本章学习目标,编写完整的汇编语言程序,用编译器再将汇编程序编译成可执行文件(如 .exe 文件),进而在操作系统中运行。
一个源程序从编写到最终执行,要经历哪些过程?
1)程序编写:使用文本编辑器编写汇编程序代码。
2)编译连接:使用汇编语言编译程序(masm.exe)对源程序文件进行编译,生成目标文件。再使用连接程序(link.exe)对目标文件进行连接,生成可以在操作系统中直接运行的可执行文件。
3)执行程序:操作系统依照可执行文件中的描述信息,将可执行文件中的机器码和数据加载到内存中去,并进行相关的初始化(如,设置 CS:IP 指向第一条要执行的程序执行),然后由 CPU 开始执行程序。
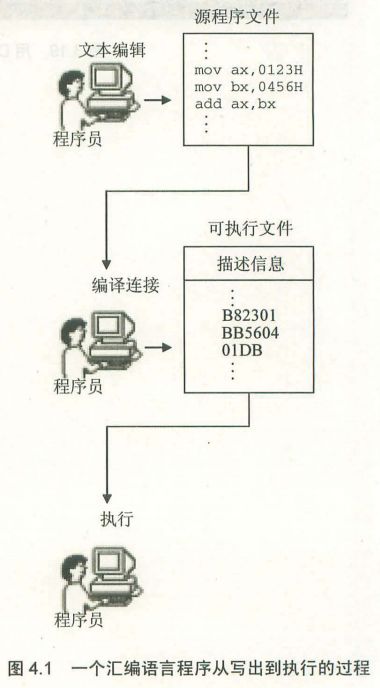
可执行文件(.exe)由哪些内容组成?
1)程序:从源程序中的汇编指令翻译而来的机器码。
2)数据:在源程序中定义的数据。
3)描述信息:比如程序有多大、要占用多少内存空间等描述信息。
源程序文件(.asm)由哪些内容组成?
1)汇编指令:汇编指令有对应的机器指令,可以被编译成机器指令,最终会被 CPU 执行。
2)伪指令:伪指令是没有对应的机器指令,它不会被 CPU 所执行。而是由编译器来执行的,编译器会根据伪指令来完成相关的编译工作。我们是通过伪指令来告诉编译器该如何工作。
segment、ends 伪指令 与 “段”
一个汇编程序是由多个段组成的,这些段被用来存放代码、数据或者当作栈空间来使用。一个有意义的汇编程序中至少要有一个段用于存放代码。
segment 和 ends 是一对成对使用的伪指令,这是在编写可以被编译器编译的汇编程序时,必须要用到的一对伪指令。这对伪指令的功能就是定义一个段,segment 指定了段的开始,ends 指定了段的结束。每一个段,都必须有一个段名,其语法格式如下:
段名称 segment
段名称 ends
end 伪指令
end 伪指令是一个汇编程源程序的结束标记,编译器在编译源程序的过程中,如果遇到了 end 伪指令,就会结束对源程序的编译。汇编源程序写完后,必须在源程序结尾加上这个 end 伪指令。否则编译器在编译源程序时,将无法知道源程序在何处结束。
这里注意 end 和 ends 的区别,前者是源程序的结束,后者是段的结束。
assume 伪指令
assume 伪指令的含义是“假设”。它假设某一个 段寄存器 和程序中的某一个以segment、ends 定义的“段”相关联。通过 assume 伪指令说明了这种关联,在需要的情况下,编译程序可以将 段寄存器 和某一个具体的段相联系起来。
assume cs: seg_name // 把程序段与代码段寄存器相关联
assume ds: seg_name // 把数据段与数据段寄存器相关联
assume ss: seg_name // 关联栈段寄存器
什么是标号?
一个标号指代着一个段地址。放在 segment 伪指令的前面,作为一个段的名称。这个段的名称最终会被编译连接程序处理,生成一个段的段地址。所谓标号,即上述代码中的 seg_name,也就是 segment 伪指令前面的段名称。
深入理解“程序”的含义
我们把源程序文件中的所有内容称为“源程序”,把源程序中最终由CPU执行和处理的指令或数据,称之为“程序”。程序,最先以汇编指令的形式存在于源程序中,经编译连接后转变为机器码,又存在于可执行文件中。程序,就是最终由计算机CPU来执行、处理的指令和数据。
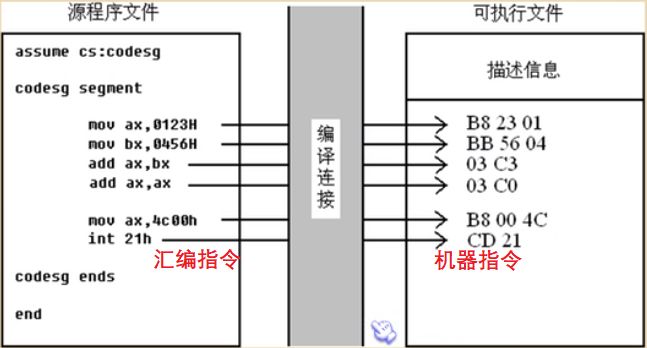
什么是程序返回?
源程序最先以汇编指令的形式存在于源程序中,经过编译连接处理后,转变成机器码存储在可执行文件中。那么可执行文件中的程序是怎样得到CPU运行的呢?
