总结一下个人看了一些Spark性能调优文章之后的理解,主要框架来自于meituantech,会在此框架上加入个人关注点,目录如下,
0. Overview
1. 开发调优
- 避免创建重复的RDD
- 尽可能复用同一个RDD
- 对多次使用的RDD进行持久化
- 尽量避免使用shuffle类算子
- 使用map-side预聚合的shuffle操作
- 使用高性能的算子
- 广播大变量
- 使用Kryo优化序列化性能
- 优化数据结构
2. 资源参数调优
- 运行时架构
- 运行流程
- 调优
- executor配置
- driver配置
- 并行度
- 网络超时
- 数据本地化
- JVM/gc配置
3. 数据倾斜调优
- 使用Hive ETL预处理数据
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 两阶段聚合
- 将reduce join转为map join
- 使用随机前缀和扩容RDD进行join
4. Shuffle调优
- shuffle原理
- shuffle演进
- 调优
- join类型
5. 其他优化项
- 使用DataFrame/DataSet
6. Reference
Overview
Spark的瓶颈一般来自于集群(standalone, yarn, mesos, k8s)的资源紧张,CPU,网络带宽,内存。通过都会将数据序列化,降低其内存memory和网络带宽shuffle的消耗。
Spark的性能,想要它快,就得充分利用好系统资源,尤其是内存和CPU:核心思想就是能用内存cache就别spill落磁盘,CPU 能并行就别串行,数据能local就别shuffle。 ----xrzs
开发调优
-
避免创建重复的RDD
- 比如多次读可以persist;但如果input太大,persist可能得不偿失
-
尽可能复用同一个RDD
- 但是如果rdd的lineage太长,最好checkpoint下来,避免长重建
-
对多次使用的RDD进行持久化
- 持久化级别(SER,MEM,DISK,_N)
-
尽量避免使用shuffle类算子
- shuffle算子如distinct(实际调用reduceByKey)、reduceByKey、aggregateByKey、sortByKey、groupByKey、join、cogroup、repartition等,入参中会有一个并行度参数numPartitions
- shuffle过程中,各个节点上的相同key都会先写入本地磁盘文件中,然后其他节点需要通过网络传输拉取各个节点上的磁盘文件中的相同key
-
使用map-side预聚合的shuffle操作
-
reduceByKey(combiner),groupByKey(没有combiner)
 without combiner
without combiner
 with combiner
with combiner
-
-
使用高性能的算子
- 使用reduceByKey/aggregateByKey替代groupByKey
- 使用mapPartitions替代普通map
- 特别是在写DB的时候,避免每条写记录都new一个connection;推荐是每个partition new一个connection;更好的是new connection池,每个partition从中取即可,减少partitionNum个new的消耗
- 使用foreachPartitions替代foreach
- 使用filter之后进行coalesce操作
- 减少小文件数量
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
- 一边进行重分区的shuffle操作,一边进行排序
-
广播大变量
- 广播变量是executor内所有task共享的,避免了每个task自己维护一个变量,OOM
使用Kryo优化序列化性能
-
优化数据结构
- 原始类型(Int, Long)
- 字符串,每个字符串内部都有一个字符数组以及长度等额外信息
- 对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间
- 集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来封装集合元素,比如Map.Entry
- 尽量使用
字符串替代对象,使用原始类型(比如Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用,从而降低GC频率,提升性能
资源参数调优
运行时架构

- Client:客户端进程,负责提交作业
- Driver/SC:运行应用程序/业务代码的main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager/ResourceManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Drive
- SparkContext:整个应用程序的上下文,控制应用的生命周期
- DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中
- TaskScheduler:分配Task到Executor上执行,并维护Task的运行状态
- Executor:应用程序Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数
- Job:一个job包含多个RDD及作用于相应RDD上的各种Operation。每执行一个action算子(foreach, count, collect, take, saveAsTextFile)就会生成一个 job
