一 为什么读这篇
目标检测的综述,18年9月份出的,非常的新,当时粗略扫了一下,感觉总结的十分全面,做目标检测不得不读。
二 截止阅读时这篇论文的引用次数
2019.2.5 9次。
三 相关背景介绍
18年9月挂到arXiv上,一作刘丽是个妹子,主要搞文理分析,12年国防科大博士毕业,现在是国防科大的副教授,同时也算芬兰的奥卢大学的人,二作,三作也是华人,分别是悉尼大学的和香港中文大学的,四作是老外,加拿大的滑铁卢大学,还有几个作者应该是一作的老板,好奇是什么促成这种合作关系来写综述的。。
GitHub上有个哥们基于本篇论文做了当前最新进展的更新:https://github.com/hoya012/deep_learning_object_detection
本文有点长,长达30页。。
四 关键词
Object Detection
Survey
Review
五 论文的主要贡献
1 对近5年深度学习时代目标检测方法的梳理
六 详细解读
1 介绍
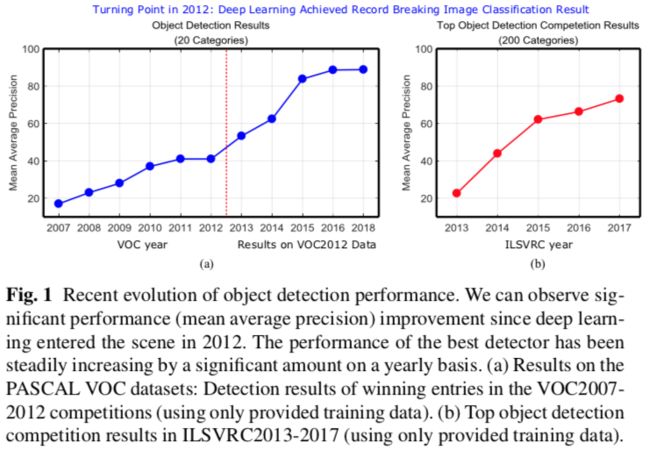
本文包括250多项关键贡献,涵盖了通用目标检测研究的许多方面:领先的检测框架,包括目标特征表示,目标提议生成的基本子问题,上下文信息建模和训练策略,评估问题,特别是基准数据集,评估指标以及SOTA的性能。
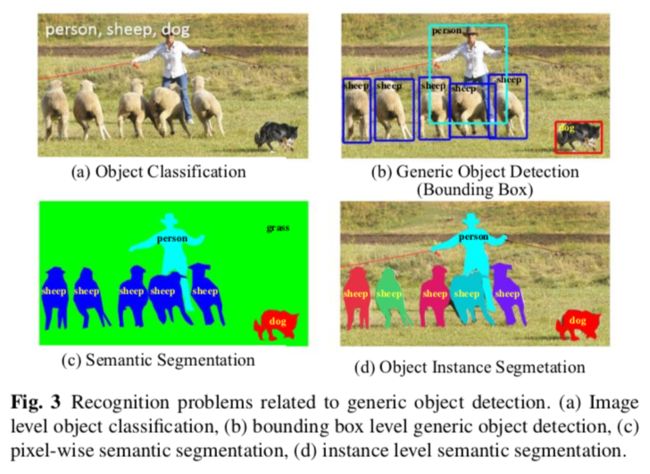
目标检测作为图像理解和计算机视觉的基石,是解决分割,场景理解,对象跟踪,图像字幕,事件检测以及活体识别的基础。
1.1 与之前综述的比较
具体目标检测(非通用),如人脸检测,行人检测,车辆检测,交通信号检测非本文讨论之列。
1.2 分类方法论
本文选取论文的标准:论文的完整性和对该领域的重要性。本文主要聚焦于近5年的工作。另外限制在图片而非视频的目标检测。
2 背景
2.1 问题
当前业界主要关心的是有高度结构化的对象(如汽车,人脸,自行车和飞机)和articulated(如人类,奶牛和马),而不是非结构化场景(如天空,草地和云彩)。本文用bounding box做空间定位,而不是精确到像素的分割掩模或封闭边界,但是需要注意的是业界正在往这个方向转。
2.2 主要挑战


尽管过去几年的研究有明显的进步,不过同时结合准确率和效率的目标尚未达成。
2.2.1 与准确率相关的挑战
总的来说就两点:
1 广泛的类内差异
2 大量的目标类别
而类内差异又可以分为两种类型:内在因素(如图5h)和成像条件(如图5a-g)。
PASCAL VOC,ILSVRC,MS COO的目标类别数分别为20,200和91,而这远远小于人类能识别的数目。
2.2.2 与效率相关的挑战
单张图像上可能有非常多的位置和尺度(如图5c)。因为图像和类别都变得太多,因此不太可能都去人工标注,逼着算法用弱监督学习。
