目录
- 高并发模式初探
- C语言的高并发案例
- Java的高并发实现
- Go的高并发实现
- Rust的高并发实现
- 总结
高并发模式初探
在这个高并发时代最重要的设计模式无疑是生产者、消费者模式,比如著名的消息队列kafka其实就是一个生产者消费者模式的典型实现。其实生产者消费者问题,也就是有限缓冲问题,可以用以下场景进行简要描述,生产者生成一定量的产品放到库房,并不断重复此过程;与此同时,消费者也在缓冲区消耗这些数据,但由于库房大小有限,所以生产者和消费者之间步调协调,生产者不会在库房满的情况放入端口,消费者也不会在库房空时消耗数据。详见下图:
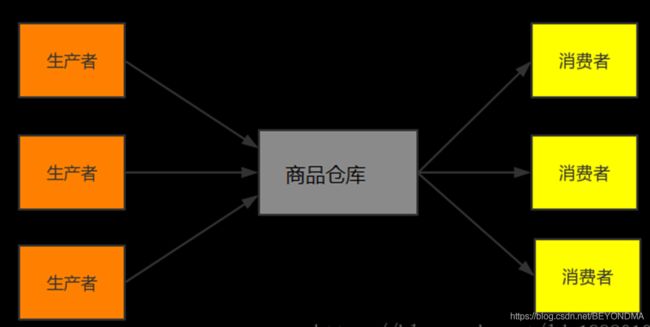
而如果在生产者与消费者之间完美协调并保持高效,这就是高并发要解决的本质问题。
C语言的高并发案例
笔者在前文曾经介绍过TDEngine的相关代码,其中Sheduler模块的相关调度算法就使用了生产、消费者模式进行消息传递功能的实现,也就是有多个生产者(producer)生成并不断向队列中传递消息,也有多个消费者(consumer)不断从队列中取消息。
后面我们也会说明类型功能在Go、Java等高级语言中类似的功能已经被封装好了,但是在C语言中你就必须要用好互斥体( mutex)和信号量(semaphore)并协调他们之间的关系。由于C语言的实现是最复杂的,先来看结构体设计和他的注释:
typedef struct {
char label[16];//消息内容
sem_t emptySem;//此信号量代表队列的可写状态
sem_t fullSem;//此信号量代表队列的可读状态
pthread_mutex_t queueMutex;//此互斥体为保证消息不会被误修改,保证线程程安全
int fullSlot;//队尾位置
int emptySlot;//队头位置
int queueSize;#队列长度
int numOfThreads;//同时操作的线程数量
pthread_t * qthread;//线程指针
SSchedMsg * queue;//队列指针
} SSchedQueue;
再来看Shceduler初始化函数,这里需要特别说明的是,两个信号量的创建,其中emptySem是队列的可写状态,初始化时其值为queueSize,即初始时队列可写,可接受消息长度为队列长度,fullSem是队列的可读状态,初始化时其值为0,即初始时队列不可读。具体代码及我的注释如下:
void *taosInitScheduler(int queueSize, int numOfThreads, char *label) {
pthread_attr_t attr;
SSchedQueue * pSched = (SSchedQueue *)malloc(sizeof(SSchedQueue));
memset(pSched, 0, sizeof(SSchedQueue));
pSched->queueSize = queueSize;
pSched->numOfThreads = numOfThreads;
strcpy(pSched->label, label);
if (pthread_mutex_init(&pSched->queueMutex, NULL) < 0) {
pError("init %s:queueMutex failed, reason:%s", pSched->label, strerror(errno));
goto _error;
}
//emptySem是队列的可写状态,初始化时其值为queueSize,即初始时队列可写,可接受消息长度为队列长度。
if (sem_init(&pSched->emptySem, 0, (unsigned int)pSched->queueSize) != 0) {
pError("init %s:empty semaphore failed, reason:%s", pSched->label, strerror(errno));
goto _error;
}
//fullSem是队列的可读状态,初始化时其值为0,即初始时队列不可读
if (sem_init(&pSched->fullSem, 0, 0) != 0) {
pError("init %s:full semaphore failed, reason:%s", pSched->label, strerror(errno));
goto _error;
}
if ((pSched->queue = (SSchedMsg *)malloc((size_t)pSched->queueSize * sizeof(SSchedMsg))) == NULL) {
pError("%s: no enough memory for queue, reason:%s", pSched->label, strerror(errno));
goto _error;
}
memset(pSched->queue, 0, (size_t)pSched->queueSize * sizeof(SSchedMsg));
pSched->fullSlot = 0;//实始化时队列为空,故队头和队尾的位置都是0
pSched->emptySlot = 0;//实始化时队列为空,故队头和队尾的位置都是0
pSched->qthread = malloc(sizeof(pthread_t) * (size_t)pSched->numOfThreads);
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for (int i = 0; i < pSched->numOfThreads; ++i) {
if (pthread_create(pSched->qthread + i, &attr, taosProcessSchedQueue, (void *)pSched) != 0) {
pError("%s: failed to create rpc thread, reason:%s", pSched->label, strerror(errno));
goto _error;
}
}
pTrace("%s scheduler is initialized, numOfThreads:%d", pSched->label, pSched->numOfThreads);
return (void *)pSched;
_error:
taosCleanUpScheduler(pSched);
return NULL;
}
再来看读消息的taosProcessSchedQueue函数这其实是消费者一方的实现,这个函数的主要逻辑是
1.使用无限循环,只要队列可读即sem_wait(&pSched->fullSem)不再阻塞就继续向下处理
