概览
- 如今,推荐引擎无处不在,人们希望数据科学家知道如何构建一个推荐引擎
- Word2vec是一个非常流行的词嵌入,用于执行各种NLP任务
- 我们将使用word2vec来构建我们自己的推荐系统。就让我们来看看NLP和推荐引擎是如何结合的吧!
完整的代码可以从这里下载。
介绍
老实说,你在亚马逊上有注意到网站为你推荐的内容吗(Recommended for you部分)? 自从几年前我发现机器学习可以增强这部分内容以来,我就迷上了它。每次登录Amazon时,我都会密切关注该部分。
Netflix、谷歌、亚马逊、Flipkart等公司花费数百万美元完善他们的推荐引擎是有原因的,因为这是一个强大的信息获取渠道并且提高了消费者的体验。
让我用一个最近的例子来说明这种作用。我去了一个很受欢迎的网上市场购买一把躺椅,那里有各种各样的躺椅,我喜欢其中的大多数并点击了查看了一把人造革手动躺椅。

请注意页面上显示的不同类型的信息,图片的左半部分包含了不同角度的商品图片。右半部分包含有关商品的一些详细信息和部分类似的商品。
而这是我最喜欢的部分,该网站正在向我推荐类似的商品,这为我节省了手动浏览类似躺椅的时间。
在本文中,我们将构建自己的推荐系统。但是我们将从一个独特的视角来处理这个问题。我们将使用一个NLP概念--Word2vec,向用户推荐商品。如果你觉得这个教程让你有点小期待,那就让我们开始吧!
在文中,我会提及一些概念。我建议可以看一下以下这两篇文章来快速复习一下
- 理解神经网络
- 构建推荐引擎的综合指南
word2vec - 词的向量表示
我们知道机器很难处理原始文本数据。事实上,除了数值型数据,机器几乎不可能处理其他类型的数据。因此,以向量的形式表示文本几乎一直是所有NLP任务中最重要的步骤。
在这个方向上,最重要的步骤之一就是使用 word2vec embeddings,它是在2013年引入NLP社区的并彻底改变了NLP的整个发展。
事实证明,这些 embeddings在单词类比和单词相似性等任务中是最先进的。word2vec embeddings还能够实现像 King - man +woman ~= Queen之类的任务,这是一个非常神奇的结果。
有两种word2vec模型——Continuous Bag of Words模型和Skip-Gram模型。在本文中,我们将使用Skip-Gram模型。
首先让我们了解word2vec向量或者说embeddings是怎么计算的。
如何获得word2vec embeddings?
word2vec模型是一个简单的神经网络模型,其只有一个隐含层,该模型的任务是预测句子中每个词的近义词。然而,我们的目标与这项任务无关。我们想要的是一旦模型被训练好,通过模型的隐含层学习到的权重。然后可以将这些权重用作单词的embeddings。
让我举个例子来说明word2vec模型是如何工作的。请看下面这句话:

假设单词“teleport”(用黄色高亮显示)是我们的输入单词。它有一个大小为2的上下文窗口。这意味着我们只考虑输入单词两边相邻的两个单词作为邻近的单词。
注意:上下文窗口的大小不是固定的,可以根据我们的需要进行更改。
现在,任务是逐个选择邻近的单词(上下文窗口中的单词),并给出词汇表中每个单词成为选中的邻近单词的概率。这听起来应该挺直观的吧?
让我们再举一个例子来详细了解整个过程。
准备训练数据
我们需要一个标记数据集来训练神经网络模型。这意味着数据集应该有一组输入和对应输入的输出。在这一点上,你可能有一些问题,像:
- 在哪里可以找到这样的数据集?
- 这个数据集包含什么?
- 这个数据有多大?
等等。
然而我要告诉你的是:我们可以轻松地创建自己的标记数据来训练word2vec模型。下面我将演示如何从任何文本生成此数据集。让我们使用一个句子并从中创建训练数据。
第一步: 黄色高亮显示的单词将作为输入,绿色高亮显示的单词将作为输出单词。我们将使用2个单词的窗口大小。让我们从第一个单词作为输入单词开始。
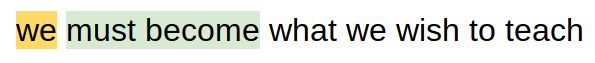
所以,关于这个输入词的训练样本如下:
| Input | Output |
|---|---|
| we | must |
| we | become |
第二步: 接下来,我们将第二个单词作为输入单词。上下文窗口也会随之移动。现在,邻近的单词是“we”、“become”和“what”。

