基于TDengine进行睿信物联网平台的迁移改造
作者:艾忠元
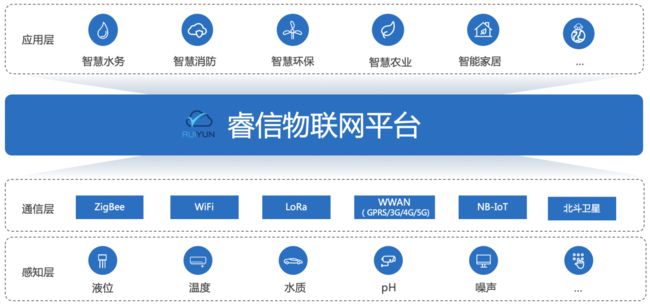
睿信物联网平台是北京睿信世达自主开发的通用物联网平台,为用户提供从传感器设备、边缘网关、云平台到APP、小程序的一整套端到端物联网SaaS云平台,可以满足用户的通用物联网功能需求;在此基础上构建了智慧水务、智慧消防、智慧环保、智慧农业、智能家居等行业应用组件,满足用户的场景化需求。
平台的整体架构如下。
现状及痛点
目前采用OpenTSDB进行时序数据的存储,功能上满足现有需求;但是由于OpenTSDB架构复杂,体量过重,给开发测试、安装部署以及运维管理等工作带来了不小的麻烦,随着业务的发展,问题逐渐凸显,开始影响工作效率,具体可以归纳为以下几方面:
-
安装难
OpenTSDB不是独立的服务组件,它还要依赖HBase、HDFS、ZooKeeper。需要把这些服务组件全部安装配置好,OpenTSDB才能正常工作,即便是一个熟练的运维工程师,把这些服务组件全部安装配置一遍,也需要很长时间。
-
调试难
在开发测试过程中,如果出现问题,需要对OpenTSDB进行日志分析,甚至可能还需要对HBase、HDFS和ZooKeeper进行全面的日志分析和问题排查,才能最终定位并解决问题。
-
运维难
在正式环境中,要求集群部署,各种服务都是双份、三份甚至n份部署,各个服务节点之间的关系错综复杂,服务节点和主机数量越多,监控管理就会越难,运维人员的工作负担也就越重。
-
成本高
成本可以分为两个方面,一个是人力成本高,由于安装、调试、运维的难度增加,造成开发运维人员工作量增加,工作效率变低,从企业经营角度看,人力成本变高;另一个是硬件资源成本高,由于服务节点众多,占用的主机、内存和磁盘空间也会很多,购买或租用这些硬件资源需要更多的费用支出。
技术选型
为了解决目前这些问题,我们决定重新进行技术选型,寻找OpenTSDB的替代方案,升级目前的时序数据库解决方案。进而,要对技术选型进行全面评估,结合实际需要,我们确定了几个选型要求:
-
开源免费:必须是开放源代码的,并且允许免费商用;
-
成熟稳定:具有较长的发展历史,经过大量项目应用实践,经历过时间的检验;
-
社区活跃:开发者社区人员多,讨论、问答、咨询、推广等线上线下活动频繁;
-
迭代更新:有开发人员一直在维护,不断在迭代更新和发布新版本;
-
性能高:单机能支持每秒10万以上的插入效率,并能够通过扩展硬件支持更高的插入效率;
-
开销低:服务节点少,占用的内存、CPU和磁盘空间少;
-
支持集群:能够集群部署,容量可水平扩展。
经过初步调查,InfluxDB、TimescaleDB和TDengine这3个时序数据库进入了我们的考察范围。
-
InfluxDB
在DB-Engines网站上,InfluxDB处于时序数据库排名的第一位,满足我们绝大部分的要求,但集群模块闭源,因此被排除在外。
-
TimescaleDB
TimescaleDB在DB-Engines中的排名也比较高,几乎满足我们的所有选型要求,但是它是PostgreSQL上的一个时序数据库插件,是基于RDBMS的时序数据库,不是一个纯粹的时序数据库;另外,对集群支持不好,不支持水平扩展。
-
TDengine
和InfluxDB一样,TDengine最初的开源版本也不支持集群,也被排除在外。去年TDengine开源了集群版本后,又进入了我们的考察范围。经过各方面的综合考察评估,TDengine满足我们所有的选型要求,成为技术选型的最终目标。
数据建模
由于是既有系统升级改造,必须符合现有系统架构,不能影响现有功能。因此,数据建模必须限定在一定的范围内,有一定的约束和限制,不能像设计一个新系统那样有那么大的自由度。总结下来,主要有两方面的约束和限制:
1. schema-free(模式自由)