2.在操作msg前,加入互斥体防止msg被误用。
3.读操作完毕后修改fullSlot的值,注意这为避免fullSlot溢出,需要对于queueSize取余。同时退出互斥体。
4.对emptySem进行post操作,即把emptySem的值加1,如emptySem原值为5,读取一个消息后,emptySem的值为6,即可写状态,且能接受的消息数量为6
具体代码及注释如下:
void *taosProcessSchedQueue(void *param) {
SSchedMsg msg;
SSchedQueue *pSched = (SSchedQueue *)param;
//注意这里是个无限循环,只要队列可读即sem_wait(&pSched->fullSem)不再阻塞就继续处理
while (1) {
if (sem_wait(&pSched->fullSem) != 0) {
pError("wait %s fullSem failed, errno:%d, reason:%s", pSched->label, errno, strerror(errno));
if (errno == EINTR) {
/* sem_wait is interrupted by interrupt, ignore and continue */
continue;
}
}
//加入互斥体防止msg被误用。
if (pthread_mutex_lock(&pSched->queueMutex) != 0)
pError("lock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));
msg = pSched->queue[pSched->fullSlot];
memset(pSched->queue + pSched->fullSlot, 0, sizeof(SSchedMsg));
//读取完毕修改fullSlot的值,注意这为避免fullSlot溢出,需要对于queueSize取余。
pSched->fullSlot = (pSched->fullSlot + 1) % pSched->queueSize;
//读取完毕修改退出互斥体
if (pthread_mutex_unlock(&pSched->queueMutex) != 0)
pError("unlock %s queueMutex failed, reason:%s\n", pSched->label, strerror(errno));
//读取完毕对emptySem进行post操作,即把emptySem的值加1,如emptySem原值为5,读取一个消息后,emptySem的值为6,即可写状态,且能接受的消息数量为6
if (sem_post(&pSched->emptySem) != 0)
pError("post %s emptySem failed, reason:%s\n", pSched->label, strerror(errno));
if (msg.fp)
(*(msg.fp))(&msg);
else if (msg.tfp)
(*(msg.tfp))(msg.ahandle, msg.thandle);
}
}
最后写消息的taosScheduleTask函数也就是生产的实现,其基本逻辑是
1.写队列前先对emptySem进行减1操作,如emptySem原值为1,那么减1后为0,也就是队列已满,必须在读取消息后,即emptySem进行post操作后,队列才能进行可写状态。
2.加入互斥体防止msg被误操作,写入完成后退出互斥体
3.写队列完成后对fullSem进行加1操作,如fullSem原值为0,那么加1后为1,也就是队列可读,咱们上面介绍的读取taosProcessSchedQueue中sem_wait(&pSched->fullSem)不再阻塞就继续向下。
int taosScheduleTask(void *qhandle, SSchedMsg *pMsg) {
SSchedQueue *pSched = (SSchedQueue *)qhandle;
if (pSched == NULL) {
pError("sched is not ready, msg:%p is dropped", pMsg);
return 0;
}
//在写队列前先对emptySem进行减1操作,如emptySem原值为1,那么减1后为0,也就是队列已满,必须在读取消息后,即emptySem进行post操作后,队列才能进行可写状态。
if (sem_wait(&pSched->emptySem) != 0) pError("wait %s emptySem failed, reason:%s", pSched->label, strerror(errno));
//加入互斥体防止msg被误操作
if (pthread_mutex_lock(&pSched->queueMutex) != 0)
pError("lock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));
pSched->queue[pSched->emptySlot] = *pMsg;
pSched->emptySlot = (pSched->emptySlot + 1) % pSched->queueSize;
if (pthread_mutex_unlock(&pSched->queueMutex) != 0)
pError("unlock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));
//在写队列前先对fullSem进行加1操作,如fullSem原值为0,那么加1后为1,也就是队列可读,咱们上面介绍的读取函数可以进行处理。
if (sem_post(&pSched->fullSem) != 0) pError("post %s fullSem failed, reason:%s", pSched->label, strerror(errno));
return 0;
}
Java的高并发实现
从并发模型来看,Go和Rust都有channel这个概念,也都是通过Channel来实现线(协)程间的同步,由于channel带有读写状态且保证数据顺序,而且channel的封装程度和效率明显可以做的更高,因此Go和Rust官方都会建议使用channel(通信)来共享内存,而不是使用共享内存来通信。
为了让帮助大家找到区别,我们先以Java为例来,看一下没有channel的高级语言Java,生产者消费者该如何实现,代码及注释如下:
public class Storage {
// 仓库最大存储量
private final int MAX_SIZE = 10;
// 仓库存储的载体
private LinkedList