新的训练样本将会被添加到之前的训练样本中,如下所示:
| Input | Output |
|---|---|
| we | must |
| we | become |
| must | we |
| must | become |
| must | what |
我们将重复这些步骤,直到最后一个单词。最后,这句话的完整训练数据如下:
Input Output
| Input | Output |
|---|---|
| we | must |
| we | become |
| must | we |
| must | become |
| must | what |
| become | we |
| become | must |
| become | what |
| become | we |
| what | must |
| what | become |
| what | we |
| what | wish |
| we | become |
| we | what |
| we | wish |
| we | to |
| wish | what |
| wish | we |
| wish | to |
| wish | teach |
| to | we |
| to | wish |
| to | teach |
| teach | wish |
| teach | to |
我们从一个句子中抽取了27个训练样本,这是我喜欢处理非结构化数据的许多方面之一——凭空创建了一个标记数据集。
获得 word2vec Embeddings
现在,假设我们有一堆句子,我们用同样的方法从这些句子中提取训练样本。我们最终将获得相当大的训练数据。
假设这个数据集中有5000个惟一的单词,我们希望为每个单词创建大小为100维的向量。然后,对于下面给出的word2vec架构:
- V = 5000(词汇量)
- N = 100(隐藏单元数量或单词embeddings长度)
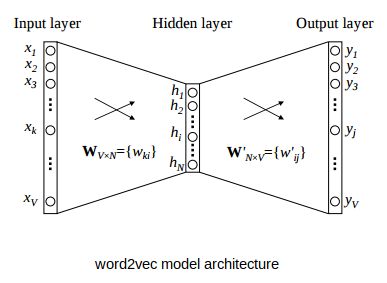
输入将是一个热编码向量,而输出层将给出词汇表中每个单词都在其附近的概率。
一旦对该模型进行训练,我们就可以很容易地提取学习到的权值矩阵 x N,并用它来提取单词向量:

正如你在上面看到的,权重矩阵的形状为5000 x 100。这个矩阵的第一行对应于词汇表中的第一个单词,第二个对应于第二个单词,以此类推。

这就是我们如何通过word2vec得到固定大小的词向量或embeddings。这个数据集中相似的单词会有相似的向量,即指向相同方向的向量。例如,单词“car”和“jeep”有类似的向量:

这是对word2vec如何在NLP中使用的高级概述。
在我们开始构建推荐系统之前,让我问你一个问题。如何将word2vec用于非nlp任务,如商品推荐?我相信自从你读了这篇文章的标题后,你就一直在想这个问题。让我们一起解出这个谜题。
在非文本数据上应用word2vec模型
你能猜到word2vec用来创建文本向量表示的自然语言的基本特性吗?
是文本的顺序性。每个句子或短语都有一个单词序列。如果没有这个顺序,我们将很难理解文本。试着解释下面这句话:
“these most been languages deciphered written of have already”
这个句子没有顺序,我们很难理解它,这就是为什么在任何自然语言中,单词的顺序是如此重要。正是这个特性让我想到了其他不像文本具有顺序性质的数据。
其中一类数据是消费者在电子商务网站的购买行为。大多数时候,消费者的购买行为都有一个模式,例如,一个从事体育相关活动的人可能有一个类似的在线购买模式:
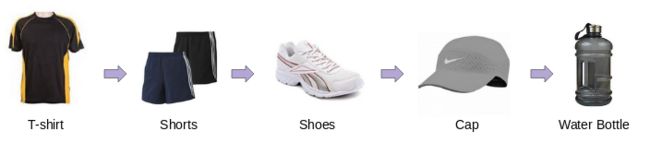
如果我们可以用向量表示每一个商品,那么我们可以很容易地找到相似的商品。因此,如果用户在网上查看一个商品,那么我们可以通过使用商品之间的向量相似性评分轻松地推荐类似商品。
但是我们如何得到这些商品的向量表示呢?我们可以用word2vec模型来得到这些向量吗?
答案当然是可以的! 把消费者的购买历史想象成一句话,而把商品想象成这句话的单词:

更进一步,让我们研究在线零售数据,并使用word2vec构建一个推荐系统。
案例研究:使用Python中的word2vec进行在线商品推荐
现在让我们再一次确定我们的问题和需求:
我们被要求创建一个系统,根据消费者过去的购买行为,自动向电子商务网站的消费者推荐一定数量的商品。
我们将使用一个在线零售数据集,你可以从这个链接下载:
让我们启动Jupyter Notebook,快速导入所需的库并加载数据集。
import pandas as pd
import numpy as np
import random
from tqdm import tqdm
from gensim.models import Word2Vec
import matplotlib.pyplot as plt
%matplotlib inline
import warnings;
warnings.filterwarnings('ignore')
df = pd.read_excel('Online Retail.xlsx')
df.head()
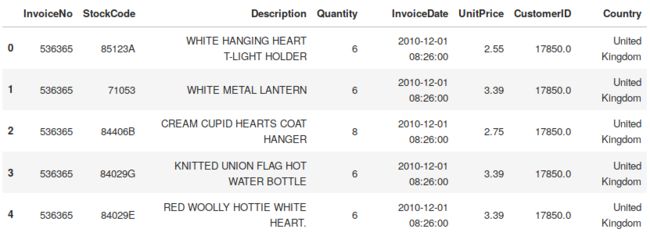
以下是该数据集中字段的描述:
- InvoiceNo: 账单号,分配给每笔交易的唯一编号
- StockCode: 商品的代码。分配给每个不同商品的唯一编号
- Description: 商品描述
- Quantity: 每笔交易每种商品的数量
- InvoiceDate: 每笔交易日期和时间
- CustomerID: 消费者编号,分配给每个消费者的唯一编号
df.shape
Output: (541909, 8)
数据集包含541,909个记录,这对于我们建立模型来说相当不错。
处理缺失数据
# 检查缺失值数据
df.isnull().sum()

由于我们有足够的数据,我们将删除所有缺少值的行。
# 删除缺失值所在行
df.dropna(inplace=True)
准备数据
让我们将StockCode转换为string数据类型:
df['StockCode']= df['StockCode'].astype(str)
让我们来看看我们的数据集中消费者的数量:
customers = df["CustomerID"].unique().tolist()
len(customers)
Output: 4372
在我们的数据集中有4,372个消费者,对于这些消费者,我们将提取他们的购买历史。换句话说,我们可以有4372个购买序列。
留出数据集的一小部分用于验证是一个很好的方法。因此,我将使用90%消费者的数据来创建word2vec embeddings。让我们开始分割数据。
# 打乱消费者id
random.shuffle(customers)
# 提取90%的消费者
customers_train = [customers[i] for i in range(round(0.9*len(customers)))]
# 分为训练集和验证集
train_df = df[df['CustomerID'].isin(customers_train)]
validation_df = df[~df['CustomerID'].isin(customers_train)]
我们将在数据集中为训练集和验证集创建消费者购买的序列。
# 存储消费者的购买历史
purchases_train = []
# 用商品代码填充列表
for i in tqdm(customers_train):
temp = train_df[train_df["CustomerID"] == i]["StockCode"].tolist()
purchases_train.append(temp)
# 存储消费者的购买历史
purchases_val = []
# 用商品代码填充列表
for i in tqdm(validation_df['CustomerID'].unique()):
temp = validation_df[validation_df["CustomerID"] == i]["StockCode"].tolist()
purchases_val.append(temp)
为商品构建word2vec Embeddings
# 训练word2vec模型
model = Word2Vec(window = 10, sg = 1, hs = 0,
negative = 10, # for negative sampling
alpha=0.03, min_alpha=0.0007,
seed = 14)
model.build_vocab(purchases_train, progress_per=200)
model.train(purchases_train, total_examples = model.corpus_count,
epochs=10, report_delay=1)
因为我们不打算进一步训练模型,所以我们在这里调用init_sims()。这将使模型的内存效率更高:
model.init_sims(replace=True)
让我们来看看“model”的相关参数:
print(model)
Output: Word2Vec(vocab=3151, size=100, alpha=0.03)
我们的模型有3151个唯一的单词,每个单词的向量大小为100维。接下来,我们将提取词汇表中所有单词的向量,并将其存储在一个地方,以便于访问。
# 提取向量
X = model[model.wv.vocab]
X.shape
Output: (3151, 100)
可视化word2vec Embeddings
可视化你所创建的embeddings是很有帮助的。在这里,我们有100维的Embeddings。我们甚至无法可视化4维空间,更不用说100维了,那么我们怎么做呢?
我们将使用UMAP算法将商品Embeddings的维数从100降到2,UMAP算法通常用于降维。
import umap
cluster_embedding = umap.UMAP(n_neighbors=30, min_dist=0.0,
n_components=2, random_state=42).fit_transform(X)
plt.figure(figsize=(10,9))
plt.scatter(cluster_embedding[:, 0], cluster_embedding[:, 1], s=3, cmap='Spectral')

