import seaborn as sns
%matplotlib inline
sns.set(font_scale=1.5,style="white")
sns.set_style('white',{'font.sans-serif':['simhei','Arial']})
# 本次试用的数据集是Seaborn内置的tips小费数据集:
data=sns.load_dataset("tips")
data.head(5)
kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。
seaborn.kdeplot(data,data2=None,shade=False,vertical=False,kernel='gau',bw='scott',gridsize=100,cut=3,clip=None,legend=True,cumulative=False,shade_lowest=True,cbar=False, cbar_ax=None, cbar_kws=None, ax=None, *kwargs)
- data:一维数组,单变量时作为唯一的变量
- data2:格式同data2,单变量时不输入,双变量作为第2个输入变量
- shade:bool型变量,用于控制是否对核密度估计曲线下的面积进行色彩填充,True代表填充
- vertical:bool型变量,在单变量输入时有效,用于控制是否颠倒x-y轴位置
- kernel:字符型输入,用于控制核密度估计的方法,默认为'gau',即高斯核,特别地在2维变量的情况下仅支持高斯核方法
- legend:bool型变量,用于控制是否在图像上添加图例
- cumulative:bool型变量,用于控制是否绘制核密度估计的累计分布,默认为False
- shade_lowest:bool型变量,用于控制是否为核密度估计中最低的范围着色,主要用于在同一个坐标轴中比较多个不同分布总体,默认为True
- cbar:bool型变量,用于控制是否在绘制二维核密度估计图时在图像右侧边添加比色卡
- color:字符型变量,用于控制核密度曲线色彩,同plt.plot()中的color参数,如'r'代表红色
- cmap:字符型变量,用于控制核密度区域的递进色彩方案,同plt.plot()中的cmap参数,如'Blues'代表蓝色系
- n_levels:int型,在二维变量时有效,用于控制核密度估计的区间个数,反映在图像上的闭环层数
rugplot
用于绘制出一维数组中数据点实际的分布位置情况,即不添加任何数学意义上的拟合,单纯的将记录值在坐标轴上表现出来,相对于kdeplot,其可以展示原始的数据离散分布情况
- a:一维数组,传入观测值向量
- height:设置每个观测点对应的小短条的高度,默认为0.05
- axis:字符型变量,观测值对应小短条所在的轴,默认为'x',即x轴
ax = sns.rugplot(iris.petal_length,color='r', height=0.2)
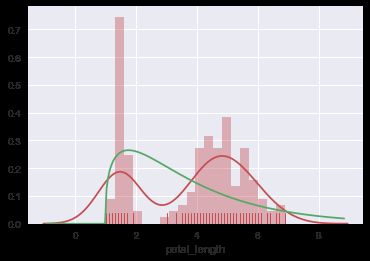
distplot
主要功能是绘制单变量的直方图,且还可以在直方图的基础上施加kdeplot和rugplot的部分内容
- a:一维数组形式,传入待分析的单个变量
- bins:int型变量,用于确定直方图中显示直方的数量,默认为None,这时bins的具体个数由Freedman-Diaconis准则来确定.
- hist:bool型变量,控制是否绘制直方图,默认为True
- kde:bool型变量,控制是否绘制核密度估计曲线,默认为True
