概述
本篇文章主要介绍如何使用Storm + spark + Kafka 实现实时数据的计算,并且使用高德地图API实现热力图的展示。
背景知识:
在有些场合,我们需要了解当前人口的流动情况,比如,需要实时监控一些旅游景点旅客的密集程度,这时可以使用GPS定位系统将该区域内旅客的IP数据进行计算,但是GPS定位系统也有一定的缺点,不是每个旅客都会GPS功能,这时可以使用“信令”来获取个人定位信息。所谓“信令”就是每个手机会不是的向附近最近的基站发送定位信息,除非手机关机。相信每个人在做车旅游的时候每经过一个地方都会受到某个地区的短信,“某某城市欢迎你的来访”等信息,移动电信应用就是利用“信令”来监控每个的定位信息。(同时也可以看出大数据下个人隐私很难受到保护)。
1. 项目架构
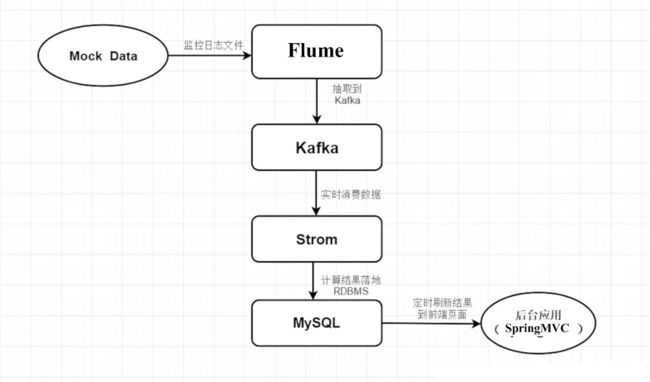
在这里我们使用了 flume来抽取日志数据,使用 Python 模拟数据。在经过 flume 将数据抽取到 Kafka 中,Strom 会实时消费数据,然后计算结果实时写入 MySQL数据库中,然后我们可以将结果送到后台应用中使用和可视化展示。
2. 环境以及软件说明
- storm-0.9.7
- zookeeper-3.4.5
- flume
- kafka_2.11-0.9.0.0
实战
第一步、模拟数据(python)
#coding=UTF-8
import random
import time
phone=[
"13869555210",
"18542360152",
"15422556663",
"18852487210",
"13993584664",
"18754366522",
"15222436542",
"13369568452",
"13893556666",
"15366698558"
]
location=[
"116.191031, 39.988585",
"116.389275, 39.925818",
"116.287444, 39.810742",
"116.481707, 39.940089",
"116.410588, 39.880172",
"116.394816, 39.91181",
"116.416002, 39.952917"
]
def sample_phone():
return random.sample(phone,1)[0]
def sample_location():
return random.sample(location, 1)[0]
def generator_log(count=10):
time_str=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
f=open("/opt/log.txt","a+")
while count>=1:
query_log="{phone}\t{location}\t{date}".format(phone=sample_phone(),location=sample_location(),date=time_str)
f.write(query_log+"\n")
# print query_log
count=count-1
if __name__=='__main__':
generator_log(100)
将模拟出的数据导出:
打开pycharm,然后选中自己的项目名,鼠标右键,选择“show in Explorer”
然后,将导出的数据代码上传到集群中。
第二步、Flume 配置
在Flume安装目录下添加配置文件 kafka-loggen.conf:
agent.sources = s1
agent.channels = c1
agent.sinks = k1
agent.sources.s1.type=exec
agent.sources.s1.command=tail -F /opt/log.txt
agent.sources.s1.channels=c1
agent.channels.c1.type=memory
agent.channels.c1.capacity=10000
agent.channels.c1.transactionCapacity=100
#设置Kafka接收器
agent.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口号
agent.sinks.k1.brokerList=hadoop01:9092,hadoop02:9092,hadoop03:9092
#设置Kafka的Topic
agent.sinks.k1.topic=kafka5
#设置序列化方式
agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder
agent.sinks.k1.channel=c1
注意:上面配置中path指定读取数据的文件,可自行创建。topic_id 参数为下文kafka中需要创建的 topic主题。
第三步,启动集群
1、将python脚本放到hadoop3里面,然后运行一下脚本,看看是否是好的,如果能出来结果,就继续下面步骤,如果不行,就检查python脚本
python Analog_data.py
2.启动zookeeper
zkServer.sh start
然后,检查一下zookeeper的启动状态。
zkServer.sh status
如下图:

3、启动kafka
kafka-server-start.sh /opt/modules/app/kafka/config/server.properties
4、启动flume
在flume目录下
#代码中kafka-loggen.conf是在/opt/modules/app/flume/conf中创建的文件
./bin/flume-ng agent -n agent -c conf -f conf/kafka-loggen.conf -Dflume.root.logger=INFO,console
5、创建一个flume里面定义的topic
#代码中的kafka5 是/opt/modules/app/flume/conf/中的kafka-loggen.conf文件里面的agent.sinks.k1.topic
kafka-topics.sh --create --zookeeper hadoop02:2181 --replication-factor 1 --partitions 1 --topic kafka5
6、开启消费者,消费内容
kafka-console-consumer.sh --zookeeper hadoop02:2181 -from-beginning --topic kafka5
7、执行python脚本
python Analog_data.py
第四步、spark程序编写
1、停止消费者消费
按ctrl+c强制退出
2、离开hdfs的安全模式
hdfs dfsadmin -safemode leave
3、在Intellij上面写java代码,连接hadoop02上面的flume日志上面的数据
import kafka.serializer.StringDecoder
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.SparkConf
/**
* Created by Administrator on 2019/3/7.
