2021白酒还能买吗?答案是...【python股价趋势预测实战】
前言
白酒股在经历2020年大幅上涨之后,2021年白酒股还能继续涨吗?炙手可热的白酒股还能买吗?
今天我们就通过股价趋势预测告诉你答案,请仔细看!

我们使用的baostock来获取股票信息,可视化它们的不同,通过一些方法来分析股票的风险。将通过长期短期记忆(LSTM)方法来预测未来的股票价格。
本文从如下几个方面展开:
- 一段时间内股票价格的变化?
- 股票的平均日回报率?
- 各种股票的移动平均线?
- 不同股票之间的相关性?
- 我们投资某只股票的风险?
- 我们如何预测未来的股票行为呢?(使用LSTM预测贵州茅台的收盘价)
预测股票趋势,要历史的各类交易价格数据来进行模型的搭建。“历史惊人的相似”是股票趋势判断问题的重要假设。
我们的想法是,股票某一天的交易价格受到该交易日前面的许多交易日的影响,而股价的确定则是由买卖市场双方共同决定的。当我们收盘股票数据集时,应该将多个开盘日归入参考范畴。
本文将前 N 个交易日作为一个时间窗口,并设为训练集,将第 N+1 个交易日作为测试集,预测测第 N+2 个交易日的股票趋势情况。
通过滑动窗口的方法,设每次滑动窗口移动的距离为 1(即 1 天),则在初始 T 个交易日上能够构造多个训练集和测试集,且训练样本的数据始终等于 N。
导入需要用到的模块
首先为了故事进展的顺利,我们先导入需要的包。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid')
plt.style.use("fivethirtyeight")
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
%matplotlib inline
from datetime import datetime
import baostock as bs
定义获取股市数据函数
def get_data(code):
end = datetime.now()
start = datetime(end.year - 1, end.month, end.day).strftime('%Y-%m-%d')
end = end.strftime('%Y-%m-%d')
# 登陆系统
lg = bs.login()
# 获取沪深A股历史K线数据
rs_result = bs.query_history_k_data_plus(
code,
fields="date,open,high,low,close,volume",
start_date=start,
end_date=end,
frequency="d",
adjustflag="3")
df_result = rs_result.get_data()
# 登出系统
bs.logout()
df_result['date'] = df_result['date'].map
lambda x: datetime.strptime(x,'%Y-%m-%d'))
_res = df_result.set_index('date')
res = _res.applymap(lambda x: float(x))
return res
接着选择四个白酒股票近一年内的历史交易数据,分别为贵州茅台,五粮液, 洋河股份,山西汾酒。其股票代码分别是sh.600519, sz.000858, sz.002304, sh.600809。
liquor_list = ['sh.600519', 'sz.000858',
'sz.002304', 'sh.600809']
# 贵州茅台,五粮液, 洋河股份,山西汾酒
company_name = ['maotai','wuliangye','yanghe','fenjiu']
