SIGIR 2021 | 广告系统位置偏差的CTR模型优化方案
美团到店广告平台算法团队基于多年来在广告领域上积累的经验,一直在数据偏差等业界挑战性问题不断进行深入优化与算法创新。在之前分享的《KDD Cup 2020 Debiasing比赛冠军技术方案与广告业务应用》一文[4]中,团队分享了在KDD Cup比赛中取得冠军的选择性偏差以及流行度偏差的解决方案,同时也分享了在广告业务上偏差优化的技术框架。
本文基于这一技术框架进行继续介绍,聚焦于位置偏差问题的最新进展,并详细地介绍团队在美团广告取得显著业务效果的位置偏差CTR模型优化方案,以该方案为基础形成的论文《Deep Position-wise Interaction Network for CTR Prediction》也被国际顶级会议SIGIR 2021录用。
近些年来,由于人工智能技术的高速发展,所带来的公平性问题也愈发受到关注。同样的,广告技术也存在着许多公平性问题,由于公平性问题造成的偏差对广告系统的生态会产生较大的负面影响。图1所示的是广告系统中的反馈环路[1],广告系统通过累积的用户交互反馈数据基于一定的假设去训练模型,模型对广告进行预估排序展示给用户,用户基于可看到的广告进行交互进而累积到数据中。在该环路中,位置偏差、流行度偏差等各种不同类型的偏差会在各环节中不断累积,最终导致广告系统的生态不断恶化,形成“强者愈强、弱者愈弱”的马太效应。

由于偏差对广告系统和推荐系统的生态有着极大的影响,针对消除偏差的研究工作也在不断增加。比如国际信息检索会议SIGIR在2018年和2020年组织了一些关注于消除偏差主题的专门会议,同时也给一些基于偏差和公平性的论文颁发了最佳论文奖(Best Paper)[2,3]。KDD Cup 2020的其中一个赛道也基于电子商务推荐中的流行度偏差进行开展[1]。
1. 背景
美团到店广告平台广告算法团队基于美团和点评双侧的广告业务场景,不断进行广告前沿技术的深入优化与算法创新。在大多数广告业务场景下,广告系统被分为四个模块,分别是触发策略、创意优选、质量预估以及机制设计,这些模块构成一个广告投放漏斗从海量广告中过滤以及精选出优质广告投放给目标用户。其中,触发策略从海量广告中挑选出满足用户意图的候选广告集合,创意优选负责候选广告的图片和文本生成,质量预估结合创意优选的结果对每一个候选广告进行质量预估,包括点击率(CTR)预估、转化率(CVR)预估等,机制排序结合广告质量以及广告出价进行优化排序。在本文中,我们也将广告称之为item。
CTR预估,作为质量预估的一个环节,是计算广告中最核心的算法之一。在每次点击付费(CPC)计费模式下,机制设计可以简单地按每千次展示收入(eCPM)来对广告进行排序以取得广告收入最大化。由于eCPM正比于CTR和广告出价(bid)的乘积。因此,CTR预估会直接影响到广告的最终收入和用户体验。为了有更高的CTR预估精度,CTR预估从早期的LR[5]、FM[6]、FFM[7]等支持大规模稀疏特征的模型,到XGBoost[8]、LightGBM[9]等树模型的结合,再到Wide&Deep[10]、Deep&Cross[11]、DeepFM[12]、xDeepFM[13]等支持高阶特征交叉的深度学习模型,进一步演化到DIN[14]、DIEN[15]、DSIN[16]等结合用户行为序列的深度学习模型,一直作为工业界以及学术界研究的热点领域之一,被不断探索和不断创新。
由于CTR预估模型的训练通常采用曝光点击数据,该数据是一种隐式反馈数据,所以会不可避免地产生各种偏差问题。其中,位置偏差因对CTR影响极大而备受关注。如图2所示,随机流量上不同位置的CTR分布反应了用户通常倾向于点击靠前位置的广告,并且CTR会随着曝光位置的增大而迅速下降。因此,直接在曝光点击数据上进行训练,模型不可避免地会偏向于靠前位置的广告集合,造成位置偏差问题。图2显示正常流量相比随机流量CTR分布更加集中在高位置广告上,通过反馈环路,这一问题将不断地放大,并且进一步损害模型的性能。因此,解决好位置偏差问题不仅能够提升广告系统的效果,而且还能平衡广告系统的生态,促进系统的公平性。