*/
object Kafkademo {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("Kafkademo").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("hdfs://hadoop02:8020/spark_check_point")
//kafka的topic集合,即可以订阅多个topic,args传参的时候用,隔开
val topicsSet = Set("kafka5")
//设置kafka参数,定义brokers集合
val kafkaParams = Map[String, String]("metadata.broker.list" -> "192.168.159.133:9092,192.168.159.130:9092,192.168.159.134:9092")
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
print("---------:" +messages)
val lines = messages.map(_._2)
// val words = lines.flatMap(_.split(" "))
// val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
lines.print()
ssc.start()
ssc.awaitTermination()
}
}
第五步、连接数据库
1、启动MySQL数据连接,然后新建一个数据库。例:strom数据库
2、创建一个新表
CREATE TABLE `location` (
`time` bigint(20) NULL ,
`latitude` double NULL ,
`longtitude` double NULL
);
3、在连接数据库之前,需要在pom.xml中添加maven依赖
mysql
mysql-connector-java
5.1.47
4、在intellij连接数据库
package com.neusoft
import java.sql
import java.sql.DriverManager
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.SparkConf
/**
* Created by Administrator on 2019/3/7.
*/
object Kafkademo {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("hdfs://hadoop3:8020/spark_check_point")
//kafka的topic集合,即可以订阅多个topic,args传参的时候用,隔开
val topicsSet = Set("ss_kafka")
//设置kafka参数,定义brokers集合
val kafkaParams = Map[String, String]("metadata.broker.list" -> "192.168.159.133:9092,192.168.159.130:9092,192.168.159.134:9092")
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
print("---------:" +messages)
val lines = messages.map(_._2)
lines.foreachRDD(rdd => {
//内部函数
def func(records: Iterator[String]) {
var conn: sql.Connection = null
var stmt: sql.PreparedStatement = null
try {
val url = "jdbc:mysql://localhost:3306/test"
val user = "root"
val password = "root" //笔者设置的数据库密码是hadoop,请改成你自己的mysql数据库密码
conn = DriverManager.getConnection(url, user, password)
// 13893556666 116.191031, 39.988585 2019-03-08 05:26:12
records.foreach(p => {
val arr = p.split("\\t")
val phoneno = arr(0)
val jingwei = arr(1)
var arrjingwei = jingwei.split(",")
//wei,jing
var sql = "insert into location(time,latitude,longtitude) values (?,?,?)"
stmt = conn.prepareStatement(sql);
stmt.setLong(1, new Date().getTime)
stmt.setDouble(2,java.lang.Double.parseDouble(arrjingwei(0).trim))
stmt.setDouble(3,java.lang.Double.parseDouble(arrjingwei(1).trim))
stmt.executeUpdate()
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (stmt != null) {
stmt.close()
}
if (conn != null) {
conn.close()
}
}
}
val repartitionedRDD = rdd.repartition(1)
repartitionedRDD.foreachPartition(func)
})
ssc.start()
ssc.awaitTermination()
}
}
5、再次运行python脚本生成数据
python Analog_data.py
6、查看数据库是否出现数据。
如果出现下图,代表成功。

所有需要的maven依赖:
4.0.0
storm-kafka-mysql
storm-kafka-mysql
0.0.1-SNAPSHOT
jar
storm-kafka-mysql
UTF-8
javax
javaee-api
8.0
provided
org.glassfish.web
javax.servlet.jsp.jstl
1.2.2
org.apache.storm
storm-core
0.9.5
org.apache.storm
storm-kafka
0.9.5
org.apache.kafka
kafka_2.11
0.8.2.0
org.apache.zookeeper
zookeeper
log4j
log4j
mysql
mysql-connector-java
5.1.31
maven-compiler-plugin
2.3.2
1.7
1.7
未完待续