for name, code in zip(company_name ,liquor_list):
exec(f"{
name}=get_data(code)")
注意这里使用高阶函数exec进行批量赋值。
# 需要批量赋值的变量名称
company_list = [maotai, wuliangye, yanghe, fenjiu]
for company, com_name in zip(company_list, company_name):
company["company_name"] = com_name
# 将四支股票数据进行纵向合并
df = pd.concat(company_list, axis=0)
df.tail(10)
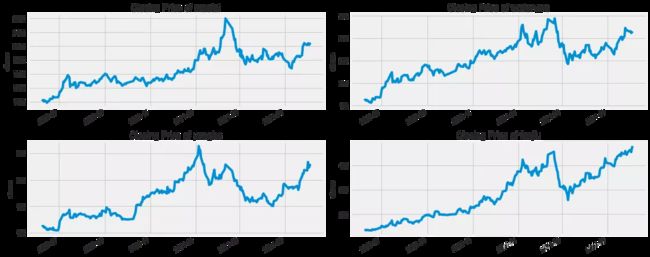
历史收盘价
绘制四支股票的历史收盘价,从历史收盘价格趋势图大致可以看出,四支股票的趋势很相似。
plt.figure(figsize=(15, 6))
plt.subplots_adjust(top=1.25, bottom=1.2)
for i, company in enumerate(company_list, 1):
plt.subplot(2, 2, i)
company['close'].plot()
plt.ylabel('close')
plt.xlabel(None)
plt.title(f"Closing Price of {
company_name[i - 1]}")
plt.tight_layout()
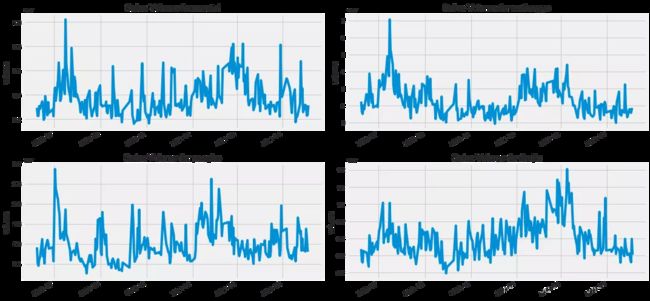
每日交易量
现在我们画出每天的股票交易量,根据交易量来进一步分析,感兴趣的小伙伴们可以研究研究。
plt.figure(figsize=(15, 7))
plt.subplots_adjust(top=1.25, bottom=1.2)
for i, company in enumerate(company_list, 1):
plt.subplot(2, 2, i)
company['volume'].plot()
plt.ylabel('volume')
plt.xlabel(None)
plt.title(f"Sales Volume for {
company_name[i - 1]}")
plt.tight_layout()
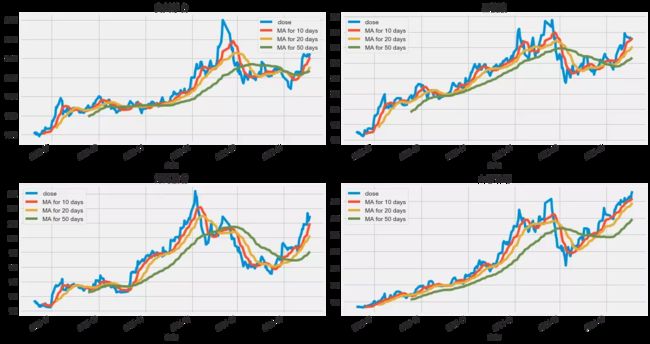
我们已经看到了可视化的每日收盘价和成交量,接下来就是要计算股票的移动平均线。
各股票的移动平均线
移动平均算法(MigAeage)是一种典型的处理时间序列数据的算法模型,而股票的价格跟着时间不断变化的一种数据,是典型的时间序列数据,因此利用移动平均算法对股票价格进行预测是股票趋势预测研究中最基础也是最典型的模型。
移动平均算法的核心思想是利用前一阶段的真实的数据值,依次利用特定的公式计算一定范围内的所考虑项目的随机机值,例如在股票趋势预测中是股票的价格,因此在具有周期性或者波动性较大的应用场景中,移动平均的实际结果准确率会受到一定的影响。
# 设置移动天数
ma_day = [10, 20, 50]
for ma in ma_day:
for company in company_list:
column_name = f"MA for {
ma} days"
company[column_name] = company['close'].rolling(ma).mean()
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_figheight(8)
fig.set_figwidth(15)
