- ES聚合查询流程
- 核心概念
2.1 桶
2.2 指标 - ES聚合查询的语法
3.1 聚合查询的size语法 - 指标聚合
4.1 value count
4.2 Cardinality
4.3 avg sum max min
4.4 综合例子 - 分组聚合查询(bucket)
5.1 Terms聚合
5.2 Histogram聚合
5.3 Date histogram聚合
5.4 Range聚合
5.5 混合使用 - 多桶排序
6.1 多桶排序
--6.1.1 内置排序
--6.1.2 按度量排序
6.2 限制返回桶的数量
推荐阅读
ES的聚合查询,类似SQL中sum/avg/count/group by分组查询,主要用于统计分析
1. ES聚合查询流程
ES聚合查询类似SQL的group by,一般统计分析主要分为两个步骤:
- group by分组
- 组内聚合
对查询的数据一般先进行分组,可以设置分组条件。然后将组内的数据进行聚合统计。
2. 核心概念
2.1 桶
满足特定条件的文档集合,叫做桶。
桶的就是一组数据的集合,数据分组后,得到一组组的数据,就是一组组的桶。
桶等同于组,分桶和分组是一个意思。
ES中桶聚合,指的就是先对数据进行分组,ES支持多种分组条件。
2.2 指标
指标指的是对文档进行统计计算的方式,又称指标聚合。
桶内聚合:就是对数据先进行分组(分桶),然后对每一个桶内的数据进行指标聚合。
常见的指标有:sum/count/max/min等统计函数。
3. ES聚合查询的语法
{
"aggregations" : { (1)
"" : { (2)
"" : { (3)
(4)
}
[,"aggregations" : { []+ } ]? // 嵌套聚合查询,支持多层嵌套
}
[,"" : { ... } ]* // 多个聚合查询,每个聚合查询取不同的名字
}
}
(1) aggregations :代表聚合查询语句,可以简写为aggs;
(2)
(3)
(4)

3.1 聚合查询的size语法
size=0代表不需要返回query查询结果,仅仅返回aggs统计结果
GET test_len/_search
{
"size": 0,
"aggs": {
"prices": {
"date_histogram": {
"field": "p_date",
"calendar_interval":"month",
"format": "yyyy-MM-dd"
}
}
}
}
4. 指标聚合
ES指标聚合,就是类型SQL的统计函数,指标聚合可以单独使用,也可以和桶聚合一起使用。
常用的统计函数:
- value count:统计总数;
- Cardinality:类似SQL的count(DISTINCT 字段), 统计不重复的数据总数
- avg:平均值
- sum:求和
- max:最大值
- min:最小值
4.1 value count
值聚合,主要用于统计文档总数。


如上图所示:得到的总数为2个文档。
GET test_len/_search
{
"aggs": {
"price_count": { //名字随便起,聚合查询的名字
"value_count": { //聚合查询的类型
"field": "price" //计算price这个字段的总数
}
}
}
}
4.2 Cardinality
基数聚合,也是用于统计文档的总数,跟value Count的区别是:基数聚合会去重,不会统计重复的值,类似SQL的count(distinct 字段)的用法。
注意:前面提到基数聚合的作用等价于SQL的count(DISTINCT 字段)的用法,其实不太准确,因为SQL的count统计结果是精确统计不会丢失精度,但是ES的cardinality基数聚合统计的总数是一个近似值,会有一定的误差,这么做的目的是为了性能,因为在海量的数据中精确统计总数是非常消耗性能的,但是很多业务场景不需要精确的结果,只要近似值,例如:统计网站一天的访问量,有点误差没关系。
4.3 avg sum max min
avg:求平均值
sum:求和
max:求最大值
min:求最小值
4.4 综合例子
前面的例子,仅仅介绍聚合指标的单独使用的情况,实际应用中经常先通过query查询,搜索索引中的数据,然后对query查询结果进行统计分析。
GET test_len/_search
{
"query": {
"term": {
"p_type": {
"value": "vip"
}
}
},
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
},
"min_price":{
"min": {
"field": "price"
}
}
}
}

5. 分组聚合查询(bucket)
