前段时间有小伙伴问了我好几次中文切词是怎么切的,我想着应该是我没表达清楚所以小伙伴才会重复问多次,是我表达能力不够,临时说也说不上来。所以就写一篇了简单的中文切词方法的短文,一方面是锻炼下自己的表达能力,另一方面下次小伙伴再问就直接扔给他Y(^o^)Y
原出处doudou0o博客
中文分词介绍
在文本处理中,如果需要理解分析句子背后的含义(语义),或者需要加入人的一些词语的先验知识,又或者数据量不够大细粒度的单元(字)容易导致过拟合(字的字典表一般都比较小),或者有些特殊的只适合词的模型的一些场景下都需要 切词 来将句子切分成词的有序串。特别的,“词”是表达/承载语义的最小单位,在需要表达句子乃至文章意义的时候切词是必要的。
但并不是所有文本处理都需要/适合切词,在数据集比较足够大的情况,或者一些深度网络模型,或者机器翻译的场景中,都是字粒度表现的更好。
所以是否真的需要切词,是在不同的场景下不同的数据下需要分别对待的。在不是必须要分词的情况下,优先尝试使用字粒度的模型能够更快更便捷的不错的结果再考虑是否引入词/语音的概念。
在英文中每个词本身就有分割的标记,但是在中文当中词与词之间没有明显的区分标记,而且经常会有字的前后语境不一样切分方式就差别很大的情况。因此如何切词(切词算法)就显得额外重要。下面以我自己的理解和简单的语言浅显地分享下我个人理解的各种分词策略。
中文切词分类
在中文切词中大多数文章都会分为三类:
1. 基于词典的分词方法(也有文章称"基于字符串匹配方法")
2. 基于统计的分词方法
3. 基于序列标注的分词方法
第一类基于词典的分词方法
扫描方向不同:正向/逆向最大匹配法、双向匹配分词法。
长度倾向不同:最少切分算法。
它们最重要的思想就是按照一定策略将待分析的字串与一个大词典中的词条进行匹配,若字串在词典中存在则匹配成功,然后进行下一个字串的猜想。
第二类基于统计的分词方法
N元模型(N-gram)、Aprior算法(频繁项集算法)
他们最重要的思想就是在大量文本中,某些相邻(有顺序)的字(/词)同时出现的次数越多,就越可能构成一个词(/词串)。因此这些算法是统计或者分析字与字顺序相邻出现的概率来得到最大概率的切词结果。
第三类基于序列标注的分词方法
条件随机场(CRF)、隐马尔科夫模型(HMM)、最大熵算法等
当然也包括神经网络分词模型。
他们都属于一种字构词方法,最重要的思想是把分词过程视为字在字串中的标注问题(例如将字标注为“首字中间字尾字”或者其他标注方式)。当这些标注完成的时候切词也就自然完成了。这种策略能够平衡地看待词表词和未登录词(未收录到词典的词)的识别问题,大大简化了使用门槛,并得到一个相当不错的切词结果。
强行插入一波广告隐马尔科夫模型的浅显介绍链接
第四类其他分词方法
分词方法不限于上述几种方式和算法。还有很多有效可靠的算法,我没有很好地将他们分类。包括N-最短路径算法,自动感知机算法,基于字的生成式模型,等等。另外还有通过计算机模拟人类对句子的理解,同时具备句法的分析,语义的理解,并共同作用于分词的结果而且能顺带给出歧义的最优解。
还有一个最准最强分词器(性能差了点)----人脑。小伙伴们有没有发现人脑能简单地进行分词,机器却这么复杂和困难才勉强能使用,人脑还是hin强大啊。
以上就是基本分词算法的分类以及其主要的思想。
下面分享一些基本的算法理论介绍,觉得无趣的小伙伴先去洗洗睡吧。
正向/逆向最大匹配算法
先说说最大匹配算法,最大匹配算法就是按照某种策略使得切得的词包含的字串长度最大。正向最大匹配算法是从左往右进行匹配,反向则是从右往左进行匹配。举个栗子:
词典: 研究,研究生,生活,水平,活水,的确,确实,在理。
句子: 研究生活水平;他说的确实在理。
那么正向匹配算法,匹配过程:(咱们字典最大长度为3)
从左往右先选择最大的长度作为待查字串,然后查询字典,没命中的情况下,将最后一个字去除,再查询字典,如此往复,直到待查字串为空。
第一句: 研究生活水平
| 待查字串 | 是否命中字典 | 输出 |
|---|---|---|
| 研究生 | 是 | 研究生 |
| 活水平 | 否 | |
| 活水 | 是 | 研究生 活水 |
| 平 | 否 | |
| null | 研究生 活水 平 |
下一句: 他说的确实在理。
| 待查字串 | 是否命中字典 | 输出 |
|---|---|---|
| 他说的 | 否 | |
| 他说 | 否 | |
| 他 | 否 | |
| null | 他 | |
| 说的确 | 否 | |
| ...略 | 否 | 他 说 |
| 的确在 | 否 | |
| 的确 | 是 | 他 说 的确 |
| 实在理 | 否 | |
| 实在 | 是 | 他 说 的确 实在 |
| 理 | 否 | |
| null | 他 说 的确 实在 理 |
