data_camp
数据的来源
-
一般有五种

使用readr包读取数据
数据读取一般两种情况:1)在R默认环境下。2)在其他目录下。
在默认工作目录下,直接在语句中输入文件名即可。
在其他目录下,则输入其所在位置的绝对路径。和终端指令不同的是,file.path() 通过, 分隔每个目录。

# Path to the hotdogs.txt file: path
path <- file.path("data", "hotdogs.txt")
读取csv文件(flat data)
使用read.csv() 读取csv数据。
ps:可以通过dir() 查看工作目录下的数据

# Import swimming_pools.csv: pools
pools <- read.csv("swimming_pools.csv")
- 默认下,read.csv() 会将数据转化为factor 格式。
通过设定stringsAsFactors(默认TRUE)调整。
# Import swimming_pools.csv correctly: pools
pools <- read.csv("swimming_pools.csv", stringsAsFactors = FALSE)
读取tab-delimited file(分隔数据)
数据被逗号或tab隔开

使用read.delim()
默认下,read.delim() 的两个参数sep = "\t",header = TRUE,分别表示数据被制表符分隔,文件第一行包含字段名。
# Import hotdogs.txt: hotdogs
hotdogs <- read.delim("hotdogs.txt", header = FALSE)
被任意方式分隔开的文件
一般适用于:1)任意分隔形式(tabular file)的data frame 文件;2)参数量很大。
使用read.table()
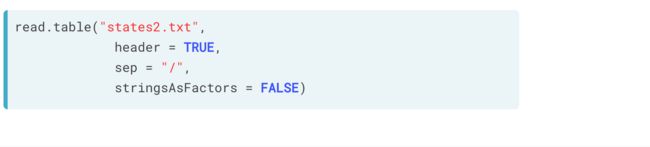
默认下,read.table() 的两个参数
sep = "",
header = FALSE,分别表示数据无分隔符,文件第一行不包含字段名。
读取文件过程中筛选内容
col.names
- col.names = 可以用于筛选特定的列
ps: 使用which.min()与which.max() 找出数据中最小或最大的数据.
# Finish the read.delim() call
hotdogs <- read.delim("hotdogs.txt", header = FALSE, col.names = c("type", "calories", "sodium"))
# Select the hot dog with the least calories: lily
lily <- hotdogs[which.min(hotdogs$calories), ]
# Select the observation with the most sodium: tom
tom <- hotdogs[which.max(hotdogs$sodium), ]
colClasses
可用于筛选特定类型的数据
如
read.delim("my_file.txt",
colClasses = c("character",
"numeric",
"logical"))
colClasses 可将对应一系列的数据类型和读取数据中不符合的筛除。
# Previous call to import hotdogs.txt
hotdogs <- read.delim("hotdogs.txt", header = FALSE, col.names = c("type", "calories", "sodium"))
# Display structure of hotdogs
# Edit the colClasses argument to import the data correctly: hotdogs2
hotdogs2 <- read.delim("hotdogs.txt", header = FALSE,
col.names = c("type", "calories", "sodium"),
colClasses = c("factor", "NULL", "numeric")
)
# Display structure of hotdogs2
str(hotdogs2)
col_types
- col_types 和colClasses 相似,用于筛选特定类型的列。
参数为一个字符串如"clid",c 代表字符串,l代表布尔值,i代表整数,d代表浮点型。
hotdogs_factor <- read_tsv("hotdogs.txt",
col_names = c("type", "calories", "sodium"),
col_types = ("fii")
)
skip, n_max
skip 可用于跳过指定的行,n_max 可用于选择
# Import 5 observations from potatoes.txt: potatoes_fragment
potatoes_fragment <- read_tsv("potatoes.txt", skip = 6, n_max = 5, col_names = properties)
collector functon
用于转化数据信息
如col_integer() 转化为整数
col_factor(levels=*) 转化为factor
ps:col_types 还可以被list 赋值,list 中的每个元素为对应的col 类型。
# readr is already loaded
# Import without col_types
hotdogs <- read_tsv("hotdogs.txt", col_names = c("type", "calories", "sodium"))
# Display the summary of hotdogs
summary(hotdogs)
# The collectors you will need to import the data
fac <- col_factor(levels = c("Beef", "Meat", "Poultry"))
int <- col_integer()
# Edit the col_types argument to import the data correctly: hotdogs_factor
hotdogs_factor <- read_tsv("hotdogs.txt",
col_names = c("type", "calories", "sodium"),
col_types = list(fac,int,int)
)
# Display the summary of hotdogs_factor
summary(hotdogs_factor)
read.table() 小结
一般功能最强的是,read.table(),read.csv()与read.delim() 作为补充与简单的调用方式。
不同类型的文件
read.csv() 读取csv文件,comma-separated value
read.tsv() 读取tsv文件。tab-separated value
使用data.table 包
data.table 使得导入table 类型文件更加方便。
fread函数
fread 是非常强大的读取table函数。
可以识别出如csv 文件是否文件第一行有列名称。