2.3 过去二十年的进展
早期的研究主要基于模板匹配,简单部分基于模型。
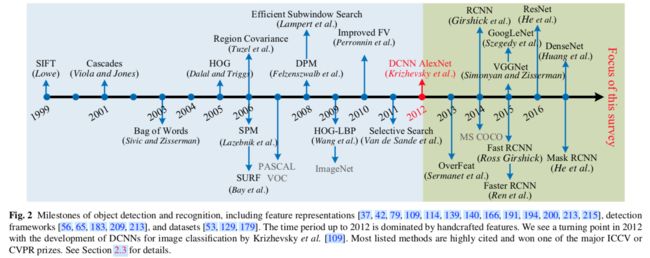
在90年代末和21世纪初,表示特征从全局表示往局部表示发展,这些表示具有平移,缩放,旋转,光照,视角和遮挡的不变性。手工提取的局部不变特征变得非常流行,始于SIFT(Scale Invariant Feature Transform)特征,后续有Haar,HOG(Histogram of Gradients),LBP(Local Binary Patterns)等等。这些局部特征通常被汇总起来,通过简单的拼接或特征池化编码(例如Bag of Visual Words,Spatial Pyramid Matching,Fisher Vectors)
Region based CNN(RCNN)是深度学习时代目标检测的里程碑。
根据识别科学家的结论,人类能够识别大约3000个大类,30000个子类的视觉目标,而领域专家通常能识别10万的级别,要想让系统达到人类这一水平还是非常有挑战的。
3 框架
近来特征提取是从手工设计的特征转为DCNN特征了,不过作为对比,用于定位的滑动窗口(sliding window)策略仍然是主流。然鹅,窗口数量很大以致于搜索空间很大,导致了高计算复杂度。因此,设计高效有效的检测框架起着关键作用。常用的策略包括级联(cascading),共享特征计算和减少每个窗口计算。
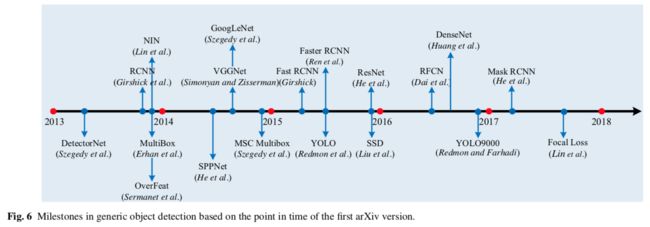
这些方法可以分为两类:
A 两阶段检测框架,包括用于候选区域(region proposal)的预处理步骤
B 一阶段检测框架(无候选区域)
3.1 基于区域(两阶段)
先从图像上生成类别无关的候选区域,然后提取这些区域的CNN特征,最后用类别有关的分类器判断候选的类别。
RCNN
集成了AlexNet和selective search的候选区域方法。
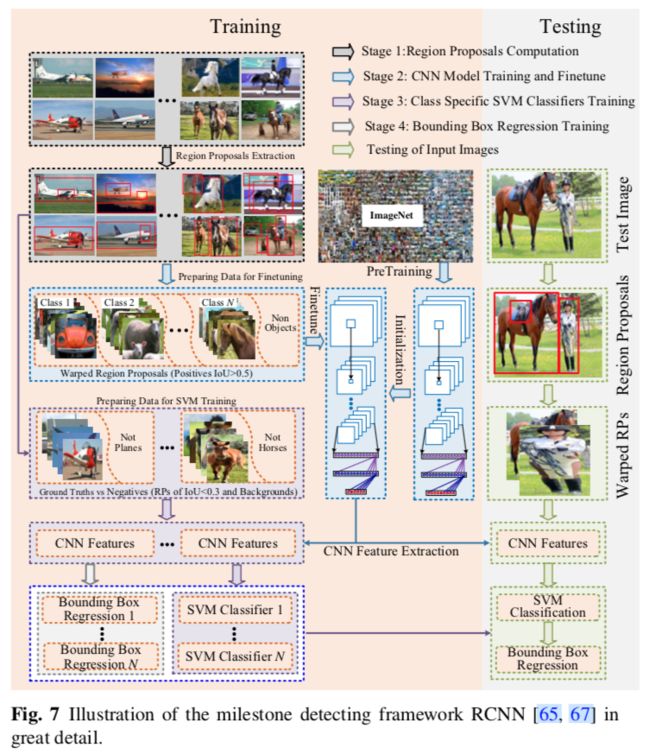
流程如下:
1 未知类别区域候选,它是可能包含目标的候选区域,通过selective search得到
2 从图像中裁剪并扭曲(warp)成相同大小的候选区域,用作微调预训练模型的输入
3 一组类别有关的线性SVM分类器,用于训练从CNN提取的固定长度的特征,SVM替换了通过微调学习的softmax
4 通过CNN特征学习每个目标类的边界框回归
缺点如下:
1 训练是一个复杂的多阶段流水线,它不够优雅,缓慢且难以优化,因为每个阶段都必须独自训练
2 仅仅用于粗定位的候选区域需要从外部检测
3 训练SVM和边界框回归很费磁盘和时间,因为从每幅图提取的候选区域的CNN特征都是独自提取的
