目录结构
一、简介
二、Java基本类型
三、虚拟机如何加载类文件
四、JVM如何执行方法调用
五、JVM如何进行异常处理
六、JVM如何实现反射
七、java对象的内存布局
八、Java内存模型(JMM)
九、JVM内存模型
十、垃圾回收机制(GC)
十一、java字节码分析
十二、JDK常用工具介绍
一、简介
1.Java代码如何运行
java代码可以在开发工具中运行、命令行运行、网页中运行等等,但是都离不开JRE,即Java运行时环境。
2.什么是JRE
JRE包含运行java程序的必需组件,如java虚拟机以及java核心类库等。我们常用接触的JDK(java开发工具)中便包含了JRE,同时附带了一系列的开发、诊断工具。
3.虚拟机如何处理java文件
java作为一门高级语言,不能直接被机器所识别,所以需要先编译成字节码,然后再翻译为机器码的方式在机器中运行。整个中间的处理过程是由JVM(java虚拟机)进行操作处理的,首先JVM将.java文件编译为.class文件,然后将.class文件加载到虚拟机中。加载后java类存放在方法区(Method Area),运行时执行方法区中的代码。
4.JVM内存如何划分
虚拟机将内存划分为堆、方法区、虚拟机栈、本地方法区、程序计数器。其中,堆和方法区为线程共享区域,用于存放类信息、实例对象、静态变量等数据。虚拟机栈、本地方法区和程序计数器为线程私有区域,用于存放局部变量,操作数等数据。
关于方法区、持久带、metaspace的理解:
参考链接:https://blog.csdn.net/goldenfish1919/article/details/81216560
jdk7和之前的版本中:永久带又叫Perm区,只存在于hotspot jvm中
jdk8和之后的版本中:已经彻底移除了永久带,引入了一个新的内存区域叫metaspace。
区别:
1) 方法区是规范层面的东西,规定了这一个区域要存放哪些东西
2) 永久带或者是metaspace是对方法区的不同实现,是实现层面的东西
5.什么是虚拟机栈
每个线程都运行在一块独立的内存空间中,在调用方法时会生成一个栈桢,栈桢包含局部变量区和操作数栈,分别用于存放局部变量和操作数,栈桢进栈出栈的内存区域就是虚拟机栈。
6.字节码如何翻译成机器码
字节码翻译成机器码有两种方式,一种是解释执行,另外一种是即时编译。
解释执行:在运行过程中逐条将字节码翻译成机器码进行执行。
即时编译:在运行过程中将整个方法的字节码翻译成机器码进行执行。
两者的区别:从效率上看,解释执行优势在于不需要等待编译,即时编译的优势在于实际运行速度更快。Hotspot当前采用混合模式,首先采用解释执行字节码,对于重复执行的热点代码采用即时编译。
二、Java基本类型
1.八个基本类型
boolean、char、byte、short、int、long、float、double
在虚拟机栈中,boolean、char、byte、short 均以 int 的方式存在。因此可能存在如下情况:
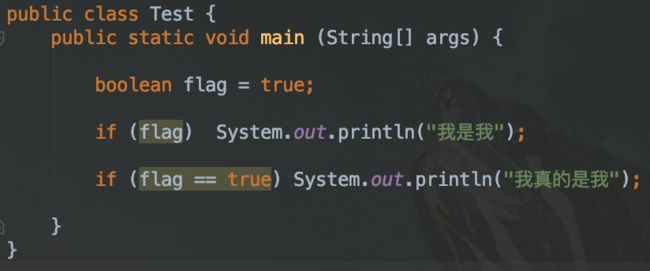
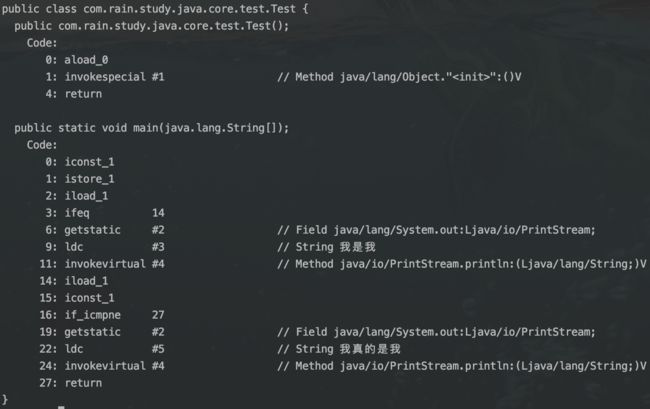
这里先简单介绍以下相关操作指令:iconst_1 表示将值为1的数压入操作数栈;istore_1 表示从操作数栈中弹出一个值,存放在局部变量表index为1的位置(index为0的位置存放着this);iload_1 表示将局部变量表中,index为1位置的值,压入到操作数栈中;ifeq 14 表示条件不满足时跳转到偏移量为14的位置;getstatic 表示访问类的静态字段;if_icmpne 27 表示条件比较,不满足时跳转到偏移量为27的位置;ldc 表示将常量加载到操作数栈中;invokevirtual 表示调用对象的虚方法;return 表示方法返回;