# load the data.table package using library()
library(data.table)
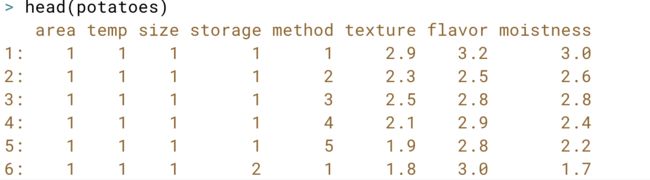
# Import potatoes.csv with fread(): potatoes
potatoes <- fread("potatoes.csv")
# Print out potatoes
potatoes
两个参数:drop&select
fread 函数中有drop 与select 两个参数。可以对数据内容进行筛选。

# fread is already loaded
# Import columns 6 and 8 of potatoes.csv: potatoes
potatoes <- fread("potatoes.csv", select = c(6,8))
# Plot texture (x) and moistness (y) of potatoes
plot(potatoes$texture, potatoes$moistness)
ps:plot 可以进行简单作图。

fread() 与 read.csv() 区别
主要区别在于,fread 的输出结果包括 data.table 与data.frame,而read.csv() 包括tbl_tf, tbl, 和data.frame。
使用readxl包导入excel文件
- 主要包含两个函数
excel_sheets(),read_excel()

excel_sheet()
用于提取excel 中的表单
# Load the readxl package
library(readxl)
# Print the names of all worksheets
excel_sheets("urbanpop.xlsx")
用于读取excel 表单中的信息到R
read_excel()
# The readxl package is already loaded
# Read the sheets, one by one
pop_1 <- read_excel("urbanpop.xlsx", sheet = 1)
pop_2 <- read_excel("urbanpop.xlsx", sheet = 2)
pop_3 <- read_excel("urbanpop.xlsx", sheet = 3)
# Put pop_1, pop_2 and pop_3 in a list: pop_list
pop_list <- list(pop_1, pop_2, pop_3)
# Display the structure of pop_list
str(pop_list)
- 通过lapply 函数可以直接将提取的表单传递给read_excel() 函数。
# The readxl package is already loaded
# Read all Excel sheets with lapply(): pop_list
pop_list <- lapply(excel_sheets('urbanpop.xlsx'), read_excel, path = "urbanpop.xlsx")
# Display the structure of pop_list
str(pop_list)
几个参数
默认参数设置为

col_types
可以通过向量进行赋值,如text, blank, numeric, date 等。
sheet
选择Excel表格中选定的表单。
skip
类似之前readr包提及的skip。用于跳过某些行内容。
col_names
默认下col_names 值为TRUE,即函数不会自动命名。可以通过赋值或改为FALSE的方式,自定义命名或依靠函数自动命名。
这里可以使用一个小技巧,通过paste() 批量连接信息。
paste("a", 0:10),即代表生成 "a0", "a1"..."a10"
# The readxl package is already loaded
# Import the first Excel sheet of urbanpop_nonames.xlsx (R gives names): pop_a
pop_a <- read_excel("urbanpop_nonames.xlsx", col_names = FALSE)
# Import the first Excel sheet of urbanpop_nonames.xlsx (specify col_names): pop_b
cols <- c("country", paste0("year_", 1960:1966))
pop_b <- read_excel("urbanpop_nonames.xlsx", col_names = cols)
# Print the summary of pop_a
summary(pop_a)
# Print the summary of pop_b
summary(pop_b)
另外一种导入Excel 方式:gdata包
gdata 原理:

gdata 和readxl 包对比

主要因为readxl 包还在发展,很多功能不完善,而且可能语法会变换。
因此选择gdata 这个成熟的包学习,会更加保险一些。
read.xls() 导入文件
# Import the second sheet of urbanpop.xls: urban_pop
urban_pop <- read.xls("urbanpop.xls", sheet = "1967-1974")
- 通过cbind() 可以添加data.frame或matrix 等信息
- data_frame[-1],可以去除第一列的信息。
-
na.omit可以用来除去data.frame 中的NA 信息。
例子
# Add code to import data from all three sheets in urbanpop.xls
path <- "urbanpop.xls"
urban_sheet1 <- read.xls(path, sheet = 1, stringsAsFactors = FALSE)
urban_sheet2 <- read.xls(path, sheet = 2, stringsAsFactors = FALSE)
urban_sheet3 <- read.xls(path, sheet = 3, stringsAsFactors = FALSE)
# Extend the cbind() call to include urban_sheet3: urban
urban <- cbind(urban_sheet1, urban_sheet2[-1], urban_sheet3[-1])
# Remove all rows with NAs from urban: urban_clean
urban_clean <- na.omit(urban)
# Print out a summary of urban_clean
summary(urban_clean)
打通excel和R的包:XLConnect
一个应用了Java的包(安装可能需要java 环境)。
几乎可以实现使用R代码进行所有excel 可以进行的操作。
loadWorkbook()
加载excel 的表格。功能是创建在R中创建一个workbook,用于连接excel文件和R工作区。可以将其赋值给一个变量。
# Load the XLConnect package
library(XLConnect)
# Build connection to urbanpop.xlsx: my_book
my_book <- loadWorkbook("urbanpop.xlsx")
getsheet()
用于列出excel 文件中的所有列表
getSheets(my_book)
readWorksheet()
读取表格信息。
readWorksheet 一般有四个参数。object 为表格对象,一般为需先经过loadWorkbook() 处理;sheet 表示表格信息,startCol 表示开始的行数,endCol 表示结束的行数。
# XLConnect is already available
# Build connection to urbanpop.xlsx
my_book <- loadWorkbook("urbanpop.xlsx")
# Import columns 3, 4, and 5 from second sheet in my_book: urbanpop_sel
urbanpop_sel <- readWorksheet(my_book, sheet = 2, startCol = 3, endCol = 5)
# Import first column from second sheet in my_book: countries
countries <- readWorksheet(my_book, sheet = 2, startCol = 1, endCol = 1)
# cbind() urbanpop_sel and countries together: selectioncbind(urbanpop_sel, countries)
selection <- cbind(countries, urbanpop_sel)
使用XLConnect 修改数据
createSheet()
createSheet(object, name = )
创建一个空的表格
# Add a worksheet to my_book, named "data_summary"
createSheet(my_book, name = "data_summary")
writeWorksheet()
将新的表格信息写入到某个表格中。
writeWorksheet(object, new_object, sheet = )
# Add data in summ to "data_summary" sheet
writeWorksheet(my_book, summ, sheet = "data_summary")
saveWorkbook()
所有的编辑结束之后需要使用该函数进行文件的保存。(类似于进行excel操作后得保存文件,否则所有内容都付之东流了。)
saveWorkbook(object, flie = )
# Save workbook as summary.xlsx
saveWorkbook(my_book, file = "summary.xlsx")
renameSheet()
对表格进行重命名
renameSheet(object, 'old_name', 'new_name' )
# Rename "data_summary" sheet to "summary"
renameSheet(my_book,sheet = 4, "summary")
removeSheet()
移除整个表格
`removeSheet(object, sheet = )
# Remove the fourth sheet
removeSheet(my_book, sheet = 4)