不需要有create table之类的建表过程,就可以直接进行数据的写入和查询。目前已经使用了OpenTSDB这种schema-free的数据库,并按照schema-free的方式进行数据的读写,希望延续这种方式,避免功能和架构上的调整。
2. 单列模式
物联网平台的设计初衷是要能够支撑所有的应用场景,不能只考虑某一种特定的应用场景,必须设计成一种通用架构,为应用层提供足够的灵活度。因此,我们将设备和指标之间的关系设计为动态绑定关系,并且能够进行动态绑定配置。
比如,某种液位仪有液位和距离两个指标,在A场景下只需要采集液位,在B场景下只需要采集距离。
为了能够支撑设备和指标之间的这种动态绑定关系,我们采用了单列模式(也被称为纵表模式或窄表模式),每个指标单独保存一条数据,如果设备有n个指标,就保存n条数据。相反,多列模式(也被称为横表模式或宽表模式)是将设备的所有指标数据存储为一条数据,分不同的列存储不同指标值。
很显然,TDengine不是schema-free的,需要先建表,然后才能进行数据读写,这就突破了上面的约束和限制,无法满足架构上的要求,难道要放弃TDengine?还有没有变通的办法呢?经过一番调查分析,最终还是找到了解决办法。
下面从三方面进行拆解说明。
1. 通用超级表
TDengine里有超级表的概念,每种设备对应一个超级表,这个超级表只负责存储这种类型的设备数据;由于前面的约束和限制,我们肯定不能这么用。但可以变通的来用,设计一个能够兼容所有设备类型的通用超级表,把所有设备的数据往这个超级表里装;这样,只需要在系统安装部署的时候,一次性执行超级表的建表脚本,实际运行时,就不需要再动态创建超级表了
2. 单列模式
TDengine支持单列模式和多列模式,出于插入效率和存储效率的考虑,官方推荐多列模式。但是,为了符合前面的约束和限制,满足通用场景需求,我们采用了单列模式,一条数据中仅存储一个指标值。
结合上面的思路,我们的数据模型的设计如下(为了方便分析问题,省去了几个无关的标签):

数据列包含时间和指标值两列,对应上报时间和上报的具体值,标签中的指标编码用来对同一个设备下的不同指标做区分,查询的时候可以用来做条件过滤。
3. 自动建表
TDengine中还有普通表的概念(为了和超级表概念区分开,这里称为普通表),普通表也需要先创建后插入。还好TDengine支持自动建表,可以在插入的时候,顺带建表。于是,我们就可以利用自动建表语法进行自动建表,屏蔽普通表的建表过程。具体写法如下:

通用超级表,单例模式,再加上自动建表,通过这些办法,我们把表的概念变得越来越弱化,TDengine逐渐被改造成了一个schema-free的数据库,可以按照schema-free的方式来使用TDengine。
这样一来,在不改动架构,不影响功能的前提下,数据建模工作就圆满完成了。
代码改造
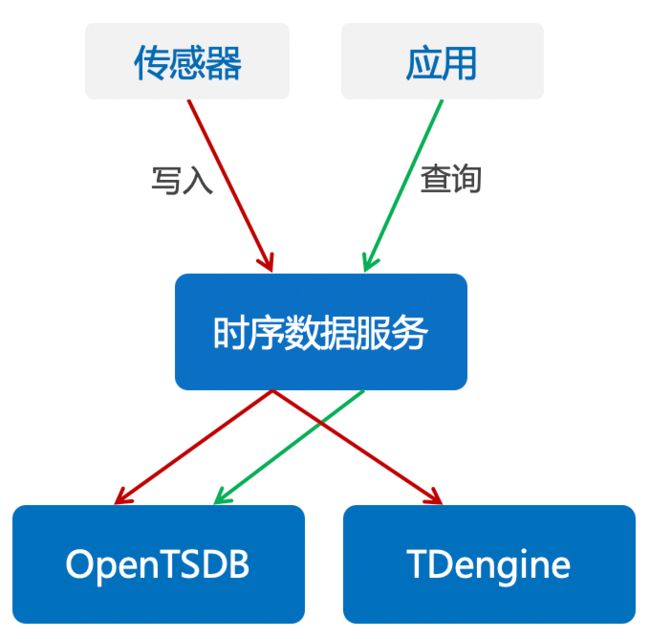
在物联网平台现有的架构中,有一个时序数据服务,专门负责对时序数据库进行封装,然后对外提供时序数据的写入和查询服务,物联网平台的其他所有模块都通过这个服务来访问时序数据库。

有了这样的架构设计,代码改造工作就变得非常简单。只需要改动这个时序数据服务,在现有基础上增加对TDengine的支持,将写入和查询两个功能按照TDengine的JDBC接口进行接口适配,将时序数据的写入和查询切换到TDengine。
通过这种方式,我们就把TDengine的改造迁移屏蔽在了时序数据服务内部,上层应用无需关心,功能上不受任何影响。
数据迁移工具
升级改造项目,需要保留历史数据,需要对历史数据进行数据迁移。为此,我们专门开发了一个数据迁移工具,将OpenTSDB中的历史数据迁移到TDengine,并且进行了详尽的功能测试