- Stage:每个Job会被拆分很多组Task,每组Task被称为Stage,亦称TaskSet。一个作业job分为多个阶段stages(shuffle,串行),一个stage包含一系列的tasks(并行)
- Task:被送往各个Executor上的执行的内容,task之间无状态传递,可以并行执行
运行流程
client向YARN的ResourceManager/RM申请启动ApplicationMaster/AM(单个应用程序/作业的资源管理和任务监控)
RM收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,spark在此启动其AM,其中AM进行SparkContext/SC/Driver初始化启动并创建RDD Object、DAGScheduler、TASKScheduler
SC根据RDD的依赖关系构建DAG图,并将DAG提交给DAGScheduler解析为stage。Stages以TaskSet的形式提交给TaskScheduler,TaskScheduler维护所有TaskSet,当Executor向Driver发送心跳时,TaskScheduler会根据其资源剩余情况分配相应的Task,另外TaskScheduler还维护着所有Task的运行状态,重试失败了的Task
AM向RM申请container资源,资源到位后便与NodeManager通信,要求它在获得的Container中(executor)启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向AM中的SC注册并申请Task
AM中的SC分配Task给CoarseGrainedExecutorBackend/executor执行,CoarseGrainedExecutorBackend运行Task并向AM汇报运行的状态和进度,以便让AM随时掌握各个task的运行状态,从而可以在任务失败时重新启动任务或者推测执行
应用程序运行完成后,AM向RM申请注销并关闭自己
调优
- executor配置
- spark.executor.memory
- spark.executor.instances
- spark.executor.cores
- driver配置
- spark.driver.memory(如果没有collect操作,一般不需要很大,1~4g即可)
- spark.driver.cores
- 并行度
- spark.default.parallelism (used for RDD API)
- spark.sql.shuffle.partitions (usef for DataFrame/DataSet API)
- 网络超时
- spark.network.timeout (所有网络交互的默认超时)
- 数据本地化
- spark.locality.wait
- JVM/gc配置
- spark.executor.extraJavaOptions
- spark.driver.extraJavaOptions
数据倾斜调优
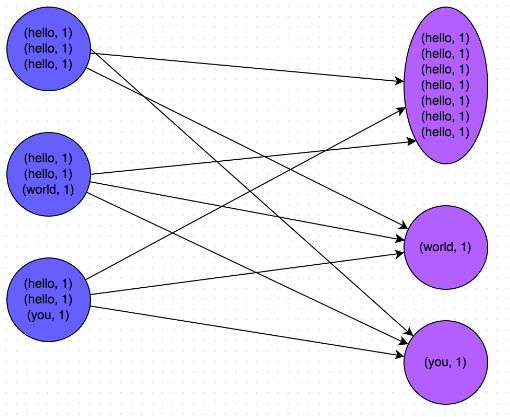
- 使用Hive ETL预处理数据
- 治标不治本(利用了mr的走disk特性),还多了一条skew pipeline
- 过滤少数导致倾斜的key
- 但有些场景倾斜是常态
- 提高shuffle操作的并行度
-
让每个task处理比原来更少的数据(之前可能task会%parNum分到2个key),但是如果单key倾斜,方法失效
 单个task分到的key少了
单个task分到的key少了
-
-
两阶段聚合(局部聚合+全局聚合)
- 附加随机前缀 -> 局部聚合 -> 去除随机前缀 -> 全局聚合
-
适用于聚合类shuffle(计算sum,count),但是对于join类shuffle不适用
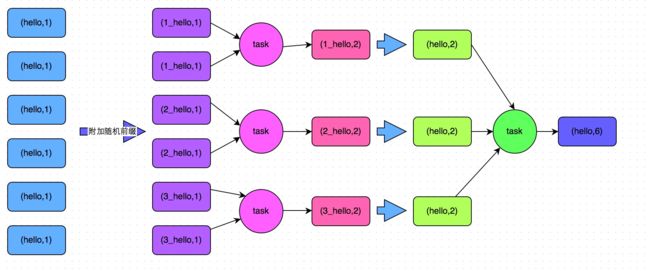 两阶段聚合
两阶段聚合
-
将reduce join转为map join
- 适用于join类shuffle,因为shuffle变成map操作了
- 只适用于一个大表和一个小表,将小表广播,并不适合两个都是大表
-
使用随机前缀和扩容RDD进行join
- leftDf添加随机前缀(1~N的);复制rightDf每条record至N条并依次打上前缀(1~N)
- 缺点是复制后的rightDf增大了N-1倍
Shuffle调优
shuffle原理
- Spark在DAG阶段以宽依赖shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write
- 下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑
- 下图中,上游stage有3个map task,下游stage有4个reduce task,那么这3个map task中每个map task都会产生4份数据。而4个reduce task中的每个reduce task都会拉取上游3个map task对应的那份数据

shuffle演进
- <0.8 hashBasedShuffle
- 每个map端的task为每个reduce端的partition/task生成一个文件,通常会产生大量的文件,伴随大量的随机磁盘IO操作与大量的内存开销
M*R
- 每个map端的task为每个reduce端的partition/task生成一个文件,通常会产生大量的文件,伴随大量的随机磁盘IO操作与大量的内存开销