Java字节码指令参考文章:https://www.cnblogs.com/vinozly/p/5399308.html
按照上述字节码执行,打印结果包括“我是我” 和 “我真的是我”。
在操作数栈中,true存储的值为1,false存储的值为0,若我们将字节码中iconst_1修改为iconst_2,再次执行只会打印处“我是我”。这说明对于JVM来说,boolean类型在操作数栈中使用时,按照整数使用,因此我们对boolean类型的值进行修改时不会导致虚拟机报错,所以程序比较中flag==true的比较变成了2==1。可能会有同学问,为什么 if (flag) 可以通过?通过查看字节码指令相关资料,ifeq 通过判断值是否为0的方式判断进行跳转,flag为0表示false,flag不为0表示true,因此 if(2) 等价于 if(true) 。
在Java虚拟机规范中,局部变量区相当于一个数组,除了long和double需要占用两个单元之外,其他基本类型以及引用类型均占用一个单元。在32位Hotspot中,1个单元占用4个字节。在64位Hotspot中,一个单元占用8个字节。
注意,这里是指局部变量区,不同于堆内存中。对于char、byte、short,在堆中分别占用一个字节、两个字节、两个字节,与之取值范围相同。
三、虚拟机如何加载类文件
基本介绍
从class文件到内存中的类,依次需要经过加载、链接、初始化三个过程。其中,链接包括验证、准备、解析三个阶段。
java语言类型分为两大类:基本类型和引用类型。
基本类型:boolean、char、byte、short、int、long、float、double
引用类型:接口、类、数据类、泛型参数。
其中,泛型会在编译后进行擦除,数组类由虚拟机直接生成,接口和类为字节流。
1.加载
加载是指查找字节流,然后根据字节流创建类的过程。接口和类的加载需要借助类加载器进行查找。
jdk9之前,类加载的划分为:启动类加载器->扩展类加载器->应用类加载器,三类加载器的关系从左至右依次为对应的父类加载器。jdk9中引入了模块系统,将扩展类加载器更名为平台类加载器。
类的加载过程需要遵循双亲委派模型,即每当一个类加载器接收到加载请求时,它会先将请求转发给父类加载器。在父类加载器没有找到所请求的类的情况下,该类加载器才会尝试去加载。
除上述三类加载器外,虚拟机允许用户自定义类加载器,实现类加载的特殊处理,如对加密的class文件进行解密等操作。
类的唯一性是通过类加载器实例和类全名共同唯一确定。即同一字节流通过不同的类加载器加载后为不同的类。
2.链接
链接是指将创建的类合并到虚拟机,并保证其能正常运行。链接包括三个阶段:验证、准备和解析。
验证:确保被加载类能够满足 Java 虚拟机的约束条件。
准备:为被加载类的静态字段分配内存,并为类中的字段、方法生成符号引用。需要注意的是静态字段的具体初始化是发生在初始化阶段。因为在类加载到虚拟机之前,无法知道引用的其他类以及自身字段、方法的具体地址,因此只能通过符号引用进行标识。
解析:将符号引用解析成为实际引用。如果符号引用指向一个未被加载的类,或者未被加载类的字段或方法,那么解析将触发这个类的加载(但未必触发这个类的链接以及初始化。)
3.初始化
基本类型和字符串类型若被final修饰,会被编译器标记成常量值(ConstantValue),其初始化直接由虚拟机完成。其他赋值操作将统一被编译器放在命名为 < clinit >的方法中。
类的初始化何时会被触发?