maotai[['close', 'MA for 10 days', 'MA for 20 days', 'MA for 50 days']].plot(ax=axes[0,0])
axes[0,0].set_title('贵州茅台')
wuliangye[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[0,1])
axes[0,1].set_title('五粮液')
yanghe[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[1,0])
axes[1,0].set_title('洋河股份')
fenjiu[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[1,1])
axes[1,1].set_title('山西汾酒')
fig.tight_layout()
股票的平均日回报率
我们上面已经完成了基本分析,现在进一步深入研究。来分析一下股票的风险。这里需要仔细观察股票的每日变化趋势。使用pct_change来查找每天的百分比变化。
for company in company_list:
company['Daily Return'] = company['close'].pct_change()
# 画出日收益率
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_figheight(8)
fig.set_figwidth(15)
maotai['Daily Return'].plot(ax=axes[0,0], legend=True,
linestyle='--', marker='o')
axes[0,0].set_title('贵州茅台')
wuliangye['Daily Return'].plot(ax=axes[0,1], legend=True,
linestyle='--', marker='o')
axes[0,1].set_title('五粮液')
yanghe['Daily Return'].plot(ax=axes[1,0], legend=True,
linestyle='--', marker='o')
axes[1,0].set_title('洋河股份')
fenjiu['Daily Return'].plot(ax=axes[1,1], legend=True,
linestyle='--', marker='o')
axes[1,1].set_title('山西汾酒')
fig.tight_layout()
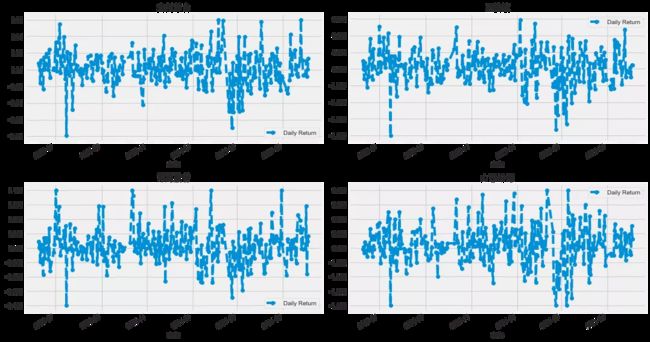
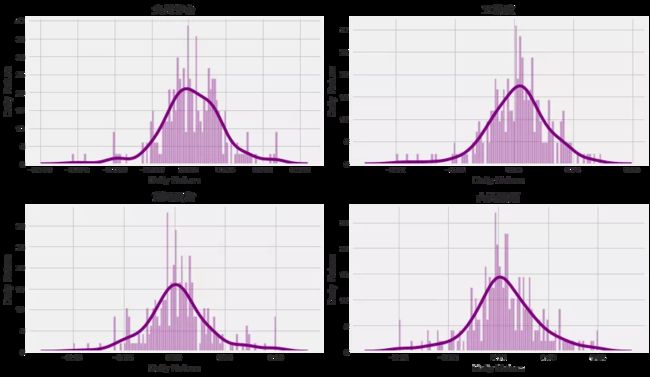
现在用直方图来全面看看平均日收益。可以用seaborn在同一图上创建直方图和kde图。
# 注意这里使用了dropna(),否则seaborn无法读取NaN值
plt.figure(figsize=(12, 7))
company_name_c = ['贵州茅台','五粮液','洋河股份','山西汾酒']
for i, company in enumerate(company_list, 1):
plt.subplot(2, 2, i)
sns.distplot(company['Daily Return'].dropna(), bins=100, color='purple')
plt.ylabel('Daily Return')
plt.title(f'{
company_name_c[i - 1]}')
# 也可以这样绘制
# maotai['Daily Return'].hist()
plt.tight_layout();
股票收盘价之间的相关性
接下来如果要分析列表中所有股票的回报怎么办呢?