- 0.8.1 引入文件合并File Consolidation机制
- 每个executor为每个reduce端的partition生成一个文件
E*R
- 每个executor为每个reduce端的partition生成一个文件
- 0.9 引入External AppendOnlyMap
- combine时可以将数据spill到磁盘,然后通过堆排序merge
- 1.1 引入sortBasedShuffle
- 每个map task不会为每个reducer task生成一个单独的文件,而是会将所有的结果写到一个文件里,同时会生成一个index文件,reducer可以通过这个index文件取得它需要处理的数据
M
- 每个map task不会为每个reducer task生成一个单独的文件,而是会将所有的结果写到一个文件里,同时会生成一个index文件,reducer可以通过这个index文件取得它需要处理的数据
- 1.4 引入Tungsten-Sort Based Shuffle
- 亦称unsafeShuffle,将数据记录用序列化的二进制方式存储,把排序转化成指针数组的排序,引入堆外内存空间和新的内存管理模型
- 1.6 Tungsten-sort并入Sort Based Shuffle
- 由SortShuffleManager自动判断选择最佳Shuffle方式,如果检测到满足Tungsten-sort条件会自动采用Tungsten-sort Based Shuffle,否则采用Sort Based Shuffle
- 2.0 hashBasedShuffle退出历史舞台
- 从此Spark只有sortBasedShuffle
调优
shuffle是一个涉及到CPU(序列化反序列化)、网络IO(跨节点数据传输)以及磁盘IO(shuffle中间结果落盘)的操作。所以用户在编写Spark应用程序的过程中应当尽可能避免shuffle算子和考虑shuffle相关的优化,提升spark应用程序的性能。
要减少shuffle的开销,主要有两个思路,
- 减少shuffle次数,尽量不改变key,把数据处理在local完成
- 减少shuffle的数据规模
- 先去重,再合并
-
A.union(B).distinct()vs.A.distinct().union(B.distinct()).distinct()
-
- 用broadcast + filter来代替join
- spark.shuffle.file.buffer
- 设置shuffle write task的buffer大小,将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘
- spark.reducer.maxSizeInFlight
- 设置shuffle read task的buffer大小,决定了每次能够拉取pull多少数据。减少拉取数据的次数,也就减少了网络传输的次数
- spark.shuffle.sort.bypassMergeThreshold
- shuffle read task的数量小于这个阈值(默认是200),则map-side/shuffle write过程中不会进行排序操作
Spark的join类型
Shuffled Hash Join
Sort Merge Join
Broadcast Join

其他优化项
- 使用DataFrame/DataSet
- spark sql 的catalyst优化器,
- 堆外内存(有了Tungsten后,感觉off-head没有那么明显的性能提升了)

| Type | RDD | DataFrame | DataSet |
|---|---|---|---|
| definition | RDD是分布式的Java对象的集合 | DataFrame是分布式的Row对象的集合 | DataSet是分布式的Java对象的集合 ds = df.as[ElementType] df = Dataset[Row] |
| pros | * 编译时类型安全 * 面向对象的编程风格 |
* 引入schema结构信息 * 减少数据读取,优化执行计划,如filter下推,剪裁 * off-heap堆外存储 |
* Encoder序列化 * 支持结构与非结构化数据 * 和rdd一样,支持自定义对象存储 * 和dataframe一样,支持结构化数据的sql查询 * 采用堆外内存存储,gc友好 * 类型转化安全,代码有好 |
| cons | * 对于结构化数据不友好 * 默认采用的是java序列化方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁 |
* rdd内部数据直接以java对象存储,dataframe内存存储的是Row对象而不能是自定义对象 * 编译时不能类型转化安全检查,运行时才能确定是否有问题 |
* 可能需要额外定义Encoder |
- 待补充
Reference
- Spark性能优化指南——基础篇
- Spark性能优化指南——高级篇
- Spark Tutorials
- 手把手教你 Spark 性能调优
- Spark性能调优分享
- Tuning Spark
- Apache Spark Performance Tuning – Degree of Parallelism
- Spark Performance Tuning: A Checklist
- Spark性能优化
- Spark Shuffle的技术演进
- Spark shuffle introduction
- Apache Spark 内存管理详解