1.搭建虚拟机环境
创建三个虚拟机,网络以桥接模式,三台虚拟机在同一网段,保证三台机器能够相互ping通。
1.1修改主机名
用root账户登录,修改/etc/sysconfig/network文件,将HOSTNAME改成自己想要的起的主机名。我这将三台机器分别改成hadoop01、hadoop02和hadoop03。

修改/etc/hostname文件,修改主机名后重启
1.2配置内网映射
修改/etc/hosts文件,配置各个主机间的ip和主机名。以hadoop01这台机器为例:

配置完成后测试能不能通过主机名ping通。

1.3关闭防火墙/关闭 Selinux
防火墙操作相关:
查看防火墙状态:service iptables status
关闭防火墙:service iptables stop
开启防火墙:service iptables start
重启防火墙:service iptables restart
关闭防火墙开机启动:chkconfig iptables off
开启防火墙开机启动:chkconfig iptables on
注意:centos7的命令稍有不同,例如关闭防火墙是 systemctl stop iptables.service,具体的命令请自行百度
关闭 Selinux:具体做法是修改/etc/selinux/config 配置文件中的 SELINUX=disabled
1.4新建用户并赋权
新建一个hadoop用户,命令是adduser hadoop。
以root用户身份为hadoop用户赋权,在 root 账号下,命令终端输入:vi /etc/sudoers
找到
root ALL=(ALL) ALL
这一行,然后在他下面添加一行:
hadoop ALL=(ALL) ALL
保存,退出
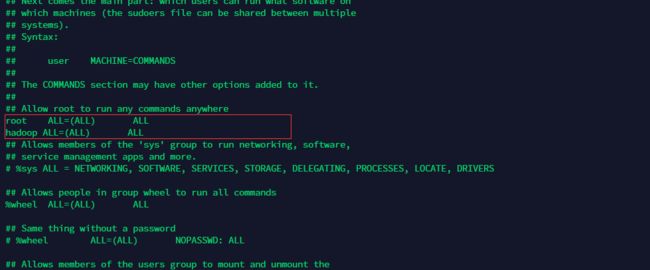
注意:如果保存的时候提示文件为只读,保存的时候加个感叹号即可。例如:wq!
2.安装jdk
上传jdk安装包,可以从网络下载的方式,也可以从本地上传。本文采用第二种方式,先将安装包下载到本地电脑,然后通过FileZilla软件上传到虚拟机中。只需上传到一台虚拟机即可,之后通过scp拷贝。

解压到/usr/local下
tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local
配置环境变量
- vi /etc/profile
- 在最后加入两行:
export JAVA_HOME=/usr/local/jdk1.8.0_73
export PATH=$PATH:$JAVA_HOME/bin
3.重新加载环境变量 source /etc/profile
4.最后检测是否安装成功,输入命:java -version
3.同步服务器时间
当Linux服务器的时间不对的时候,可以使用ntpdate工具来校正时间。
210.72.145.44 中国(国家授时中心)
ntpdate 210.72.145.44
4.配置免密登录
这一步是为了配置各个服务器间hadoop用户的免密登录(密钥方式登录)。这一步操作时记得切换至hadoop用户。
1)在 hadoop 登录状态下,输入命令 ssh-keygen 或者 ssh-keygen -t rsa,一直按回车即可。
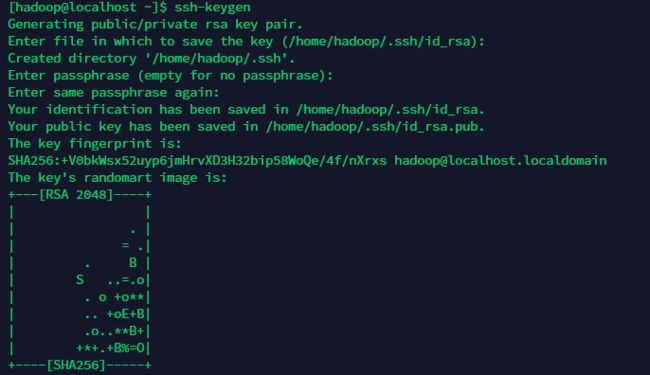
2)之后你会发现,在/home/hadoop/.ssh 目录下生成了公钥文件

