简介
熟悉Java编程的童鞋对于Quartz应该是比较属性的了。一个开源的任务调度框架。当你的系统中需要定时、定期来执行一次或多次任务的时候,那它一定是不二之选。
目前市面上也要好多开源的任务调度平台,比如TBSchedule,Elastic-Job,XXL-JOB,大多的任务调度平台都是以Quartz为基础进行的二次封装或者重新。可见Quartz在调度框架中的地位还是比较高的。
本文主要从代码层面介绍Quartz执行任务调度时,任务的获取、执行、重试的流程。
案例介绍
场景:某个系统在用户提交请求的时候,需要后台异步处理数据。
搭建一个简单的Quartz + spring boot + mysql 的系统
- pom.xml 引入依赖
com.alibaba
druid
1.1.10
com.alibaba
druid-spring-boot-starter
1.1.10
org.springframework.boot
spring-boot-starter-quartz
- 参数文件
#数据库参数配置 application.properties
spring.datasource.primary.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.primary.url=jdbc:mysql://localhost:3306/tf?useUnicode=true&characterEncoding=utf-8
spring.datasource.primary.username=***
spring.datasource.primary.password=****
spring.datasource.primary.driverClassName=com.mysql.cj.jdbc.Driver
spring.datasource.primary.initialSize=30
spring.datasource.primary.minIdle=10
spring.datasource.primary.maxActive=50
spring.datasource.primary.maxWait=60000
spring.datasource.primary.timeBetweenEvictionRunsMillis=60000
spring.datasource.primary.minEvictableIdleTimeMillis=300000
spring.datasource.primary.validationQuery=SELECT 1
spring.datasource.primary.testWhileIdle=true
spring.datasource.primary.testOnBorrow=true
spring.datasource.primary.testOnReturn=true
### 配置Quartz参数 quartz.properties
org.quartz.scheduler.instanceName=TfScheduler
org.quartz.scheduler.instanceId=AUTO
org.quartz.scheduler.rmi.export=false
org.quartz.scheduler.rmi.proxy=false
org.quartz.scheduler.wrapJobExecutionInUserTransaction=false
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount=20
org.quartz.threadPool.threadPriority=5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread=true
org.quartz.jobStore.misfireThreshold=50000
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.clusterCheckinInterval=15000
- 配置Bean
配置数据
@Configuration
public class DuridDatasource {
@Primary
@Bean("dataSource")
@ConfigurationProperties("spring.datasource.primary")
public DataSource dataSourceOne() {
return DruidDataSourceBuilder.create().build();
}
}
配置Quartz
@Configuration
public class QuartzConfig {
@Autowired
private JobFactory jobFactory;
@Autowired
@Qualifier("dataSource")
private DataSource primaryDataSource;
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
//获取配置属性
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
//在quartz.properties中的属性被读取并注入后再初始化对象
propertiesFactoryBean.afterPropertiesSet();
//创建SchedulerFactoryBean
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setQuartzProperties(propertiesFactoryBean.getObject());
//使用数据源,自定义数据源
factory.setDataSource(primaryDataSource);
factory.setJobFactory(jobFactory);
factory.setWaitForJobsToCompleteOnShutdown(true);//这样当spring关闭时,会等待所有已经启动的quartz job结束后spring才能完全shutdown。
factory.setOverwriteExistingJobs(false);
factory.setStartupDelay(10);
return factory;
}
}
配置JOB能够注入Spring Bean
@Component
