序
本文整理了Single Producer/Consumer lock free Queue step by step这篇文章里头关于高性能的SPSC无锁队列使用遵循的四个原则:
- 单写原则
- 使用lazySet替代volatile set
- 使用位运算替代取模运算
- 避免伪共享
- 减少缓存一致性冲突
1.Single Writer Principle(单写原则)
如果只有一个线程对资源进行写操作,它实际上是比你想象的更容易,这个方案是可行的,无需CPU浪费管理资源争夺或上下文切换。当然,如果有多个线程读取相同的数据。CPU可以通过高速缓存一致性的子系统广播只读数据的拷贝到其他核。这虽然有成本的,但它的尺度非常好。
多个线程如果同时写同一个资源,必有争夺,就需要用锁或乐观锁等堵塞方法,而非堵塞的单线程写比多线程写要快,能获得高吞吐量和低延迟,特别是多核情况,一个线程一个CPU核,大大增加其他CPU核并行运行其他线程的概率。
| Method | Time (ms) |
|---|---|
| One Thread | 300 |
| One Thread with Memory Barrier | 4,700 |
| One Thread with CAS | 5,700 |
| Two Threads with CAS | 18,000 |
| One Thread with Lock | 10,000 |
| Two Threads with Lock | 118,000 |
Disruptor分离了关注,真正实现单写原则。(Disruptor的特点是将多线程生产者通过Ringbuffer变成单线程消费者,通过单线程消费者对共享资源进行写操作)
目前 Node.js, Erlang, Actor 模式, SEDA 都采取了单写解决方案,但是他们大多数使用基于队列的下实现的,它打破单独写原则
2.使用lazySet替代volatile set
- lazySet是使用Unsafe.putOrderedObject方法,会前置一个store-store barrier(在当前的硬件体系下或者是no-op或者非常轻),而不是store-load barrier。
- store-load barrier较慢,总是用在volatile的写操作上。在操作序列Store1; StoreStore;Store2中,Store1的数据会在Store2和后续写操作之前对其它处理器可见。换句话说,就是保证了对其它数据可见的写的顺序。
- 如果只有一个线程写我们就用不着store-load barrier,lazySet和volatile set在单写原则下面是等价的。
- 这种性能提升是有代价的,虽然廉价,也就是写后结果并不会被其他线程看到,甚至是自己的线程,通常是几纳秒后被其他线程看到,lazySet的写在实践上来延迟是纳秒级,这个时间比较短,所以代价可以忍受。
- 类似Unsafe.putOrderedObject还有unsafe.putOrderedLong等方法,unsafe.putOrderedLong比使用 volatile long要快3倍左右。
3.使用位运算替代取模运算
比如这段
public boolean offer(final E e) {
if (null == e) {
throw new NullPointerException("Null is not a valid element");
}
final long currentTail = tail;
final long wrapPoint = currentTail - buffer.length;
if (head <= wrapPoint) {
return false;
}
buffer[(int) (currentTail % buffer.length)] = e;
tail = currentTail + 1;
return true;
}
使用位运算之后
mask = capacity - 1;
public boolean offer(final E e) {
if (null == e) {
throw new NullPointerException("Null is not a valid element");
}
final long currentTail = tail.get();
final long wrapPoint = currentTail - buffer.length;
if (head.get() <= wrapPoint) {
return false;
}
buffer[(int) currentTail & mask] = e;
tail.lazySet(currentTail + 1);
return true;
}
性能对比
x % 8 == x & (8 - 1) 但是位运算速度更快
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 5, time = 3, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 20, time = 3, timeUnit = TimeUnit.SECONDS)
@Fork(1)
@State(Scope.Benchmark)
public class ModuloMaskTest {
private static final int LENGTH = 16;
int[] ints = new int[LENGTH];
int mask = LENGTH - 1;
int someIndex = 5;
@Benchmark
public int moduloLengthNoMask() {