a.当虚拟机启动时,初始化用户指定的主类;
b.当遇到用以新建目标类实例的 new 指令时,初始化 new 指令的目标类;
c.当遇到调用静态方法的指令时,初始化该静态方法所在的类;
d.当遇到访问静态字段的指令时,初始化该静态字段所在的类;
e.子类的初始化会触发父类的初始化;
f.如果一个接口定义了 default 方法,那么直接实现或者间接实现该接口的类的初始化,会触发该接口的初始化;
g.使用反射 API 对某个类进行反射调用时,初始化这个类;
h.当初次调用 MethodHandle 实例时,初始化该 MethodHandle 指向的方法所在的类。
四、JVM如何执行方法调用
1.JVM 的静态绑定和动态绑定
虚拟机通过类名、方法名以及方法描述符识别方法。其中,方法描述符由参数类型及返回类型构成。
需要注意:
java语言不允许方法名称和参数类型相同方法出现在同一个类中。
Java虚拟机不允许方法名称和方法描述符相同的方法出现在同一个类中。
子类定义了与父类中非私有、非静态方法同名的方法,只有当这两个方法的参数类型以及返回类型一致,虚拟机会判定为重写。而对于java语言中重新而虚拟机中非重写的情况,需要通过桥接方法实现java语言的重写。
静态绑定:在解析时便能够直接识别目标方法
动态绑定:需要在运行过程中根据调用者的动态类型来识别目标方法
Java 字节码中与调用相关的指令共有五种。
a. invokestatic:用于调用静态方法。
b. invokespecial:用于调用私有实例方法、构造器,以及使用 super 关键字调用父类的实例方法或构造器,和所实现接口的默认方法。
c. invokevirtual:用于调用非私有实例方法。
d. invokeinterface:用于调用接口方法。
e. invokedynamic:用于调用动态方法。
2.重载与重写
重载:同一类中存在方法名相同,参数不同的方法
重载的方法在编译过程中完成识别。编译器根据所传入参数的声明类型(注意与实际类型区分)来选取重载方法。选取的过程共分为三个阶段:
1.在不考虑对基本类型自动装拆箱,以及可变长参数的情况下选取重载方法;
2.如果在第 1 个阶段中没有找到适配的方法,那么在允许自动装拆箱,但不允许可变长参数的情况下选取重载方法;
3.如果在第 2 个阶段中没有找到适配的方法,那么在允许自动装拆箱以及可变长参数的情况下选取重载方法。

当传入 null 时,它既可以匹配第一个方法中声明为 Object 的形式参数,也可以匹配第二个方法中声明为 String 的形式参数。由于 String 是 Object 的子类,因此编译器会认为第二个方法更为贴切。
重写:子类定义了与父类中非私有方法同名的方法,而且这两个方法的参数类型相同
3.调用指令的符号引用
虚拟机在编译过程中,无法获取目标方法的具体地址,因此需要通过符号引用的方式来表示目标方法。
符号引用包含目标方法所在的类或接口的名称、方法名称以及方法描述符。符号引用存储在 class 文件的常量池之中。根据目标方法是否为接口方法,引用可分为接口符号引用和非接口符号引用。
在解析阶段,虚拟机会将符号引用替换为实际引用。替换过程可以分为以下两种:
3.1 非接口符号引用
3.1.1 在当前类中查找符合名字及描述符的方法。
3.1.2 如果没有找到,在当前类的父类中继续查找,直至 Object 类。
3.1.3 如果没有找到,在当前类所直接实现或间接实现的接口中进行查找。
在接口中查找的得到的目标方法必须是非私有、非静态的方法。并且,如果目标方法在间接实现的接口中,则需满足当前类与该接口之间没有其他符合条件的目标方法。如果有多个符合条件的目标方法,则任意返回其中一个。
3.2 接口符号引用
3.2.1 在当前接口中查找符合名字及描述符的方法。
3.2.2 如果没有找到,在 Object 类中的公有实例方法中查找。
3.2.3如果没有找到,则在当前接口的超接口中查找。这一步的搜索结果的要求与非接口符号引用步骤 3.1.3 的要求一致。
4.虚方法调用
何为虚方法调用?在 Java 中所有非私有实例方法调用都会被编译成 invokevirtual 指令,而接口方法调用都会被编译成 invokeinterface 指令。这两种指令,均属于 Java 虚拟机中的虚方法调用。
如果虚拟机在解析式不能直接识别目标方法,则需要通过动态绑定的方式选择目标方法,即根据当前调用者的动态类型进行选择。相比较于静态绑定,动态绑定更加耗时。
哪些方法可以直接静态绑定?
静态方法、构造器、私有实例方法、超类非私有实例方法以及标记为 final 的方法调用。
虚拟机如何通过动态绑定的方式实现目标方法的查找?