public class QuartzJobFactory extends AdaptableJobFactory {
@Autowired
private AutowireCapableBeanFactory capableBeanFactory;
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
//调用父类的方法
Object jobInstance = super.createJobInstance(bundle);
//进行注入
capableBeanFactory.autowireBean(jobInstance);
return jobInstance;
}
}
- 编写一个简单的JOB处理数据
public class TfCommandJob implements Job {
private static final Logger log = LoggerFactory.getLogger(TfCommandJob.class);
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
log.info("start do tf command");
try {
TimeUnit.SECONDS.sleep(30);
} catch (Exception e) {
log.error("error in sleep", e);
}
log.info("end");
}
}
- 编写触发入口
@RestController
@RequestMapping("/test")
public class TestController {
private static final String NAME = "tf_command_%s";
private static final String GROUP = "tf_command_group";
private static final String TRIGGER_NAME = "tf_command_trigger_%s";
private static final String TRIGGER_GROUP = "tf_command_trigger_group";
@Resource
private Scheduler quartzScheduler;
private static final Logger logger = LoggerFactory.getLogger(TestController.class);
@RequestMapping("/startJob")
public JsonResponse startJob() {
JobDataMap jobDataMap = new JobDataMap();
Long time = new Date().getTime();
JobDetail job = JobBuilder
.newJob(TfCommandJob.class)
.withIdentity(String.format(NAME, time), GROUP)
.setJobData(jobDataMap)
.requestRecovery()
.storeDurably()
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity(String.format(TRIGGER_NAME, time), TRIGGER_GROUP)
.forJob(job)
.startNow().build();
try {
quartzScheduler.scheduleJob(job, trigger);
} catch (Exception e) {
return JsonResponse.fail(ResultConst.ERROR_CODE, ResultConst.ERROR_MSG);
}
return JsonResponse.succ(null);
}
}
- 最后,在执行案例程序之前需要创建Quartz用到的数据库表。创建表的SQL文件在quartz源码包的 org.quartz.impl.jdbcjobstore 目录下,根据不同的数据库选择不同的 tables*.sql ,本案例使用的是mysql,所以我选择的 tables_mysql.sql 文件执行。
案例分析
配置相关的不具体说了。
在该案例中,我们编写了一个需要异步执行一个JOB:TfCommandJob.class
为了让这个JOB可以异步执行,并且 :
- 可以在任务失败的时候被重试
- 在实例被停止,重启的时候JOB可以被重新执行(不会被丢失)
- 多实例运行的时候任务不会被重复执行
- 任务数量过多的时候,可以控制并发,控制执行数量,避免JVM OOM
所以用到了Quartz任务调度框架。
配置好了Quartz,编写好了JOB之后。需要把JOB注册给调度器,在TestController 中,创建 JobDetail (代表一个具体的可执行的调度程序), 在创建一个 Trigger,讲两者交给调度器。
这样调度器就会根据Trigger指定的时间规则执行JOB。
通过PostMan 请求 localhost:8080/test/startJob ,后台显示
组件介绍
在这里主要提几个概念:
- 任务(Job): 定义任务执行的任务,需要实现Job接口,重写execute方法。在案例中是 TfCommandJob ,他表示的是一个实际需要执行的任务。在实际执行的过程中,我们可以通过JobBuilder进行实例化为一个JobDetail对象,然后配合合适的Trigger,交给Scheduler进行调度。
JobDetail job = JobBuilder
//指定JOB的class
.newJob(TfCommandJob.class)
//指定Name唯一识别
.withIdentity(String.format(NAME, time), GROUP)
//指定传入到JOB执行时时候使用到的参数数据
.setJobData(jobDataMap)
//当Quartz服务被中止后,再次启动任务时会尝试恢复执行之前未完成的所有任务
.requestRecovery()
//标识job是持久的,删除所有触发器的时候不被删除
.storeDurably()
.build();
- 触发器(Trigger):为任务设定出发条件,比如马上,即刻,每天早上8点,每月1号12点……。在案例中是
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity(String.format(TRIGGER_NAME, time), TRIGGER_GROUP)