return someIndex % ints.length;
}
@Benchmark
public int moduloLengthMask() {
return someIndex & (ints.length - 1);
}
@Benchmark
public int moduloConstantLengthNoMask() {
return someIndex % LENGTH;
}
@Benchmark
public int moduloMask() {
return someIndex & mask;
}
@Benchmark
public int consume() {
return someIndex;
}
@Benchmark
public void noop() {
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(".*" +ModuloMaskTest.class.getSimpleName()+ ".*")
.forks(1)
.build();
new Runner(opt).run();
}
}
结果如下:
# Run complete. Total time: 00:07:34
Benchmark Mode Cnt Score Error Units
ModuloMaskTest.consume avgt 20 3.099 ± 0.152 ns/op
ModuloMaskTest.moduloConstantLengthNoMask avgt 20 3.430 ± 0.509 ns/op
ModuloMaskTest.moduloLengthMask avgt 20 3.505 ± 0.058 ns/op
ModuloMaskTest.moduloLengthNoMask avgt 20 6.490 ± 0.143 ns/op
ModuloMaskTest.moduloMask avgt 20 3.304 ± 0.159 ns/op
ModuloMaskTest.noop avgt 20 0.404 ± 0.010 ns/op
可以发现%操作性能最差要6.x纳秒,&操作基本在3ns左右
4.避免伪共享
L1 L2 L3 cache
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在 L1 缓存中。
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80ns | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
定义
Cache是由很多个cache line组成的。每个cache line通常是64字节,并且它有效地引用主内存中的一块儿地址。一个Java的long类型变量是8字节,因此在一个缓存行中可以存8个long类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此你能非常快的遍历这个数组。事实上,你可以非常快速的遍历在连续内存块中分配的任意数据结构。这种无法充分使用缓存行特性的现象,称为伪共享。
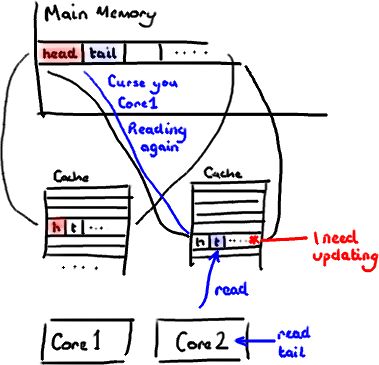
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手。
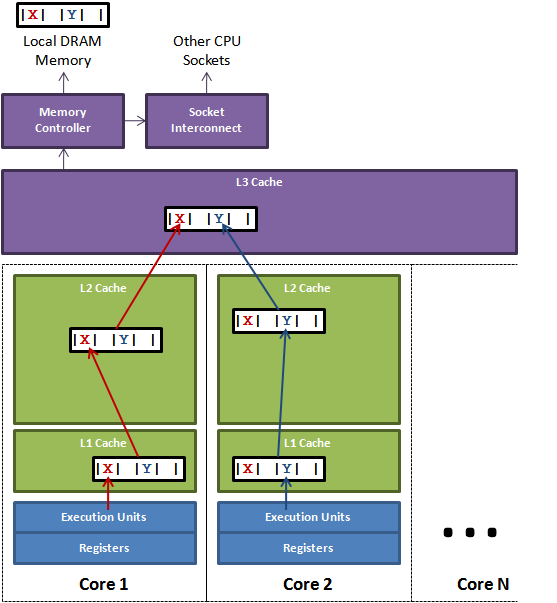
图1说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
解决
对于伪共享,一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。在jdk1.8中,有专门的注解@Contended来避免伪共享,更优雅地解决问题。
@Contended
public class VolatileLong {
public volatile long value = 0L;
}
public class FalseSharingJdk8 implements Runnable {
public static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseSharingJdk8(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
/**
* -XX:-RestrictContended
* –XX:+PrintFieldLayout --- 只是在调试版jdk有效
* @param args
* @throws Exception
*/
public static void main(final String[] args) throws Exception {
Thread.sleep(10000);
System.out.println("starting....");
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingJdk8(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
}
没有使用注解的话,需要自己去填充
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
5.减少缓存一致性冲突
只要系统只有一个CPU核在工作,一切都没问题。如果有多个核,每个核又都有自己的缓存,那么我们就遇到问题了:如果某个CPU缓存段中对应的内存内容被另外一个CPU偷偷改了,会发生什么?