那么逆向最大匹配算法,也就是说是个从右往左的一个反向过程,实际上与上述过程一样。只写一句栗子。
| 待查字串 | 是否命中字典 | 输出 |
|---|---|---|
| 实在理 | 否 | |
| 在理 | 是 | 在理 |
| 的确实 | 否 | |
| 确实 | 是 | 确实 在理 |
| 他说的 | 否 | |
| 说的 | 否 | |
| ...略 | 否 | 他 说 的 确实 在理 |
小伙伴也看到了,逆向匹配好像要优于正向匹配。也确实实验表明(哪里有过统计),逆向最大匹配算法要优于正向最大匹配算法的。但也不绝对,还是有不少句子正向的结果要比反向结果要好很多的。
双向最大匹配算法
双向最大匹配算法是将正向最大匹配法与逆向最大匹配法组合。将句子分别使用正向最大匹配和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按照最小集或者其他策略进行选择和融合处理。
据说,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到 的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因所在。
最少切分策略
最少切分策略,思路也比较简单,将几种切分算法得到的结果,选择词数最少的,如果词数一样再用其他方式进行挑选。这个只是个挑选策略,事实证明句子词数最少的切分方式往往都是正确的。
N元模型(N-gram)切词
基于N元模型的切词策略是将训练好的N-gram模型进行路径计算得到最优切分策略路径。巨大多数句子由于歧义的存在,肯定会有多种切分路径,之前的最大匹配算法就是就是用一种贪婪的规则方式选择最优的路径,N-gram模型则是用统计得到的先验概率来得到概率最大的路径。
依然还是举上述的例子:
句子: 他说的确实在理
假设我们使用的2-gram,每个字出现的概率只与其前面的一个字有关
那么我们能举例出所有的词路径:
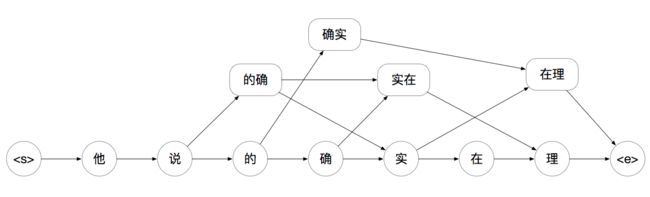
找出其最优的路径,就能得到最优的切分方式。
在其他算法中如最短路径算法,是设定每个路径上的每条边作为一个触达距离,然后再使用Dijkstra或者其他最短路径法来得到最短的触达距离作为最优解。
在N-gram模型的算法中,每个路径上的边都是一个N-gram的概率于是得到如下概率路径有向图。
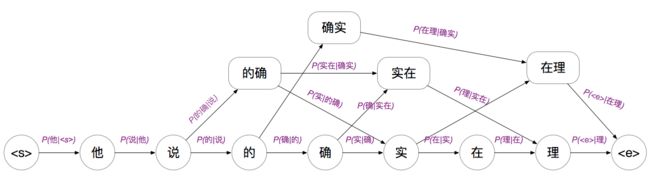
那么分词任务就转变为如何求解最优策略路径
假设随机变量S为一个汉字序列,W是S上所有可能的切分路径(如上图所有从头至尾的不同路径)。对于分词,实际上就是求解使条件概率P(W∣S)最大的切分路径,P(W∣S)即为每条路径的衡量标准。
做贝叶斯公式转换:
由于P(S)为归一化因子,而且一般情况下(词序列无论怎么变子序列都是不会变化)P(S∣W)为1,因此只需要求解 。
假设我们使用 2-gram 语言模型进行建模(一个字词的出现只依赖它前面的那个字或词)。
有了上述模型,就可以得到每条切分路径的也就是开头说的每条切分路径的衡量标准。
在这只后再使用暴力穷举也好,动态规划也好,最短路径算法也好,最终找出最优解序列即为最优的切词策略。
隐马尔科夫模型(HMM)切词
再次强行插入一波广告隐马尔科夫模型的浅显介绍链接
字构词的分词方法思想,是将分词问题转化为字的分类问题(序列标注问题)。就是说序列标注有以下几种: 词首,词中,词尾,单子词等。举个下面的列子就能明白了。
| 研 | 究 | 生 | 说 | 的 | 确 | 实 | 在 | 理 |
|---|---|---|---|---|---|---|---|---|
| 词首 | 词中 | 词尾 | 单字词 | 单字词 | 词首 | 词尾 | 词首 | 词尾 |
当每个字的标注都得出的时候,切词也就顺理成章得完成了。
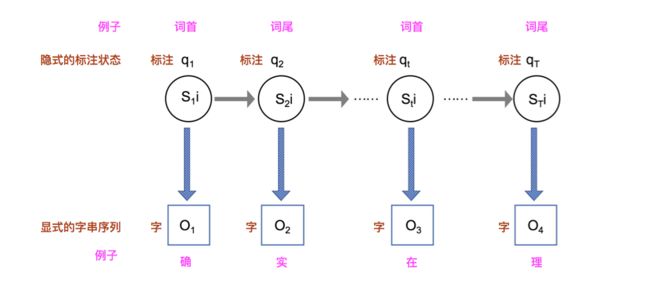
在隐马尔科夫模型中上述切词问题,对应以下几种要素,字为观察符号,标注为隐含状态,目标是找出概率最大的标注序列,实际上就是隐马尔科夫模型三大问题中的解码问题。
给定一个模型λ , 和一个观察序列O,找出产生这一序列概率最大的状态序列Q
这个问题可以使用Viterbi算法就可以轻松解决。
CRF切词
条件随机场(CRF)同样也是一种标注思想,但与HMM不同的地方在于,HMM还算是生成式的话,CRF就属于判别式了,因为CRF主要的思想是将字进行分类任务得到它的最优的标注。
CRF假设标注序列Y在给定观察序列X的条件下,Y构成的图为一个MRF(马尔科夫随机场)。
参考资料
https://www.cnblogs.com/en-heng/p/6214023.html
https://zhuanlan.zhihu.com/p/33261835