所有的垃圾回收器的目的都是朝着减少STW的目的而前进,G1(Garbage First)回收器的出现颠覆了之前版本CMS、Parallel等垃圾回收器的分代收集方式,从2004年Sun发布第一篇关于G1的论文后,直到2012年JDK7发布更新版本,花了将近10年的时间G1才达到商用的程度,而到JDK9发布之后,G1成为了默认的垃圾回收器,CMS也变相地相当于被淘汰了。
G1结构
G1抛弃了之前的分代收集的方式,面向整个堆内存进行回收,把内存划分为多个大小相等的独立区域Region。
一共有4种Region:
- 自由分区Free Region
- 年轻代分区Young Region,年轻代还是会存在Eden和Survivor的区分
- 老年代分区Old Region
- 大对象分区Humongous Region
每个Region的大小通过-XX:G1HeapRegionSize来设置,大小为1~32MB,默认最多可以有2048个Region,那么按照默认值计算G1能管理的最大内存就是32MB*2048=64G。
对于大对象的存储,存在Humongous概念,对G1来说,超过一个Region一半大小的对象都被认为大对象,将会被放入Humongous Region,而对于超过整个Region的大对象,则用几个连续的Humongous来存储(如下图H区域)。

G1优势
上面我们也提到,垃圾回收器的最终目的都是为了减少STW造成的停顿,比如之前老的垃圾回收器CMS这种带来的停顿时间是不可预估的。
而G1最大的优势就在于可预测的停顿时间模型,我们可以自己通过参数-XX:MaxGCPauseMillis来设置允许的停顿时间(默认200ms),G1会收集每个Region的回收之后的空间大小、回收需要的时间,根据评估得到的价值,在后台维护一个优先级列表,然后基于我们设置的停顿时间优先回收价值收益最大的Region。
那么,这个可预测的停顿时间模型怎么计算和建立的?主要是基于衰减平均值的理论基础,衰减平均是一种数学方法,用来计算一个数列的平均值,给近期的数据更高的权重,强调近期数据对结果的影响,代码如下:
hotspot/src/share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
double get_new_prediction(TruncatedSeq* seq) {
return MAX2(seq->davg() + sigma() * seq->dsd(),
seq->davg() * confidence_factor(seq->num()));
}davg表示衰减值
sigma表示一个系数,代表信贷度,默认值为0.5
dsd表示衰减标准偏差
confidence_factor表示可信度系数,用于当样本数据不足(小于5个)时取一个大于1的值,样本数据越少该值越大。
基于这个模型,G1希望根据用户设置的停顿时间(只是期望时间,尽量努力在这个范围内完成GC)来选择需要对哪些Region进行回收,能回收多大空间。
比如过去10次回收10G内存花费1s,如果预设的停顿时间是200ms,那么就最多可以回收2G的内存空间。
空间分配&扩展
既然G1还是存在新生代和老年代的概念,那么新生代和老年代的空间是怎么划分的呢?
在G1中,新增了两个参数G1MaxNewSizePercent、G1NewSizePercent,用来控制新生代的大小,默认的情况下G1NewSizePercent为5,也就是占整个堆空间的5%,G1MaxNewSizePercent默认为60,也就是堆空间的60%。
假设现在我们的堆空间大小是4G,按照默认最大2048个Region计算,每个Region的大小就是2M。
初始新生代的大小那么就是200M,大约100个Region格子,动态扩展最大就是60%*4G=2.4G大小。
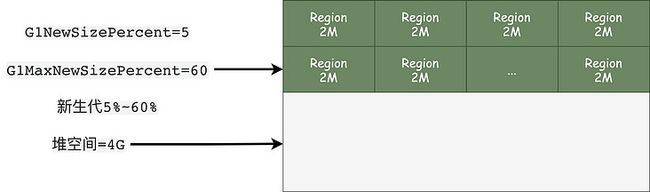
不过显然,事情不是这么简单,实际上初始化新生代的空间大小逻辑还是挺复杂的。
首先,我们通过原有参数-Xms设置初始堆的大小,-Xmx设置最大堆的大小还是生效的,可以设置堆的大小。
- 可以通过原有参数
-Xmn或者新的参数G1NewSizePercent、G1MaxNewSizePercent来设置年轻代的大小,如果设置了-Xmn相当于设置G1NewSizePercent=G1MaxNewSizePercent。 - 接着看是不是设置了
-XX:NewRatio(表示年轻代与老年代比值,默认值为2,代表年轻代老年代大小为1:2),如果1都设置了,那么忽略NewRatio,反之则代表G1NewSizePercent=G1MaxNewSizePercent,并且分配规则还是按照NewRatio的规则。 - 如果只是设置了
G1NewSizePercent、G1MaxNewSizePercent中的一个,那么就按照这两个参数的默认值5%和60%来设置。 - 如果设置了
-XX:SurvivorRatio,默认为8,那么Eden和Survivor还是按照这个比例来分配
按照这个规则,我们新生代和老年代的空间分配基本就完成,如果说新生代走默认的规则,每次动态扩展空间大小怎么办?