把每个股票数据框构建一个包含所有[‘Close’]列的DataFrame,再把所有的收盘价为白酒股列表到一个DataFrame内。
index = maotai.index
closing_df = pd.DataFrame()
for company, company_n in zip(company_list,company_name_c):
temp_df = pd.DataFrame(index=company.index,
data = company['close'].values ,
columns=[company_n])
closing_df = pd.concat([closing_df,temp_df],axis=1)
# 看看数据
closing_df.head()
现在已经有了所有的收盘价,继续获取所有股票的日回报,就像对茅台股票做的那样。
liquor_rets = closing_df.pct_change()
liquor_rets.head()
现在可以比较两支股票的日收益率来检验相关性。
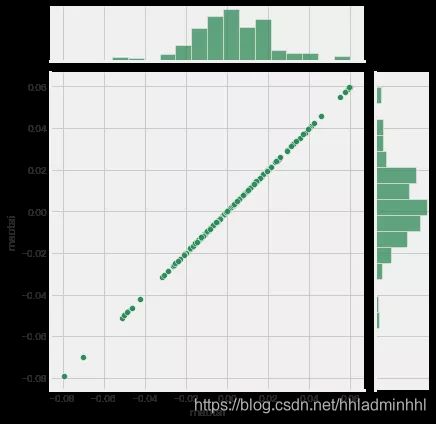
首先让我们看一只股票和它本身的比较。将贵州茅台股票与自身进行比较,应该会显示出一个完美的线性关系。
sns.jointplot('maotai', 'maotai',
tech_rets, kind='scatter',
color='seagreen')
我们将使用joinplot来比较贵州茅台和五粮液的日收益。
sns.jointplot('贵州茅台', '五粮液',
liquor_rets, kind='scatter')
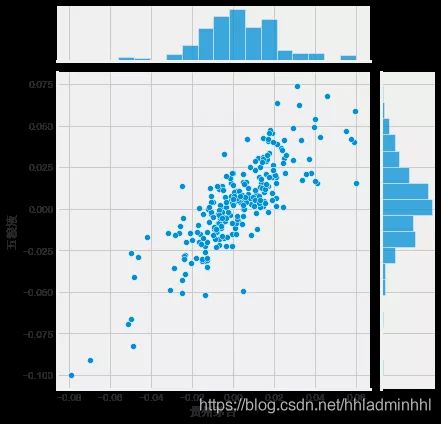
因此,现在可以看到,如果两个股票是完全(和正的)相互相关,它的日回报值之间的线性关系应该发生。
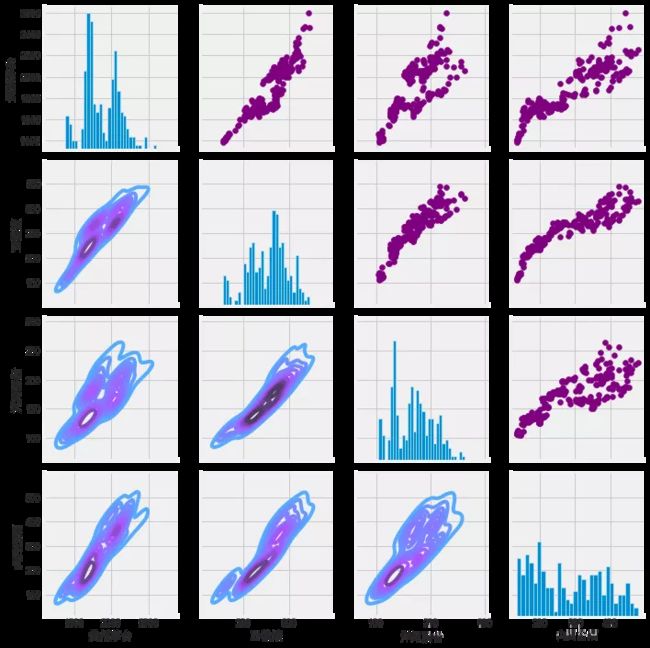
Seaborn和pandas使得我们很容易对我们的技术股票行情列表中的每一个可能的股票组合重复这种比较分析。我们可以使用sns.pairplot() 自动创建这个绘图。简单地调用DataFrame上的pairplot来对所有比较进行自动可视化分析。
sns.pairplot(liquor_rets, kind='reg')
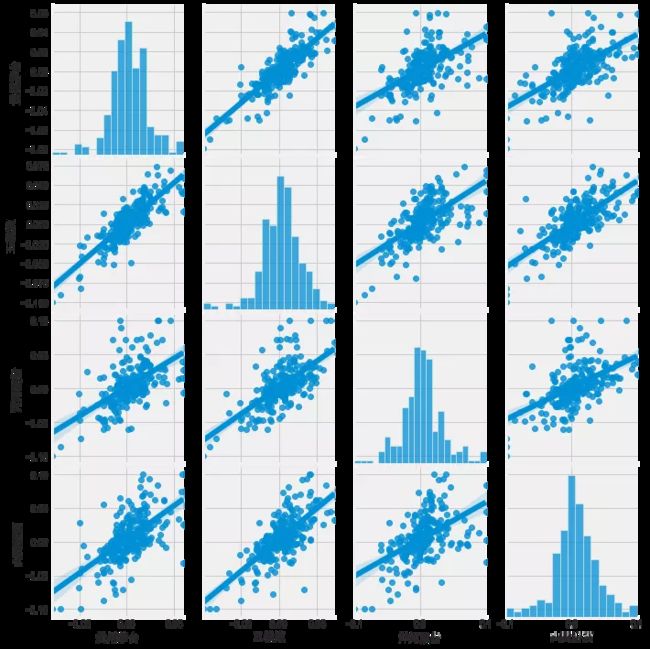
上面我们可以看到所有股票之间的日回报关系。贵州茅台和五粮液日收益之间都是有关联的。
虽然仅仅调用sns.pairplot()非常简单,但也可以使用sns.pairgrid()来完全控制图形,包括对角线上的哪种图、上三角形和下三角形。下面是一个充分利用seaborn的力量来实现这一结果的例子。
# 通过命名为returns_fig来设置我们的图形,
# 在DataFrame上调用PairPLot
return_fig = sns.PairGrid(liquor_rets.dropna())