4 测试也很慢,因为每个目标提名都要提取CNN特征
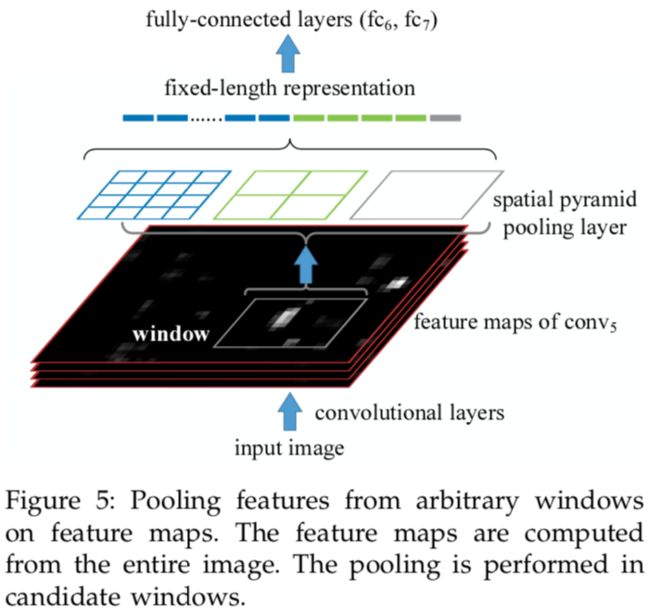
SPPNet
在测试期间,CNN特征的提取是R-CNN的主要瓶颈,因为需要提取上千个扭曲的候选区域的CNN特征。注意到这些问题,何恺明等人引入了传统的空间金字塔池化(spatial pyramid pooling SPP)。他们发现了一个事实,卷积层可以接受任意大小的输入,CNN中需要固定图像大小的要求仅仅是因为全连接层。所以在最后一个卷积层上面添加了一个SPP层,以获取用于全连接层的固定长度特征。通过SPPNet,R-CNN速度明显得到改善并且没有牺牲检测质量,就是因为只需在测试图像上运行一次卷积层,用来生成固定长度的特征用于任意大小的候选区域。尽管SPPNet从数量级上提高了R-CNN的测试阶段的速度,但是并没怎么加速训练阶段。更糟的是,微调SPPNet不能更新SPP层之前的卷积层,这限制了非常深的网络的准确率。

Fast R-CNN
R-CNN的作者Girshick提出Fast R-CNN用于解决R-CNN和SPPNet的问题。如图8所示,Fast R-CNN能够端到端的训练(忽略了生成候选区域的过程),通过开发一个精简的训练过程,使用多任务损失,同时学习softmax分类器和与类别有关的边界框回归,而不是像R-CNN/SPPNet那样在三个独立的阶段训练softmax分类器,SVM和BBRs。
Fast R-CNN利用多个候选区域共享卷积计算的想法,在最后一个卷积层和第一个全连接层之间添加感兴趣区域池化层(Region of Interest(ROI) pooling),以提取每个候选区域固定长度的特征。实质上,RoI pooling在特征级别使用扭曲(warping)来近似图像级别的扭曲。RoI pooling层之后的特征输入给FC层,最终分为两个分支:softmax用于目标类别预测,边界框回归用于优化候选区域的偏移。
相比R-CNN/SPPNet,Fast R-CNN在训练时快3倍,测试时快10倍。它可以在一个训练阶段更新所有的网络,也不需要存储特征缓存。
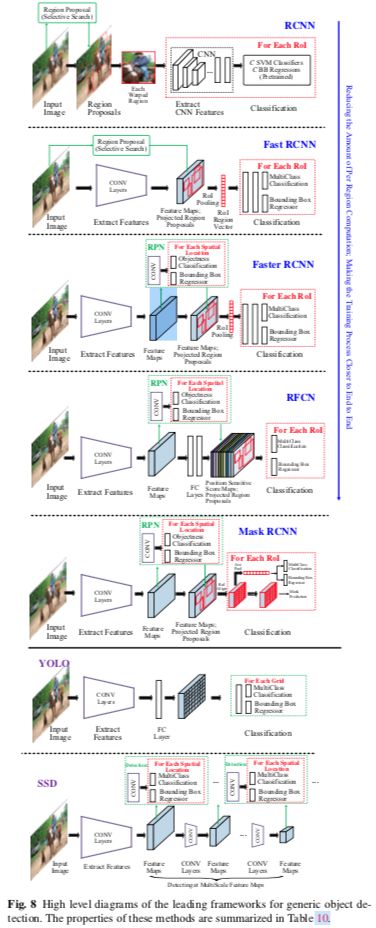
Faster R-CNN
尽管Fast R-CNN极大加速了检测过程,不过还是要依赖外部的候选区域。候选区域的计算是Fast R-CNN新的瓶颈。因此,可以把用于生成候选区域的selective search用CNN替换。任少卿等人的Faster R-CNN提出了候选区域网络(Region Proposal Network RPN)用来生成候选区域。他们用一个网络来完成,RPN生成候选区域,Fast R-CNN用于区域分类。RPN和Fast R-CNN共享大量的卷积层。最后一个共享卷积层的特征被用于候选区域和区域分类这两个分支。
