HashMap和Hashtable的区别:(HashMap是Hashtable的轻量级实现)
1最主要的区别就是:hashtable是线程安全的,而hashmap是非线程安全的(hashtable里面的方法都添加了synchronized关键字来确保线程同步。(2)hashtable是不允许key和value为null的,但是hashmap就可以。(3)Hashtable和HashMap扩容的方法不一样,HashTable中hash数组默认大小11,扩容方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数,增加为原来的2倍,没有加1、(4)两者通过hash值散列到hash表的算法不一样,HashTbale是古老的除留余数法,直接使用hashcode,而后者是强制容量为2的幂,重新根据hashcode计算hash值,在使用hash 位与 (hash表长度 – 1),也等价取膜,但更加高效,取得的位置更加分散,偶数,奇数保证了都会分散到。前者就不能保证。
JDK8 对hashmap进行了重新整理,并且还能引出红黑树。
2 hashmap 的源码就是数组+链表:数组中存的是
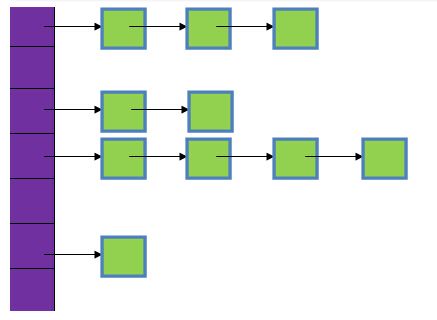
说一下HashMap的流程:首先根据key.hashcode()算出hash值,然后根据hash得出下角标index,这样就避免了一个一个去找。如果index相同的话,就会在链表中查找。hash值和索引值的两个方法是HashMap最为核心的部分,二者能保证哈希表的元素均匀的分布。
HashMap的扩容机制:hashmap的构造器里指明了两个对于理解HashMap比较重要的两个参数 int initialCapacity, float loadFactor,这两个参数会影响HashMap效率。HashMap底层采用散列数组实现,利用initialCapacity来设置数组的大小,也就是散列桶的大小。在不断add后,这些桶可能被沾满了,利用每个桶附带的链表增加元素,但是有个缺点,他会退化成LinkedList,使get和put方法时间开销上升。但是HashMap 采用了增加桶的数量,这样get和put 又回到近于常数的复杂度上。关于扩容reSize(),它会新建一个HashMap,然后将旧的hashmap中的元素添加到新的HashMap中。可以看出,扩容是一件相当耗时的操作。需要重新计算这些元素在新的数组中的位置并进行复制处理。
HashMap什么时候回增加容量呢?因为效率问题,JDK采用了预加载方式,当size > initialCapacity * loadFactor,hashmap就会调用内部的reSize方法。
如果key 为null,就会直接在哈希表的第一个位置table[0]对应的链表上面查找。
如果put时,hash值相同产生冲突时,就会使用头插法,将该元素插入到该下标的链表第一个位置,后面的依次往后移。
HashMap和ConcurrentHashMap的区别:
ConcurrentHashMap:在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁的几率,提高并发效率。
TreeMap、HashMap、LindedHashMap的区别:
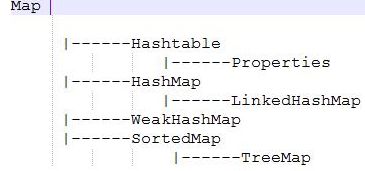
TreeMap:实现了SortMap接口,能够把他保存的记录根据键值排序,默认是按键值的升序排序,也可以比较器,当用iterator遍历TreeMap时,得到的记录是排过序的。注意,此实现不是同步的。需要外部同步。一般是通过对自然封装该映射的对象执行同步操作来完成的。可以通过这样来进行封装:(下面这两种集合也可以通过这种方式进行封装)
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
HashMap:键和值都可以为空,不保证映射的顺序,多次访问,映射的顺序可能不一样,非线程安全
LinkedHashMap:内部维持了一个双向链表,可以保持顺序。保存了记录的插入顺序,在iterator遍历LinkedHashMap时,先得到的肯定是先插入的。在遍历的时候可能比HashMap慢,不过有一种情况,当HashMap的容量特别大,但是实际数据比较小时,遍历起来可能比LinkedHashMap慢。因为LinkedHashMap只和他的实际数据有关,而HashMap和他的容量有关。
使用场景:一般情况下,我们用的最多的是HashMapHashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。 TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。 LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
Collection包结构,与Collections的区别:
Collection是集合继承结构中的顶层接口
Collections 是提供了对集合进行操作的强大方法的工具类 ,它包含有各种有关集合操作的静态多态方法。此类不能实例化
try catch finally,try里有return,finally还执行么?(总之 finally 永远执行!)