我们知道,DOS是一个单任务的操作系统,即同一时刻只能运行一个程序。举个例子:一个 P2程序存在于可执行文件中,则必须有一个正在运行的程序P1把 P2程序从可执行文件中加载到内存中去,同时把 CPU的控制权交给 P2,此时 P2开始运行,P1处于暂停状态。当 P2 程序运行完毕后,又将 CPU控制权交还给使它得以运行的 P1 程序,此时 P1 程序继续运行,P2 处理停止状态。从这个例子中,我们就可以得到“程序返回”的基本定义。
所谓程序返回,就是一个程序执行结束后,将CPU控制权交还给使它得以运行的程序,这个过程就叫做“程序返回”。我们应该在程序的末尾添加上“程序返回”的代码段,下面两行代码即起着程序返回的作用。
mov ax, 4c00H
int 21H
下图是几个与程序结束有关的概念,如下图示:

编程中常见的两类错误
1)语法错误:这类错误一般在程序编译时就会被编译器发现。容易发现。
2)逻辑错误:这类错误在程序编译时不能被表现出来,只有在程序运行时才会发生的错误。不容易发现。
第一个汇编程序
1)准备工作,把 debug.exe、masm.exe、link.exe 拷贝到 e:\asm 目录下。(汇编编程我们需要以下基础工具程序:文本编辑器、编译器masm.exe、连接器link.exe、调试工具debug.exe等,这些工具程序都是运行在操作系统之上的,操作系统本身也是一个程序,各种工具程序运行结束后都会遵从“程序返回”的约定以返回并执行操作系统这个大程序。)

2)使用 mount 命令把本地电脑的 e:\asm 目录挂载到 DOSBox 的 c 盘下,进入 DOSBox 的 c 盘。
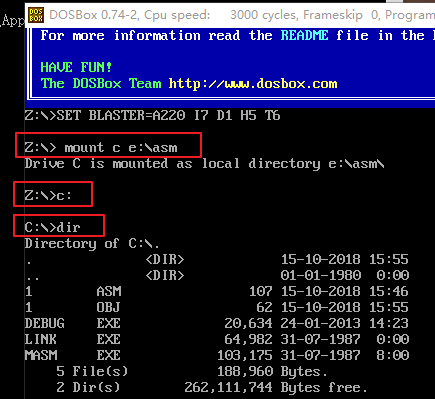
3)编写汇编程序并命名为 1.asm 文件,存放在 e:\asm 目录下。源码如下:
assume cs:hello
hello segment
main: mov ax, 0123H
mov bx, 0456H
add ax, bx
add ax, ax
mov ax,4c00H
int 21H
hello ends
end main
4)使用 “masm 1.asm”命令编译 1.asm 源程序文件,生成 1.obj 目标文件。
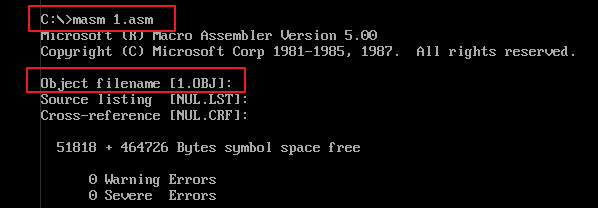
在源程序文件编译过程中,DOSBox 控制台如果输出 “errors” 字样,则说明源程序文件中有语法错误。请修正语法错误后重新编译,直到编译通过为止。
5)使用“link 1.obj”命令连接 1.obj 目标文件,生成 1.exe 可执行文件。
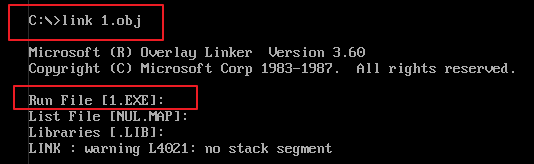
6)直接输入可执行文件的名称,即可执行经过编译、连接而生成的可执行文件。
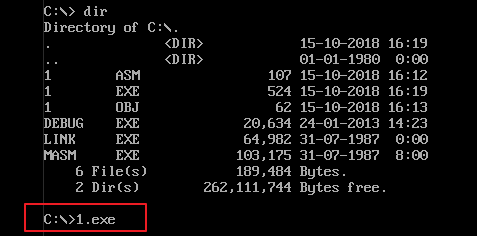
执行 1.exe 可执行文件后,控制台上并没有输出任何信息。这是因为我们只做了一些将数据送入寄存器和加法的操作,这些操作不会有任何信息输出到控制台。1.exe执行完成后,程序返回,控制台中会再次出现操作系统的提示符。
深入理解“连接”过程的作用和意义
1)“连接”过程的第一个作用:当源程序很大时,可能把它拆分成多个源程序文件来分别编译,每个源程序编译成目标文件后,再执行“连接”过程再把它们连接到一起,进而生成最终的可执行文件。
2)“连接”过程的第二个作用:如果源程序中调用了某个库文件,则需要把这个库文件的目标文件和源程序所生成的目标文件连接到一起,进而生成最终的可执行文件。
3)“连接”过程的第三个作用:一个源程序编译后,得到了存有机器码的目标文件。目标文件中的有些内容还不能直接用来生成可执行文件,“连接”过程可以把这些内容加工成最终的可执行文件。
“连接”过程的最终目标是把一个或多个目标文件加工合成我们需要的最终可执行文件。
温馨强调:我们学习汇编的主要目的,就是通过用汇编语言进行编程,进而深入地理解计算机底层的基本工作机理,从而达到可以随心所欲地控制计算机的目的。
可执行文件中的程序,是如何被加载到内存中去的?