# 使用map_upper,我们可以指定上面的三角形是什么样的。
return_fig.map_upper(plt.scatter, color='purple')
# 我们还可以定义图中较低的三角形,
# 包括绘图类型(kde)或颜色映射(blueppurple)
return_fig.map_lower(sns.kdeplot, cmap='cool_d')
# 最后,我们将把对角线定义为每日收益的一系列直方图
return_fig.map_diag(plt.hist, bins=30)
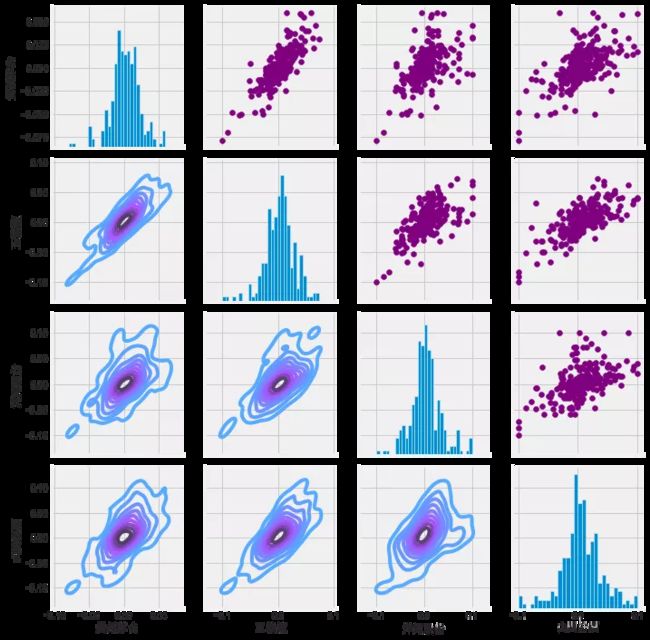
使用同样的方法,绘制四支股票的收盘价相关图。
returns_fig = sns.PairGrid(closing_df)
returns_fig.map_upper(plt.scatter,color='purple')
returns_fig.map_lower(sns.kdeplot,cmap='cool_d')
returns_fig.map_diag(plt.hist,bins=30)
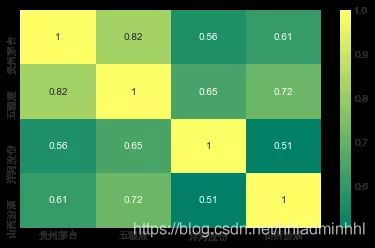
当然了,我们还可以做一个相关图,得到股票日收益值之间的相关性的实际数值。通过比较收盘价格,我们发现了茅台和五粮液之间有趣的关系。
# 让我们用sebron来做一个每日收益的快速相关图
sns.heatmap(liquor_rets.corr(),
annot=True, cmap='summer')
sns.heatmap(closing_df.corr(),
annot=True, cmap='summer')
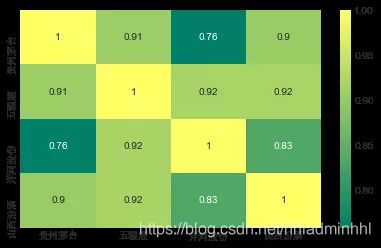
这也验证了前面的分析,从数字和视觉上看到五粮液和其他几个白酒股票收益率有最强的相关性。有趣的是,所有的白酒都是正相关的。
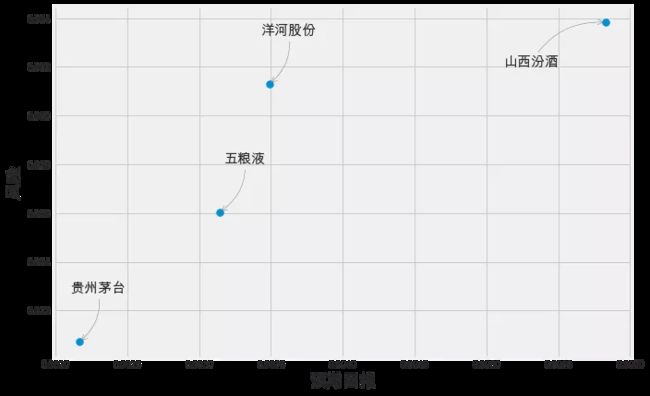
股票投资的风险
金融风险往往来源于未来的不确定性。我们通常假设股票价格服从对数正态分布,因而股票回报率服从正态分布。基于此假设,股票回报率的标准房差常用来度量金融风险,也称为波动率。
我们有很多方法来量化风险,其中一个最基本的方法是利用我们收集的关于日收益率百分比的信息将预期收益率与日收益率的标准差进行比较。
# 让我们首先将一个新的DataFrame定义为原始liquor_rets的 DataFrame的压缩版本
rets = liquor_rets.dropna()
area = np.pi * 20
plt.figure(figsize=(10, 7))
plt.scatter(rets.mean(), rets.std(), s=area)
plt.xlabel('预期回报',fontsize=18)
plt.ylabel('风险',fontsize=18)