- rug:bool型变量,控制是否绘制对应rugplot的部分,默认为False
- fit:传入scipy.stats中的分布类型,用于在观察变量上抽取相关统计特征来强行拟合指定的分布,下文的例子中会有具体说明,默认为None,即不进行拟合
- hist_kws,kde_kws,rug_kws:这几个变量都接受字典形式的输入,键值对分别对应各自原生函数中的参数名称与参数值,在下文中会有示例
- color:用于控制除了fit部分拟合出的曲线之外的所有对象的色彩
- vertical:bool型,控制是否颠倒x-y轴,默认为False,即不颠倒
- norm_hist:bool型变量,用于控制直方图高度代表的意义,为True直方图高度表示-对应的密度,为False时代表的是对应的直方区间内记录值个数,默认为False
- label:控制图像中的图例标签显示内容
from scipy.stats import chi2
ax = sns.distplot(iris.petal_length,color='r',rug=True,bins=20, fit=chi2, fit_kws={'color':'g'})
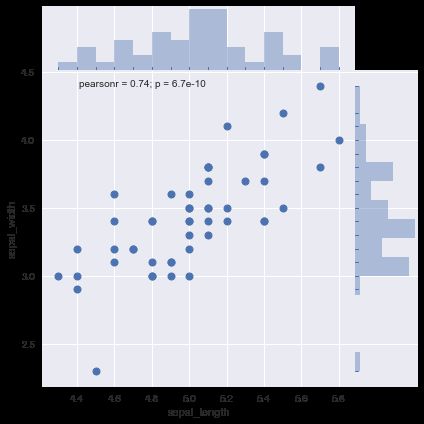
jointplot
聚合了前面所涉及到的众多内容,用于对成对变量的相关情况、联合分布以及各自的分布在一张图上集中呈现,
-x,y:代表待分析的成对变量,有两种模式,第一种模式:在参数data传入数据框时,x、y均传入字符串,指代数据框中的变量名;第二种模式:在参数data为None时,x、y直接传入两个一维数组,不依赖数据框
- data:与上一段中的说明相对应,代表数据框,默认为None
- kind:字符型变量,用于控制展示成对变量相关情况的主图中的样式
设置为'reg',为联合图添加线性回归拟合直线与核密度估计结果
'hex'来为联合图生成六边形核密度估计
'kde'来将直方图和散点图转换为核密度估计图 - color:控制图像中对象的色彩
- height:控制图像为正方形时的边长
- ratio:int型,调节联合图与边缘图的相对比例,越大则边缘图越矮,默认为5
- space:int型,用于控制联合图与边缘图的空白大小
- xlim,ylim:设置x轴与y轴显示范围
- joint_kws,marginal_kws,annot_kws:传入参数字典来分别精细化控制每个组件
ax=sns.jointplot(x='sepal_length',y='sepal_width',data=setosa, marginal_kws=dict(bins=15, rug=True), linewidth=1,space=0)
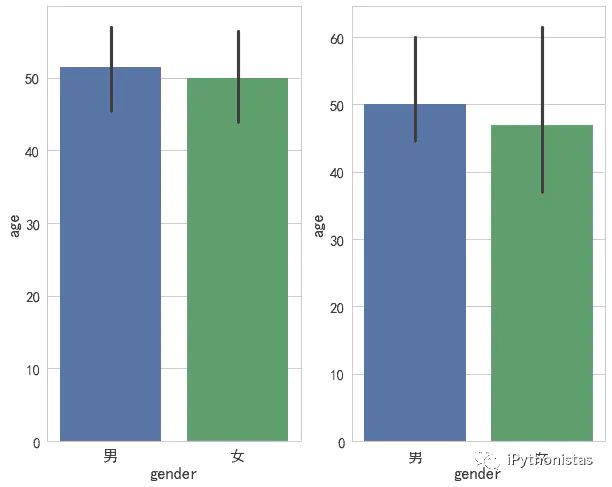
barplot(条形图)
条形图表示数值变量与每个矩形高度的中心趋势的估计值,并使用误差线提供关于该估计值附近的不确定性的一些指示。具体用法如下:
seaborn.barplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=(function mean), ci=95, n_boot=1000, units=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None, capsize=None, dodge=True, ax=None, **kwargs)
- x,y(str):dataframe中的列名
- data:dataframe或者数组