我们已经知道,在 DOS 中,可执行文件中的程序(P1)要想运行,必须有一个正在运行的程序(P2)把 P1 从可执行文件中加载入内存,并将 CPU 控制权交给 P1,进而运行 P1 程序,此时 P2程序处于挂起状态。当 P1 运行完毕后,又将 CPU 控制权交还给使它得以运行的程序 P2,即“程序返回”。(这种机制可类比成皇帝指派将军去打仗,当有将军需要出去打仗时,皇帝就把“令牌”分派给这个将军,当将军打仗归来后,再把“令牌”返还给皇帝。)
操作系统是由多个功能模块组成的庞大的复杂的软件系统。任何通用的操作系统,都要提供一个被称为 Shell(外壳)的程序,用户使用这个外壳程序可以操作计算机系统。举例说明,在DOS 中有一个 command.exe 的程序,这个程序在 DOS 中被称为命令解释器,也就是 DOS 系统中的外壳 Shell。
在 DOS 命令行输入“1.exe”执行可执行文件时,到底是哪个程序把 1.exe 中的程序加载到内存的?这个正在运行的程序是什么?它把 1.exe 中的程序加载入内存后,是如何使程序得以运行的呢?1.exe 中的程序执行结束后,“程序返回”又返回到了哪里?
1)在 DOS 中直接执行“1.exe”时,是正在运行的 command.exe 程序把 1.exe 中的程序加载入内存的。
2)command.exe 通过设置 CPU 的 CS:IP 指向 1.exe 程序中的第一条指令(即程序的入口),从而使得 1.exe 中的程序得以运行。
3)1.exe 中的程序运行结束后,将返回到 command.exe 中,CPU 继续运行 command.exe 这一程序。
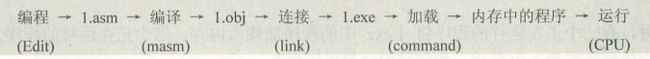
使用 debug.exe 来追踪可执行文件的执行过程
为了观察可执行文件的执行过程,我们可以使用 debug.exe 来调试。debug 可以把可执行文件中的程序加载入内存,并设置 CS:IP 指向该程序的入口。但 debug 并不会放弃对 CPU 的控制,如此我们就可以使用 debug 的系列命令来单步执行该程序,进一步查看每条程序指令执行后的结果。
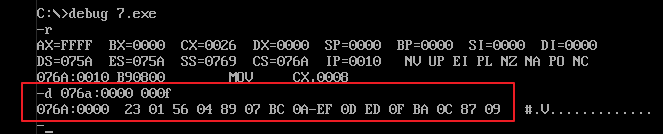
1)使用 debug.exe 运行 1.exe 可执行文件,并使用 r 命令查看 CPU 的寄存器状态,如下图示:
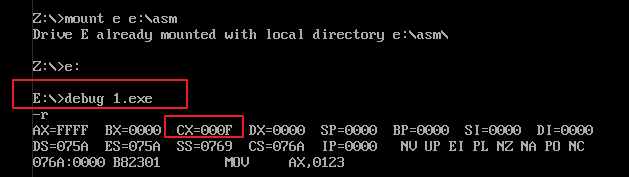
使用“debug.exe”把 1.exe 加载到内存中后,cx 通用寄存器中的值就等于 1.exe 可执行文件中程序的长度,即 1.exe 中程序的机器码的总长度(单位是“字节”)。
现在程序已经从 1.exe 中装入了内存。那问题来了,程序到底被装入到内存中的哪个地方去了?我们在内存的哪个地方可以查看到程序中代码呢?在 DOS 系统中,1.exe 文件中的程序的加载过程是怎样的?