虚拟机为每个类生成了一张方法表,通过空间换时间的策略实现动态绑定。上面提到目标方法的引用分为非接口符号引用和接口符号引用,两者对应的方法表分别为虚方法表(使用 invokevirtual 指标调用)和接口方法表(使用 invokeinterface 指令调用),接下来通过虚拟方法表进行分析:
方法表本质上是一个数组,数组中的每个元素指向当前类或父类的非私有实例方法。其中子类的方法表中会包含父类中所有的非私有方法,且对应方法或重写方法的索引值与父类方法表一致。
举例:
public class Animal () {
public void eat () { ... }
public String toString() { ... }
}
public class Rabbit () {
public String run() { ... }
}
public class Eagle () {
public String fly() { ... }
}
上述三个类的方法表如下:
//Animal
0:Animal.toString()
1:Animal.eat()
//Rabbit
0:Animal.toString()
1:Animal.eat()
2.Rabbit.run()
//Eagle
0:Animal.toString()
1:Animal.eat()
2.Eagle.fly()
在解析过程我们提到,虚拟机会将符号引用替换为实际引用。对于静态绑定的方法而言,实际引用将指向具体的目标方法。对于动态绑定的方法而言,实际引用指向的是索引表中的索引值(不完全确定)。
在执行过程中,虚拟机根据调用者的实际类型,在实际类型的虚方法表中根据索引获取目标方法。这个过程就是动态绑定。
动态绑定和静态绑定相比,动态绑定首先需要访问栈上的调用者,获取调用者的类型,然后访问该类型的方法表,根据索引值再获取目标方法,整个过程开销并不太大。同时,即时编译虚拟机给予了一定的优化,优化手段主要包括内联缓存和方法内联两种方式。
什么是内联缓存?
内联缓存优化技术和我们平常项目中经常使用的缓存技术非常相似。将调用者类型和目标方法放在缓存中,在执行过程中如果遇到该类型,则直接从内联缓存中获取目标方法,否则通过方法表动态绑定的方式获取。
动态绑定主要是解决类中的多态问题,多态我们可以划分为单态、多态(数量较少)、超多态(数量较多),每种类别也分别有对应的内联缓存,依次为单态内联缓存、多态内联缓存、超多态内联缓存。每种内联缓存的实现策略略有不同,这里不做详细研究。
什么是方法内联?
在java面向对象中,我们常常会对方法进行抽象,避免存在一个冗杂的方法。抽象的方式时将一个复杂的方法抽象出多个单一的方法,然后进行方法之间的调用。由于方法之间的调用会带来上述繁杂的操作,因此可以通过将调用的方法体内容复制到调用位置,从而较少调用。
这种方法虽然可以较小方法调用带来的性能开销,但是编译过程会复杂,导致编译时间变长,另外由于方法体中的内容是直接通过copy的方式到另一个方法中,因此会占用更多的内存空间,所以并非所有的情况都适合方法内联。
在 Java 虚拟机里,编译生成的机器码会被部署到 Code Cache 之中。这个 Code Cache 是有大小限制的(由 Java 虚拟机参数 -XX:ReservedCodeCacheSize 控制)。
哪些情况我们可以使用方法内联?
这里首先需要说一下三种即时编译器,HotSpot 虚拟机包含多个即时编译器 C1、C2 和 Graal。
Graal 是一个实验性质的即时编译器,可以通过参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 启用,并且替换 C2。
C1编译器编译效率较快,对于执行时间较短的,或者对启动性能有要求的程序,我们采用C1编译器,对应参数 -client。
C2编译器编译后代码执行效率更快,对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的 C2,对应参数 -server。
1.由 -XX:CompileCommand 中的 inline 指令指定的方法,以及由 @ForceInline 注解的方法(仅限于 JDK 内部方法),会被强制内联。而由 -XX:CompileCommand 中的 dontinline 指令或 exclude 指令(表示不编译)指定的方法,以及由 @DontInline 注解的方法(仅限于 JDK 内部方法),则始终不会被内联。
2.如果调用字节码对应的符号引用未被解析、目标方法所在的类未被初始化,或者目标方法是 native 方法,都将导致方法调用无法内联
3.C2 不支持内联超过 9 层的调用(可以通过虚拟机参数 -XX:MaxInlineLevel 调整),以及 1 层的直接递归调用(可以通过虚拟机参数 -XX:MaxRecursiveInlineLevel 调整)。
4.即时编译器将根据方法调用指令所在的程序路径的热度,目标方法的调用次数及大小等因素决定方法调用能否被内联。
补充:
静态方法调用,即时编译器可以轻易地确定唯一的目标方法。然而,对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化,即转换为一个或多个直接调用,然后才能进行方法内联。即时编译器的去虚化方式可分为完全去虚化以及条件去虚化。
完全去虚化是通过类型推导或者类层次分析(class hierarchy analysis),识别虚方法调用的唯一目标方法,从而将其转换为直接调用的一种优化手段。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化则是将虚方法调用转换为若干个类型测试以及直接调用的一种优化手段。它的关键在于找出需要进行比较的类型。
五、JVM如何进行异常处理
首先,我们先了解一下java语言规范中异常的基本概念。
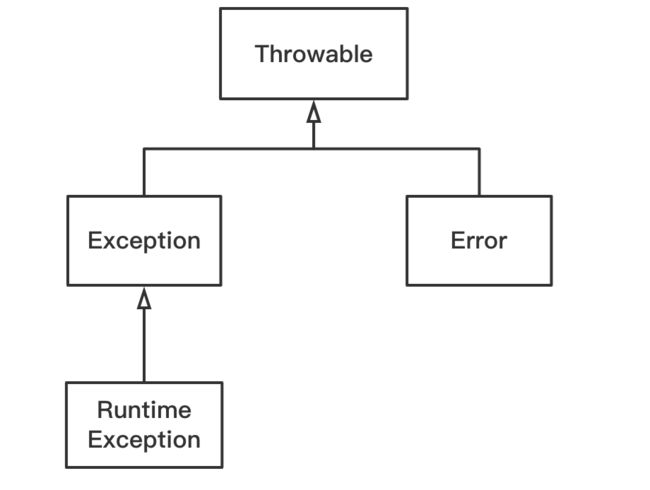
1.Throwable,所有异常都是 Throwable 类或者其子类的实例,Throwable 有两大直接子类,分别是Error和Exception。
2.Error,涵盖程序不应捕获的异常。当程序触发 Error 时,它的执行状态已经无法恢复,需要中止线程甚至是中止虚拟机,属于非检查异常。
3.Exception,涵盖程序可能需要捕获并且处理的异常,属于检查异常。
4.RuntimeException,是Exception的子类,属于非检查异常。
5.自定义的异常类,基本均为 Exception 的子类。
检查异常和非检查异常是什么?