有一个参数叫做-XX:GCTimeRatio表示GC时间与应用耗费时间比,默认为9,就是说GC时间和应用时间占比超过10%才进行扩展,扩展比例为20%,最小不能小于1M。
回收过程
G1的回收过程分为以下四个步骤:
- 初始标记:标记GC ROOT能关联到的对象,需要STW
- 并发标记:从GCRoots的直接关联对象开始遍历整个对象图的过程,扫描完成后还会重新处理并发标记过程中产生变动的对象
- 最终标记:短暂暂停用户线程,再处理一次,需要STW
- 筛选回收:更新Region的统计数据,对每个Region的回收价值和成本排序,根据用户设置的停顿时间制定回收计划。再把需要回收的Region中存活对象复制到空的Region,同时清理旧的Region。需要STW。
总的来说这是一个偏向记忆的回收过程,知道就行了。
相对于之前我们存在分代概念的GC来说,G1其实也是类似的过程,总体可以分为这两种:
- 年轻代GC,年轻代Region在超过我们默认设置的最大大小之后就会触发GC,还是用的我们熟悉的复制算法,Eden和Survivor来回倒腾,这里不再赘述。
- Mixed GC混合回收,混合回收类似于之前我们的Full GC概念,既会回收年轻代的Region,也会回收老年代的Region,还有我们新的Humongous大对象区域。触发规则根据参数
-XX:InitiatingHeapOccupancyPercent(默认45%)值,也就是说老年代Region达到整个堆内存的45%时触发Mixed GC。
其他问题
上面应该把基本概念都解释完了。
比如什么是G1?G1有什么特点?他的优点是什么?划分Region后怎么分配空间?怎么进行垃圾回收?什么时候进行YGC?什么时候进行FGC?可靠的停顿时间模型建立方式?
除此之外,其实还有一些较为复杂的问题,比如之前我们说分代收集有跨代引用的问题,划分Region之后应该也有对不对,那怎么解决的?
还有之前我们说并发收集阶段怎么解决用户线程和收集线程互不干扰的?
这些更深一点的问题其实在现在已经卷到需要问三色标记了吗?已经说到了很多了,下面我们再详细点说明下在G1中的一些不同点。
记忆集
在这篇文章中我们提到过一次关于Remembered Set的概念,为了避免GC时扫描整个堆内存,用来标志哪些区域存在跨代引用,对于G1来说也一样,只不过G1的记忆集会更复杂一点。
每个Region中都存在一个Hash Table结构的记忆集,Key为其他Region的起始地址,Value是其他Card Table卡表的索引集合。
原来我们的卡表指向的是卡页的内存地址段,代表我引用了谁,现在的记忆集则是代表着谁引用了我,因此收集的过程会更复杂一点,并且需要额外的10%~20%的堆内存空间来维持。
维护记忆集的方式也和卡表类似,通过写屏障来实现。
原始快照SATB
在三色标记中我们也提到过,并发标记用户线程和收集线程一起工作会产生问题,解决方案CMS使用的是增量更新,G1则是用原始快照。
总结
写这些东西比较费劲,因为总在想在理解的基础上怎么写的更通俗易懂,但是发现好像并不容易,因为自己也都是看完没过多久就忘记了,所以记录下来,能看懂就行了,实在不行就去看书。
周老师的深入Java虚拟机写的比较简单,很多东西要去搜资料和书结合看才能看明白,另外一本书写的也不是很好,作者感觉只是堆砌知识点,看起来很费劲,美团写的那篇文章也是一大堆名词,不知道的人看的简直蛋疼。
我应该,比他们写的更通俗一点就好了?
参考:
彭成寒《JVM G1源码分析和调优》
周志明《深入理解Java虚拟机第三版》