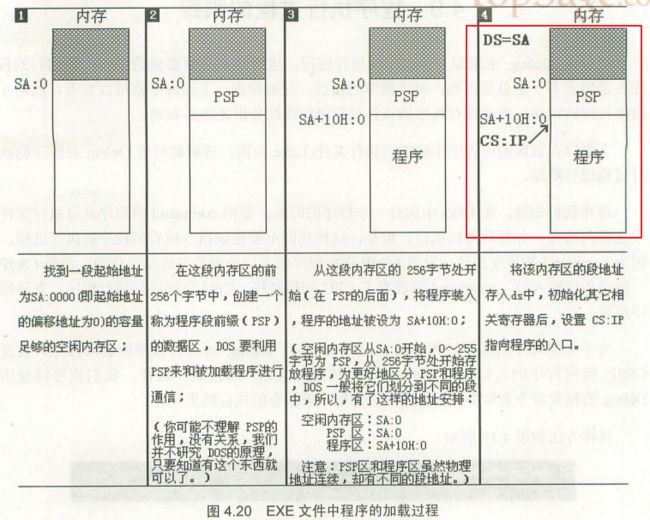
程序被加载入内存后,ds 段寄存器中存放着程序所在内存区的段地址,这个内存区的偏移地址为 0,则程序所在的内存区段的物理地址的起点为 ds[0]。这个内存区的前 256 个字节中存放的是 PSP,DOS 程序使用 PSP 来和程序进行通信。这 256 字节处往后的内存空间存放着程序指令。
所以,我们从 ds 寄存器中可以得到 PSP 的段地址 SA,PSP 的偏移地址为 0,则PSP物理地址为 SA * 16 + 0(因为 PSP 所占空间是 256字节,即 100H);则程序段的物理地址是 SA * 16 + 0 + 256 = ( SA + 16 ) * 16 + 0,用段地址和偏移地址表示为 SA+10 : 0。
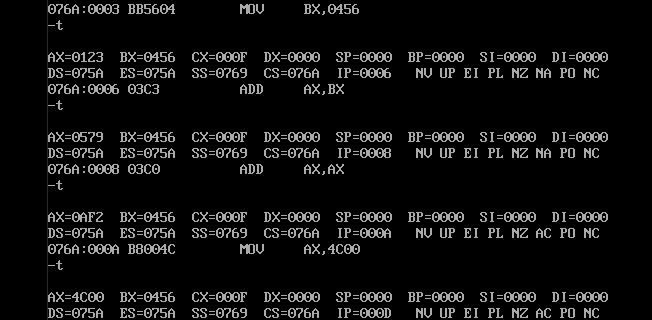
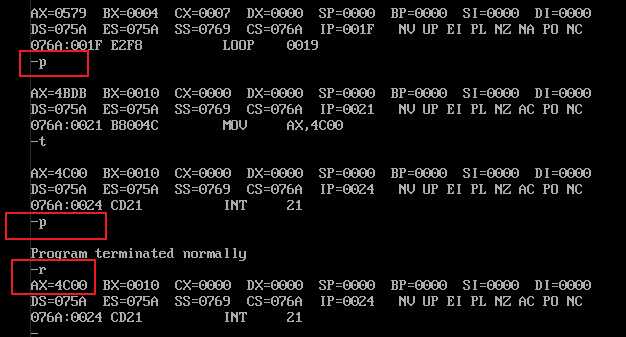
2)用 t 命令进行单步执行,同步查看寄存器的状态变化结果。
3)当程序执行到“int 21”时,用 p 命令执行“程序返回”,当控制台打印出“program terminated normally”时则表示这个程序正常结束,否则程序将非正常结束。使用 p 命令执行“程序返回”,即返回到 debug.exe 程序中。再使用 q 命令退出 debug.exe 程序,debug.exe 程序执行“程序返回”,即返回到 command.exe 程序中。
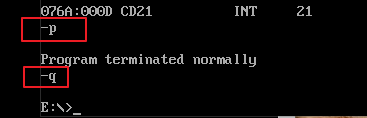

关于“程序返回”,当前程序是由哪个程序加载入内存并执行的,则当前程序执行结束后的“程序返回”,就返回至哪个程序中。在上述实验过程中,command.exe 把 debug.exe 加载入内存并执行,debug.exe 把 1.exe 加载入内存并执行;所以 1.exe 执行结束后“程序返回”至 debug.exe 中,debug.exe 被结束后“程序返回”至 command.exe 中。
约定一个描述性符号: ( )
为了描述上的简洁,在以后的课程中,我们将使用一个描述性符号“( )”来表示一个寄存器或一个内存单元中的内容。注意,这个描述性符号不能用到编程中去,这只是一个方便我们描述存储单元或寄存器中的内容的符号而已。示例如下:
1)ax 中的内容为 0010H,我们可以这样来描述:(ax) = 0010H。
2)2000:1000H 处的存储单元中的内容为 0010H,我们可以这样来描述:(21000H) = 0010H。
3)对于“mov ax, [2]”的功能,我们可以这样来描述:(ax) = ((ds) 16 + 2)。
4)对于“mov [2], ax”的功能,我们可以这样来描述:((ds)16 + 2) = (ax)。
5)对于“add ax, 2”的功能,我们可以这样来描述:(ax) = (ax) + 2。
6)对于“add ax, bx”的功能,我们可以这样来描述:(ax) = (ax) + (bx)。
7)对于“push ax”的功能,我们可以这样来描述:(sp) = (sp) - 2;((ss) 16 + (sp)) = (ax)。
8)对于“pop ax”的功能,我们可以这样来描述:(ax) = ((ss)16 + (sp));(sp) = (sp) + 2。
约定一个常量符号:idata
使用 idata 来表示一个常量。示例如下:
1)“mov ax, [idata]”就代表着“mov ax, [2]”、“mov ax, [2]”等。
2)“mov bx, idata”就代表着“mov bx, 1”、“mov bx, 2”等。
注意:段寄存器不接收直接赋值(必须使用通用寄存器来过渡),所以“mov ds, idata”这是非法的指令,切忌!
[bx] 是什么含义?