for label, x, y in zip(rets.columns, rets.mean(), rets.std()):
if label == '山西汾酒':
xytext=(-50,-50)
else:
xytext=(50,50)
plt.annotate(label, xy=(x, y), xytext=xytext,
textcoords='offset points',
ha='right', va='bottom', fontsize=15,
arrowprops=dict(arrowstyle='->',
color='gray',
connectionstyle='arc3,rad=-0.3'))
贵州茅台收盘价预测
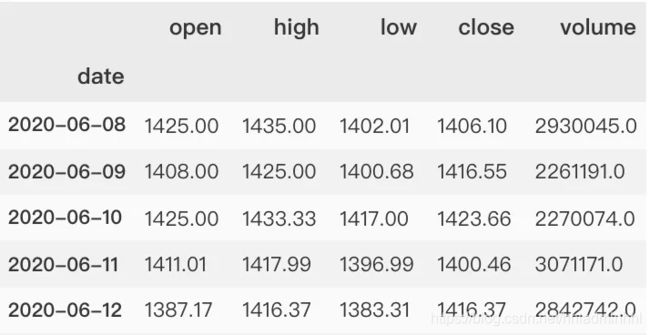
# 获取股票报价
df = maotai.loc[:,['open','high','low','close','volume']]
df.head()
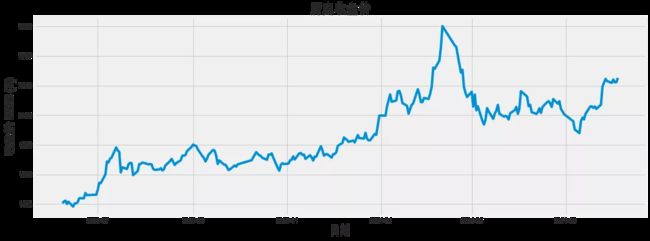
可视化收盘价
plt.figure(figsize=(16,6))
plt.title('历史收盘价',fontsize=20)
plt.plot(df['close'])
plt.xlabel('日期', fontsize=18)
plt.ylabel('收盘价 RMB (¥)', fontsize=18)
plt.show()
# 创建一个只有收盘价的新数据帧
data = df.filter(['close'])
# 将数据帧转换为numpy数组
dataset = data.values
# 获取要对模型进行训练的行数
training_data_len = int(np.ceil( len(dataset) * .95 ))
# 数据标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
# 创建训练集,训练标准化训练集
train_data = scaled_data[0:int(training_data_len), :]
# 将数据拆分为x_train和y_train数据集
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
if i<= 61:
print(x_train)
print(y_train)
# 将x_train和y_train转换为numpy数组
x_train, y_train = np.array(x_train), np.array(y_train)
# Reshape数据
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
使用LSTM模型预测股价。
# pip install keras
from keras.models import Sequential
from keras.layers import Dense, LSTM