为了确保海量数据的快速迁移,我们还做了性能优化,并进行了大数据量的压力测试。数据迁移是升级上线过程中非常重要的一个环节,所以,我们在这个工具上投入了很多精力,甚至比代码改造本身还多。
升级上线
为了能够平滑顺利地完成升级上线,不影响用户正常使用,我们制定了详细的迁移方案,将升级上线分为三阶段完成。
第一阶段:数据迁移
将改造后的新版本上线,OpenTSDB和TDengine并行运行,同时向两个数据库写入数据,由于OpenTSDB有全量数据,查询请求全部交给OpenTSDB;与此同时,启动数据迁移工具,将历史数据迁移到TDengine,待数据迁移完成,进入到第二阶段。
第二阶段:试运行
OpenTSDB和TDengine依然并行运行,也同时向两个数据库写入数据;数据迁移已经完成,TDengine中已经具备全量数据,因此,查询请求全部切换到TDengine。观察两周左右的时间,没有发现任何问题,进入到第三阶段。

第三阶段:正式上线
TDengine经过试运行一切正常,功能和性能都没有问题,于是我们将OpenTSDB停止运行,数据只向TDengine写入,OpenTSDB占用的资源全部回收。
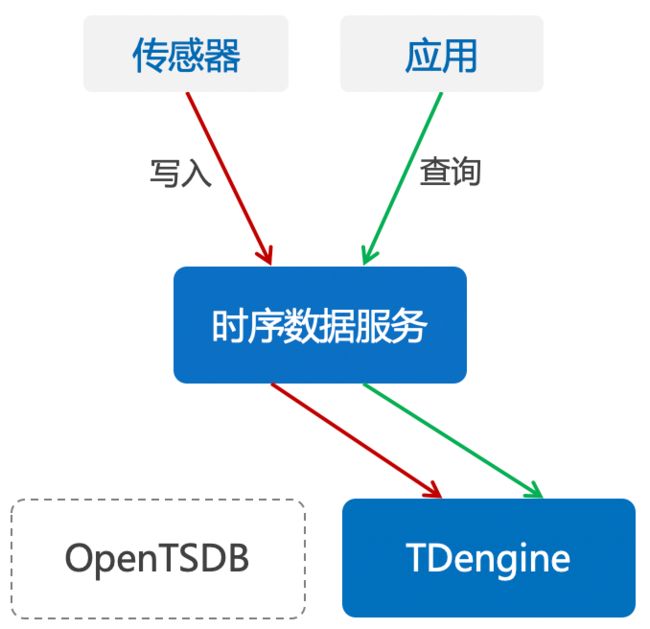
到此为止,升级上线全部完成。
改造效果
迁移到TDengine后,效果非常明显,硬件资源减少到原来的1/5,效率有了明显的提升。随着存储规模的不断变大,这种改善和提升效果会越来越明显。此外,在运维管理、费用支出、开发测试等方面也有了很大的改善。
-
开发人员现在可以自己电脑上搭建一套环境,随便折腾,不用担心跑不起来,也不用担心影响别人;
-
性能测试的时候,用配置低一些的机器也没问题,照样能做出压测效果;
-
遇到技术难题,原来通过Google、百度、StackOverflow寻找答案,现在可以直接在官方渠道https://github.com/taosdata/TDengine提issue,也可以在TDengine的技术社区提问,TDengine的技术专家亲自答复,响应非常快;
-
TDengine的体积小,只有几M,上传起来非常快,有些私有化部署项目,不允许访问外网,只能手动上传,体积小的优势就非常明显;
-
安装部署简单,配合Docker容器,可以在几分钟内完成安装部署;
-
运营监控工作变简单了,只需要对TDengine的几个进程进行监控;
-
占用的磁盘空间明显变小了,减少到原来的1/5;
-
使用的主机减少到原来的1/5,相应的费用支出也减少了。
总结
此次升级改造总体进行得比较顺利,但过程中也有一些波折,尤其是在数据建模的时候遇到了一些困难。办法总比困难多,通过一些方法和技巧,我们把TDengine改造成了schema-free的数据库,满足了物联网平台的要求,最终完成了升级改造。
目前,已经支撑起了所有物联网设备上报的数据,同时支撑起了应用层的各种应用场景。
改造后的效果明显,硬件资源减少为原来1/5,开发、测试、运维、管理、支出等方面都有明显的改善和提升。
我们使用到的功能还比较简单,主要是插入、连续查询以及降采样查询,对于物联网平台来说基本够用。UNION、GROUP BY、JOIN、聚合查询等功能暂时还未使用到,这些功能对于大数据分析的场景非常有用,将来在一些大数据项目里可以尝试使用,用来代替Hadoop全家桶。
此外,使用过程中遇到一些问题,希望改进:
-
JDBC-JNI不是纯Java的,依赖一个动态库,给安装部署带来不少麻烦;后来通过JDBC-RESTful解决了这个问题,但是中间多了一层RESTful Connector,性能会低一些;最理想的做法,还是用纯Java写一个直连后端服务的JDBC Driver;
-
客户端是命令行方式,对于开发者不是很友好,尤其是一些初级开发者,或者是用惯了图形界面的开发者;图形界面,语法高亮,语法检查,这些功能还是很香;虽然目前有两个社区开发者提供的GUI,当然官方能提供支持的话是最好不过了。