我们已经知道描述一个内存单元的物理地址,由段地址和偏移地址共同决定。当数据在寄存器和内存之间传递时,段地址默认存放在 ds 寄存器中,偏移地址由 [address] 来指定;具体到每次所传递的数据量则是由指令所操作的寄存器来决定的,比如指令操作的是通用寄存器 AX 则每次传输的数据量是一个“字”,指令操作的 AL 或者 AH 则每次传输的数据量是一个“字节”。
[bx] 和 ds[address] 中的 [address] 有些类似,[address] 所指向的内存单元的偏移地址是 address。 [bx] 也指向一个内存单元,[bx] 的意思说“ bx 通用寄存器中的值即是当前数据单元的偏移地址”。比如,ds[bx],其含义是“当前数据单元的段地址存放在 ds 寄存器中,偏移地址存放在 bx 寄存器中”。如下示例:
mov ax, [0] // 这在masm编译器中,会被错误地理解成“把数字 0 送往 ax寄存器”
// 应该使用 [bx] 进行过渡
mov bx, 0000H
mov ax, [bx]
mov al, [3] // 这在masm编译器中,会被错误地理解成“把数字 0 送往 al低位寄存器”
// 应该使用 [bx] 进行过渡
mov bx, 0003H
mov al, [bx]
到底为什么会有 [bx] 存在呢?是因为 masm.exe 编译器无法正确地理解 " [address] " 这样的语法,masm编译器会错误地理解 "[address] = address"。因此,我们引入了 [bx] 来对偏移地址进行过渡,当我们需要指向某个数据单元时,则需要预先把偏移地址的值存放到 bx 通用寄存器中,如此 masm 编译器会默认从 ds 中取出段地址,从 bx 中取出偏移地址,进而决定一个数据单元的物理地址。
mov ax, [bx]
即 (ax) = ((ds)*16 + (bx)),意思是把段地址为 ds、偏移地址为 bx 的物理地址处内存单元中的数据送入到 ax 寄存器中去。
mov [bx], ax
即 ((ds)*16 + (bx)) = (ax),意思是把 ax 寄存器中的数据送往段地址为 ds、偏移地址为 bx 的物理地址处的内存单元中去。
loop 指令 与 cx 寄存器
语法格式:"loop 标号"。CPU 在执行 loop 指令时,要进行以下两步操作:
1)(cx) = (cx) - 1
2)判断 (cx) 是否等于零。如果不等于零,则跳转至标号处执行程序;如果等于零,则向下执行程序。所谓“标号”,就代表着一个存储单元的地址。
cx 中存放着 loop 循环的次数,cx 寄存器中的值影响着 loop 指令的执行结果。loop循环的程序模板格式如下:
mov cx, 循环次数
s: 要循环的程序段代码
loop s
【例1】计算 2 的 12次方,并将结果保存到 ax 寄存中。汇编代码实现如下:
assume cs:hello
hello segment
main: mov ax, 2
mov cx, 11
s: add ax, ax
loop s
mov ax, 4c00H
int 21H
hello ends
end main
例1题解:1)标号 s 指向“add ax, ax”所在存储单元的物理地址。2)loop 指令运行并,先执行 (cx) = (cx) - 1,再判断 (cx) 是否为零,如果不为零则继续循环 s ,如果为零则停止循环,类似高级编程语言中的 do...while 循环。
【例2】计算 物理地址为 2000:0006H 处内存单元中的数乘以 123,并将结果存储到 dx 中。汇编代码实现如下:
assume cs:geek
geek segment
main: mov ax, 02000H // ax 通用寄存器是 16位的
mov ds, ax
mov bx, 0006H // 设置 ds:[bx] 指向数据单元
mov dh, 00H
mov dl, [bx] // 初始化 dx 通用寄存器
mov cx, 123 // 设置 loop 循环次数
s: add dx, dx // 标号,要循环的代码
loop s
mov ax, 4c00H // 程序返回
int 21H
geek ends
end main
在 debug.exe 中,可以使用“ g [代码段的偏移地址] ”实现多步执行,即一次执行多行程序代码。在 debug.exe 中,可以使用 “ p ” 命令,直接跳转到 “mov ax, 4c00H”指令处,再输入“ p ”命令,即可执行“程序返回”。
温故而知新,阶段小结:
1)[bx] 作为偏移地址与 DS 数据段寄存器配合使用。
2)loop 循环指令 与 cx 寄存器合作。
3)debug.exe 中使用 “g 偏移地址”执行多行程序,使用“p”命令一次性把循环语句执行完毕或者跳转至程序结尾处。
4)注意对比“在debug.exe中编程”和“在文本编辑器中编程在masm.exe中编译”的异同。
