Jieba使用实验
本文尝试了jieba的三种分词模式、自定义字典、计算频数并将频数较高的分词结果存入csv文件。
1. 配置
安装jieba
pip install jieba
2. jieba三种分词模式尝试
jieba的分词一般用cut函数完成,函数定义如下:
def cut(sentence,cut_all=False,HMM=True):
其中sentence是需要分词的句子样本;cut_all是分词的模式,默认是false是精准模式;HMM就是隐马尔可夫链,这个是在分词的理论模型中用到的,默认是开启的。
jieba分词的模式分为三种:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
由于本组的课程设计为导师搜索引擎,所以本次实验的分词对象选用了四川大学公共管理学院官网的夏志强教师的简介文本:

实现jieba三种分词模式的python代码如下:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import jieba
#全模式
seg_list = jieba.cut(text,cut_all=True)
print "[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text,cut_all=False)
print "[精确模式]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
print "[搜索引擎模式]: ","/ ".join(seg_list)
运行结果如下:

3. 自定义字典
从结果中我们可以看出,专有名词"公共管理学院、"博士生导师"、"政治学类"可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
- 新建dict.txt

在代码中引入自定义字典:
jieba.load_userdict("dict.txt") #自定义字典-
结果:

我们可以看到由于添加了自定义词典,“公共管理学院”、“博士生导师”、“副主任”等词被连起来了。
4. 计算词频并存入文件后,得到最终结果
为实现计数并存入文件,我使用了python的Counter模块对分词结果列表进行计数,使用了csv模块将结果写入csv编辑。
最终代码如下:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import jieba
import csv
from collections import Counter
import codecs
jieba.load_userdict("dict.txt") #自定义字典
def word_frequency(text):
seg_list = [seg for seg in jieba.cut(text,cut_all=False) if len(seg)>=2] #字符串长度为2及以上的精确分词的list
count = Counter(seg_list) #计数
csv =open('result.csv','w') #打开或新建一个csv文件
csv.write(codecs.BOM_UTF8) #防止乱码
for wordcount in count.most_common(50):
word,freq=wordcount
csv.write(word+','+str(freq)+'\n') #写入csv文件
print (word,freq)
if __name__=='__main__':
with open('text1.txt','r') as t:
text=t.read() #打开待分词文本文件
word_frequency(text)
运行结果,输出了50个频次最高的分词及其对应的频数:
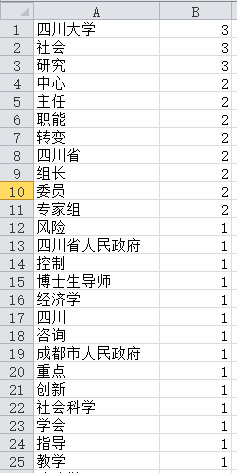
顺便用在线工具按词频做了一个词云:

IK Analyzer使用实验
配置
1. 安装Apache Solr
wget [http://mirror.bit.edu.cn/apache/lucene/solr/7.3.1/solr-7.3.1.tgz](http://mirror.bit.edu.cn/apache/lucene/solr/7.3.1/solr-7.3.1.tgz)
tar zxvf solr-7.3.1.tgz
启动solr服务
sudo ./solr start -p 8983 -force
启动成功(图中是8080端口,但实际上我们最后用的是8983)
2. 配置IK Analyzer
- 将IK分词器 JAR 包拷贝到../server/solr-webapp/webapp/WEB-INF/lib下
- 将词典配置文件拷贝到 ../server/solr-webapp/webapps/solr/WEB-INF/classes下
- 新建core
sudo ./solr create -c hyjcore -p 8983 -force
在core下,conf中放的是配置文件,stopwords中放的是停用词 - 修改conf下的managed-schema配置文件,添加ik analyzer的相关配置
- 在bin下重启solr服务
sudo ./solr start -p 8983 -force
进行分词
使用chrome浏览器进入http://139.199.177.192:8983(公网ip和solr运行端口)/solr/#/

运行结果:

从分词结果来看,IK Analyzer和Jieba的全模式和搜索引擎模式结果较为相似,但从语义上来看精确度不如Jieba的精确模式。