- hue(str):dataframe的列名,按照列名中的值分类形成分类的条形图
- order, hue_order (lists of strings):用于控制条形图的顺序
- estimator:
控制条形图的取整列数据的什么值 - ci(float):统计学上的置信区间(在0-100之间),若填写"sd",则误差棒用标准误差。(默认为95)
- capsize(float): 设置误差棒帽条(上下两根横线)的宽度
- palette:调色板,控制不同的颜色style
fig,axes=plt.subplots(1,2)
sns.barplot(x="gender",y="age",data=data,ax=axes[0]) #左图,默认为平均值
sns.barplot(x="gender",y="age",estimator=np.median,data=data,ax=axes[1]) #右图,中位数
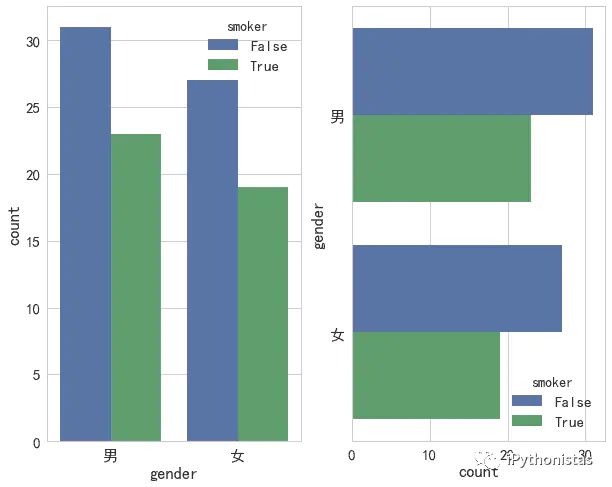
countplot
一个计数图可以被认为是一个分类直方图,而不是定量的变量。基本的api和选项与barplot()相同,因此您可以比较嵌套变量中的计数。(工作原理就是对输入的数据分类,条形图显示各个分类的数量)具体用法如下:
seaborn.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
注:countplot参数和barplot基本差不多,不同的是countplot中不能同时输入x和y,且countplot没有误差棒。
fig,axes=plt.subplots(1,2)
sns.countplot(x="gender",hue="smoker",data=data,ax=axes[0]) #左图
sns.countplot(y="gender",hue="smoker",data=data,ax=axes[1]) #右图
pointplot
点图代表散点图位置的数值变量的中心趋势估计,并使用误差线提供关于该估计的不确定性的一些指示。点图可能比条形图更有用于聚焦一个或多个分类变量的不同级别之间的比较。他们尤其善于表现交互作用:一个分类变量的层次之间的关系如何在第二个分类变量的层次之间变化。连接来自相同色调等级的每个点的线允许交互作用通过斜率的差异进行判断,这比对几组点或条的高度比较容易。具体用法如下:
seaborn.pointplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=(function mean), ci=95, n_boot=1000, units=None, markers='o', linestyles='-', dodge=False, join=True, scale=1, orient=None, color=None, palette=None, errwidth=None, capsize=None, ax=None, **kwargs)
- dodge参数可以使重叠的部分错开
- markers均值点的样式
- linestyles点之间的连线
sns.pointplot(x="smoker",y="age",data=data,hue="gender")
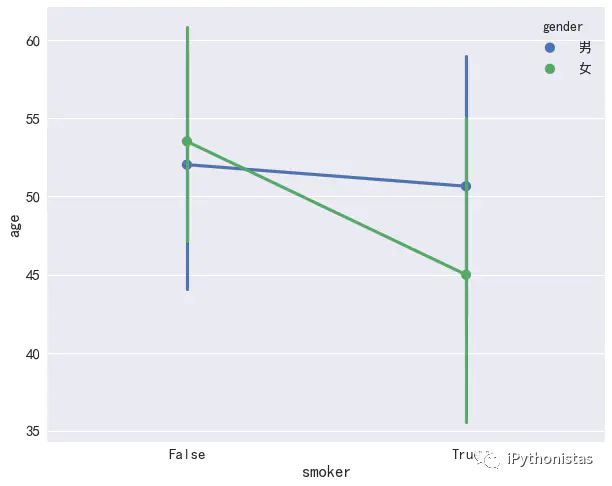
图中的点为这组数据的平均值点,竖线则为误差棒,默认两个均值点会相连接,若不想显示,可以通过join参数实现:
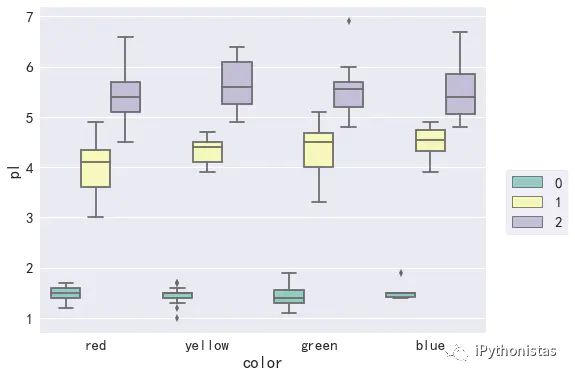
boxplot