5)区分下面四条语句在 debug.exe 和 masm.exe 中的异同:
mov al, [5]
mov al, ds:[5]
mov al, [bx]
mov al, ds:[bx]
第1条语句在dubug中意思是“把偏移地址为5的数据单元中的值送入al寄存器中”;在masm中它等价于“mov al, 5”。后3条语句在debug和masm中的意思相同,且都是合法的汇编程序语句。
【例3】累加 2000:0H 到 2000:bH 数据段中的数值,并把结果存储到 dx 寄存器中去。汇编代码实现如下:
assume cs:geek
geek segment
main: mov cx, 12
mov bx, 0
mov ax, 2000H
mov ds, ax
mov ah, 0
mov dx, 0
s: mov al, [bx]
inc bx
add dx, ax
loop s
mov ax, 4c00H
int 21H
geek ends
end main
例解:1)初始化工作:从 2000:0H 到 2000:bH 共有12个数字,且都是 8位的单字节数据,对它们进行累加,可使用 loop 循环来实现,cx 中存储着 loop 循环的次数,ds 中存储着数据段的段地址,并把 dx 归零。2)因为数据源是 8位单字节的,而 dx 是16位双字节的,所以不能对它们进行直接相加,这就需要使用 ax 寄存器来过渡,所以 ah 初始化为 0,并用 al 来接收8位单字节的源数据,然后再把 16位 ax 累加到 dx上。如此循环 12 次,每循环一次都将 bx 自加一,即可实现需求。3)经过编译、连接后,生成 .exe 可执行文件,在 debug.exe 中调试,先使用 e 命令向内存中写入数据源,再使用 t、p 命令执行单步或多步跟踪调试,图示如下:
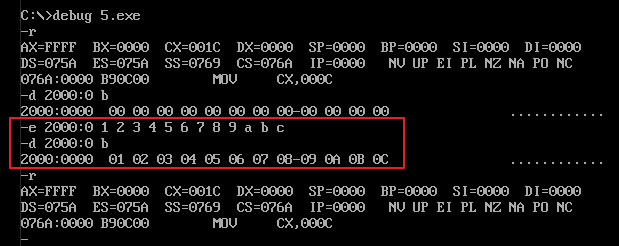
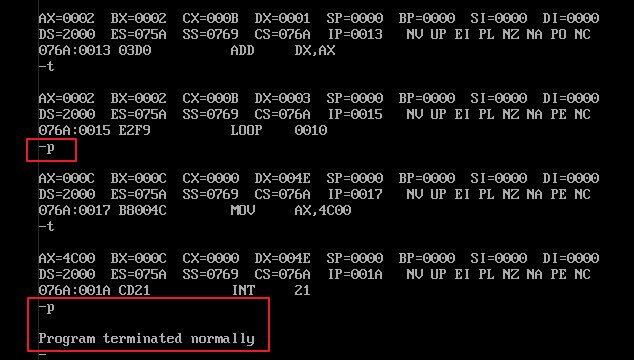
在这个例子中,我们强调了 [bx] 这个变量的重要意义:[bx] 可以看作是一个指向数据单元的变量,在循环中有规律地改变 bx 中的值即可实现有规律地内存访问。变量,在实际编程实践中非常有用。
什么是“段前缀”?
指令“mov ax, [bx]”中默认以 ds 段寄存器中的值作为数据单元的段地址。事实上,我们在访问内存单元时,也可以显示地给出内存单元的段地址,比如“mov ax, cs:[bx]”。像这样,在访问内存单元的指令中,用于显示地指明内存单元的段地址的“ds:”、"cs:"、“ss:”、“es:”,在汇编语言中即被称为“段前缀”。“段前缀”示例如下:
mov ax, ds:[bx]
mov ax, ds:[2]
mov ax, ss:[bx]
mov ax es:[bx]
mov ax ss:[0]
mov ax, cs:[8]
使用汇编语言编程时,我们应该在操作系统中安全、规矩地编程呢?还是应该自由、直接地面向硬件进行编程呢?
在操作系统的环境下工作,操作系统管理着所有的资源,包括内存。我们学习汇编语言,目的是通过它来获得底层的编程体验,进一步理解计算机底层的基本工作机理。因此,我们尽量直接对硬件进行编程,而不用去理会操作系统。
在纯DOS方式(实模式)下,可以不用理会DOS,直接用汇编语言去操作真实的硬件,因为运行在CPU实模式下的DOS,没有能力对硬件系统进行全面、严格地管理。
在Windows、UNIX这些运行在CPU保护模式下的操作系统中,不理会操作系统、用汇编语言去操作真实的硬件,是根本不可能的。因为硬件已经被这些操作系统利用CPU保护模式所提供的功能全面而严格地管理起来了。
使用一段安全的内存空间
在8086模式下,随意地向一段内存空间中写入内容是非常危险的,因为这段内存空间中可能存放着其它重要的系统数据或代码。可见,当我们不能确定一段内存空间中是否存放着重要的数据或代码时,就不能随意地向其中写入内容。所以,我们要找到一段安全的内存空间以供我们使用。
在一般的PC机中,DOS方式下,DOS和其它合法程序一般都不会使用或占用 0:200H ~ 0:2FFH 的 256 个字节空间,所以,我们使用这段空间是最安全的。往后我们在实验时,使用这段内存空间即可。
在 debug.exe 中,输入“d 0:200 2ff”查看这段内存空间是否都为0,如果都为0,则说明这段空间确实是安全的。如下图示:

那么,为什么 0:200H ~ 0:2ffH 这段空间在各个CPU模式下都是安全的呢?为什么DOS和其它合法程序都不会占用这段内存空间呢?这些问题将在以后的课程中继续讨论。

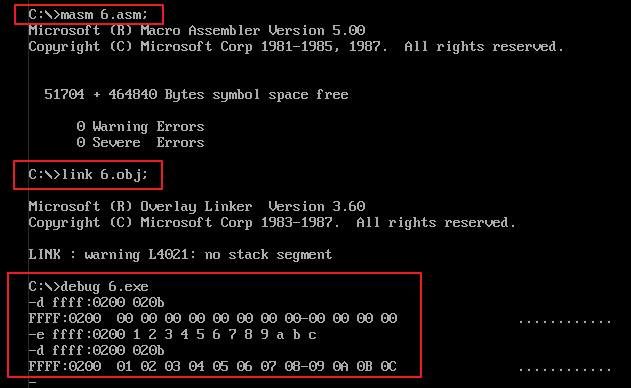
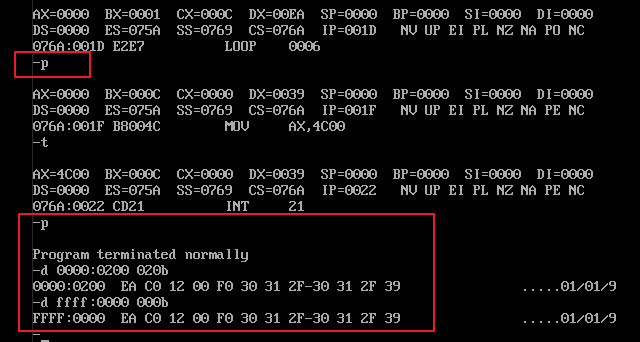
