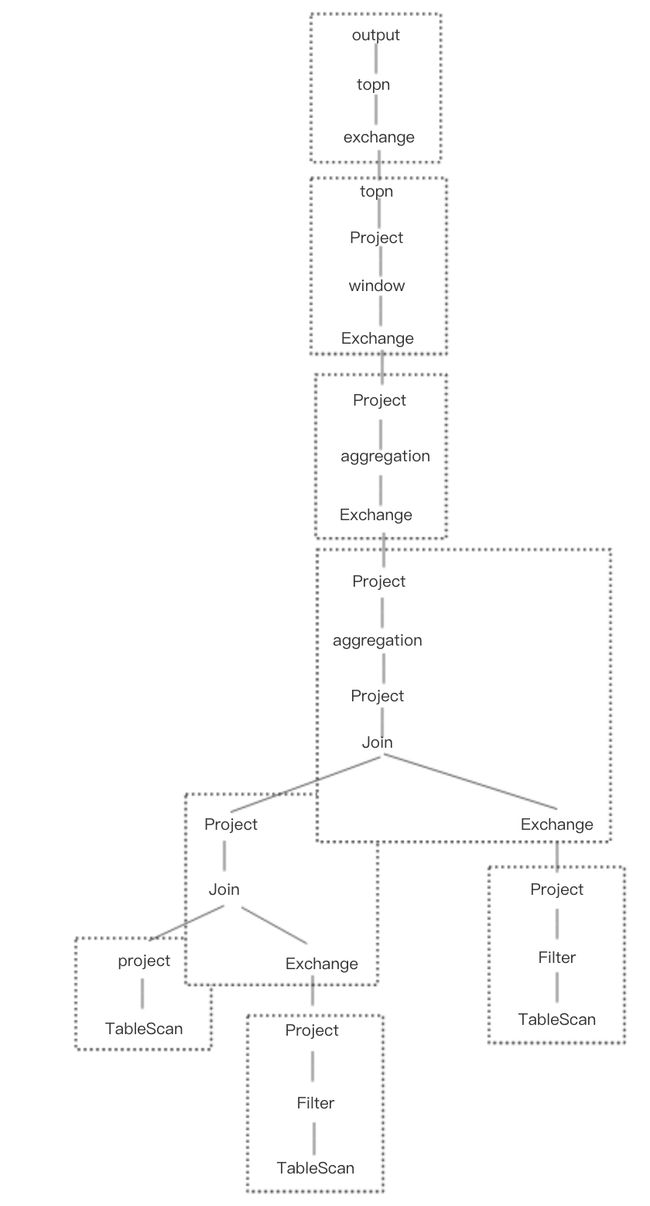
presto总执行时间17.7s。
presto相比spark SQL的速度更快的原因:
1.其模型有跨stage的流水线处理。其整个执行计划各部分会同时分发到各个worker,其中exchange operator会主动向上游worker节点拉取数据。也就是说上一个stage还没处理完,只要已经有数据产出,下一个stage就已经开始执行了。所以上图中没有指出各stage的执行时间,因为没有比较意义。
2.见下图,presto的每个表扫描之后都进行了projection,执行计划比spark SQL更优。
这次没有实际测试impala,比较了presto与impala的原理,两者基本类似,impala同样有stage间的流水线处理。与效率相关的地方,有两点不同,一是impala后端使用c++实现,语言上的效率上限高于presto。二是架构上impala抛弃了主从结构,不像presto只有一个coodinator,而是所有的impalad地位相同,都可以接受查询,解析sql,生成执行计划。当多用户并发查询的时候,效率优势会很明显。
总结一下影响效率的几个点:
1.资源申请、运行环境初始化
hive on mr 有参数可以配置同一个job中的task重用jvm,上图中每一个stage都是一个job,可见效果不会很明显。
hive on tez和spark都有container重用
presto不基于yarn,资源预分配
2.减少数据读写
hive on mr中间结果写hdfs
hive on tez 内存
spark 内存+本地
presto 纯内存
3.减少数据传输
全都做到了local计算
4.并发度
hive on mr 最弱,虽然有hive.exec.parallel,job内有效
hive on tez, 无依赖的vertices 并行执行
spark, 同hive on tez,无依赖的job并行执行
presto
5.执行计划优化
predicate pushdown 都一样
project pushdown 程度上presto > spark > hive
另外这次没提到的影响效率的点还有动态代码生成,文件存储格式,基于代价的执行计划优化等。
最后考虑一下影响查询引擎的效率上限的本质原因:
他们为用户提供的不同程度的灵活性而设计的编程模型的差异。
比如tez比spark慢的第二点,因为tez提供的模型是DAG,由用户自己控制vertex之间的edge,还可以自定义vertex manager。给用户提供了灵活性。而spark 的编程模型是RDD,对于stage的划分,stage到stage的数据交互完全不用向用户开放,因此可以做的效率更高。
而presto更是只提供了sql模型,相比spark不需要把sql先转成RDD,而是直接一体化,怎么快怎么来!