这个图中的每个点都是一个商品。如你所见,这些数据点有几个很小的集群。这些是相似商品的组。
开始推荐商品
恭喜你!我们终于准备好我们的在线零售数据集中每个商品的word2vec embeddings 。现在,我们的下一步是为某个商品或某个商品的向量推荐类似的商品。
让我们首先创建一个商品id和商品描述的字典,以便轻松地将商品的描述映射到其id,反之亦然。
products = train_df[["StockCode", "Description"]]
# 去重
products.drop_duplicates(inplace=True, subset='StockCode', keep="last")
# 创建一个商品id和商品描述的字典
products_dict = products.groupby('StockCode')['Description'].apply(list).to_dict()
# 字典测试
products_dict['84029E']
Output: [‘RED WOOLLY HOTTIE WHITE HEART.’]
我定义了下面的函数。将一个商品的向量(n)作为输入,返回前6个相似的商品:
def similar_products(v, n = 6):
# 为输入向量提取最相似的商品
ms = model.similar_by_vector(v, topn= n+1)[1:]
# 提取相似产品的名称和相似度评分
new_ms = []
for j in ms:
pair = (products_dict[j[0]][0], j[1])
new_ms.append(pair)
return new_ms
让我们通过传递商品编号为'90019A' (‘SILVER M.O.P ORBIT BRACELET’)的商品:
similar_products(model['90019A'])
Output:
[(‘SILVER M.O.P ORBIT DROP EARRINGS’, 0.766798734664917),
(‘PINK HEART OF GLASS BRACELET’, 0.7607438564300537),
(‘AMBER DROP EARRINGS W LONG BEADS’, 0.7573930025100708),
(‘GOLD/M.O.P PENDANT ORBIT NECKLACE’, 0.7413625121116638),
(‘ANT COPPER RED BOUDICCA BRACELET’, 0.7289256453514099),
(‘WHITE VINT ART DECO CRYSTAL NECKLAC’, 0.7265784740447998)]
太酷了!结果还是非常相关,并且与输入商品匹配得很好。然而,这个输出仅基于单个商品的向量。如果我们想根据他或她过去的多次购买来推荐商品呢?
一个简单的解决方案是取用户迄今为止购买的所有商品的向量的平均值,并使用这个结果向量找到类似的商品。我们将使用下面的函数,它接收一个商品id列表,并返回一个100维的向量,它是输入列表中商品的向量的平均值:
def aggregate_vectors(products):
product_vec = []
for i in products:
try:
product_vec.append(model[i])
except KeyError:
continue
return np.mean(product_vec, axis=0)
回想一下,为了验证目的,我们已经创建了一个单独的购买序列列表。现在刚好可以利用它。
len(purchases_val[0])
Output: 314
用户购买的第一个商品列表的长度为314。我们将把这个验证集的商品序列传递给aggregate_vectors函数。
aggregate_vectors(purchases_val[0]).shape
Output: (100, )
函数返回了一个100维的数组。这意味着函数运行正常。现在我们可以用这个结果得到最相似的商品:
similar_products(aggregate_vectors(purchases_val[0]))
Output:
[(‘PARTY BUNTING’, 0.661663293838501),
(‘ALARM CLOCK BAKELIKE RED ‘, 0.640213131904602),
(‘ALARM CLOCK BAKELIKE IVORY’, 0.6287959814071655),
(‘ROSES REGENCY TEACUP AND SAUCER ‘, 0.6286610960960388),
(‘SPOTTY BUNTING’, 0.6270893216133118),
(‘GREEN REGENCY TEACUP AND SAUCER’, 0.6261675357818604)]
结果,我们的系统根据用户的整个购买历史推荐了6款商品。此外,你也可以根据最近几次购买情况来进行商品推荐。
下面我只提供了最近购买的10种商品作为输入:
similar_products(aggregate_vectors(purchases_val[0][-10:]))
Output:
[(‘PARISIENNE KEY CABINET ‘, 0.6296610832214355),
(‘FRENCH ENAMEL CANDLEHOLDER’, 0.6204789876937866),
(‘VINTAGE ZINC WATERING CAN’, 0.5855435729026794),
(‘CREAM HANGING HEART T-LIGHT HOLDER’, 0.5839680433273315),
(‘ENAMEL FLOWER JUG CREAM’, 0.5806118845939636)]
你可以随意修改这段代码,并尝试从验证集中的更多商品序列进行商品推荐。也可以进一步优化这段代码或使其更好。
结语
最后,你可以尝试在类似的非文本序列数据上实现此代码。例如,音乐推荐就是一个很好的用例。