【例4】把内存 ffff:0000H ~ ffff:000bH 这段存储单元中的数据拷贝到 0:200H ~ 0:20bH 这段安全的内存空间中去。汇编代码实现如下:
assume cs:code
code segment
main: mov bx, 0 ; (bx) = 0,偏移地址从 0 开始
mov cx, 12 ; (cx) = 12,设定循环的次数
s: mov ax, 0ffffH
mov ds, ax ; 设置数据源的段地址
mov dl, [bx] ; (dl) = ((ds)*16 + (bx)) 把源数据放到 dl 中进行过渡
mov ax, 00000H
mov ds, ax ; 设置目标内存地址的段地址
add bx, 200H ; 偏移地址
mov [bx], dl ; 把过渡区中的数据写入到目标内存单元中去,实现拷贝
sub bx, 200H ; 偏移地址
inc bx ; 偏移地址自增 1
loop s ; 执行循环
mov ax, 4c00H ; 执行“程序返回”
int 21H
code ends
end main
例解:1)通过题目分析,使用 loop 循环来实现需求是必须的,用 cx 寄存器存放 loop 循环的次数。2)需求是跨内存单元拷贝数值,通常需要使用一个寄存器来进行过渡,在本例中我们使用了 dl 低位寄存器来过渡。3)由于是跨内存单元的读、写数据,并且跨越的是两个数据段,因此需要在循环中不断地切换 ds 段地址。4)使用 bx 存放数据单元的偏移地址,通过观察发现两个数据段的偏移地址之间相差 200H,因此在每次循环时都需要对偏移地址先加 200H 再减 200H。5)对源程序进行编译、连接,在debug.exe 中使用 e 命令向内存中添加数据源,再使用 t、p等命令进行跟踪高度,图示如下:
ES 段寄存器(附加段寄存器)
当段寄存器(ds、ss、cs)不够用时,可以使用 es 段寄存器来补充使用,因此 es 也被称为是“附加段寄存器”。
仔细分析上述【例4】的源码,我们发现在 loop 循环中,每循环一次都要两次修改 ds 段寄存器,这显然是比较浪费 CPU 资源的,而这种资源浪费的根本原因是因为程序中使用到了两个数据段、但只有 ds 一个数据段寄存器用来提供段地址。在这个时候,我们可以使用 es 附加段寄存器来弥补数据段寄存器不足的问题,即把 es 当作数据段寄存器来使用,通过“段前缀”的方式显示地指向数据单元的段地址。综合分析后,【例4】源码优化如下:
assume cs:code
code segment
main: mov cx, 12 ; (cx) = 12,设定循环的次数
mov bx, 0 ; (bx) = 0,偏移地址从 0 开始
mov ax, 0ffffH
mov ds, ax ; 设置数据源的段地址
mov ax, 00000H
mov es, ax ; 设置目标内存段的段地址
s: mov dl, [bx] ; (dl) = ((ds)*16 + (bx)) 把源数据放到 dl 中进行过渡
add bx, 200H ; 偏移地址
mov es:[bx], dl ; 把过渡区中的数据写入到目标内存单元中去,实现拷贝
sub bx, 200H ; 偏移地址
inc bx ; 偏移地址自增 1
loop s ; 执行循环
mov ax, 4c00H ; 执行“程序返回”
int 21H
code ends
end main
在上述所有例子中,我们的程序都只有一个代码段。本章我们将学习在程序中如何使用数据段、栈段来存放程序所需要用到的数据。
在接下来的系列例子中,我们将实验“在一个内存段中同时存放数据、代码和栈” 和 “把数据、代码和栈放入到不同的内存段” 这两种编程思想,以比较这两种做法的优劣。事实上,后者的思想是把数据、代码和栈分隔并存储在多个内存段中,即用多个内存段来编程,即高级编程语言中所倡导的“封装”思想。
在一个内存段中同时存放数据、代码和栈
【例5】题目要求如下图示,要求只使用一个内存段来实现。

assume cs:geek
geek segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
main: mov cx, 8 ; 指定程序的入口
mov ax, 0
mov bx, 0
s: add ax, cs:[bx] ; (ds) = (cs)
add bx, 2
loop s
mov ax, 4c00H
int 21H
geek ends
end main
源码实现如上所示,代码解读与分析如下:
1)dw 指令,即 define word,其作用是用来定义“字”型数据。同时定义多个字型数据时用英式逗号进行分隔,每个字型数据占据16位内存空间。
2)db 指令,即 define byte,其作用是用来定义“字节”型数据。
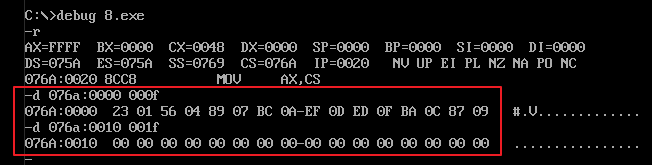