缓存一致性协议就是为了解决这个问题而设计的,使多组缓存的内容保持一致,即使用多组缓存,但使它们的行为看起来就像只有一组缓存那样。
private final AtomicLong tail = new AtomicLong(0);
private final AtomicLong head = new AtomicLong(0);
public static class PaddedLong {
public long value = 0, p1, p2, p3, p4, p5, p6;
}
private final PaddedLong tailCache = new PaddedLong();
private final PaddedLong headCache = new PaddedLong();
public boolean offer(final E e) {
if (null == e) {
throw new NullPointerException("Null is not a valid element");
}
final long currentTail = tail.get();
final long wrapPoint = currentTail - capacity;
if (headCache.value <= wrapPoint) {
headCache.value = head.get();
if (headCache.value <= wrapPoint) {
return false;
}
}
buffer[(int) currentTail & mask] = e;
tail.lazySet(currentTail + 1);
return true;
}
public E poll() {
final long currentHead = head.get();
if (currentHead >= tailCache.value) {
tailCache.value = tail.get();
if (currentHead >= tailCache.value) {
return null;
}
}
final int index = (int) currentHead & mask;
final E e = buffer[index];
buffer[index] = null;
head.lazySet(currentHead + 1);
return e;
}
对比没有cache的版本
private final AtomicLong tail = new AtomicLong(0);
private final AtomicLong head = new AtomicLong(0);
public boolean offer(final E e) {
if (null == e) {
throw new NullPointerException("Null is not a valid element");
}
final long currentTail = tail.get();
final long wrapPoint = currentTail - buffer.length;
if (head.get() <= wrapPoint) {
return false;
}
buffer[(int) currentTail & mask] = e;
tail.lazySet(currentTail + 1);
return true;
}
public E poll() {
final long currentHead = head.get();
if (currentHead >= tail.get()) {
return null;
}
final int index = (int) currentHead & mask;
final E e = buffer[index];
buffer[index] = null;
head.lazySet(currentHead + 1);
return e;
}
对比数据
0 - ops/sec=56,689,539 - OneToOneConcurrentArrayQueue2 result=777
1 - ops/sec=33,578,974 - OneToOneConcurrentArrayQueue2 result=777
2 - ops/sec=54,105,692 - OneToOneConcurrentArrayQueue2 result=777
3 - ops/sec=84,290,815 - OneToOneConcurrentArrayQueue2 result=777
4 - ops/sec=79,851,727 - OneToOneConcurrentArrayQueue2 result=777
-----
0 - ops/sec=110,506,679 - OneToOneConcurrentArrayQueue3 result=777
1 - ops/sec=117,252,276 - OneToOneConcurrentArrayQueue3 result=777
2 - ops/sec=115,639,936 - OneToOneConcurrentArrayQueue3 result=777
3 - ops/sec=116,555,884 - OneToOneConcurrentArrayQueue3 result=777
4 - ops/sec=115,712,336 - OneToOneConcurrentArrayQueue3 result=777
整体上有一定的提升。
doc
- Single Producer/Consumer lock free Queue step by step
- Single Writer Principle
- Atomic*.lazySet is a performance win for single writers
- 单独写原则Single Writer Principle
- Java性能优化要点之五: 队列与lazySet
- 学习一下Disruptor
- The Mythical Modulo Mask
- 伪共享和缓存行填充,从Java 6, Java 7 到Java 8
- Java8的伪共享和缓存行填充--@Contended注释
- Diving Deeper into Cache Coherency
- 缓存一致性(Cache Coherency)入门
- 伪共享(False Sharing)