广告最终的真实曝光位置信息在线上预估时是未知的,这无疑进一步增大了位置偏差问题的解决难度。现有的解决位置偏差的方法可以大致分为以下两种:
-
神经网络位置特征建模:该方法将位置建模为神经网络中的特征,由于在预估过程中并不知道真实位置信息,故而有些方法[17-19]把位置信息放于网络的Wide部分,在线下训练时使用真实位置,在线上预估时使用固定位置,这种方法由于其简单性和有效性,在工业界被广泛应用。为了在线上预估时无需使用位置信息,如图3所示,PAL[20]将样本的CTR建模为ProbSeen乘以pCTR,其中ProbSeen仅使用位置特征建模,而pCTR使用其他信息建模,在线上只使用pCTR作为CTR预估值。

-
Inverse Propensity Weighting(IPW):该方法被学术界广泛研究[21-29],其在模型训练时给不同曝光位置的样本赋予不同的样本权重,直观地看,应该将具有较低接收反馈倾向的广告样本(曝光位置靠后的广告)分配较高的权重。因此,这种方法的难点就在于不同位置的样本权重如何确定,一个简单的方法是使用广告随机展示的流量来准确地计算位置CTR偏差,但不可避免地损害用户体验。故而,许多方法致力于在有偏的流量上来准确地预估位置偏差。
上述的方法通常基于一个较强的假设,即点击伯努利变量依赖于两个潜在的伯努利变量E和,如下式所示:

其中,等式左边指的是用户在上下文中点击第个广告的概率,我们定义上下文为实时的请求信息。等式右边第一项指的是位置被查看的概率,其中通常为上下文的一个子集,大部分方法假设为空集,即位置被查看的概率仅与有关。等式右边第二项指的是相关性概率(例如用户在上下文中对广告的的真实兴趣)。上述方法通常显式或隐式地估计查看概率,然后利用反事实推理(Counterfactual Inference)得出相关性概率,最终在线上将相关性概率作为CTR的预估值。训练和预估之间位置信息的不同处理将不可避免地导致线下线上间的不一致问题,进一步导致次优的模型性能。
此外,已有方法通常假设查看概率仅依赖于位置及部分上下文信息,其假设过于简单。不同的用户通常具有不同的浏览习惯,有些用户可能倾向于浏览更多item,而有些用户通常能快速做出决定,并且同一个用户在不同的上下文中搜索意图中也会有不同的位置偏好,例如商场等地点词的搜索往往意图不明确导致高低位置的CTR差异并不大。故而,位置偏差与用户,上下文有关,甚至可能与广告本身也有关,建模它们间的关系能更好地解决位置偏差问题。
不同于上述的方法,本文提出了一个基于深度位置交叉网络(Deep Position-wise Interaction Network)(DPIN)模型的多位置预估方法去有效地直接建模来提高模型性能,其中是第个广告在第个位置的CTR预估值。该模型有效地组合了所有候选广告和位置,以预估每个广告在每个位置的CTR,实现线下线上的一致性,并在在线服务性能限制的情况下支持位置、用户、上下文和广告之间的深度非线性交叉。广告的最终序可以通过最大化来确定,其中为广告的出价,本文在线上机制采用一个位置自顶向下的贪婪算法去得到广告的最终序。本文的贡献如下:
-
本文在DPIN中使用具有非线性交叉的浅层位置组合模块,该模块可以并行地预估候选广告和位置组合的CTR,达到线下线上的一致性,并大大改善了模型性能。
-
不同于以往只对候选广告进行用户兴趣建模,本次首次提出对候选位置也进行用户兴趣建模。DPIN应用一个深度位置交叉模块有效地学习位置,用户兴趣和上下文之间的深度非线性交叉表示。
-
根据对于位置的新处理方式,本文提出了一种新的评估指标PAUC(Position-wise AUC),用于测量模型在解决位置偏差问题上的模型性能。本文在美团广告的真实数据集上进行了充分的实验,验证了DPIN在模型性能和服务性能上都能取得很好的效果。同时本文还在线上部署了A/B Test,验证了DPIN与高度优化的已有基线相比有显著提升。
2. 深度位置交叉网络(Deep Position-wise Interaction Network)
本节主要介绍深度位置交叉网络(Deep Position-wise Interaction Network)(DPIN)模型。如图4所示,DPIN模型由三个模块组成,分别是处理个候选广告的基础模块(Base Module),处理个候选位置的深度位置交叉模块(Deep Position-wise Interaction Module)以及组合个广告和个位置的位置组合模块(Position-wise Combination Module),不同模块需预估的样本数量不一样,复杂模块预估的样本数量少,简单模块预估的样本数量多,由此来提高模型性能和保障服务性能。通过这三个模块的组合,DPIN模型有能力在服务性能的限制下预估每个广告在每个位置上的CTR,并学习位置信息和其他信息的深度非线性交叉表示。下文将会详细地介绍这三个模块。
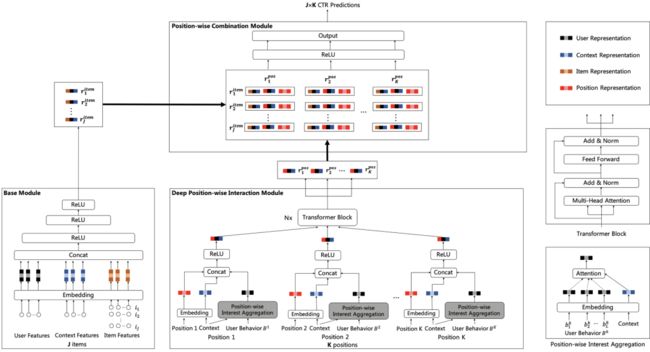
2.1 基础模块(Base Module)
与大多数深度学习CTR模型[10-16]类似,本文采用Embedding和MLP(多层感知机)的结构作为基础模块。对于一个特定请求请求,基础模块将用户、上下文和个候选广告作为输入,将每个特征通过Embedding进行表示,拼接Embedding表示输入多层MLP,采用ReLU作为激活函数,最终可以得到每个广告在该请求下的表示。第个广告的表示可以通过如下公式得到:

其中,,分别是当前用户特征集合、当前上下文特征集合以及第个广告的特征集合,是Embedding映射。
2.2 深度位置交叉模块(Deep Position-wise Interaction Module)
在大多数业务场景中,基础模块通常已经被高度优化,包含了大量特征甚至用户序列等信息,其目的是捕捉用户在该上下文中对不同广告的兴趣。因此,基础模块的推理时间复杂度通常较大,直接在基础模块中加入位置特征对所有广告在所有位置上进行CTR预估是不可接受的。因此,本文提出了一个与基础模块并行的深度位置交叉模块,不同于针对广告进行兴趣建模的基础模块,该模块针对于位置进行兴趣建模,学习每个位置与上下文及用户兴趣的深度非线性交叉表示。
在深度位置交叉模块中,我们提取用户在每个位置的行为序列,将其用于各位置上的用户兴趣聚合,这样可以消除整个用户行为序列上的位置偏差。接着,我们采用一层非线性全连接层来学习位置、上下文与用户兴趣非线性交叉表示。最后,为了聚合用户在不同位置上的序列信息来保证信息不被丢失,我们采用了Transformer[30]来使得不同位置上的行为序列表示可以进行交互。
位置兴趣聚合(Position-wise Interest Aggregation)。 我们令为用户在第个位置的历史行为序列,其中为用户在第个位置上的历史第个行为记录,为点击的item特征集合,为发生该行为时的上下文(包括搜索关键词、请求地理位置、一周中的第几天、一天中的第几个小时等),行为记录的Embedding表示可以通过下式得到:
![]()
其中,分别为和的特征集合,为该行为与当前上下文的时间差。
第个位置行为序列的聚合表示可以通过注意力机制获取,如以下公式所示:

其引入当前上下文去计算注意力权重,对于与上下文越相关的行为可以给予越多的权重。
位置非线性交叉(Position-wise Non-linear Interaction): 我们采用一层非线性全连接层来学习位置、上下文与用户兴趣非线性交叉表示,如下式所示:

其中,将拼接的向量映射到维度。
Transformer Block: 如果将直接作为第个位置的非线性交叉表示,那么会丢失用户在其他位置上的行为序列信息。因此,我们采用Transformer去学习不同位置兴趣的交互。令为Transformer的输入,Tranformer的多头自注意力结构可以由以下公式表示:

其中,是每个头的维度。因为中已经包含位置信息,故而我们不需要Transformer中的位置编码。同样的,我们也沿用Transformer中的前馈网络(Position-wise Feed-forward Network)、残差连接(Residual Connections)以及层标准化(Layer Normalization)。N个Transformer Block会被使用去加深网络。
最终,深度位置交叉模块会产出每个位置的深度非线性交叉表示,其中第个位置被表示为。
2.3 位置组合模块(Position-wise Combination Module)
位置组合模块的目的是去组合个广告和个位置来预估每个广告在每个位置上的CTR,我们采用一层非线性全连接层来学习广告、位置、上下文和用户的非线性表示,第个广告在第个位置上的CTR可以由如下公式得出:

其中包括了一层非线性连接层和一层输出层,是位置k的embedding表示,是sigmoid函数。
整个模型可以使用真实位置通过批量梯度下降法进行训练学习,我们采用交叉熵作为我们的损失函数。
3. 实验
在本节中,我们评估DPIN的模型性能和服务性能,我们将详细描述实验设置和实验结果。
3.1 实验设置
数据集: 我们使用美团搜索关键词广告数据集训练和评估我们的CTR模型。训练数据量达到数亿,测试数据量大约一千万。测试集被划分为两个部分,一部分是线上收集的常规流量日志,另一部分是线上Top-k随机的探索流量日志。Top-k随机的探索流量日志是更适合用来评估位置偏差问题,因为它大大削弱了相关性推荐对位置偏差的影响。
评估指标: 我们使用AUC(Area Under ROC)作为我们的评估指标之一。为了更好的针对位置偏差问题进行评估,我们提出PAUC (Position-wise AUC)作为我们的另一个评估指标,其由以下公式计算:

其中,是第个位置的曝光数量,是第个位置曝光数据的AUC。PAUC指标衡量每个位置上相关性排序的质量,忽略了位置偏差对排序质量的影响。
对比的方法。 为了公平且充分地对比不同模型的效果,我们所有实验中所使用的模型输入使用等量且深度结合美团业务的特征,不同模型中的相同模块都使用一致的参数,并且对比的基线DIN[14]模型经过高度优化,以下为我们具体进行对比的实验:
-
DIN: 该模型训练和预估时都没有使用位置信息。
-
DIN+PosInWide: 这个方法在网络的Wide部分建模位置特征,在评估时采用第一个位置作为位置特征的默认值去评估。
-
DIN+PAL: 这个方法采用PAL框架去建模位置信息。
-
DIN+ActualPosInWide: 这个方法在网络的Wide部分建模位置特征,在评估时采用真实位置特征去评估。
-
DIN+Combination: 这个方法在DIN的基础上添加了位置组合模块,评估时采用真实位置特征去评估。
-
DPIN-Transformer: 这个方法在我们提出的DPIN模型上去除了Transformer结构,来验证Transformer的作用。
-
DPIN: 这是我们提出的DPIN模型。
-
DPIN+ItemAction: 我们在DPIN的基础模块MLP层前添加深度位置交叉模块,并在位置兴趣聚合和位置非线性交叉中引入候选广告的信息,这个实验是我们方法模型性能的理论上界,然而服务性能是不可接受的。
3.2 离线评估

表1展示了我们所进行的对比方法在常规流量和随机流量上的离线实验评估结果,其中的数值为各个模型相对于DIN模型的效果差异,我们首先分析在常规流量上不同方法的差异。与DIN相比,DIN+PosInWide和DIN+PAL的模型在AUC指标上有所下降,但在PAUC上有所提升,这表明了这两种方法都可以有效地缓解位置偏差,但会导致离线和在线之间的不一致。
DIN+AcutalPosInWide通过在评估过程中引入实际位置来解决不一致问题,这可以通过位置组合模块来实现,但是在wide部分建模位置会导致位置特征只是一个偏差,不能提升PAUC指标,虽然能更准确地预估各位置上的CTR,但没有对数据中固有的位置偏差进行更好的学习。
DIN+Combination通过在DIN中引入位置组合模块,我们取得了1.52%的AUC增益和0.82%的PAUC增益,达到线下线上一致性的同时也进一步地缓解了位置偏差,这个结果说明了位置偏差与上下文、用户等信息不独立,在不同的用户及上下文中会有不同的位置偏差。更进一步的,DPIN建模位置、上下文、用户的深度非线性交叉关系,也消除了用户行为序列中存在的位置偏差,对比DIN+Combination取得了0.24%的AUC增益以及0.44%的PAUC增益。
DPIN-Transformer的效果说明了丢失其他位置的用户兴趣会影响模型的性能,因为这将损失大部分用户兴趣信息。对比DPIN和DPIN+ItemAction,我们发现DPIN的模型性能接近于这个暴力方法,说明DPIN模型逼近了我们方法的理论上界。最终,相较于我们的线上基线模型DIN+PosInWide,DPIN取得了2.98%的AUC增益和1.07%的PAUC增益,这在我们的业务场景中是一次极大的AUC和PAUC提升。
为了确保我们的方法能够学习位置偏差而不是单纯地过度拟合系统的选择性偏差,我们进一步在随机流量上评估我们的方法。表1的结果表明了在常规流量和随机流量上不同方法之间的差异是一致的,这说明了就算系统的推荐结果有了巨大的差异,该模型仍能有效地学习到在不同用户及上下文中的位置偏差,模型学到的位置偏差受系统推荐列表的影响很小,这也说明我们的模型可以不受系统选择性偏差的影响从而泛化到其他推荐方法的流量上。
3.3 服务性能