3)由于本例仅使用了一个内存段实现,所以 dw 所定义的字型数据的段地址与代码段的段地址相等,即 (ds) = (cs)。另外,dw 定义字型数据的代码位于程序的顶部,所以这 8 个字型数据的偏移地址依次为 0、2、4、6、8、a、c、e。这么分析后,我们就得出了这 8 个数据源的物理地址。
4)上述源码中的“main”标号,它指定了程序的入口,这个自定义的标号是供给 end 伪指令使用的。
5)end 伪指令的作用:它除了通知编译器让程序结束外,还可以告诉编译器程序的入口在什么地方。CPU寻找程序入口的唯一依据就是 end 伪指令所指向的标号。
在 debub.exe 中跟踪调试,如下图示:
在代码段中使用栈段
【例6】题目如下图,要求在代码段中使用“栈空间”来管理数据,从而实现源数据的倒序排列。

解题思路,使用 dw 指令定义8个“字”型数据源,使用“栈”空间来管理数据,读取源数据并入栈,出栈时覆写源数据即可实现倒序排列。汇编代码实现如下:
assume cs:geek
geek segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H ; 定义源数据
dw 0,0,0,0,0,0,0,0 ; 初始化8个“字”空间,稍后将其当作“栈”来使用
start: mov ax, cs
mov ss, ax ; 设定“栈”空间的段地址
mov sp, 001fH ; 初始化栈顶的偏移地址
mov bx, 0 ; 读数据时的偏移地址
mov cx, 8 ; 设置入栈循环次数 8 次
s1: push cs:[bx] ; 入栈
add bx, 2
loop s1
mov bx, 0 ; 写数据时的偏移地址
mov cx, 8 ; 设置出栈循环次数 8 次
s2: pop cs:[bx] ; 出栈
add bx, 2
loop s2
mov ax, 4c00H
int 21H
geek ends
end start ; 指明程序的入口在 start 标号处
代码解读:
1)使用 dw 定义数据源,cs:[bx] 即指向数据源。
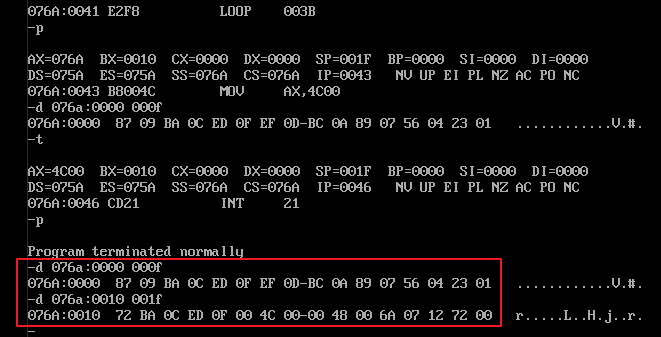
2)再使用 dw 初始化一个数据段,让 ss:sp 指向这个数据段的最底部(初始化“栈顶”位置),(ss) = (cs),(sp) = 82 + 82 = 1fH。
3)使用 push cs:[bx] 把数据源依次入栈,再使用 pop cs:[bx] 把出栈数据覆写到源数据段中去。
4)cx 寄存器保存着 loop 循环的次数。
5)对源码进行编译、连接后,在 debug.exe 中跟踪调试结果如下图所示:
把数据、代码、栈放至不同的内存段中(“封装”的编程思想)
在上述两个例子中,我们在程序中用到了数据和栈,并且把数据、栈 和代码放在了同一个段中。于是我们在编程时,总要时刻注意何处是数据,何处是栈,何处是代码。这种把代码、数据和栈混在一起的做法,会带来如下两个问题:
1)这使得程序显得混乱。
2)当数据量较大、代码量也较大时,很有可能超出 64KB,但是一个段的最大容量不能大于 64KB,在8086模式下是有这样的限制。
基于上述两个潜在的问题,我们应该考虑使用多个内存段来存放数据、代码和栈。那该怎样做呢?
我们可以用和定义代码段一样的方式来定义多个段,然后在这些段里面定义我们所需要的数据,或者通过定义数据来取得栈空间。接下来,我们以上例【例6】进行优化,优化后源码如下:
assume cs:code, ds:data, ss:stack
data segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax, stack
mov ss, ax ; 指定栈段
mov sp, 0020H ; 设置栈顶 ss:sp 指向 stack:0020
mov ax, data
mov ds, ax ; ds 指向 data标号的段地址
mov bx, 0 ; 读数据
mov cx, 8 ; 设置循环次数
s1: push [bx]
add bx, 2
loop s1 ; 循环入栈
mov bx, 0 ; 写数据
mov cx, 8 ; 设置循环次数
s2: pop [bx]
add bx, 2
loop s2 ; 循环出栈
mov ax, 4c00H
int 21H
code ends
end start ; 指定程序的入口
源码分析:1)在源码中,使用 segment / ends 伪指令定义了三个代码段。2)在 assume 伪指令中,用 cs: 指向 code标号处的代码段,用 ds: 指向 data标号处的数据段,用 ss: 指向 stack标号处的栈段。3)end 伪指令指定了程序的入口,如果 end 未指明程序入口,编译程序时可能会报错。4)在程序代码中,使用 mov 指令显示地设置 ss:sp 栈顶位置,设置 ds:[bx] 数据段。5)使用 loop 指令实现循环入栈和出栈,更改数据源的排序。
本章完!!!