# 建立LSTM模型
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape= (x_train.shape[1], 1)))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(x_train, y_train, batch_size=1, epochs=1)
170/170 [==============] - 7s 25ms/step - loss: 0.0253
# 创建测试数据集
# 创建一个新的数组,包含从索引的缩放值
test_data = scaled_data[training_data_len - 60: , :]
# 创建数据集x_test和y_test
x_test = []
y_test = dataset[training_data_len:, :]
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i, 0])
# 将数据转换为numpy数组
x_test = np.array(x_test)
# 重塑的数据
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1 ))
# 得到模型的预测值
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# 得到均方根误差(RMSE)
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2)))
将训练数据、实际数据集预测数据可视化。
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize=(16,6))
plt.title('模型')
plt.xlabel('日期', fontsize=18)
plt.ylabel('收盘价 RMB (¥)', fontsize=18)
plt.plot(train['close'])
plt.plot(valid[['close', 'Predictions']])
plt.legend(['训练价格', '实际价格', '预测价格'], loc='lower right')
plt.show()
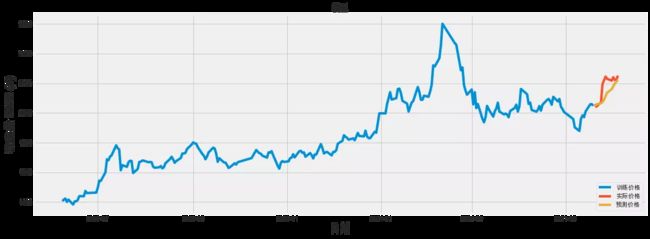
结论
根据上述预测趋势来看,白酒行业股价呈现逐步上涨阶段,未来还有一定的上涨的潜力。不多说了,只能告诉这么多了!

tips:本文是对股票价格预测的初级尝试,旨在学习python在股票预测中的应用案例。股票的预测是一个很大的学问,并不是通过一文就能解决的。
好了,今天就到这里,明天我们继续努力!

创作不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
Dragon少年 | 文
如果本篇博客有任何错误,请批评指教,不胜感激 !