Condition 1:如果try中没有异常且try中有return(执行顺序)try----finally---return
Condition 2:如果try中有异常并且try中有return :try----catch---finally---return
Condition 3:try中有异常,try-catch-finally里都没有return ,finally 之后有个return:try----catch---finally try中有异常以后,根据java的异常机制先执行catch后执行finally,此时错误异常已经抛出,程序因异常而终止,所以你的return是不会执行的
Condition 4:当 try和finally中都有return时,finally中的return会覆盖掉其它位置的return(多个return会报unreachable code,编译不会通过)。
Condition 5:当finally中不存在return,而catch中存在return,但finally中要修改catch中return 的变量值时
int ret =0;
try{thrownewException();
}catch(Exceptione)
{
ret =1;returnret;
}finally{
ret =2;
}
最后返回值是1,因为return的值在执行finally之前已经确定下来了
Excption与Error包结构。OOM你遇到过哪些情况,SOF你遇到过哪些情况:

SOF:StackOverflowError,(堆栈溢出)当应用程序递归太深而发生堆栈溢出,以为一般默认为1-2m,一旦出现死循环或者大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。原因有:递归调用,大量循环或者死循环,全局变量是否过多,数组、list、map数据过大
android的OOM(out of Memory)当内存占有量超过了虚拟机的分配最大值就会发生OOM(VM分配不出更多的page),一般出现这种情况:加载的图片太多或者太大,分配特大的数组,内存相应资源过多来不及释放。
java多态的实现原理
方法的重载和方法的复写都是多态的表现。
同一个类的不同表现形式,不同的形态是通过不同的子类体现,java通过将子类对象引用赋值给超类对象变量,来实现动态方法调用。
多态允许具体访问时实现方法的动态绑定,java对于动态绑定的实现主要依赖方法表。通过继承和接口的多态实现有所不同。
继承:在执行某个方法时,在方法区找到该类的方法表,再确认该方法在方法表中的偏移量。找到该方法后如果被重写则直接调用,否则没有重写父类该方法,这时会按照继承关系搜索父类的方法表中该偏移量对应的方法。
接口:java允许一个类实现多个接口,从某种意义上说相当于多继承,这样同一个的方法在不同类中方法表的位置就不一样了。所以不能通过偏移量的方法,而是通过搜索整个完整的方法表。
JVM结构:
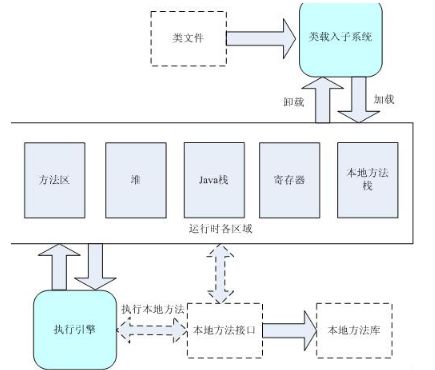
并在方法区建立该类的类型信息(包括方法代码、类变量、成员变量、以及方法表)。注意:这个方法区中的类型信息跟堆中存放的class对象是不同的。在方法区中,这个class的类型信息只有唯一的实例(所以方法区是各个线程共享的内存区域)。而在堆中可以有多个该class对象,可以通过堆中的class对象方法到方法区中的类型信息。就像在java反射机制那样,通过class对象可以访问到该类的所有信息一样。【重点】方法表是实现动态调用的核心,为了优化对象调用方法的速度,方法区的类型信息会增加一个指针,该指针指向记录该类方法的方法表,方法表中的每一项都是对应方法的指针,这些方法中包括从父类继承的所有方法以及自身重写的方法。
java的方法调用方式:动态方法调用和静态方法调用。静态方法调用是指对于类的静态方法的调用方式,是静态绑定的。而动态方法调用需要有方法调用所作用的对象、是动态绑定的。类调用时在编译时就已经确定调用方法的情况。实例调用时在调用的时候才确定的具体方法的调用方法。这就是动态绑定,也是多态要解决的核心问题。JVM的方法调用指令有四个,分别是invokestatic,invokespecial,invokesvirtual和invokeinterface。前两个是静态绑定,后两个是动态绑定的。本文也可以说是对于JVM后两种调用实现的考察
如果子类改写了父类的方法,那么子类和父类的那些同名的方法共享一个方法表项。因此,方法表的偏移量总是固定的。所有继承父类的子类的方法表中,其父类所定义的方法的偏移量也总是一个定值。Person或Object中的任意一个方法,在它们的方法表和其子类Girl和Boy的方法表中的位置 (index) 是一样的。这样JVM在调用实例方法其实只需要指定调用方法表中的第几个方法即可。

(1)在常量池(这里有个错误,上图为ClassReference常量池而非Party的常量池)中找到方法调用的符号引用。
(2)查看Person的方法表,得到speak方法在该方法表的偏移量(假设为15),这样就得到该方法的直接引用。
(3)根据this指针得到具体的对象(即 girl 所指向的位于堆中的对象)。
(4)根据对象得到该对象对应的方法表,根据偏移量15查看有无重写(override)该方法,如果重写,则可以直接调用(Girl的方法表的speak项指向自身的方法而非父类);如果没有重写,则需要拿到按照继承关系从下往上的基类(这里是Person类)的方法表,同样按照这个偏移量15查看有无该方法。
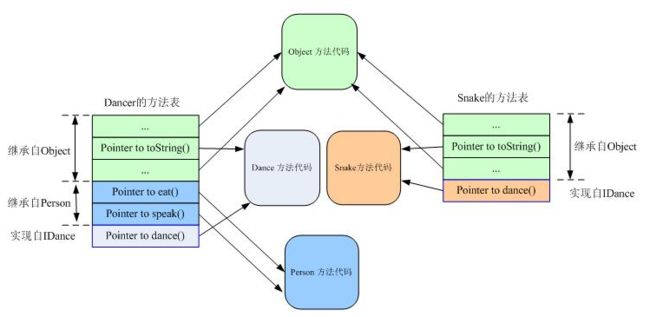
可以看到,由于接口的介入,继承自接口 IDance 的方法 dance()在类 Dancer 和 Snake 的方法表中的位置已经不一样了,显然我们无法仅根据偏移量来进行方法的调用。
Java 对于接口方法的调用是采用搜索方法表的方式,如,要在Dancer的方法表中找到dance()方法,必须搜索Dancer的整个方法表。
因为每次接口调用都要搜索方法表,所以从效率上来说,接口方法的调用总是慢于类方法的调用的。