seaborn.boxplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, notch=False, ax=None, **kwargs)
- data:dataframe或者数组
- palette:调色板
- hue(str):dataframe的列名
- order, hue_order (lists of strings):用于控制条形图的顺序
- orient:"v"|"h" 用于控制图像使水平还是竖直显示
- fliersize:float,用于指示离群值观察的标记大小
- whis: 确定离群值的上下界(IQR超过低和高四分位数的比例),此范围之外的点将被识别为异常值。IQR指的是上下四分位的差值。
- width: float,控制箱型图的宽度
sns.boxplot(x="color",y="pl",data=data,hue="catagory",palette="Set3")
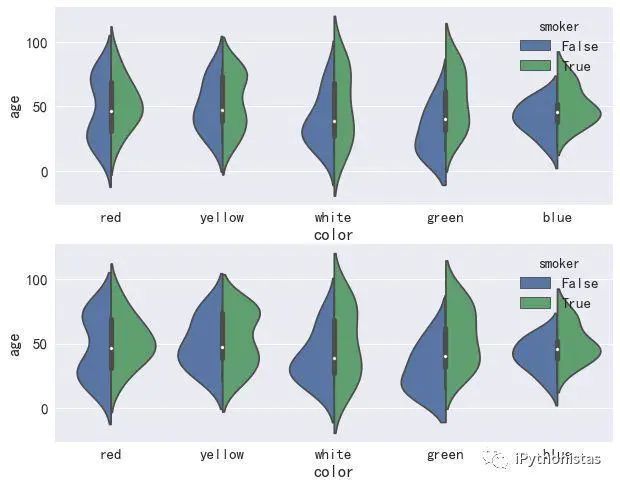
violinplot
它显示了定量数据在一个(或多个)分类变量的多个层次上的分布。不像箱形图中所有绘图组件都对应于实际数据点,小提琴绘图以基础分布的核密度估计为特征。具体用法如下:
seaborn.violinplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100, width=0.8, inner='box', split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, ax=None, **kwargs)
- split: 将split设置为true则绘制分拆的violinplot以比较经过hue拆分后的两个量
- scale_hue:bool,当使用色调变量(hue参数)嵌套小提琴时,此参数确定缩放是在主要分组变量(scale_hue = true)的每个级别内还是在图上的所有小提琴(scale_hue = false)内计算出来的。
- inner:控制violinplot内部数据点的表示,有'box','quartile','point','stick'四种方式。
- scale: 该参数用于缩放每把小提琴的宽度,有'area','count','width'三种方式
- cut: float,距离,以带宽大小为单位,以控制小提琴图外壳延伸超过内部极端数据点的密度。设置为0以将小提琴范围限制在观察数据的范围内(即,在ggplot中具有与trim = true相同的效果)
fig,axes=plt.subplots(2,1)
ax=sns.violinplot(x="color",y="age",data=data,hue="smoker",split=True,scale_hue=False,ax=axes[0]) #上图
ax=sns.violinplot(x="color",y="age",data=data,hue="smoker",split=True,scale_hue=True,ax=axes[1]) #下图
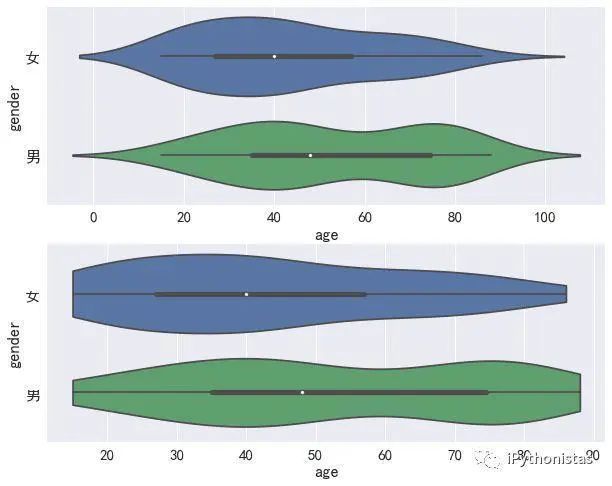
fig,axes=plt.subplots(2,1)
sns.violinplot(x="age",y="gender",data=data,ax=axes[0]) #上图
sns.violinplot(x="age",y="gender",data=data,cut=0,ax=axes[1]) #下图