在 Java 语法中,所有的检查异常都需要程序显式地捕获,或者在方法声明中用 throws 关键字标注。通常情况下,程序中自定义的异常应为检查异常,以便最大化利用 Java 编译器的编译时检查。
在java虚拟机的异常处理中包含两大组成要素:抛出异常和捕获异常。这两大要素共同实现程序控制流的非正常转移。
如何在代码中抛出异常?
抛出异常可分为显式和隐式两种。
显式抛异常的主体是应用程序,它指的是在程序中使用“throw”关键字,手动将异常实例抛出
隐式抛异常的主体则是 Java 虚拟机,它指的是 Java 虚拟机在执行过程中,碰到无法继续执行的异常状态,自动抛出异常。
如何在代码中捕获异常?
捕获异常则涉及了如下三种代码块。

1. try 代码块:用来标记需要进行异常监控的代码。
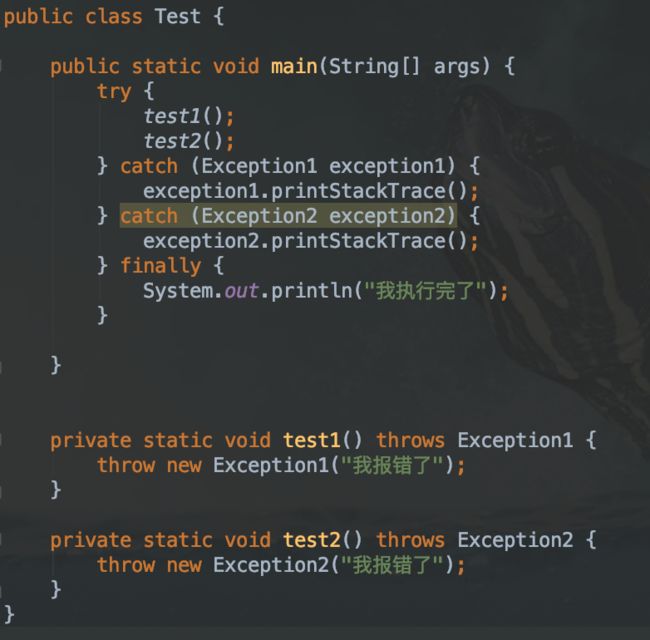
2. catch 代码块:跟在 try 代码块之后,用来捕获在 try 代码块中触发的某种指定类型的异常,并对异常捕获后执行相应的处理。try 代码块后面可以跟着多个 catch 代码块,来捕获不同类型的异常。虚拟机会从上至下匹配异常处理器。因此,前面的 catch 代码块所捕获的异常类型不能覆盖后边的,否则编译器会报错。
3. finally 代码块:跟在 catch 代码块之后,用来声明一段必定运行的代码。
第一种情况:try 代码块中没有发生异常,则执行完后进入 finally 代码块。
第二种情况:try 代码块中发生异常,然后被 catch 代码块捕获后,进入 finnaly 代码块。
第三种情况: try 代码块中发生异常,没有被 catch 代码块捕获后,直接进入 finnaly 代码块。
上述三种情况仅是针对于 try 代码块发生异常,catch 代码块 和 finally 代码块没有发生异常的场景。
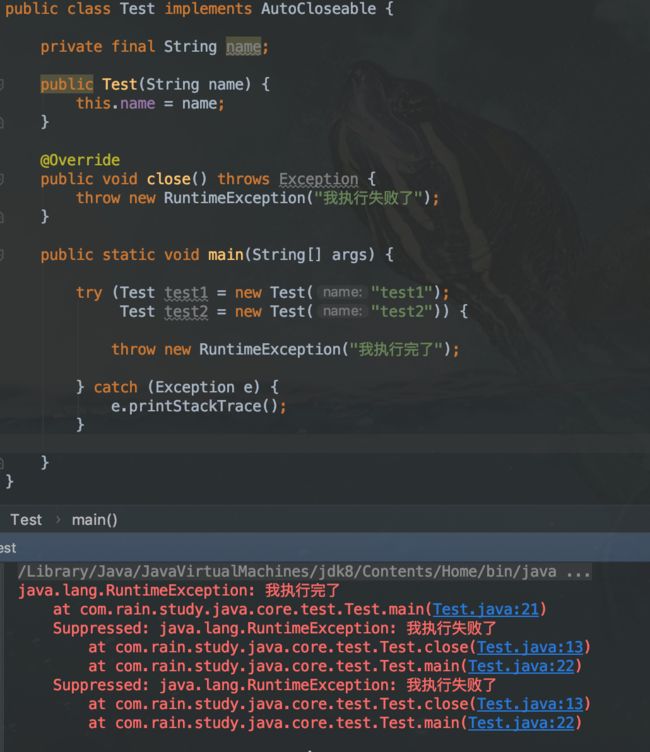
如果 catch 代码块也发生异常了呢? 同样会进入 finally 代码块,然后抛出 catch 代码块中的异常信息。finnaly 代码块中发生异常则直接抛出相应异常信息。并且后者的异常信息栈会覆盖上层抛出的异常信息。
我们之后在代码中可以通过 try-catch 的方式进行异常捕获,但是虚拟机是如何捕获异常的呢?