RPN首先初始化k个n x n的anchors,这些anchors在每个卷积特征图的位置上有不同的尺度和纵横比。每个n x n anchor映射为低维向量(ZF256维,VGG512维),之后输入到两个并行的FC层,一个目标类别分类层和一个边界框回归层。
和Fast R-CNN不同,RPN中用于回归的特征有同样的大小。RPN共享Fast R-CNN的卷积特征,因此在计算候选区域时非常高效。
RPN实际上是一种FCN(Fully Convolutional Network)。
总的来说,Faster RCNN是一种没有使用手工特征的纯CNN框架。
RFCN(Region based Fully Convolutional Network)
尽管Faster RCNN比Fast RCNN有数量级的提速,然鹅每个RoI上仍需要使用基于区域的子网络(每张图上有数百个RoI)。MSRA的代季峰等人提出的RFCN几乎所有计算都是整张图共享。如图8所示,RFCN与Faster RCNN的不同仅仅在于RoI子网络。在Faster RCNN中,RoI池化层后的计算不是共享的。一个很自然的想法就是最小化不能共享的总计算量,因此代等人提出全部使用卷积层来构建共享的RoI子网络,在预测之前,提取最后一层卷积特征的RoI crops。然鹅,他们发现这种简单的设计检测准确率相当低,推测到更深的卷积层对类别的语义更敏感,而对平移不够敏感,然而目标检测需要与平移变化相关的定位表示。基于这个观察,代等人通过使用一组专门的卷积层作为FCN的输出构建了一组位置敏感的得分图,在上面添加了与标准RoI池化层不同的位置敏感的RoI池化层。
Mask RCNN
何恺明等人遵循简洁,高效和灵活的理念,通过扩展Faster RCNN提出Mask RCNN,来解决像素级对象实例分割。Mask RCNN的第一阶段与Faster RCNN一样,在第二阶段,增加了一个分支用于输出每个RoI的二进制掩模。新分支是CNN特征图上的FCN。为了避免原始RoI池化层引起的错位,提出了一个RoIAlign层来保持像素级空间对应。
Light Head RCNN
为了更进一步加速RFCN,旷视的黎泽明等人提出Light Head RCNN,使检测网络的头部尽可能轻,以减少RoI区域计算。
3.2 统一Pipeline(一阶段)
统一流水线是指直接从全图上预测类概率和边界框偏移的架构,不涉及候选区域生成或后分类。该方法简单而优雅,因为它完全消除了候选区域生成和后续的像素或特征重采样阶段,将所有计算封装在单个网络中。因为是单个网络,所以能直接端到端的优化。
DetectorNet
GoogLeNet的一作于2013年提出的。
OverFeat