我们从数据集中检索出一些具有不同候选广告数量的请求,以评估不同候选广告数量下的服务性能。如图5所示,由于用户序列操作的延迟在服务延迟中占了很大比例,因此与DIN模型相比,位置组合模块服务延迟可以忽略不计。DPIN的服务延迟随着广告数量的增加而缓慢增加,这是因为相比较于DIN,DPIN将用户序列从基础模块移动到深度位置交叉模块,而深度位置交叉模块的服务性能与广告数量无关。与DIPIN+ItemAction方法相比,DPIN在服务性能方面有了很大的改进,对模型性能的损害很小,这表明我们提出的方法既高效又有效。
3.4 在线评估
我们在线上部署了A/B测试,有稳定的结果表明,与基线相比,DPIN在CTR上提高了2.25%,在RPM(每千次展示收入)上提高了2.15%。如今,DPIN已在线部署并服务于主要流量,为业务收入的显着增长做出了贡献。
4. 总结与展望
在本文中,我们提出了一种新颖的深度位置交叉网络模型(Deep Position-wise Interaction Network)以缓解位置偏差问题,该模型有效地组合了所有候选广告和位置以估算每个广告在每个位置的点击率,实现了离线和在线之间的一致性。该模型设计了位置、上下文和用户之间的深层非线性交叉,可以学习到不同用户、不同上下文中的位置偏差。为了评估位置偏向问题,我们提出了一种新的评估指标PAUC,离线实验表明,所提出的DPIN的效果和效率均优于已有方法。目前,DPIN已部署到美团搜索关键词广告系统并服务于主要流量。
值得一提的是,我们的并行组合思想不仅可以用在广告和位置的组合上,也可以用在广告和创意的组合等广告领域常见的组合排序问题。在未来,我们将在这些问题上继续实践我们的方法,并进一步地设计更完善的网络结构来解决类似的组合排序问题。我们也将在偏差领域上进行更多的探索,解决更多的问题,进一步维护广告系统的生态平衡。
5. 参考文献
[1] Chen, Jiawei, et al. "Bias and Debias in Recommender System: A Survey and Future Directions." arXiv preprint arXiv:2010.03240 (2020).
[2] Cañamares, Rocío, and Pablo Castells. "Should I follow the crowd? A probabilistic analysis of the effectiveness of popularity in recommender systems." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[3] Morik, Marco, et al. "Controlling fairness and bias in dynamic learning-to-rank." Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020.
[4] 《KDD Cup 2020 Debiasing比赛冠军技术方案及在美团的实践》。
[5] Richardson, Matthew, Ewa Dominowska, and Robert Ragno. "Predicting clicks: estimating the click-through rate for new ads." Proceedings of the 16th international conference on World Wide Web. 2007.
[6] Rendle, Steffen. "Factorization machines." 2010 IEEE International Conference on Data Mining. IEEE, 2010.
[7] Juan, Yuchin, et al. "Field-aware factorization machines for CTR prediction." Proceedings of the 10th ACM conference on recommender systems. 2016.
[8] Chen, Tianqi, and Carlos Guestrin. "Xgboost: A scalable tree boosting system." Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016.
[9] Ke, Guolin, et al. "Lightgbm: A highly efficient gradient boosting decision tree." Advances in neural information processing systems 30 (2017): 3146-3154.
[10] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
[11] Wang, Ruoxi, et al. "Deep & cross network for ad click predictions." Proceedings of the ADKDD'17. 2017. 1-7.
[12] Guo, Huifeng, et al. "DeepFM: a factorization-machine based neural network for CTR prediction." arXiv preprint arXiv:1703.04247 (2017).
[13] Lian, Jianxun, et al. "xdeepfm: Combining explicit and implicit feature interactions for recommender systems." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[14] Zhou, Guorui, et al. "Deep interest network for click-through rate prediction." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
[15] Zhou, Guorui, et al. "Deep interest evolution network for click-through rate prediction." Proceedings of the AAAI conference on artificial intelligence. Vol. 33. No. 01. 2019.