Elasticsearch桶聚合,目的就是数据分组,先将数据按指定的条件分成多个组,然后对每一个组进行统计。 组的概念跟桶是等同的,在ES中统一使用桶(bucket)这个术语。
ES桶聚合的作用跟sql的group by作用是一样的,区别是ES支持更加强大的数据分组能力,SQL只能根据字段的唯一值进行分组,分组的数量跟字段的唯一值的数量相等,例如: group by 店铺id, 去掉重复的店铺ID后,有多少个店铺就有多少个分组。
ES常用的桶聚合如下:
- terms聚合:类似sql的group by,根据字段唯一值分组;
- Histogram(柱状图,
[ˈhɪstəɡræm])聚合:根据数组间隔分组,例如:价格100间隔分组,0,100,200等等; - Date histogram聚合:根据时间间隔分组,例如:按月、天、小时分组;
- Range聚合:按数值范围,例如0-150、150-200一组,200-500一组。
桶聚合一般不单独使用,都是配合指标聚合一起使用,对数据分组之后肯定要统计桶内数据,在ES中如果没有明确指定指标聚合,默认使用Value Count指标聚合,统计桶内文档总数。
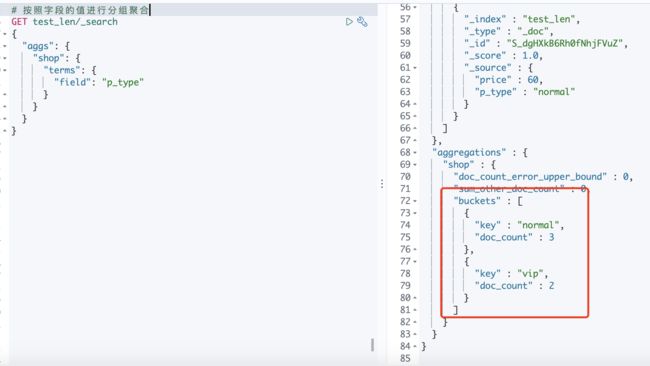
5.1 Terms聚合
terms聚合的作用跟sql中的group by作用一致,都是根据字段唯一值对数据进行分组(分桶),字段值相等的文档都分到同一个桶内。
5.2 Histogram聚合
histogram(直方图)聚合,只要根据数值间隔分组,使用histogram聚合分组统计结果,通常用在绘制条形图报表。
POST test_len/_search?size=0
{
"aggs" : {
"prices" : { // 聚合查询名字,随便取一个
"histogram" : { // 聚合类型为:histogram
"field" : "price", // 根据price字段分桶
"interval" : 50 // 分桶的间隔为50,意思就是price字段值按50间隔分组
}
}
}
}

5.3 Date histogram聚合
类似histogram聚合,区别是Date histogram可以很好的处理时间类型字段,主要用于根据时间、日期分桶的场景。
POST /sales/_search?size=0
{
"aggs" : {
"sales_over_time" : { // 聚合查询名字,随便取一个
"date_histogram" : { // 聚合类型为: date_histogram
"field" : "date", // 根据date字段分组
"calendar_interval" : "month", // 分组间隔:month代表每月、支持minute(每分钟)、hour(每小时)、day(每天)、week(每周)、year(每年)
"format" : "yyyy-MM-dd" // 设置返回结果中桶key的时间格式
}
}
}
}
返回结果:
{
...
"aggregations": {
"sales_over_time": { // 聚合查询名字
"buckets": [ // 桶聚合结果
{
"key_as_string": "2015-01-01", // 每个桶key的字符串标识,格式由format指定
"key": 1420070400000, // key的具体字段值
"doc_count": 3 // 默认按Value Count指标聚合,统计桶内文档总数
},
{
"key_as_string": "2015-02-01",
"key": 1422748800000,
"doc_count": 2
},
{
"key_as_string": "2015-03-01",
"key": 1425168000000,
"doc_count": 2
}
]
}
}
}
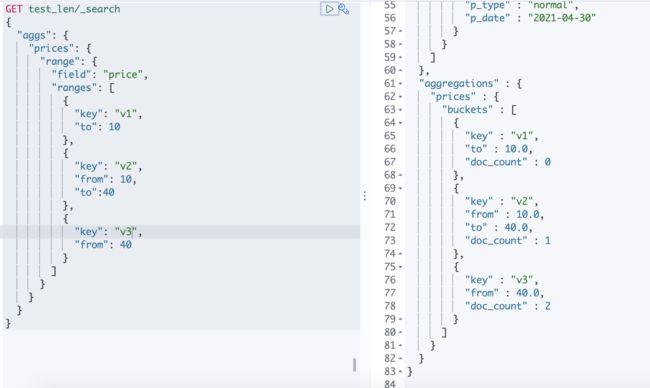
5.4 Range聚合
GET /_search
{
"aggs" : {
"price_ranges" : { // 聚合查询名字,随便取一个
"range" : { // 聚合类型为: range
"field" : "price", // 根据price字段分桶
"ranges" : [ // 范围配置
{ "to" : 100.0 }, // 意思就是 price < 100的文档归类到一个桶
{ "from" : 100.0, "to" : 200.0 }, // price>=100 and price<200的文档归类到一个桶
{ "from" : 200.0 } // price>=200的文档归类到一个桶
]
}
}
}
}
返回结果:
{
...