GoogLeNet的合作者于2013年提出的,算是第一个现代一阶段目标检测网络,赢了ILSVRC2013的定位挑战赛。OverFeat通过CNN网络的单个前向传播以多尺度滑动窗口的方式执行目标检测,该CNN网络仅由卷积层组成(除最终分类/回归层)。通过这种方式,它们很自然的共享了重叠区域的计算。OverFeat生成一个特征向量网格,每个特征向量代表输入图像中稍微不同的上下文视角位置,因此可以预测目标的存在。一旦识别出目标,则使用相同的特征来预测单个边界框回归。速度优势源于使用完全卷积网络共享重叠窗口之间的卷积计算。
YOLO(You Only Look Once)
Redmon等人提出的YOLO是统一的框架,将目标检测问题转化为回归问题。如图8所示,因为把候选区域生成阶段完全抛弃掉,YOLO可以使用一组小的候选区域直接预测。不像Faster RCNN那样的基于区域的方法,预测基于局部区域的特征,YOLO使用全图的特征。特别地,YOLO将图像分为S x S的格网,每个格网预测C个类别概率,B个边界框位置和置信度分数。这些预测编码为的张量。因为预测时YOLO看到的是整张图,它隐含地编码关于目标类的上下文信息,因此不太可能把背景预测为正例。
YOLO有可能对小目标预测失败,是因为网格划分比较粗糙,并且每个网格内只能包含一个目标。
YOLOv2 and YOLO9000
YOLOv2的改进点有,用更简单的DarkNet19替换自定义的GoogLeNet,利用了当时一系列策略,比如加上BN,去掉全连接层,使用kmeans学习到的anchor box,以及多尺度训练。
YOLO9000能实时检测超过9000个目标的类别。
SSD(Single Shot Detector)
SSD的速度比YOLO v1快,准确率和Faster RCNN差不多。SSD结合了Faster RCNN中的RPN,YOLO以及多尺度卷积特征的理念。跟YOLO一样,SSD预测固定数目的边界框和目标类别分数,之后跟着NMS。
SSD的网络是完全卷积的,早期层基于标准架构,如VGG。之后几个辅助卷积层逐渐减小大小,加到基网络的后面。低分辨率的最后一层的信息可能空间上太粗糙而不能精确定位,SSD使用高分辨率的浅层来预测小目标。
对于不同大小的目标,SSD通过多个卷积特征图的来执行多尺度检测,每个特征图预测类别分数及边界框合适的偏移。
4 基本子问题
本节包含特征表示,候选区域,上下文信息挖掘以及训练策略等重要的子问题。
4.1 基于目标表示的DCNN(Depp CNN)
4.1.1 流行的CNN架构
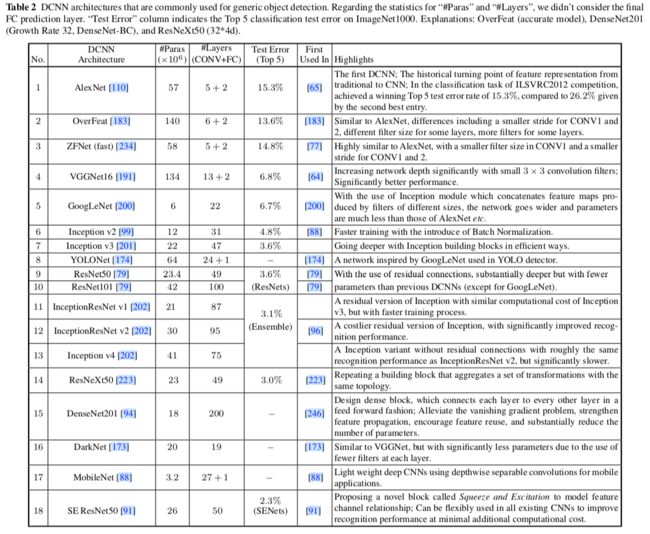
4.1.2 提升目标表示的方法