3)使用ssh-copy-id命令与其他主机建立免密连接,其实就是将自己的公钥拷贝至其他主机的authorized_keys文件中。
例如 建立 hadoop01 到 hadoop02 的免密登录
在hadoop01机器上,用hadoop用户执行命令 ssh-copy-id hadoop02,接下来会让输入hadoop02的密码,输入完之后就建立成功。使用ssh命令验证,在hadoop01下用hadoop用户执行 ssh hadoop@hadoop02,执行完之后可以看到主机名变成了hadoop02,说明免密登录配置成功。
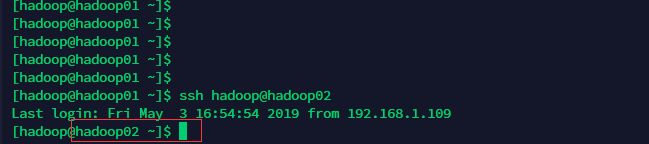
还需要配置自己登陆自己的免密登录
4)在另外两台机器上重复以上步骤,保证3台机器中两两能够互相免密登录即可。
5. hadoop 分布式集群安装
5.1拷贝并解压hadoop安装包
从hadoop官网下载安装包,本文安装的是2.9版本。上传至/usr/src目录下,解压至home/hadoop/apps目录下
命令:tar -zxvf hadoop-2.9.2.tar.gz -C /home/hadoop/apps
5.2修改hadoop配置文件
进入hadoop安装目录
cd /home/hadoop/apps/hadoop-2.9.2
核心配置文件在etc/hadoop下
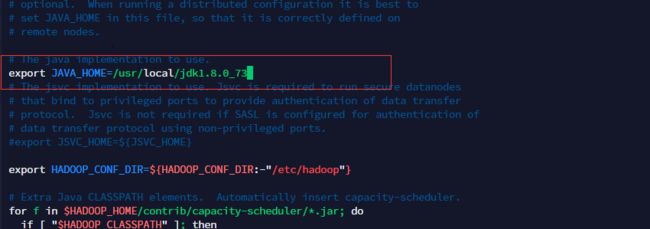
1)修改hadoop-env.sh,指定JAVA_HOME目录
export JAVA_HOME=/usr/local/jdk1.8.0_73
2)修改 core-site.xml
在
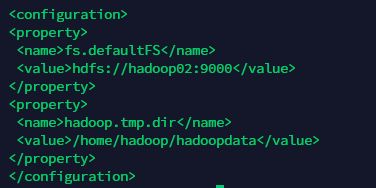
其中fs.defaultFS配置的是namenode的节点ip和端口,hadoop.tmp.dir配置的是hadoop数据存储目录。
3)修改 hdfs-site.xml
在

其中每个配置项的说明在description标签中已标明
4)修改 mapred-site.xml(集群只有 mapred-site.xml.template,可以从这个文件进行复
制,或者直接改名也可)
在
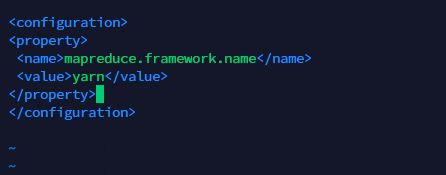
配置采用yarn作为资源调度框架
5)修改 yarn-site.xml
在

yarn.resourcemanager.hostname配置resourcemanager节点
6)修改 slaves 文件
添加以下内容,该内容是从节点列表
hadoop01
hadoop02
hadoop03
5.3分发安装包到各个节点
采用scp命令将hadoop安装目录拷贝至另外两个节点
scp -r hadoop-2.9.2/ hadoop@hadoop02:/home/hadoop/apps
scp -r hadoop-2.9.2/ hadoop@hadoop03:/home/hadoop/apps
在各个节点配置hadoop环境变量
修改/etc/profile 添加以下内容
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载环境变量
source /etc/profile
执行hadoop --help命令测试环境变量是否配置成功
5.4初始化namenode
在 HDFS 主节点(core-site.xml中配置的fs.defaultFS)上执行命令进行初始化 namenode
在namenode节点执行命令
hadoop namenode -format
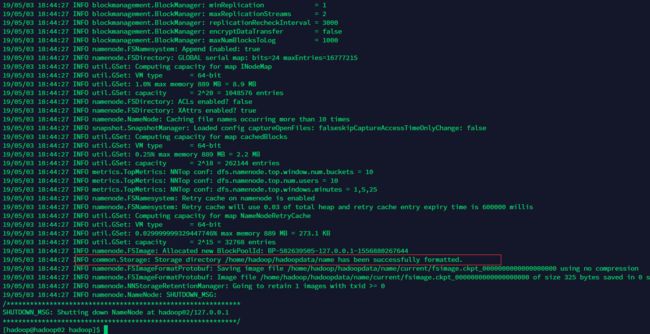
当看到图中红框的 successfully formatted时,即是初始化成功。
如果初始化没有成功,查找报错信息,重新执行初始化命令,直至成功为止。
注意,初始化操作只需要执行一次,初始化成功之后可以在之前配置的hadoop数据存储目录(hdfs-site.xml文件中配置的dfs.datanode.data.dir)看到hadoopdate目录,如果需要重新初始化,就删除每个节点的这个文件夹,重新执行hadoop namenode -formate命令