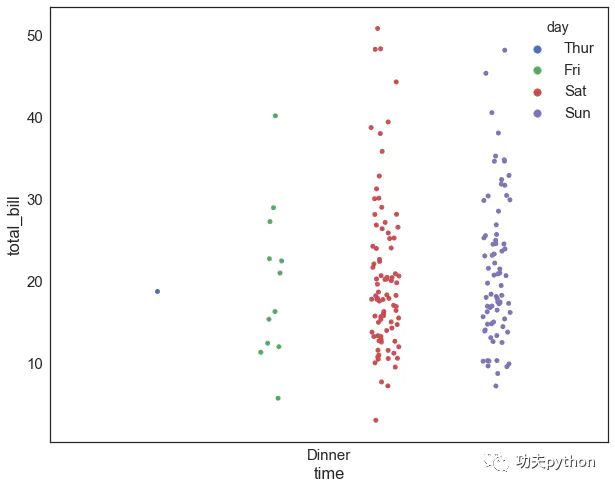
stripplot(分布散点图)
按照x属性所对应的类别分别展示y属性的值,适用于分类数据。
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, *kwargs)
- x:设置分组统计字段
- y:设置分布统计字段
- jitter:当数据点重合较多时设置为True使点散开
- hue参数进行内部的分类
- dodge:控制组内分类是否彻底分拆
- order:对x参数所选字段内的类别进行排序以及筛选
sns.stripplot(x="time",y="total_bill",data=data,jitter=True,
hue="day",dodge=True,order=["Dinner","Lunch"])
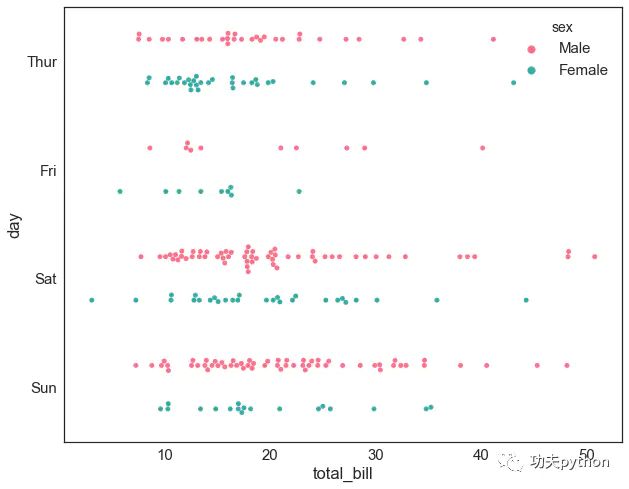
swarmplot(分簇散点图)
可以看到swarmplot将不同类别的散点图以树状来显示,其他参数用法和stripplot一致
sns.swarmplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, *kwargs)
sns.swarmplot(y="day",x="total_bill",data=data,hue="sex",dodge=True,palette="husl")
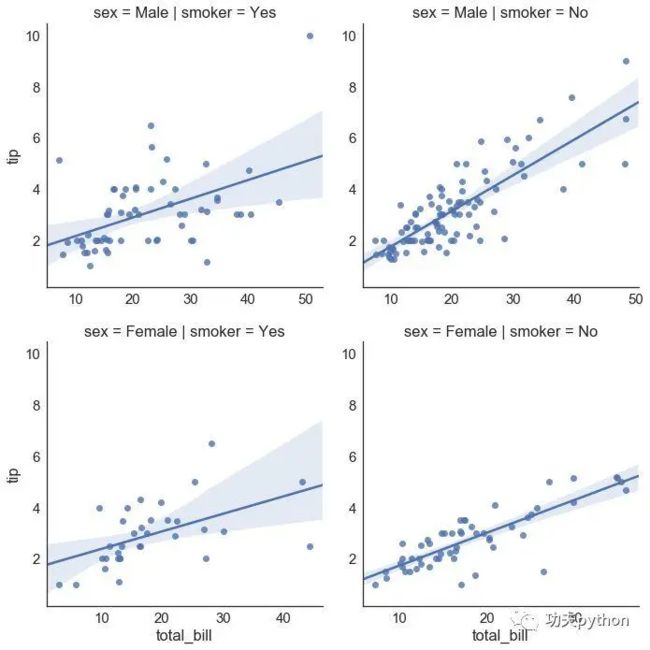
lmplot(回归图)
通过lmplot我们可以直观地总览数据的内在关系
seaborn.lmplot(x, y, data, hue=None, col=None, row=None, palette=None, col_wrap=None, size=5, aspect=1, markers='o', sharex=True, sharey=True, hue_order=None, col_order=None, row_order=None, legend=True, legend_out=True, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=False, x_jitter=None, y_jitter=None, scatter_kws=None, line_kws=None)
- col:根据所指定属性在列上分类
- row:根据所指定属性在行上分类
- col_wrap:指定每行的列数,最多等于col参数所对应的不同类别的数量
- aspect:控制图的长宽比
- sharex:共享x轴刻度(默认为True)
- sharey:共享y轴刻度(默认为True)
- hue:用于分类
- ci:控制回归的置信区间
- x_jitter:给x轴随机增加噪音点
- y_jitter:给y轴随机增加噪音点
- order:控制进行回归的幂次(一次以上即是多项式回归)
sns.lmplot(x="total_bill",y="tip",data=data,row="sex",col="smoker",sharex=False)
#可以看到设置为False时,各个子图的x轴的5#坐标刻度是不一样的
heatmap 热力图
热力图在实际中常用于展示一组变量的相关系数矩阵,在展示列联表的数据分布上也有较大的用途,通过热力图我们可以非常直观地感受到数值大小的差异状况。