.forJob(job)
.startNow().build();
该trigger是指马上触发。它还有很多类的Trigger,比如
- 调度器(Scheduler):将任务与触发器相结合,注册到调度器中,待执行。这个是在配置文件 schedulerFactoryBean 定义了Scheduler构造工厂,并且Controller中注入使用
quartzScheduler.scheduleJob(job, trigger);
调度流程分析
分析其调度过程之前,有几个问题:
- 调度如何控制并发
- 如何做到多实例情况下不被重复执行
- 如何保证实例停止的时候任务能被别的实例接管
就算大家没有这几个问题我也要提出并且讲清楚这几个问题 ^ _ ^
调度框架的启动
我们先来分析调度框架的启动流程。
在案例中的 QuartzConfig 文件,初始化了 SchedulerFactoryBean ,通过这个Factory创建了 QuartzScheduler , QuartzScheduler 这个类是Quartz的 核心 ,间接继承了Scheduler接口,包含了调度Job、注册JobListener实例的方法, 通过这个 Scheduler 创建了实际执行调度的调度线程: QuartzSchedulerThread
而 QuartzSchedulerResources 相当于一个配置信息保存的空间,它包含创建QuartzScheduler实例所需的所有资源(JobStore,ThreadPool等),当然也拥有一个执行QuartzSchedulerThread的执行器。
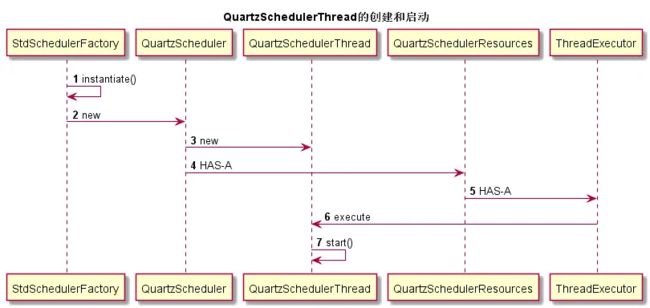
StdSchedulerFactory.instantiate():生成StdScheduler过程中会new一个QuartzScheduler实例
生成StdScheduler过程中会new一个QuartzScheduler实例
在QuartzScheduler的构造器方法里面可以看到创建QuartzSchedulerThread的代码逻辑,并通过QuartzSchedulerResources对象获取ThreadExecutor对象,最后execute新建的QuartzSchedulerThread。
public QuartzScheduler(QuartzSchedulerResources resources, long idleWaitTime, @Deprecated long dbRetryInterval)
throws SchedulerException {
this.resources = resources;
if (resources.getJobStore() instanceof JobListener) {
addInternalJobListener((JobListener)resources.getJobStore());
}
this.schedThread = new QuartzSchedulerThread(this, resources);
ThreadExecutor schedThreadExecutor = resources.getThreadExecutor();
schedThreadExecutor.execute(this.schedThread);
if (idleWaitTime > 0) {
this.schedThread.setIdleWaitTime(idleWaitTime);
}
jobMgr = new ExecutingJobsManager();
addInternalJobListener(jobMgr);
errLogger = new ErrorLogger();
addInternalSchedulerListener(errLogger);
signaler = new SchedulerSignalerImpl(this, this.schedThread);
getLog().info("Quartz Scheduler v." + getVersion() + " created.");
}
调度框架启动完成之后
所有任务调度的工作都交给了 QuartzSchedulerThread 来完成:
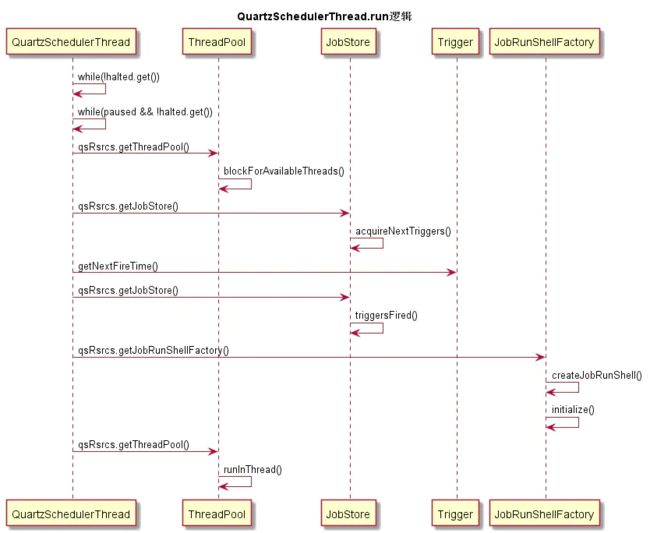
流程图中,QuartzSchedulerThread整个的运行方法都包含在while语句中,在执行JOB之前会判断 halted,paused的状态
然后通过 QuartzSchedulerResources 这个资源存储实例获取线程池,查看是否有可用的线程。如果有再往下进行。再次也回答了之前提到的几个问题中的第四个问题 任务数量过多的时候,可以控制并发,控制执行数量,避免JVM OOM
-
再有可用的线程之后再调用QuartzSchedulerResources 获取JobStore. 这个的JobStore是负责跟踪所有scheduler的“工作数据”,包括Jobs,Triggers,比较常用的有:
- RAMJobStore :RAMJobStore 正如它名字描述的一样,它保存数据在内存中的,所以只要服务重启,任务就会丢失,而且它无法做到分布式任务调度,只能做到单机任务调度。
- JDBCJobStore : 与上面的不同,它以JDBC的方式保存数据在数据库中,它比RAMJobStore的配置复杂一点,当然,肯定也没有RAMJobStore快。其广泛用于 Oracle, PostgreSQL, MySQL, MS SQLServer, HSQLDB, 和DB2。使用JDBCJobStore之前你必须首先创建一系列Quartz要使用的表。这个表在上文的案例中有提到。由于其数据都是存储在数据库中,所以实例在被停止重启之后,JOB不会丢失 这也就回答了第二个问题
JobStore
在执行的过程中有这么几个方法调用
- 获取triggers
qsRsrcs.getJobStore().acquireNextTriggers - 触发执行
qsRsrcs.getJobStore().triggersFired - 释放trigger
qsRsrcs.getJobStore().releaseAcquiredTrigger - 完成触发任务后的调用
qsRsrcs.getJobStore().triggeredJobComplete
这几个方法都是由JobStore来调用的。而实现分布式任务调度需要使用到的JobStore实现类为数据库类型
so .