6.启动集群
6.1启动hdfs,在任意一个节点执行start-dfs.sh命令。

可以看到hdfs在各个节点启动的过程以及日志输出。
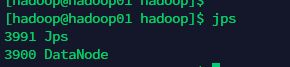
启动完之后,在各个节点执行jps命令查看java进程。
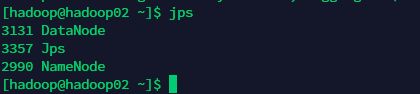
可以看到hadoop02上启动了一个namenode进程和一个DataNode进程。因为我们配置的hdfs主节点在hadoop02 上,所以namenode进程就在hadoop02上。

hadoop03上启动了一个DataNode进程和一个SecondaryNameNode进程。
6.2启动yarn
在 YARN 主节点启动 YARN,要求在 YARN 主节点进行启动,否则 ResourceManager 主进
程会启动不成功,需要额外手动启动。
启动yarn的命令为:start-yarn.sh
因为我配置的yarn主节点在hadoop01机器上,所以在hadoop01上启动yarn。

用JPS查看进程
结果:在主节点启动了 resourcemanager 守护进程
在从节点启动了 nodemanager 守护进程
6.3检查hdfs是否启动成功
在任意节点上执行 hadoop fs -ls /
上传一份文本文件 hadoop fs -put /in /
访问HDFS的web控制台,地址是NameNode节点的50070端口,例如:http://192.168.1.107:50070/
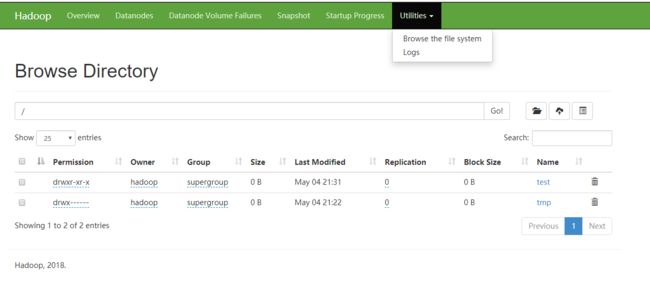
在这个页面可以下载HDFS上的文件,不过默认的下载地址是主机名,如果windows没有配置过NDS解析,那么就需要将主机名改成对应的ip,也可以直接修改hosts文件(文件位于C:\Windows\System32\drivers\etc下,记得用管理员身份打开,或者复制到桌面修改完之后再覆盖原文件)
如果能成功的上传或者下载,就说明HDFS启动成功。
6.3检查yarn是否启动成功
hadoop安装包里有一些程序实例,可以用hadoop jar命令执行,我们可以用经典的wordcount程序测试下yarn是否启动成功。
首先上传一份文本文件到hdfs,文本中随便写一些单词,以回车符分割。
然后进入/home/hadoop/apps/hadoop-2.9.2/share/hadoop/mapreduce目录,执行以下命令
hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /test/test /test/wcout
执行完之后到HDFS的/test/wcout下就会看到输出的结果文件。至此,hadoop的伪分布式集群环境搭建完成。
7.搭建过程中一些可能出现的问题
7.1HDFS监听的9000端口默认绑定127.0.0.1地址问题
启动hdfs之后,发现只有namenode节点可以访问hdfs,其他节点访问不到,使用netstat -ano|grep 9000命令查看9000端口的监听情况,发现监听的是127.0.0.1地址。
出现这个问题的原因是hosts文件配置错误,解决办法是修改hosts文件,127.0.0.1和::1两个地址不要绑定主机名,主机名绑定内网地址即可。如图:

7.2启动的时候提示要输入从节点的密码
执行start-dfs.sh或者start-all.sh的时候提示要输入密码,如图:

问题原因:用root用户启动的命令,而root用户没有配置过免密登录,所以需要密码。
解决办法:切换到hadoop用户,再执行启动命令。这个每次关机重启后经常会忘记。
7.3连接拒绝问题
访问hdfs文件或者执行mr程序的时候会出现connection refused的错误,这时候检查一下节点的防火墙设置。
CentOS 7.0默认使用的是firewall作为防火墙
查看防火墙状态
firewall-cmd --state
停止firewall
systemctl stop firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service