在编译生成的字节码中,每个方法都附带一个异常表。异常表中的每一个条目代表一个异常处理器,并且由 from 指针、to 指针、target 指针以及所捕获的异常类型构成。这些指针的值是字节码索引,用以定位字节码。其中,from 指针和 to 指针标示了该异常处理器所监控的范围。
异常实例的构造十分昂贵。这是由于在构造异常实例时,Java 虚拟机便需要生成该异常的栈轨迹。该操作会逐一访问当前线程的 Java 栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字,方法所在的类名、文件名,以及在代码中的第几行触发该异常。

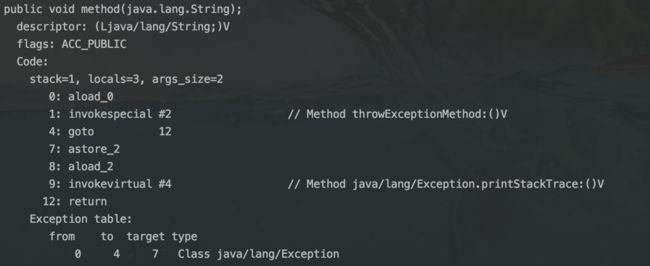
上述方法编译后,异常表中有一个条目,from 指针和 to 指针分别为 0 和 4,表示异常监控的字节码索引范围为 0-4(不包括4),target 指针为 7, 表示异常处理器从字节码的索引为7的位置开始, type 表示捕获异常的类型。
当程序触发异常后,虚拟机开始从上至下遍历异常表中的所有条目。
当触发异常的字节码的索引值在某个异常表条目的监控范围内,虚拟机会判断所抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,Java 虚拟机会将控制流转移至该条目 target 指针指向的字节码。
如果遍历完所有异常表条目,Java 虚拟机仍未匹配到异常处理器,那么它会弹出当前方法对应的 Java 栈帧,并且在调用者中重复上述操作。在最坏情况下,虚拟机需要遍历当前线程 Java 栈上所有方法的异常表。
补充:Java 7 的 Suppressed 异常以及语法糖
Java 7 专门构造了一个名为 try-with-resources 的语法糖,在字节码层面自动使用 Suppressed 异常,精简资源打开关闭的用法。
例如:try-catch 用法
六、JVM如何实现反射
1.什么是反射?
反射是在程序的运行状态中,可以构造任意一个类的对象,可以了解任意一个对象所属的类,可以了解任意一个类的成员变量和方法,可以调用任意一个对象的属性和方法。这种动态获取程序信息以及动态调用对象的功能称为Java语言的反射机制。
2.java代码中如何使用反射?