"aggregations": {
"price_ranges" : { // 聚合查询名字
"buckets": [ // 桶聚合结果
{
"key": "*-100.0", // key可以表达分桶的范围
"to": 100.0, // 结束值
"doc_count": 2 // 默认按Value Count指标聚合,统计桶内文档总数
},
{
"key": "100.0-200.0",
"from": 100.0, // 起始值
"to": 200.0, // 结束值
"doc_count": 2
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3
}
]
}
}
}
可以发现,range分桶,默认key的值不友好。尤其是开发的时候,不知道key是什么样子,处理比较麻烦,可以为每一个分桶指定一个有意义的名字。
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"keyed" : true,
"ranges" : [
// 通过key参数,配置每一个分桶的名字
{ "key" : "cheap", "to" : 100 },
{ "key" : "average", "from" : 100, "to" : 200 },
{ "key" : "expensive", "from" : 200 }
]
}
}
}
}
5.5 混合使用
实际开发中,经常需要配合query语句,先搜索目标文档,然后使用aggs聚合语句对搜索结果进行统计分析。
聚合查询支持多层嵌套。
GET /cars/_search
{
"size": 0, // size=0代表不需要返回query查询结果,仅仅返回aggs统计结果
"query" : { // 设置查询语句,先赛选文档
"match" : {
"make" : "ford"
}
},
"aggs" : { // 然后对query搜索的结果,进行统计
"colors" : { // 聚合查询名字
"terms" : { // 聚合类型为:terms 先分桶
"field" : "color"
},
"aggs": { // 通过嵌套聚合查询,设置桶内指标聚合条件
"avg_price": { // 聚合查询名字
"avg": { // 聚合类型为: avg指标聚合
"field": "price" // 根据price字段计算平均值
}
},
"sum_price": { // 聚合查询名字
"sum": { // 聚合类型为: sum指标聚合
"field": "price" // 根据price字段求和
}
}
}
}
}
}
6. 多桶排序
类似terms、histogram、date_histogram这类桶聚合都会动态生成多个桶,如果生成的桶特别多,我们如何确定这些桶的排序顺序,如何限制返回桶的数量。
6.1 多桶排序
默认情况下,ES会根据doc_count文档总数,降序排序。
ES桶聚合支持两种方式排序:
- 内置排序;
- 按度量指标排序;
6.1.1 内置排序
内置排序参数:
- _count :按文档数排序,对terms、histogram、date_histogram有效;
- _term:按次项的字符串值的字母顺序排序,只在terms内使用;
- _key:按每个桶的键值数值排序,仅对histogram和date_histogram有效;
GET /cars/_search
{
"size" : 0,
"aggs" : {
"colors" : { // 聚合查询名字,随便取一个
"terms" : { // 聚合类型为: terms
"field" : "color",
"order": { // 设置排序参数
"_count" : "asc" // 根据_count排序,asc升序,desc降序
}
}
}
}
}
6.1.2 按度量排序
通常情况下,我们根据桶聚合分桶后,都会对桶内进行多个维度的指标聚合,所以我们也可以根据桶内指标聚合的结果进行排序。
GET /cars/_search
{
"size" : 0,
"aggs" : {
"colors" : { // 聚合查询名字
"terms" : { // 聚合类型: terms,先分桶
"field" : "color", // 分桶字段为color
"order": { // 设置排序参数
"avg_price" : "asc" // 根据avg_price指标聚合结果,升序排序。
}
},
"aggs": { // 嵌套聚合查询,设置桶内聚合指标
"avg_price": { // 聚合查询名字,前面排序引用的就是这个名字
"avg": {"field": "price"} // 计算price字段平均值
}
}
}
}
}
6.2 限制返回桶的数量
如果分桶数量太多,可以通过给桶聚合增加一个size参数限制返回桶的数量。
GET /_search
{
"aggs" : {
"products" : { // 聚合查询名字
"terms" : { // 聚合类型为: terms
"field" : "product", // 根据product字段分桶
"size" : 5 // 限制最多返回5个桶
}
}
}
}
推荐阅读
Elasticsearch笔记(七):聚合查询
Elasticsearch 聚合查询(aggs)基本概念