[16] Feng, Yufei, et al. "Deep session interest network for click-through rate prediction." arXiv preprint arXiv:1905.06482 (2019).
[17] Ling, Xiaoliang, et al. "Model ensemble for click prediction in bing search ads." Proceedings of the 26th International Conference on World Wide Web Companion. 2017.
[18] Zhao, Zhe, et al. "Recommending what video to watch next: a multitask ranking system." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[19] Haldar, Malay, et al. "Improving Deep Learning For Airbnb Search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[20] Guo, Huifeng, et al. "PAL: a position-bias aware learning framework for CTR prediction in live recommender systems." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
[21] Wang, Xuanhui, et al. "Learning to rank with selection bias in personal search." Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 2016.
[22] Joachims, Thorsten, Adith Swaminathan, and Tobias Schnabel. "Unbiased learning-to-rank with biased feedback." Proceedings of the Tenth ACM International Conference on Web Search and Data Mining. 2017.
[23] Ai, Qingyao, et al. "Unbiased learning to rank with unbiased propensity estimation." The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018.
[24] Wang, Xuanhui, et al. "Position bias estimation for unbiased learning to rank in personal search." Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining. 2018.
[25] Agarwal, Aman, et al. "Estimating position bias without intrusive interventions." Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 2019.
[26] Hu, Ziniu, et al. "Unbiased lambdamart: an unbiased pairwise learning-to-rank algorithm." The World Wide Web Conference. 2019.
[27] Ovaisi, Zohreh, et al. "Correcting for selection bias in learning-to-rank systems." Proceedings of The Web Conference 2020. 2020.
[28] Yuan, Bowen, et al. "Unbiased Ad click prediction for position-aware advertising systems." Fourteenth ACM Conference on Recommender Systems. 2020.
[29] Qin, Zhen, et al. "Attribute-based propensity for unbiased learning in recommender systems: Algorithm and case studies." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
[30] Vaswani, Ashish, et al. "Attention is all you need." arXiv preprint arXiv:1706.03762 (2017).
6. 作者简介
坚强、胡可、庆涛、明健、漆毅、程佳、雷军等,均来自美团广告平台技术部。
阅读更多
---
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试
---------- END ----------
招聘信息
美团广告平台广告算法团队立足广告场景,探索深度学习、强化学习、人工智能、大数据、知识图谱、NLP和计算机视觉最前沿的技术发展,探索本地生活服务电商的价值。主要工作方向包括:
触发策略:用户意图识别、广告商家数据理解,Query改写,深度匹配,相关性建模。
质量预估:广告质量度建模。点击率、转化率、客单价、交易额预估。
机制设计:广告排序机制、竞价机制、出价建议、流量预估、预算分配。
创意优化:智能创意设计。广告图片、文字、团单、优惠信息等展示创意的优化。
岗位要求:
-
有三年以上相关工作经验,对CTR/CVR预估、NLP、图像理解、机制设计至少一方面有应用经验。
-
熟悉常用的机器学习、深度学习、强化学习模型。
-
具有优秀的逻辑思维能力,对解决挑战性问题充满热情,对数据敏感,善于分析/解决问题。
-
计算机、数学相关专业硕士及以上学历。
具备以下条件优先:
-
有广告/搜索/推荐等相关业务经验。
-
有大规模机器学习相关经验。
感兴趣的同学可投递简历至:[email protected](邮件标题请注明:广平搜索团队)。
也许你还想看
| KDD Cup 2020多模态召回比赛季军方案与广告业务应用
| KDD Cup 2020 Debiasing比赛冠军技术方案及在美团广告的实践
| KDD Cup 2020 自动图学习比赛冠军技术方案及在美团广告的实践