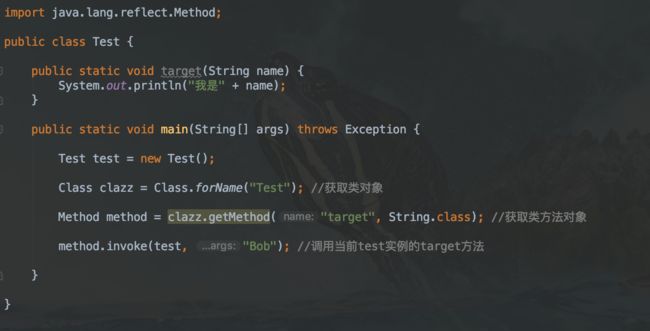
第一步:获取 Class 对象。
在 Java 中常见的有这么三种。
2.1 使用静态方法 Class.forName 来获取。
2.2 调用对象的 getClass() 方法。
2.3 直接用类名 +“.class”访问。
对于基本类型来说,它们的包装类型拥有一个名为“TYPE”的 final 静态字段,指向该基本类型对应的 Class 对象。
例如,Integer.TYPE 指向 int.class。对于数组类型来说,可以使用类名 +“[ ].class”来访问,如 int[ ].class。
第二步:反射功能的使用
2.4 newInstance() :生成一个该类的实例。前提要求:该类中必须拥有一个无参数的构造器
2.5 isInstance(Object) :判断一个对象是否是该类的实例
2.6 Array.newInstance(Class,int) :构造该类型的数组
2.7 Constructor/Field/Method.setAccessible(true) :可以绕开 Java 语言的访问限制
2.8 Constructor.newInstance(Object[]) :生成该类的实例
2.9 Field.get/set(Object) :访问字段的值
2.10 Method.invoke(Object, Object[]) :调用方法
3.反射的实现机制
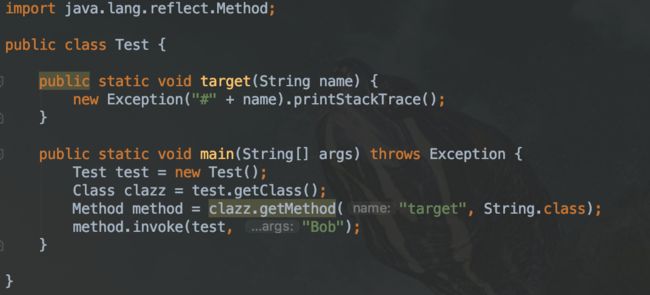
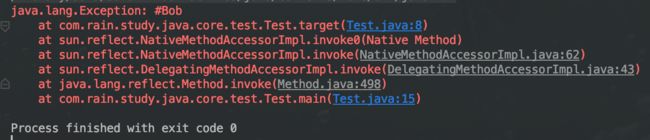
当通过调用Method.invoke执行对应方法时,首先会进入委派实现(DelegatingMethodAccessorImpl),然后进入本地实现(NativeMethodAccessorImpl),最后到达目标方法。
可能会有这么几个疑问:为什么要经过一层委派实现然后再到达本地实现呢?直接调用本地实现不可以吗?委派实现的作用是什么呢?
也许有人会猜测,通过委派实现可能是为了选择实现方式,那也就是说可能除了本地实现之外,还有其他的实现方式。
通过查阅,发现虚拟机还支持另一种动态生成字节码的实现,可以直接使用 invoke 指令来调用目标方法。所以我们可以确定,委派实现是为了在本地实现和动态实现之间进行选择。
接下来我们带着以下两个个问题对动态实现和本地实现进行实验比较:
1.什么情况下会使用动态实现,什么情况下会使用本地实现?
2.反射和直接调用的开销差距有多少?