Quartz核心表介绍
先来介绍一下Quartz的各个表。暂时先了解有这么几个表。
| Table Name | Description |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的JobListener的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的Trigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGER_LISTENERS | 存储已配置的TriggerListener的信息 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
- acquireNextTriggers(long noLaterThan, int maxCount, long timeWindow)
查询、获取一段时间内将要被调度的triggers.我们走进源码看一下他的实现:
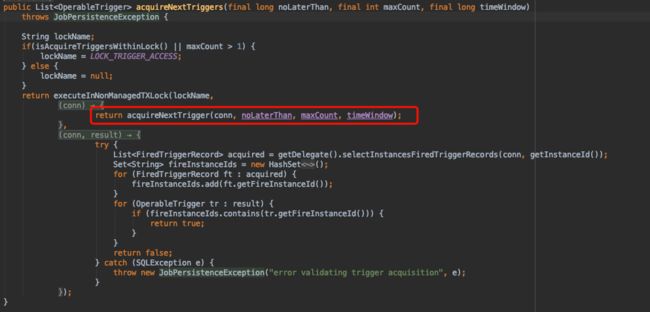
可以看到他又调用了另一个获取方法acquireNextTrigger
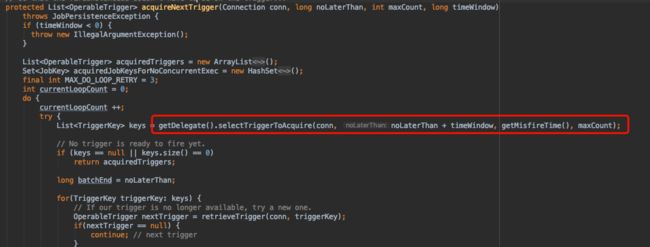
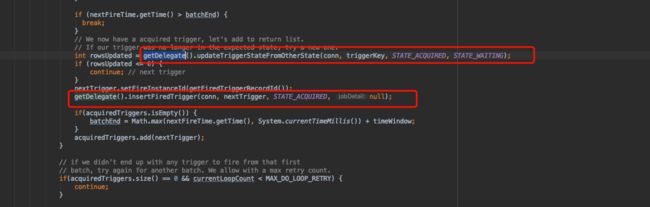
在这个方法中我们可以看到实际的执行方法有:
getDelegate().selectTriggerToAcquire
直接执行语句:
SELECT
TRIGGER_NAME,
TRIGGER_GROUP,
NEXT_FIRE_TIME,
PRIORITY
FROM
{ 0 } TRIGGERS
WHERE
SCHED_NAME = { 1 }
AND TRIGGER_STATE = ?
AND NEXT_FIRE_TIME <= ? AND ( MISFIRE_INSTR = - 1 OR ( MISFIRE_INSTR != - 1 AND NEXT_FIRE_TIME >= ?))
ORDER BY
NEXT_FIRE_TIME ASC,
PRIORITY DESC
getDelegate().updateTriggerStateFromOtherState
UPDATE { 0 } TRIGGERS
SET TRIGGER_STATE = ?
WHERE
SCHED_NAME = { 1 }
AND TRIGGER_NAME = ?
AND TRIGGER_GROUP = ?
AND TRIGGER_STATE = ?
getDelegate().insertFiredTrigger
INSERT INTO {0}FIRED_TRIGGERS (SCHED_NAME, ENTRY_ID, TRIGGER_NAME, TRIGGER_GROUP, INSTANCE_NAME, FIRED_TIME, SCHED_TIME, STATE, JOB_NAME, JOB_GROUP, IS_NONCONCURRENT, REQUESTS_RECOVERY, PRIORITY)
VALUES({1}, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
第一个SQL语句,目的就是为了获取当前所有可执行的Trigger的记录。
第二个SQL语句,目的是为了实现任务锁定,采用的是CAS模式
// We now have a acquired trigger, let's add to return list.