CNN这种固有的特征层次结构生成了不同空间分辨率的特征图,但在结构上存在固有问题:后面的(更高的)层有大的感受野,更强的语义,对目标姿态,光照,部分变形等变化有很强的健壮性,但是分辨率很低因此集合信息都丢失了。与此相反,前面的(更低的)层有小的感受野和丰富的几何信息,但是分辨率太高,对语义缺少敏感。直觉上,目标的语义概念可以出现在不同的层中,具体取决于目标的大小。
大量方法通过利用CNN的多个层来提升检测效果,多尺度目标检测大致分为三种类型:
1 使用多个CNN层的组合特征进行检测
2 在多个CNN层上直接检测
3 结合上述两种方法
(1)使用多个CNN层的组合特征进行检测
代表方法有Hypercolumns,HyperNet,ION。这种特征组合通常通过跳跃连接来完成。
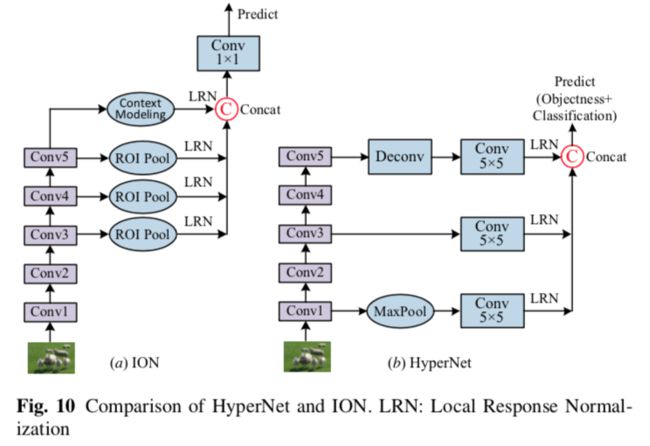
(2)在多个CNN层上直接检测
FCN通过平均分割概率结合多个层的从粗糙到精细的预测。SSD,MSCNN,RBFNet,DSOD结合多个特征图的预测来处理各种大小的目标。SSD将不同比例的默认框展开到CNN中的多个层,并强制每个层专注于预测特定比例的目标。
(3)结合上述两种方法
从具有较大感受野的后面的层检测大目标,从具有较小感受野的前面的层检测小目标,感觉是很自然的,然而,简单地检测来自前面层的目标可能导致效果很差,因为前面的层具有较少的语义信息。因此,为了结合两者的优点,最近的一些工作提出了在多个层上检测目标,并通过组合来自不同层的特征去获取每个检测层的特征。代表方法有SharpMask,DSSD(Deconvolutional Single Shot Detector),FPN(Feature Pyramid Network),TDM(Top Down Modulation),RON(Reverse connection with Objectness prior Network),ZIP,STDN(Scale Transfer Detection Network),RefineDet,StairNet,如表3和图11,图12所示。
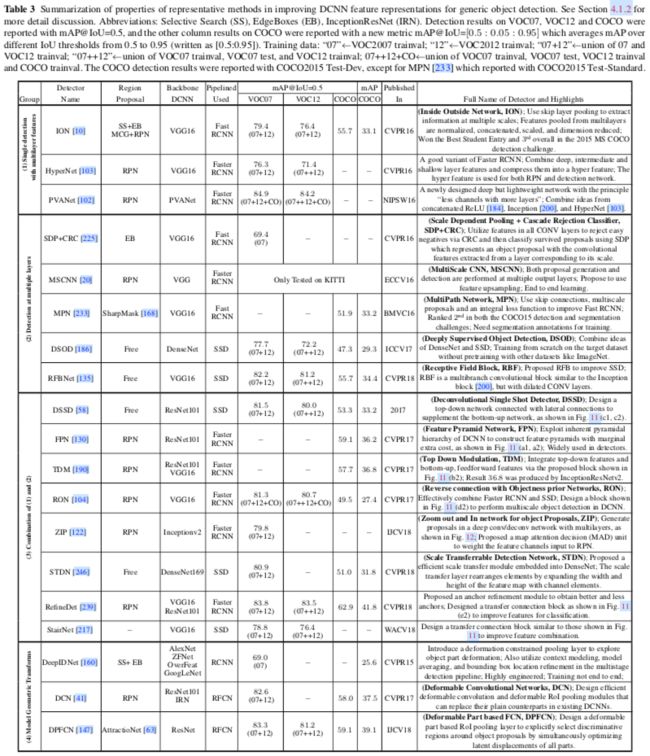
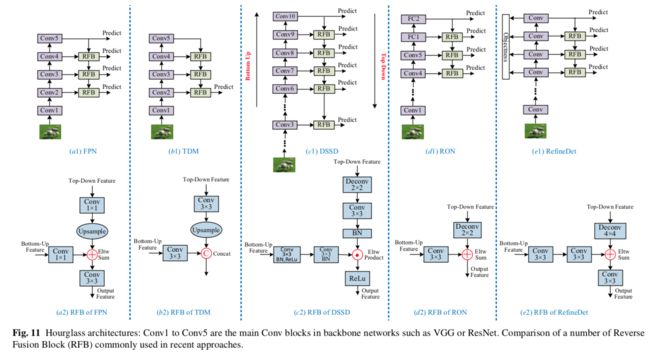
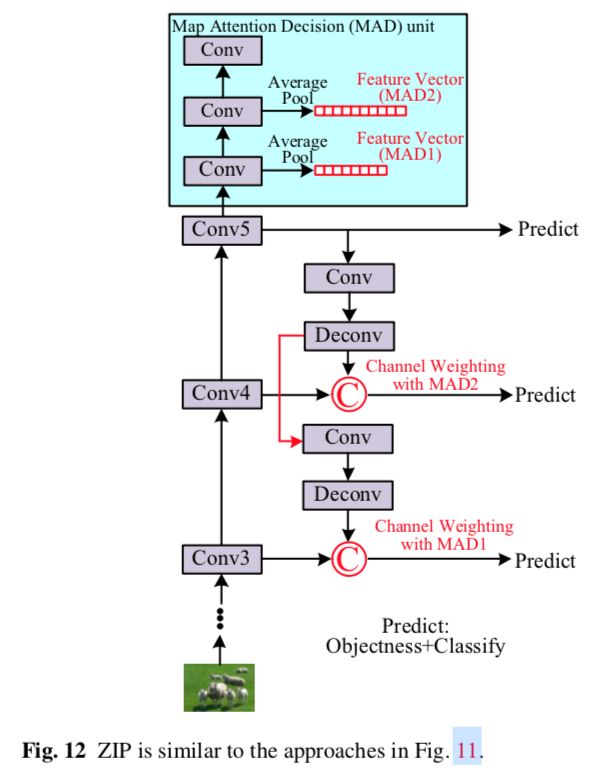
如图11所示,这些方法都有高度相似的检测架构,具体来讲,在自下而上的传递之后,最终的高级语义特征由自上而下的网络回传,以便在横向处理后与来自中间层的自下而上的特征相结合。
(4)模型几何变换
DCNN对明显的几何变换有着天生的限制。一些方法用于增强CNN表示的健壮性,如STN。
对变形的目标建模
在深度学习之前,对于目标检测,DPMs(Deformable Part based Models)是非常成功的(10年的文章,引用有7000多次),它是用可变形配置,通过排列部分组件来表示目标。这种DPM建模方式对目标姿态,视角和非刚性变形的变换不太敏感,是因为目标的部分相应地定位,并且它们的局部外观是稳定的。所以现在一些深度学习的方法也借鉴DPM的思路。