首先,我们看一下第一个问题:什么情况下会使用动态实现,什么情况下会使用本地实现
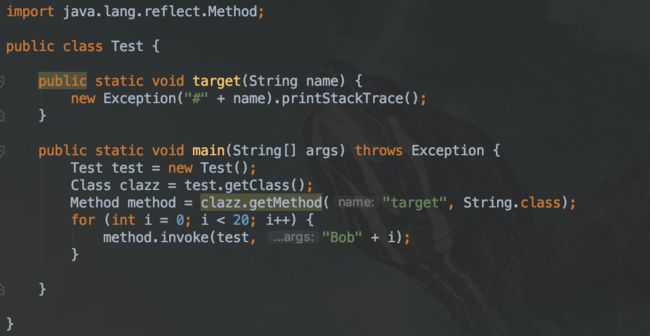
对刚才的method.invoke方法循环调用20次,查看打印日志:
从上述日志中我们发现,从第15次之前,虚拟机采用的是本地实现的方式,然而从第16次开始,虚拟机开始采用动态生成字节码的实现方式。
虚拟机默认设置了一个阈值 15(可以通过 -Dsun.reflect.inflationThreshold= 来调整),当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
接下来,我们再看一下第二个问题:反射和直接调用的开销差距有多少
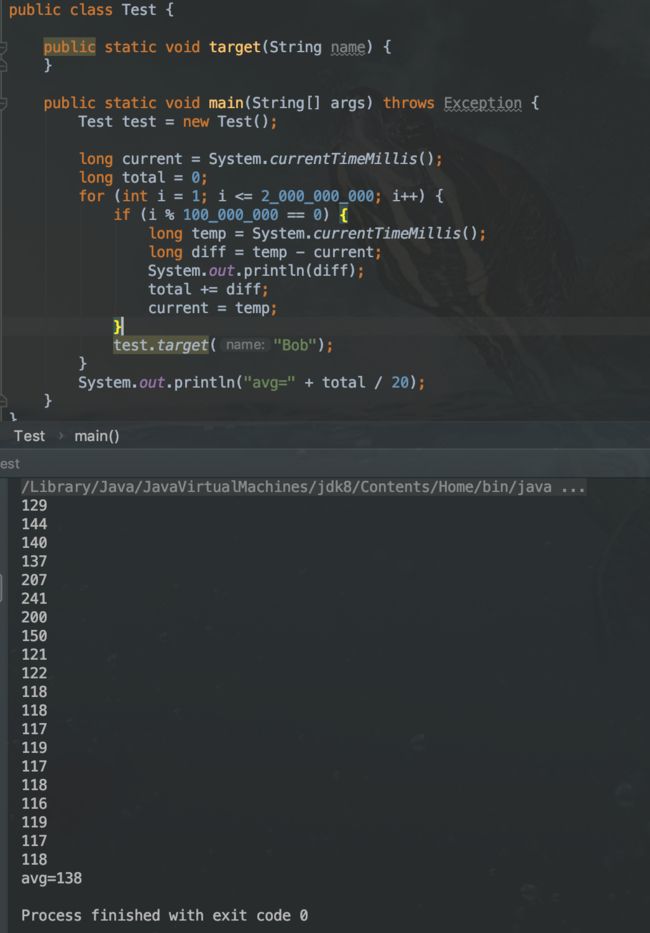
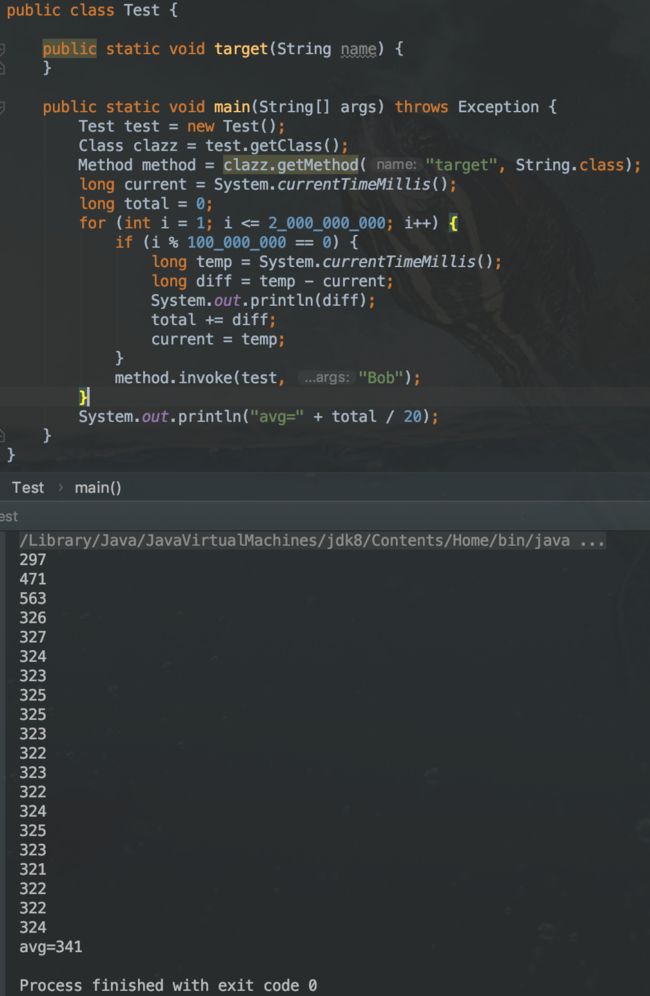
上面实例中,将直接调用和反射调用分别执行了20亿次,每隔1亿次打印执行时间。直接调用1亿次的开销平均为138ms,反射调用1亿次的开销平均用时为341ms,反射调用约为直接调用的2.5倍。
七、java对象的内存布局
1.新建对象的方式
1.1 new Object()
1.2 反射:Class.newInstance() 或 Constructor.newInstance()
1.3 Object.clone()
1.4 Unsafe.allocateInstance(Object.class)
更新中…