// If our trigger was no longer in the expected state, try a new one.
int rowsUpdated = getDelegate().updateTriggerStateFromOtherState(conn, triggerKey, STATE_ACQUIRED, STATE_WAITING);
if (rowsUpdated <= 0) {
continue; // next trigger
}
从把Triggers里面的记录,从一个状态更新为另一个状态,如果更新成功,表示该任务被本实例获取了。如果更新失败,则表示另外一个实例抢先更改了状态。
第三个SQL语句,在本实例已经获取到了Trigger的情况下,往FIRED_TRIGGERS插入一条记录,表示当前的任务处于执行中。
- executeInNonManagedTXLock
如果同一时间执行Trigger的数量大于1,则属性 org.quartz.jobStore.acquireTriggersWithinLock 应设置为true,开启分布式悲观锁,可以避破坏数据。
executeInNonManagedTXLock方法源码如下:
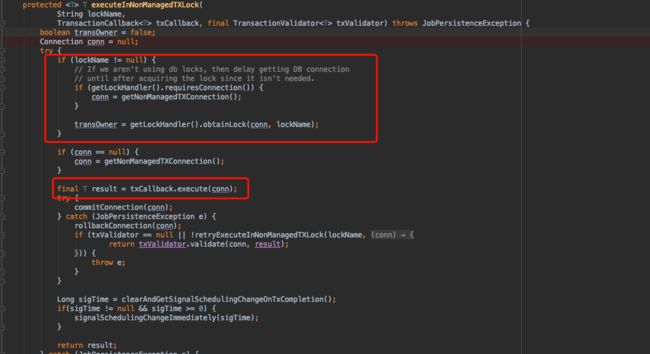
总体的步骤为: 获取锁、执行callback、提交事务、最后释放锁
getLockHandler().obtainLock 表示获取锁
txCallback.execute(conn) 表示执行逻辑
commitConnection(conn) 表示提交事务
releaseLock(lockName, transOwner) 表示释放锁
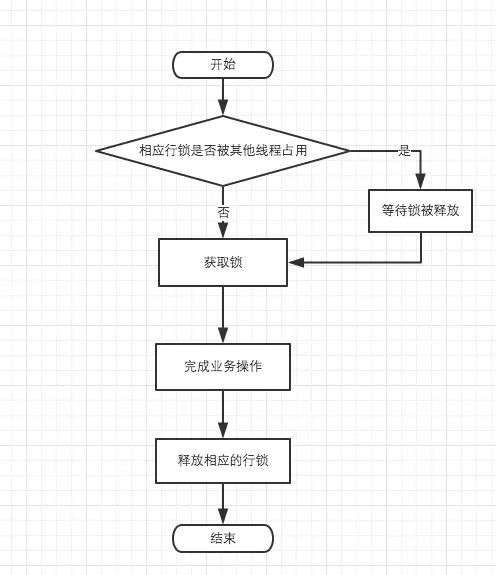
getLockHandler()方法会获得一个信号量,如果是单机环境使用的是SimpleSemaphore,如果集群环境使用的是DBSemaphore。在集群环境下obtainLock()方法如下:
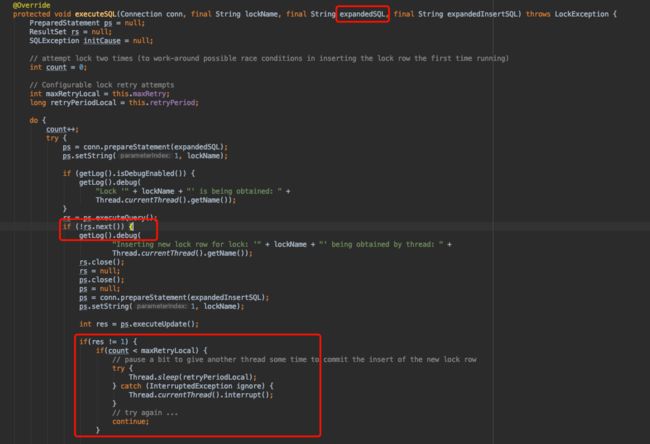
obtainLock首先判断是否已经获取到锁,如果没有执行方法executeSQL,其中有两条重要的SQL,分别是:expandedSQL和expandedInsertSQL,以SCHED_NAME = ‘TfScheduler’为例:
expandedSQL:
SELECT * FROM QRTZ_LOCKS WHERE SCHED_NAME = 'TfScheduler' AND LOCK_NAME = ? FOR UPDATE
expandedInsertSQL:
INSERT INTO QRTZ_LOCKS(SCHED_NAME, LOCK_NAME) VALUES ('TfScheduler', ?)
select语句后面添加了FOR UPDATE是使用了MySQL的悲观锁,如果LOCK_NAME存在,当多个节点去执行此SQL时,只有第一个节点会成功,其他的节点都将进入等待;
如果LOCK_NAME不存在,多个节点同时执行expandedInsertSQL,只会有一个节点插入成功,执行插入失败的节点将进入重试,重新执行expandedSQL;
参考:
https://www.jianshu.com/p/38e5e0953e56