4.2 上下文建模
在物理世界中,视觉目标出现在特定的环境中,并且通常与其他目标一起出现,这是有充分的心理学证据的,语境在人类识别系统中起着重要作用。
上下文大致分为三种类型:
1 语义上下文:在某些场景中找到目标但在其他场景中找不到目标的可能性
2 空间上下文:在某个位置找到一个目标的可能性
3 尺度上下文:目标相对于场景中的其他目标,其尺寸大小是有限的。
当前SOTA的方法(Faster RCNN,FCN)并没有显式利用上下文信息,而更多的是隐式的使用,因为它们学习了多级抽象的的层次表示。
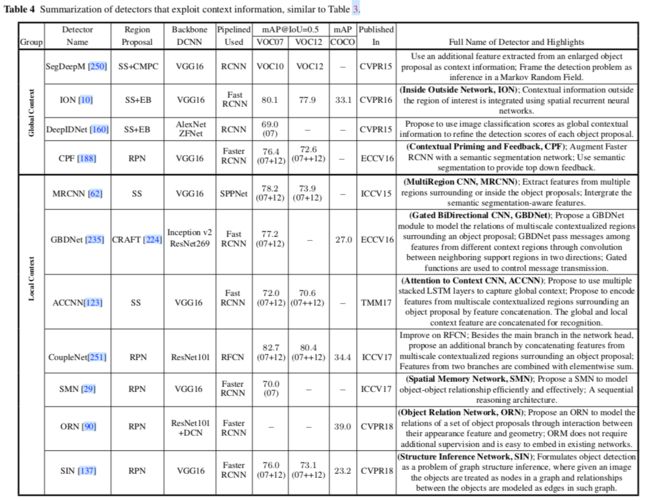
Global context
考虑图像或场景级别的上下文,可以用作目标检测的线索(例如,卧室将预测有床的存在)
Local context
考虑目标关系中的局部环境,目标与其周围区域之间的相互作用。
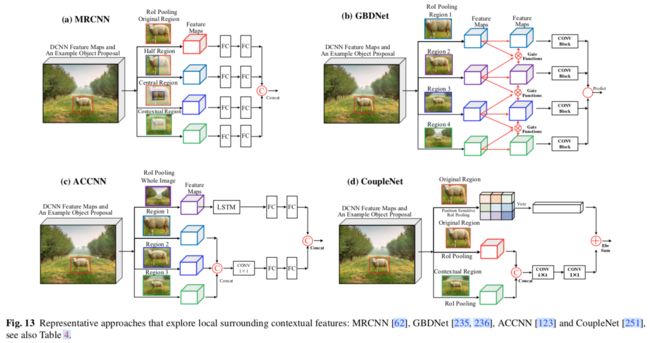
4.3 候选检测方法
一个好的候选检测应当有如下特征:
1 高召回,而且只需少量候选即可实现
2 候选应尽可能准确地匹配目标
3 高效率
在基于传统低级线索(如颜色,纹理,边缘和梯度)的候选目标方法中,Selective Search,MCG和EdgeBoxes更为流行。后来就成瓶颈了。最近的基于DCNN的候选目标方法可以分为两类:基于边界框的和基于对象分割的。
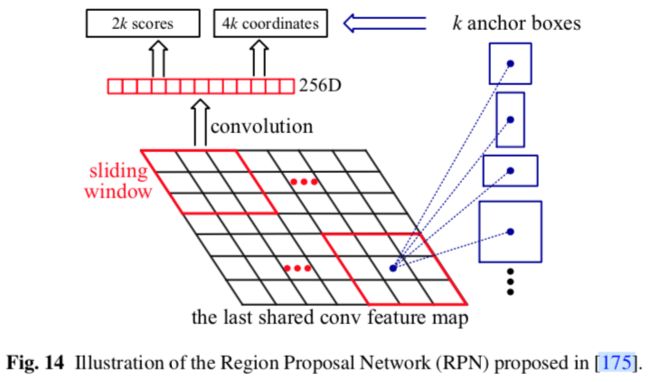
边界框候选方法
"anchor"这个词第一次出现是在Faster RCNN中。如图14所示,RPN通过在最后一个共享卷积层的特征图上滑动小网络来预测候选目标。在每个滑动窗口位置,它通过使用k个anchor同时预测k个候选,每个anchor位于图像上某个位置的中间,anchor与特定的比例和纵横比相关联。
对象分割候选方法
分割候选比边界框候选富含更多信息,而且朝着对象实例分割更进一步。
DeepMask是其中的先驱,后续有更高级的SharpMask。
4.4 其他特殊问题
数据增强技术必不可少。图像分辨率对检测准确率有明显的影响。因此,在图像增强技术中,缩放被广泛使用,因为高分辨率的输入有助于小目标的检测。
类别不平衡问题的处理。
还有一些工作是关于NMS的。
5 数据集和性能评估
5.1 数据集
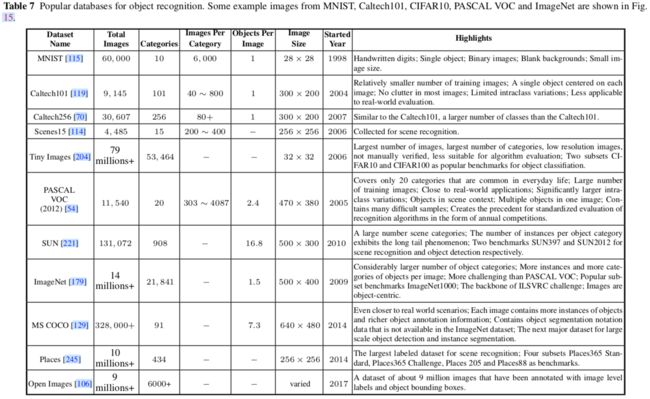
5.2 评估标准