seaborn.heatmap(data,vmin=None,vmax=None,cmap=None,center=None,robust=False,annot=None,fmt=.2g,annot_kws=None,linewidths=0,linecolor=white',cbar=True,cbar_kws=None,cbar_ax=None,square=False,xticklabels='auto',yticklabels='auto',mask=None,ax=None,“kwargs)
- vmax:设置颜色带的最大值
- vmin:设置颜色带的最小值
- cmap:设置颜色带的色系
- center:设置颜色带的分界线
- annot:是否显示数值注释
- fmt:format的缩写,设置数值的格式化形式
- linewidths:控制每个小方格之间的间距
- linecolor:控制分割线的颜色
- cbar_kws:关于颜色带的设置
- mask:若为矩阵内为True,则热力图相应的位置的数据将会被屏蔽掉
#导入数据集后按年月两个维度进行数据透视
data=sns.load_dataset("flights")\
.pivot("month","year","passengers")
sns.heatmap(data=data,annot=True,fmt="d",linewidths=0.3,linecolor="grey",cmap="RdBu_r")
#原来的白色间隙变成了灰色间隙

pairplot
pairplot主要展现的是变量两两之间的关系(线性或非线性,有无较为明显的相关关系)
seabom. pairplot(data, hue=None, hue order=None, palette=None, vars=None,x_vars=None, y_vars=None, kind=' scatter, diag kind=' hist, markers=None, size=2.5, aspect=1, dropna=True, plot_kws=None, diag_kws=None, grid_kws=None)
- kind:用于控制非对角线上的图的类型,可选"scatter"与"reg"
- diag_kind:控制对角线上的图的类型,可选"hist"与"kde"
- hue :针对某一字段进行分类
- palette:控制色调
- markers:控制散点的样式
- vars,x_vars,y_vars:选择数据中的特定字段,以list形式传入
- plot_kws:用于控制非对角线上的图的样式
- diag_kws:用于控制对角线上图的样式
#导入seaborn自带iris数据集
data=sns.load_dataset("iris")
#为了方便大家观看,把列名换成中文的
data.rename(columns={"sepal_length":"萼片长",
"sepal_width":"萼片宽",
"petal_length":"花瓣长",
"petal_width":"花瓣宽",
"species":"种类"},inplace=True)
kind_dict = {
"setosa":"山鸢尾",
"versicolor":"杂色鸢尾",
"virginica":"维吉尼亚鸢尾"
}
data["种类"] = data["种类"].map(kind_dict)
data.head() #数据集的内容如下
#不同类别的点会以不同的颜色显现出来
sns.pairplot(data,hue="种类")
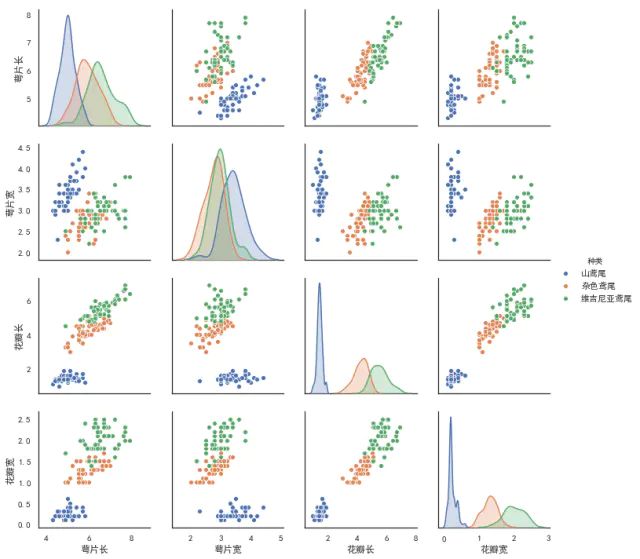
对角线上是各个属性的直方图(分布图),而非对角线上是两个不同属性之间的相关图