说明:个人练手python用。
操作系统:window10 x64
IDE:Pycharm 2017.2.2
Python版本:3.6.2
本文参考自:https://www.shiyanlou.com/courses/623/labs/2072/document
一、接口获取
打开12306,在余票查询页面,点击F12,点击查询按钮

通过Network可以查询到本次查询时所有的网络请求接口,这里的第二个接口就是火车票数据查询的接口,如下:
https://kyfw.12306.cn/otn/leftTicket/queryX?leftTicketDTO.train_date=2017-09-25&leftTicketDTO.from_station=ZZF&leftTicketDTO.to_station=KFF&purpose_codes=ADULT
其中:
1、leftTicketDTO.train_date表示查询日期
2、leftTicketDTO.from_station:表示出发地编码
3、leftTicketDTO.to_station:表示目的地编码
4、purpose_codes:表示票的类型,ADULT表示成人,如果是学生,则值为0X00
也就是网页中我们填上去的参数,很好对应上:

访问该接口,就可以获取本次查询的全部JSON格式的数据了:

二、数据分析
把上述比较乱的数据中的result部分(车票部分)存入文本,然后导入到excel(用|分割即可),然后删除没用的列,空列等,看起来就规整多了,像这样:
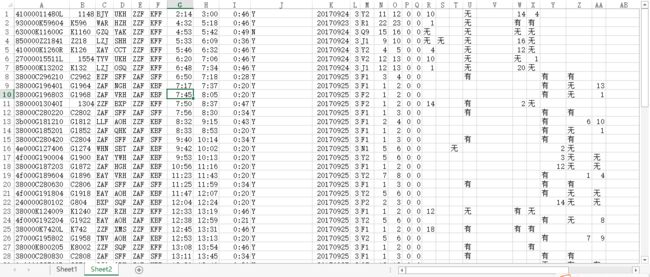
然后对比着12306上面的查询结果
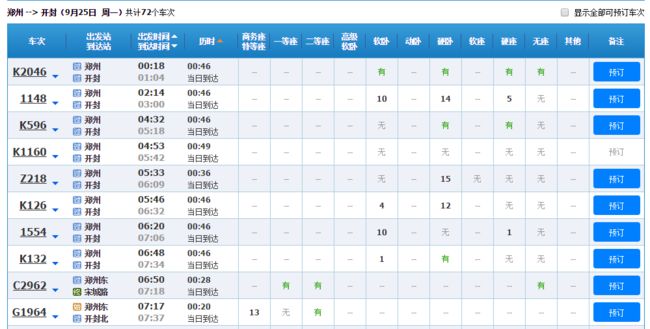
很容易分析出每列的含义:

这就是本工具的数据基础,接下来就简单了:
1、使用python请求接口获取数据
2、数据格式调整并展示
三、使用python获取数据
定义方法用于请求接口数据,如下:
def get_json(url, train_date, from_station, to_station, purpose_codes='ADULT'):
url = url + '?leftTicketDTO.train_date=' + train_date + '&leftTicketDTO.from_station=' + from_station + '&leftTicketDTO.to_station=' + to_station + '&purpose_codes=' + purpose_codes
req = request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')
req.add_header('Cookie',
'BLPROV=; JSESSIONID=17F82C085BEAE9774B1D7D18363207AA; route=6f50b51faa11b987e576cdb301e545c4; BIGipServerotn=1473839370.50210.0000; fp_ver=4.5.1; RAIL_EXPIRATION=1505522206734; RAIL_DEVICEID=ngfa0xXXc43Aw-RdePQiYKNAXLxgF_0NC4u29FDPVr73XbEdk2jAZXdZmGwbMs5tmX28EVf3pqQWywtJRANyU-F1F4o1jEN2J8gI5mQVerkJAel9E5ACri_F-7hggwk7zmV0IkRNjiH5CA0RFxBPLTsBkmBvAJ9_; current_captcha_type=C; _jc_save_fromStation=%u90D1%u5DDE%2CZZF; _jc_save_toStation=%u5F00%u5C01%2CKFF; _jc_save_fromDate=2017-09-25; _jc_save_toDate=2017-09-25; _jc_save_wfdc_flag=wf')
with request.urlopen(req) as f:
return json.loads(f.read())
注意这里的request header中要添加cookie信息,否则报405错误!感觉两者没有直接关系,但结果就是这样,不知道为啥。
然后根据上面分析的结果,json解析及拆分展示如下:
def list_ticket():
json_result = get_json('https://kyfw.12306.cn/otn/leftTicket/queryX', '2017-09-25', 'ZZF', 'KFF')
list_tickets = json_result['data']['result']
print("车次", "始发站", "终点站", "出发站", "到达站", "出发时间", "到达时间", "历时", "商务座", "一等座", "二等座", "软卧", "硬卧", "软座", "硬座", "无座",
"备注")
for ticket in list_tickets:
list_ticket_item = ticket.split('|')
print(list_ticket_item[3], list_ticket_item[4], list_ticket_item[5], list_ticket_item[6], list_ticket_item[7],
list_ticket_item[8], list_ticket_item[9], list_ticket_item[10], list_ticket_item[32], list_ticket_item[31],
list_ticket_item[30], list_ticket_item[23], list_ticket_item[28], list_ticket_item[24],
list_ticket_item[29], list_ticket_item[26], list_ticket_item[11])
运行输出结果为:

四、车站名称和编码
上述步骤虽然查询到了结果,但是有两方面的问题
1、车站名称应该显示中文名称,而不是编码,并且应该能查询任意两站的火车票信息。
2、直接print打印格式比较乱
先来说第一点:
在余票查询页面上右击--查看源代码--大概962行,可以看到如下js文件:
点击该js文件链接可以看到

该文件包含了全部的站名称和对应编码,根据该文件,前端页面把从后台查询到的编码转为了火车站中文名称。
写个python把站名和对应编码拿下来:
import re
import requests
from pprint import pprint
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9025'
response = requests.get(url, verify=False)
stations = re.findall(u'([\u4e00-\u9fa5]+)\|([A-Z]+)', response.text)
print(dict(stations), indent=4)
# 反转dict
dict_res = dict(stations)
dict_res = dict(zip(dict_res.values(), dict_res.keys()))
print(dict_res)
结果如下:


把这些数据作为字典,存在py文件中,就可以直接当dict用了。
经过上述改进,输出结果如下:

五、格式化
可以使用第三方模块prettytable对控制台输出结果美化,结果如下:
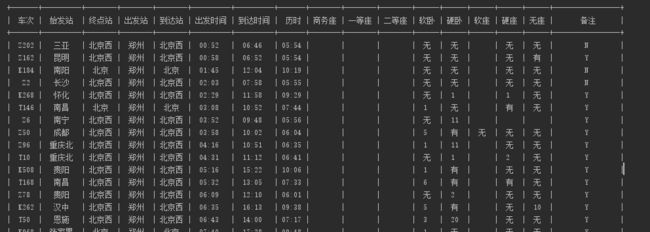
六、补充说明
1、如果在请求HTTPS协议时碰到证书问题,则在最前面加上一句:
ssl._create_default_https_context = ssl._create_unverified_context
2、可以使用colorama模块对控制台进行着色处理,这个没做。
七、完整代码
完整代码