有三种指标评估检测效果:检测速度(Frames Per Second,FPS),精确率,召回率。最常用的指标是Average Precision(AP),源于精确率和召回率。AP通常用于评估一类目标。mean AP(mAP)平均了所有目标类别,被作为最终的衡量指标。
测试图像的标准输出通常是。其中j为索引。b为预测的位置(Bounding Box, BB),c为预测的标签,p为置信度。如果一个预测满足如下两个条件,则记为True Positive(TP):
1 预测的标签和真实标签一样
2 IOU(Intersection Over Union)高于某个阈值,阈值通常为0.5
否则,记为False Positive(FP)。

基于TP和FP,可以计算准确率和召回率,之后就可以算AP了。

5.3 性能
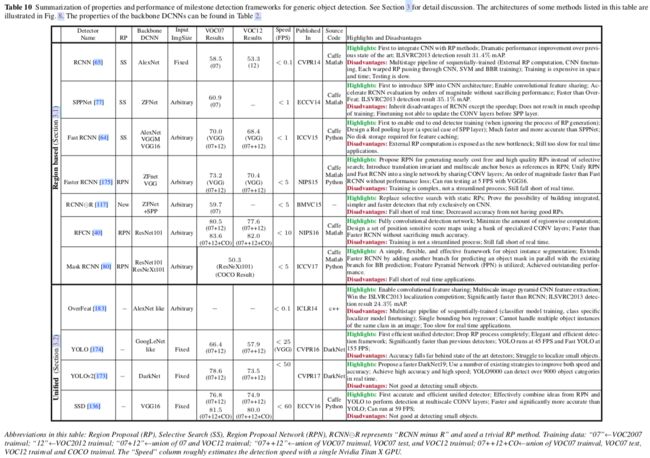
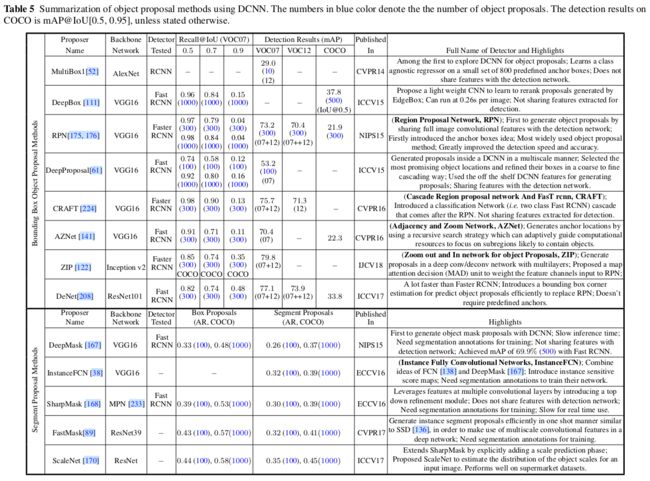
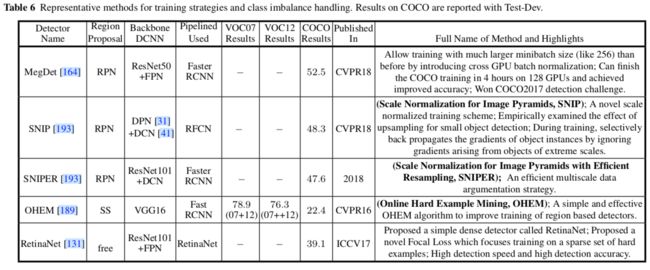
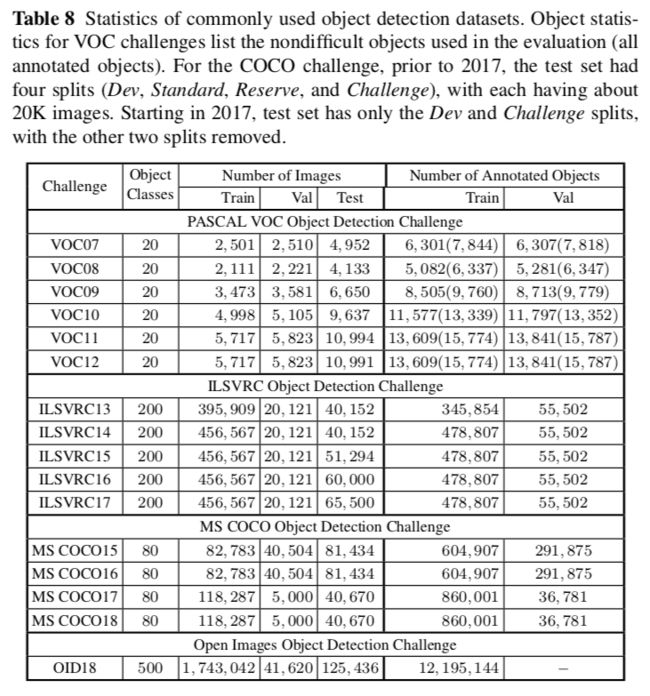
见之前的表3,4,5,6,10
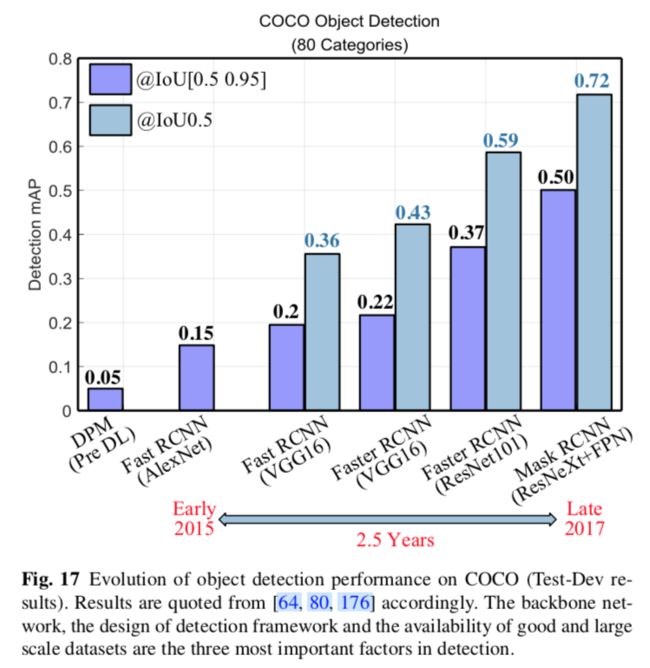
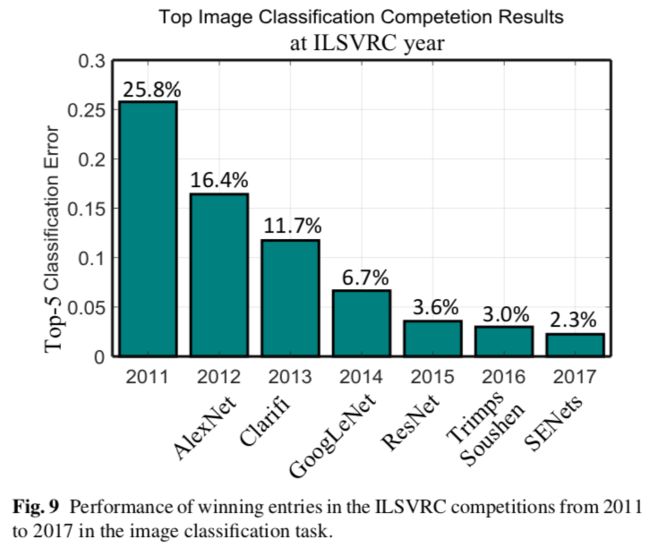
从图17可以看出,backbone网络,检测框架,数据集规模是影响效果的3个最重要的因素。
然而,当前效果最好的MegDet在COCO(80类)上的mAP也只有73%(即使是0.5的IOU),可见目标检测比图像分类难得多。
6 总结
还有许多工作要做,我们将重点放在以下八个领域:
(1)开放世界的学习
目前的检测算法学习的数据是相当有限的,与人类视觉系统尚有距离。
(2)更好更有效的检测框架
(3)紧凑高效的深度CNN特征
(4)健壮的目标表示
当前对各种变化还是缺乏健壮性,因此很明显的限制了真实世界的应用。
(5)上下文推理
(6)对象实例分割
(7)弱监督或非监督学习
(8)3D目标检测
七 读后感
总算看完了,TMD真长。越看感觉不会的越多。现在的网络简直可以用海量来形容了,真是从特征工程走向网络工程了,各种魔改网络结构。不知道是作者本人写作习惯,还是综述就得这么写,感觉好多地方就是为引用而引用。好多文献都引用了两遍,比如Faster RCNN,比如FCN,另外通过这个知道了一般期刊比会议要晚2年出。
此外,感觉上下文建模那块有点不可取,这块主要是利用先验知识的,而不是视觉本身的特点,所以会相当受限。
八 补充
GitHub上的awesome-object-detection
Ross Girshick大神在CVPR2018上的slide,这个基本上算必读了。
知乎的这篇文章不错:基于深度学习的图像目标检测(上),基于深度学习的图像目标检测(下)